

新智元報道
編輯:桃子
【新智元導讀】大模型涌現(xiàn)能力如何理解?谷歌的最新論文研究了語言模型中的上下文學習,是如何受到語義先驗和輸入-標簽映射影響。
前段時間,OpenAI整出了神操作,竟讓GPT-4去解釋GPT-2的行為。
對于大型語言模型展現(xiàn)出的涌現(xiàn)能力,其具體的運作方式,就像一個黑箱,無人知曉。
眾所周知,語言模型近來取得巨大的進步,部分原因是它們可以通過上下文學習(ICL)來執(zhí)行任務。
上下文學習是一種過程,模型在對未見過的評估樣本執(zhí)行任務之前,會先接收幾個輸入-標簽對的范例。
在谷歌最新發(fā)表的論文中,研究人員研究了語義先驗,以及輸入-標簽映射在ICL中如何相互作用。

論文地址:https://arxiv.org/pdf/2303.03846.pdf
特別是,語言模型在上下文學習能力,如何隨著參數(shù)規(guī)模而改變。
論文一作Jerry Wei表示,大型語言模型(GPT-3.5、PaLM)可以遵循上下文中的范例,即使標簽被翻轉或在語義上不相關。這種能力在小型語言模型中是不存在的。

網友表示,這對模型新的涌現(xiàn)能力很有見解。
AI「黑箱」怎么破?
一般來說,模型能夠在上下文中學習,有以下2個因素:
一種是使用預先訓練的語義先驗知識來預測標簽,同時遵循上下文范例的格式。
比如,見到以「積極情緒」和「消極情緒」作為標簽的影評例子,并用先驗知識進行情感分析。
另一種是從提供的范例中,學習ICL中的輸入-標簽映射。比如,找到正面評價映射到一個標簽,而負面評價映射到另一個標簽的模式。
最新研究的目標就是為了了解這兩個因素在上下文中如何作用。
因此,在論文中,研究者調查了兩個設置來進行研究:翻轉標簽ICL,語義無關標簽的ICL (SUL-ICL)。
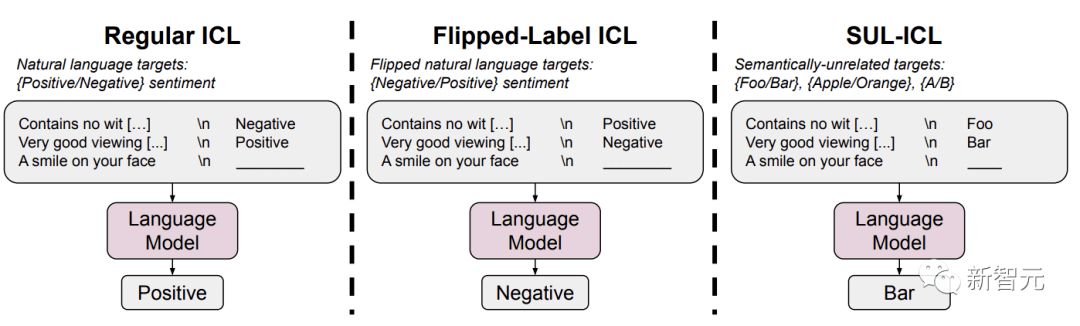
翻轉標簽ICL和語義無關標簽ICL(SUL-ICL)在情感分析任務中的概述
在翻轉標簽ICL中,上下文范例的標簽被翻轉,強制模型覆蓋語義先驗,以遵循上下文范例。
在SUL-ICL中,使用與任務無語義關系的標簽,意味著模型必須學習輸入標簽映射才能執(zhí)行任務,因為它們不再依賴于自然語言標簽的語義。
研究者發(fā)現(xiàn),覆蓋先驗知識是模型規(guī)模能力,就像在上下文中學習與語義無關的標簽的能力一樣。
此外,指令調優(yōu)加強了先驗知識的使用,而不是增加了學習輸入-標簽映射的能力。
實驗過程
此外,研究人員還對五種語言模型進行了測試:PalM、Flan-PalM、GPT-3、DirectGPT和Codex。
翻轉標簽
在這個實驗中,上下文示例的標簽被翻轉,這意味著先驗知識和輸入-標簽映射不一致。比如,包含積極情緒的句子被標記為「消極情緒」,從而研究模型是否可以覆蓋其先驗知識。
在此設置中,能夠覆蓋先驗知識,并在上下文中學習輸入-標簽映射的模型性能會下降,因為真實評估標簽沒有被翻轉。
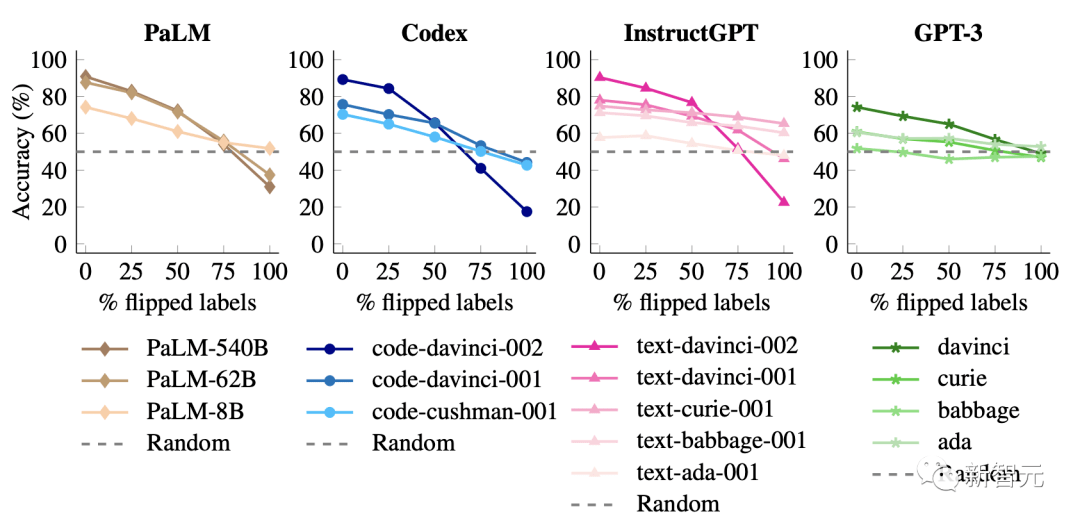
研究者還發(fā)現(xiàn)當沒有標簽被翻轉時,參數(shù)規(guī)模較大的模型比較小的模型,擁更好的性能。
但是,當翻轉越來越多的標簽,小型模型的性能保持相對平穩(wěn),但大型模型的性能大幅下降,遠低于隨機猜測。
比如,code-davinci-002的性能從90%下降到22.5%。
這些結果表明,當輸入標簽映射相互矛盾時,大模型可以覆蓋預訓練的先驗知識。
小型模型無法做到這一點,這使得這種能力成為模型規(guī)模的涌現(xiàn)現(xiàn)象。
語義無關的標簽
在這個實驗中,研究人員用語義無關的標簽替換原來標簽。
比如,在情感分析中,用「foo/bar」代替「消極/積極」 ,這意味著模型只能通過學習輸入-標簽映射來執(zhí)行 ICL。
如果一個模型主要依賴于ICL的先驗知識,那么在這種替換之后,它的性能應該會下降,因為它將不再能夠使用標簽的語義意義來進行預測。
另一方面,可以在上下文中學習輸入-標簽映射的模型,將能夠學習這些語義不相關的映射,其性能不會出現(xiàn)大幅的下降。
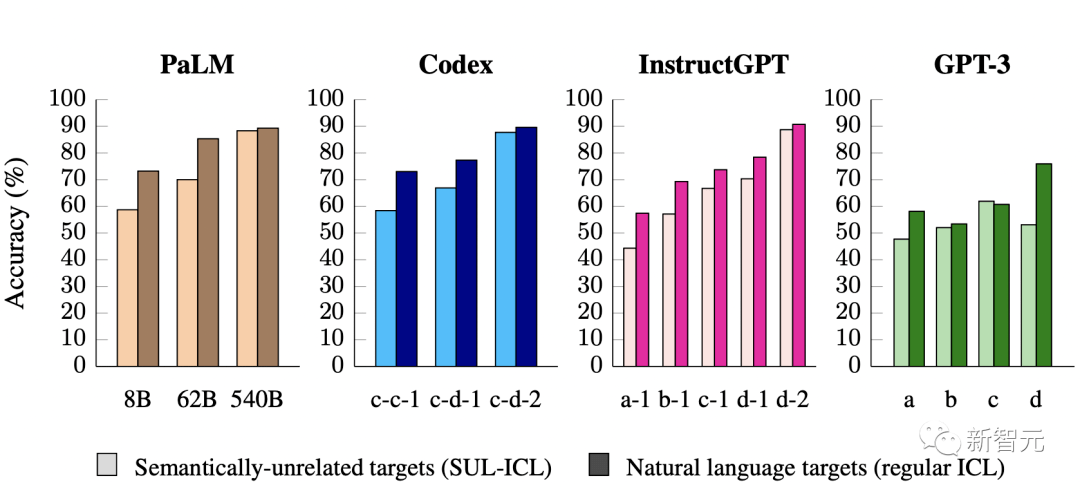
事實上,使用語義無關的標簽會導致小型模型的性能大幅下降。
這表明較小的模型主要依賴于它們在上下文中的語義先驗,而不是從提供的輸入標簽映射中學習。
另一方面,當標簽的語義特性被移除時,大型模型具有在上下文中學習輸入標簽映射的能力。
此外,研究人員還發(fā)現(xiàn),包含更多的上下文范例對大型模型的性能改善,比對小型模型的性能改善更大。
顯然,大型模型比小型模型更善于從上下文范例中學習。
指令調優(yōu)模型如何?
當前,指令調優(yōu)是提高模型性能比較流行的一種方法。
這兩者都將導致標準上下文任務性能的提高。
研究人員繼續(xù)通過與前面相同的兩個設置來研究這個問題,只是這一次將重點放在比較標準語言模型(特別是 PaLM)和它們的指令調優(yōu)變體(Flan-PaLM)上。
首先,當使用語義不相關的標簽時,F(xiàn)lan-PalM比PalM性能更好。
這種效應在小型模型中非常顯著,因為Flan-PalM-8B的性能比PaLM-8B高9.6% ,幾乎趕上了PaLM-62B。
這種趨勢表明,指令調優(yōu)加強了學習輸入標簽映射的能力,但這并不是令人驚訝的發(fā)現(xiàn)。
更有趣的是,研究者還發(fā)現(xiàn)Flan-PalM在遵循翻轉標簽上比PalM更差,這意味著指令調優(yōu)模型無法覆蓋它們的先驗知識。
在100%翻轉標簽的情況下,F(xiàn)lan-PaLM模型無法做到隨機猜測,但是在相同的設置下,沒有進行指令調優(yōu)的PaLM模型可以達到31%的準確率
這些結果表明,指令調優(yōu)必須增加模型在語義先驗可用時的依賴程度。
結合前面的研究結果,研究者得出結論:雖然指令調優(yōu)提高了學習輸入-標簽映射的能力,但它更強化了語義先驗知識的使用。
谷歌這篇論文強調了語言模型的ICL行為如何根據(jù)其參數(shù)而改變,并且更大的語言模型具有將輸入映射到許多類型的標簽的涌現(xiàn)能力。
這是一種推理形式,其中輸入-標簽映射可以潛在地學習任意符號。
未來,更進一步的研究可以幫助人們去了解為什么這些現(xiàn)象會與模型參數(shù)相關。
參考資料:
https://ai.googleblog.com/2023/05/larger-language-models-do-in-context.html





