
梯度下降是機器學習的動力之源。
經過前面兩節內容的鋪墊,我們可以開始講一講機器學習的動力之源:梯度下降。
梯度下降并不是一個很復雜的數學工具,其歷史已經有200多年了,但是人們可能不曾料到,這樣一個相對簡單的數學工具會成為諸多機器學習算法的基礎,而且還配合著神經網絡點燃了深度學習革命。
1、什么是梯度
對多元函數的各參數求偏導數,然后把所求得的各個參數的偏導數以向量的形式寫出來,就是梯度。
具體來說,兩個自變量的函數f(x1,x2),對應著機器學習數據集中的兩個特征,如果分別對x1,x2求偏導數,那么求得的梯度向量就是(∂f/∂x1,∂f/∂x2)T,在數學上可以表示成Δf(x1,x2)。那么計算梯度向量的意義何在呢?其幾何意義,就是函數變化的方向,而且是變化最快的方向。對于函數f(x),在點(x0,y0),梯度向量的方向也就是y值增加最快的方向。也就是說,沿著梯度向量的方向Δf(x0),能找到函數的最大值。反過來說,沿著梯度向量相反的方向,也就是 -Δf(x0)的方向,梯度減少最快,能找到函數的最小值。如果某一個點的梯度向量的值為0,那么也就是來到了導數為0的函數最低點(或局部最低點)了。
2、梯度下降:下山的隱喻
在機器學習中用下山來比喻梯度下降是很常見的。想象你們站在一座大山上某個地方,看著遠處的地形,一望無際,只知道遠處的位置比此處低很多。你們想知道如何下山,但是只能一步一步往下走,那也就是在每走到一個位置的時候,求解當前位置的梯度。然后,沿著梯度的負方向,也就是往最陡峭的地方向下走一步,繼續求解新位置的梯度,并在新位置繼續沿著最陡峭的地方向下走一步。就這樣一步步地走,直到山腳,如下圖所示。
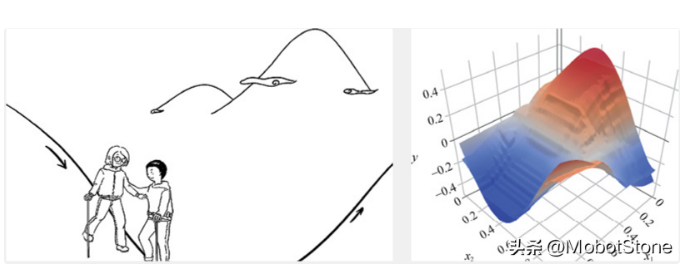
從上面的解釋中,就不難理解為何剛才我們要提到函數的凹凸性了。因為,在非凸函數中,有可能還沒走到山腳,而是到了某一個山谷就停住了。也就是說,對應非凸函數梯度下降不一定總能夠找到全局最優解,有可能得到的只是一個局部最優解。然而,如果函數是凸函數,那么梯度下降法理論上就能得到全局最優解。
3、梯度下降有什么用
梯度下降在機器學習中非常有用。簡單地說,可以注意以下幾點。
機器學習的本質是找到最優的函數。
如何衡量函數是否最優?其方法是盡量減小預測值和真值間的誤差(在機器學習中也叫損失值)。
可以建立誤差和模型參數之間的函數(最好是凸函數)。
梯度下降能夠引導我們走到凸函數的全局最低點,也就是找到誤差最小時的參數。





