擊這里在線咨詢客服")

圖片來源@視覺中國
文 | 零點(diǎn)有數(shù)科技
作為人工智能史上里程碑事件之一的ChatGPT,自2022年11月30日發(fā)布至今,一直備受熱議。在ChatGPT熱潮尚未見減弱之勢,2023年3月14日,OpenAI公司繼續(xù)發(fā)布新一代AI語言大模型GPT-4,并官宣稱GPT-4是“OpenAI最先進(jìn)的系統(tǒng)”“能夠產(chǎn)生更安全、更有用的響應(yīng)”。
作為同一家公司推出的同屬人工智能技術(shù)驅(qū)動(dòng)的自然語言處理工具(AI語言大模型),相比此前的ChatGPT,GPT-4到底有何先進(jìn)之處?支持這些先進(jìn)之處的底層邏輯是什么?點(diǎn)擊閱讀原文,領(lǐng)取零點(diǎn)有數(shù)專家的超萬字詳細(xì)解讀。
鑒于ChatGPT是基于GPT-3.5大模型微調(diào)形成的一個(gè)應(yīng)用產(chǎn)品——AI聊天機(jī)器人,而GPT-4則是GPT-3.5的下一代大模型,本文將從兩個(gè)層面來比較:一是從基礎(chǔ)模型層面,比較GPT-4與GPT-3.5(作為底層邏輯);二是從應(yīng)用能力層面,比較GPT-4與ChatGPT(作為先進(jìn)之處)。
01 GPT-4與GPT3.5
GPT-4是OpenAI公司自2018年6月發(fā)布GPT-1以來,并歷經(jīng)GPT-2、GPT-3、GPT-3.5之后的最新一代AI自然語言大模型(參見下表1)。
從歷代沿革來看,原理基本相同。第一,都是采用一種稱之為“自回歸生成”的關(guān)聯(lián)統(tǒng)計(jì)方法;第二,都是首先采用無監(jiān)督學(xué)習(xí)預(yù)訓(xùn)練出一個(gè)基礎(chǔ)通用模型,然后再通過監(jiān)督學(xué)習(xí)進(jìn)行微調(diào)適配各種任務(wù),最后采用“從人類反饋中強(qiáng)化學(xué)習(xí)”的強(qiáng)化學(xué)習(xí)方法,使得模型能像人類一樣進(jìn)行對話交流;第三,都是基于一種稱之為“Transformer”的算法框架。即都是“GPT”(生成式預(yù)訓(xùn)練轉(zhuǎn)換器,或稱生成式預(yù)訓(xùn)練大模型)。
然而不同的是,演變的變量主要關(guān)乎模型的規(guī)模(即參數(shù)個(gè)數(shù))、預(yù)訓(xùn)練的數(shù)據(jù)量、對輸入信息的支持能力(是否是多模態(tài)、是否是長信息)、模型功能(是否有多種能力)以及模型性能、應(yīng)用安全和可靠性等方面。
具體對比如下:
1、模型規(guī)模。相較于GPT-3.5的1750億個(gè)參數(shù),GPT-4的參數(shù)達(dá)到了5000億個(gè)(也有報(bào)道為1萬億),GPT-4的規(guī)模比GPT-3.5更大。更大的規(guī)模通常意味著更好的性能,能夠生成更復(fù)雜、更準(zhǔn)確的語言。
2、訓(xùn)練數(shù)據(jù)。GPT-3.5使用了來自維基百科、新聞報(bào)道、網(wǎng)站文章等互聯(lián)網(wǎng)上的大量文本數(shù)據(jù),大小為45TB左右。而GPT-4則使用了更大量的網(wǎng)頁、書籍、論文、程序代碼等文本數(shù)據(jù),同時(shí)還使用了大量的可視數(shù)據(jù)。盡管無法考究具體數(shù)值,但毫無疑問,GPT-4的訓(xùn)練數(shù)據(jù)比GPT-3.5更豐富。這使得GPT-4具備更廣泛的知識,回答也更具針對性。
表1 OpenAI歷代GPT模型參數(shù)與預(yù)訓(xùn)練數(shù)據(jù)量對比
3、模態(tài)與信息。GPT-3.5是基于文本的單模態(tài)模型,無論是圖像、文本、音頻,用戶只能輸入一種文本類型的信息。而GPT-4是一個(gè)多模態(tài)模型,可以接受文本和圖像的提示語(包括帶有文字和照片的文件、圖表或屏幕截圖)。這使得GPT-4可以結(jié)合兩類信息生成更準(zhǔn)確的描述。在輸入信息長度方面,與GPT-3.5限制3000個(gè)字相比,GPT-4將文字輸入限制提升至2.5萬字。文字輸入長度限制的增加,也大大擴(kuò)展了GPT-4的實(shí)用性。例如可以把近50頁的書籍輸入GPT-4從而生成一個(gè)總結(jié)概要,直接把1萬字的程序文檔輸入給GPT-4就可直接讓它給修改Bug。
4、模型功能。GPT-3.5主要用于文字回答和劇本寫作。而GPT-4,除文字回答和劇本寫作外,還具有看圖作答、數(shù)據(jù)推理、分析圖表、總結(jié)概要和角色扮演等更多功能。
5、模型性能。雖然GPT-3.5已經(jīng)表現(xiàn)出很強(qiáng)大的性能,但GPT-4在處理更復(fù)雜的問題方面表現(xiàn)得更好。例如,在多種專業(yè)和學(xué)術(shù)基準(zhǔn)方面,GPT-4表現(xiàn)出近似人類水平;在模擬律師考試方面,GPT-4可以進(jìn)入應(yīng)試者前10%左右,而GPT-3.5則在應(yīng)試者倒數(shù)10%左右;在USABO Semifinal Exam 2020(美國生物奧林匹克競賽)、GRE口語等多項(xiàng)測試項(xiàng)目中,GPT-4也取得了接近滿分的成績,幾乎接近了人類水平。參見如下圖1。
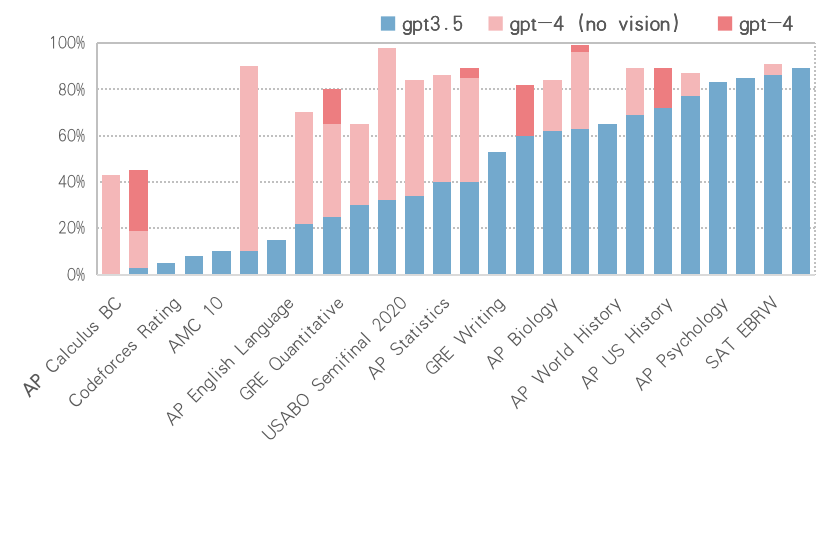
圖1 GPT-4各項(xiàng)考試結(jié)果(按GPT-3.5性能排序)(數(shù)據(jù)來源:https://openai.com/research/gpt-4)
6、安全性和可靠性。GPT-4改進(jìn)了對抗生成有毒或不真實(shí)內(nèi)容的策略,以減少誤導(dǎo)性信息和惡意用途的風(fēng)險(xiǎn),提高其安全性和可靠性。特別地,GPT-4在事實(shí)性、可引導(dǎo)性和拒絕超范圍解答(非合規(guī))問題方面取得了有史以來最好的結(jié)果(盡管它還不夠完美)。與GPT-3.5相比,在生成的內(nèi)容符合事實(shí)測試方面,GPT-4的得分比GPT-3.5高40%,對敏感請求(如醫(yī)療建議和自我傷害)的響應(yīng)符合政策的頻率提高29%,對不允許內(nèi)容的請求響應(yīng)傾向降低82%。
總體來說,GPT-4比GPT-3.5更可靠,更有創(chuàng)造力,能夠處理更細(xì)微的指令。參見表2。
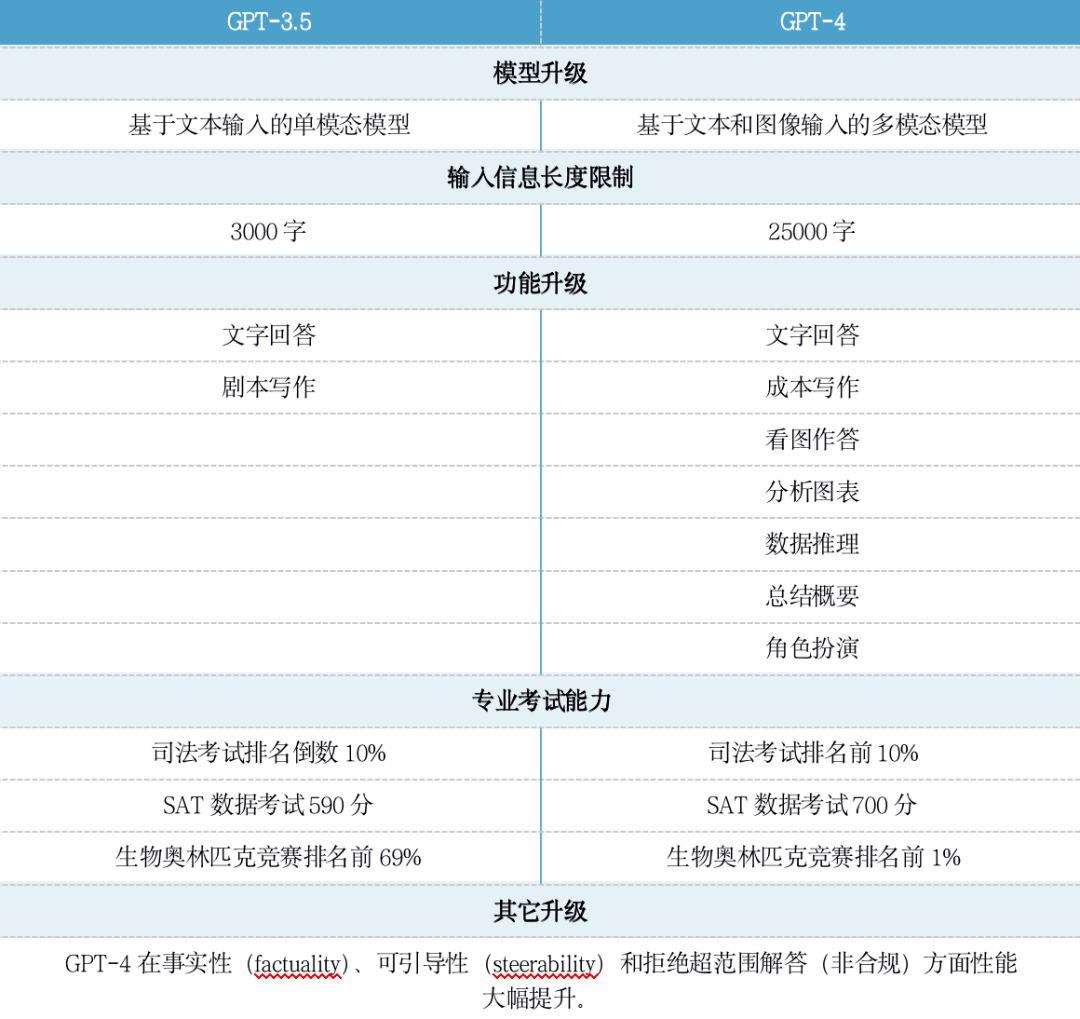
表2 從GPT-3.5到GPT-4的新變化
02 GPT-4與ChatGPT
ChatGPT是基于GPT-3.5的AI聊天機(jī)器人。但在對話方面,GPT-4已表現(xiàn)出更好的連貫性和語境理解能力:不僅可以生成流暢、準(zhǔn)確和有邏輯的文本,還可以理解和回答各種類型的問題,甚至還可以與用戶進(jìn)行創(chuàng)造性和技術(shù)性的寫作任務(wù)。其中,比較突出的應(yīng)用能力體現(xiàn)如下。
1、新增的圖片辨識和分析能力。與ChatGPT相比,GPT-4除了可以支持文字輸入以外,還新增了圖片辨識和分析功能,即能辨識圖片(輸出對圖片的內(nèi)容描述)、分析圖表(類似Excel中的圖表分析)、發(fā)現(xiàn)圖片中的不常之處(對圖片中異常現(xiàn)象進(jìn)行辨識)、閱讀文件并總結(jié)概要(如對PDF文件內(nèi)容進(jìn)行歸納總結(jié))等。甚至只需要在紙上畫一個(gè)網(wǎng)站的草稿圖,拍一張照片上傳給GPT-4,模型便可生成網(wǎng)站代碼。
2、更先進(jìn)的推理能力。相比ChatGPT只能在一定程度上進(jìn)行簡單和直接的推理,GPT-4可以進(jìn)行復(fù)雜和抽象的思考,能解決更復(fù)雜的問題。如前所述,GPT-4在多個(gè)專業(yè)和學(xué)術(shù)領(lǐng)域都已表現(xiàn)出人類的水平,如美國的律師考試已經(jīng)達(dá)到了前10%的標(biāo)準(zhǔn),法學(xué)院的入學(xué)考試也達(dá)到了88%的成績,SAT大學(xué)入學(xué)考試也達(dá)到了90%的成績。特別是ChatGPT不擅長的數(shù)學(xué)解題能力,GPT-4有了大幅提升,在美國高校入學(xué)考試SAT數(shù)學(xué)考試中,獲得了800分中的700分。
3、更高水平的創(chuàng)造力和協(xié)作性。與ChatGPT只能在一定范圍內(nèi)進(jìn)行有限的創(chuàng)造和協(xié)作不同,GPT-4可以與用戶進(jìn)行創(chuàng)造性和技術(shù)性的寫作任務(wù),例如創(chuàng)作歌曲、編寫劇本或者學(xué)習(xí)用戶的風(fēng)格和偏好,還可以生成、編輯和迭代各種類型和風(fēng)格的文本,并且能夠根據(jù)用戶的反饋和建議來改進(jìn)其輸出。
4、更廣泛的應(yīng)用前景。GPT-4憑借接近人類水平的語言理解和生成能力以及其他方面的優(yōu)勢,可在各種領(lǐng)域和場合中發(fā)揮重要作用。例如,GPT-4可以作為一個(gè)智能助理、教育工具、娛樂伙伴和研究助手,為office辦公軟件、搜索引擎、虛擬導(dǎo)師應(yīng)用等提供使能。據(jù)公開資料報(bào)道,微軟已將GPT-4接入Office套件從而推出全新的AI功能Copilot,也已將GPT-4接入Bing以提供定制化搜索服務(wù);摩根士丹利正在應(yīng)用GPT-4進(jìn)行財(cái)富管理部市場信息的分類和檢索;Doulingo將使用GPT-4進(jìn)行角色扮演以增進(jìn)語言的學(xué)習(xí);BeMyEyes正在運(yùn)用GPT-4將視覺型圖片轉(zhuǎn)成文字幫助盲人理解;可汗學(xué)院也已使用GPT-4作為虛擬導(dǎo)師Khanmigo……等等。
可以預(yù)見,GPT-4將會(huì)接入越來越多的行業(yè),從而促進(jìn)社會(huì)生產(chǎn)力和創(chuàng)造力的提升,為人類帶來便利和價(jià)值。與此同時(shí),伴隨著GPT-4的應(yīng)用拓展和深入,GPT-4將從人類反饋中進(jìn)行更多、更快的學(xué)習(xí),其模型迭代升級的速度也將隨之加快,更多的功能、更強(qiáng)的性能將會(huì)呈驚現(xiàn)于世。
03 共同的問題
如前所述,GPT-4和ChatGPT同屬生成式AI自然語言大模型。所謂生成式,簡而言之就是根據(jù)輸入的單詞來預(yù)測下一個(gè)最有可能出現(xiàn)的關(guān)聯(lián)性單詞,然后將這個(gè)最有可能出現(xiàn)的單詞輸入模型,再預(yù)測下一個(gè)最有可能出現(xiàn)的關(guān)聯(lián)性單詞……,類似“單詞接龍”,如此接續(xù)。通過對大量現(xiàn)存的各種人類語料進(jìn)行“訓(xùn)練”,讓模型的各個(gè)參數(shù)不斷調(diào)整,使得模型的“單詞接龍”水平不斷接近人類語料的真實(shí)情況,即讓模型學(xué)到規(guī)律。由此,GPT-4和ChatGPT均會(huì)存在由于生成式本身的短板所導(dǎo)致的一系列問題。
例如:如果真實(shí)語料中本身存在大量虛假信息,或者存在大量有毒信息(如充滿種族、性別、宗教、政治等偏見或惡意),而這些信息恰好被模型學(xué)到了,這無疑會(huì)導(dǎo)致模型存在產(chǎn)生有害內(nèi)容的風(fēng)險(xiǎn);如果出現(xiàn)了實(shí)際不同但碰巧符合同一規(guī)律的內(nèi)容,模型有可能無法區(qū)分其真實(shí)性,最直接的結(jié)果是,若現(xiàn)實(shí)中不存在的內(nèi)容剛好符合模型從訓(xùn)練材料中學(xué)到的規(guī)律,模型就有可能對不存在的內(nèi)容進(jìn)行“合乎規(guī)律的混合捏造”,即產(chǎn)生虛假信息;由于模型缺乏可解釋性,而我們又無法直接查看模型到底記住了什么、學(xué)到了什么,只能通過多次提問來評估和猜測它的所記所學(xué),這會(huì)導(dǎo)致隱私泄露風(fēng)險(xiǎn)(據(jù)BBC 3月23日報(bào)道,有用戶在社交媒體上看到了其他人使用ChatGPT的歷史搜索記錄標(biāo)題);基于“從人類反饋中強(qiáng)化學(xué)習(xí)”,難以避免從惡意的誘導(dǎo)中學(xué)到了不該學(xué)的規(guī)律,這會(huì)給意識形態(tài)侵襲、網(wǎng)絡(luò)安全帶來沖擊……。總之,伴隨著應(yīng)用越廣泛、越深入,GPT-4和ChatGPT都將面臨更多的安全與風(fēng)險(xiǎn)挑戰(zhàn)。
正如OpenAI公司的創(chuàng)始人兼首席執(zhí)行官Sam Altman最近接受ABC新聞采訪時(shí)表示,他對人工智能技術(shù)以及它如何影響勞動(dòng)力、選舉和虛假信息的傳播有些“害怕”。他也警告說,人工智能的廣泛使用可能會(huì)帶來負(fù)面影響,這需要政府和社會(huì)共同參與監(jiān)管,他呼吁反饋和規(guī)則對抑制人工智能的負(fù)面影響非常關(guān)鍵。





