
“ 這是不是第一個被 AI 顛覆的職業?”我在小紅書上看到這么一個熱搜,點開發現, 人們說的是淘寶模特。
大概內容是說如果淘寶店主完全用 AI 穿拍,可以不用在模特、化妝師、攝影師身上反復掏錢了,而且 AI 是 24/7 在崗,出圖更是以秒為單位,成本低廉,打幾行 prompt(提示詞),把衣服圖樣導入,再調整、挑選就可以了。
著名牛仔裝品牌李維斯(Levi's)就曾宣布今年開始測試用 AI 模特來展示服裝。因為相比真人,品牌可以任意選擇模特的年齡、膚色、體態。
對淘寶模特來說,現在除了要和同行競爭,還要和 AI 競爭。
有意思的是,消費者對 AI 模特并不滿意,因為 “沒人味”,也 “展現不了真實的衣服質感”,因為衣服也“數字化”了,“是假的”。
但對于視覺工作者來說,AI 工具這般涌現讓我無比興奮,我開始研究如何做出 AI 模特,讓他們穿上我指定的服裝……
結果, 單個人形的效果讓我很滿意,于是我萌生了一個想法:干脆就做一個全員 AI 的虛擬時尚雜志。

我在小紅書上運營這本雜志 @AI Bubbles泡泡丨作者提供
初試:Midjourney V5 是能出片,但無法精確還原衣服
自 Midjourney 在三月底更新到了第五代后,這個 AI 畫畫工具又在全球的社交網絡上掀起一股狂潮——人們熱烈地分享自己的“攝像級”畫作,以及對應的提示詞,以下就是我用 Midjourney V5 生成的:



Midjourney 有“墊圖”功能,也就是上傳圖片讓 AI 參考用戶指定的場景、色彩、布局、物件等等。

那么,如果我 把衣服照片當作底圖發給 Midjourney,再用文本指令讓 AI 幫我生成一個人,是不是就能讓模特穿上我指定的衣服了?
一分鐘后,我得到了答案:能,但不完全能。

Prompt: A young girl in a rainbow tank top, knitted and crocheted, wearing yellow sun glasses, ink-washed ship tattoo, hazy, dreamlike quality.
(一個身穿彩虹背心的年輕女孩,針織和鉤編,戴著黃色太陽眼鏡,有墨水脫色感的船舶紋身,朦朧,有夢境般的質感。)
雖然圖片非常驚艷,但并不能 1:1 還原衣服的細節。 你看,袖套就不見了!(AI 工具的進化,簡直是以日為單位的,沒準 V6、V7 就能解決這個問題了。)
再試:自己訓練一個專屬模型?讓它記得住我喂的衣服單品
現有的畫畫 AI 并不能滿足我的“刁鉆”需求,有沒有可能自己整一個呢?我想到了“煉丹”。
煉丹就是人將大量靈材置入丹爐,最終凝煉成丹。到了 AI 繪畫界, 煉丹就是給 Stable Diffusion 這樣的大模型,專門投喂一個指定方向(比如二次元)的數據集,訓練出對應垂類的小模型,讓 AI 可以根據需求精準出圖。
丹要咋煉?有一種訓練方法叫 LoRA,你按照自己的喜好微調 Stable Diffusion 大模型,然后就能導出體積更小的模型,保存、傳播都更方便了。
比如,我的一個朋友就通過投喂了 200 余張明清兩代水墨大師的畫作,做出了國風墨心模型:

通過 LoRA 的腳本訓練,不光可以訓練風格模型,還可以訓練人物角色模型。在 CivitAI 上,就有人做了“瑞秋”Jennifer Aniston 的模型:

能記住風格和人物,那記一件衣服應該不難吧?我跑了一遍流程后,發現……還真的行。我先發出一些實驗成果:


接下來,我將手把手教大家訓練出一個服裝模型。 你千萬別剛滑幾屏就被勸退了,一步步跟著做,其實非常簡單。
注:本教程只適用于 windows 電腦
保姆級教程:如何訓練一個服裝模型
準備:看看自己的顯卡,安裝必備軟件
選顯卡的時候,主要看算力和顯存。其中,顯存的重要性主要體現在以下兩個方面:
- 訓練模型時有更大的顯存,就能用上更高清的素材;
- 生成圖片如使用放大算法,如果顯存夠大,放大倍數也能跟著上去。這樣,生成的圖片細節會更多,質量也會更高。
我在用的顯卡是 RTX 3070 8G,應對本文的訓練場景夠用了。我在網上找到了一張“常見顯卡 AI 跑圖性能、性價比表”,供大家參考:
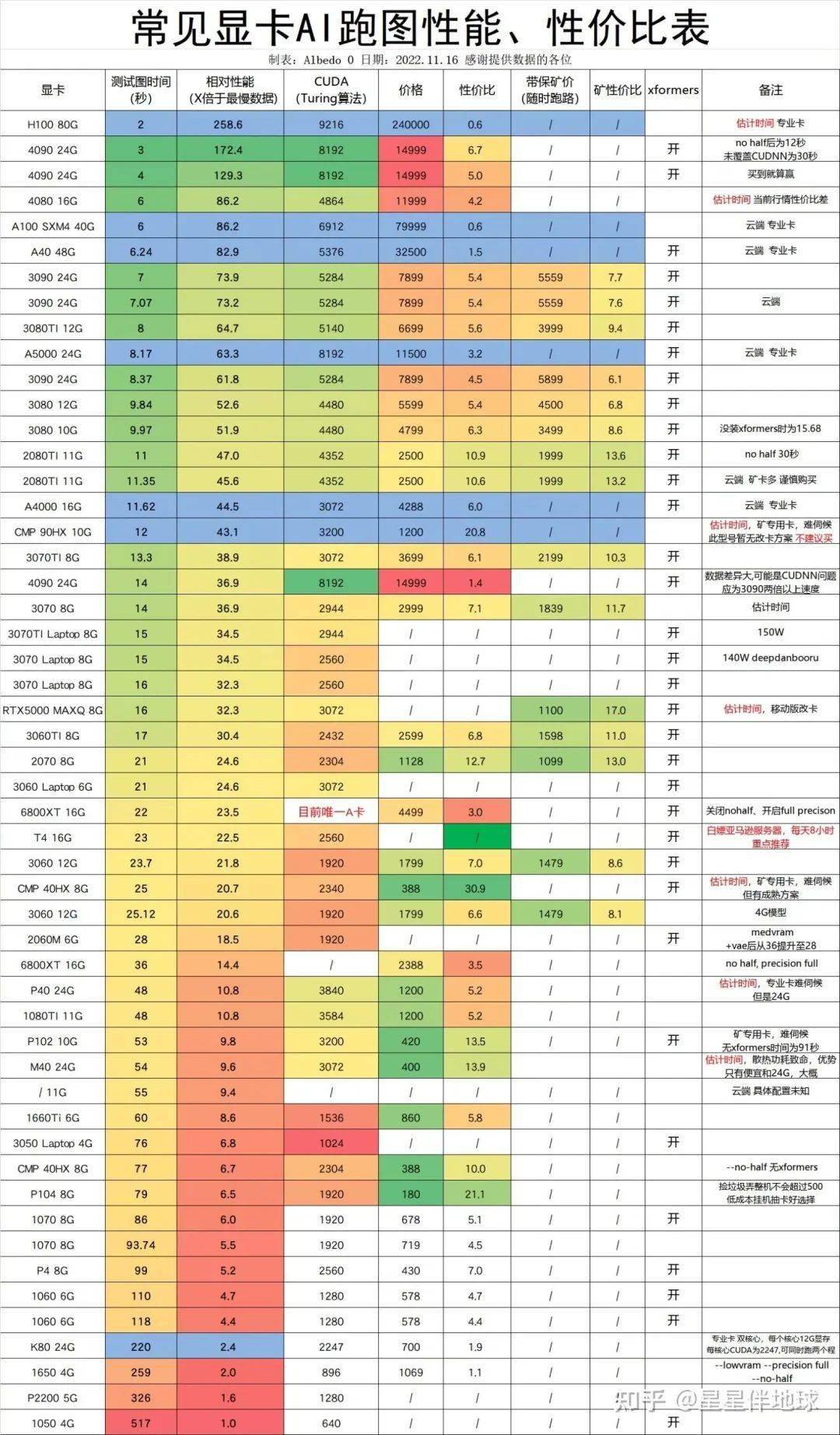
接下來,準備 Kohya_ss 版本的 LoRA 腳本需要的環境:
- 安裝 Python/ target=_blank class=infotextkey>Python 3.10 (https://www.python.org/ftp/python/3.10.9/python-3.10.9-amd64.exe) ,下載成功后,直接雙擊安裝,唯一需要注意的是勾選 【add python to the ‘PATH’ environment variable】 ;
- 安裝 Git (https://git-scm.com/download/win) ,找到你電腦的對應版本號,下載,安裝;
- 安裝 Visual Studio 2015, 2017, 2019 和 2022 的可再開發組件 (https://aka.ms/vs/17/release/vc_redist.x64.exe) ,下載,安裝。
在安裝好 Python 3.10 和 Git 后,搜索 Powershell,點擊右鍵,以管理員模式啟動,輸入 【Set-ExecutionPolicy Unrestricted】后回車,接著會跳出一段文字,選擇 【A】回答 【全是】即可,關閉該窗口。
然后,就可以安裝 Kohya_ss 版本的 LoRA (https://Github.com/bmaltais/kohya_ss)了。如果你想安裝在電腦上某個特定位置,先在地址欄處敲擊 【cmd】,回車,你會進入這樣一個命令窗:
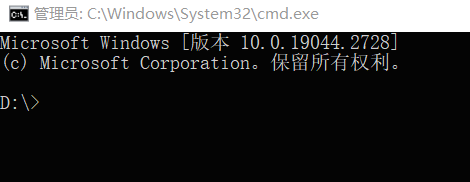
將以下代碼粘貼到窗口中:
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python -m venv venv
.venvsactivate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --use-pep517 --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .bitsandbytes_windows*.dll .venvLibsite-packagesbitsandbytes
cp .bitsandbytes_windowscextension.py .venvLibsite-packagesbitsandbytescextension.py
cp .bitsandbytes_windowsmain.py .venvLibsite-packagesbitsandbytescuda_setupmain.py
accelerate config
在執行 【accelerate config】后,它將詢問一些設置選項,請按照以下選項依次選擇:
This machine No distributed training NO NO NO all fp16
執行完后,就算裝好啦!
如圖,文件夾的名字叫 【Kohya】, 點進去后可以看到一個叫 【kohya_ss】的文件夾。
我們還需要新建一個文件夾,比如 【Lora Training Data】用來存放后續要用的訓練數據。
準備訓練:多找幾張圖
恭喜你成功到了這一步,接下來就是 fun part 啦!
先回答一個問題: 到底需要準備多少張圖做訓練呢?能不能就喂一張圖片?
我幫大家試了:


可見,AI 能學習到大致風格,模特穿著也像樣,但沒法還原花紋和細節。因為單張圖片能提供的信息有限。所以, 我們應該盡量給出衣服在各個角度的圖像。
以這一款動物帽子為例,我準備了三個角度的圖像。

雖然數量不多,但效果竟然還不錯:
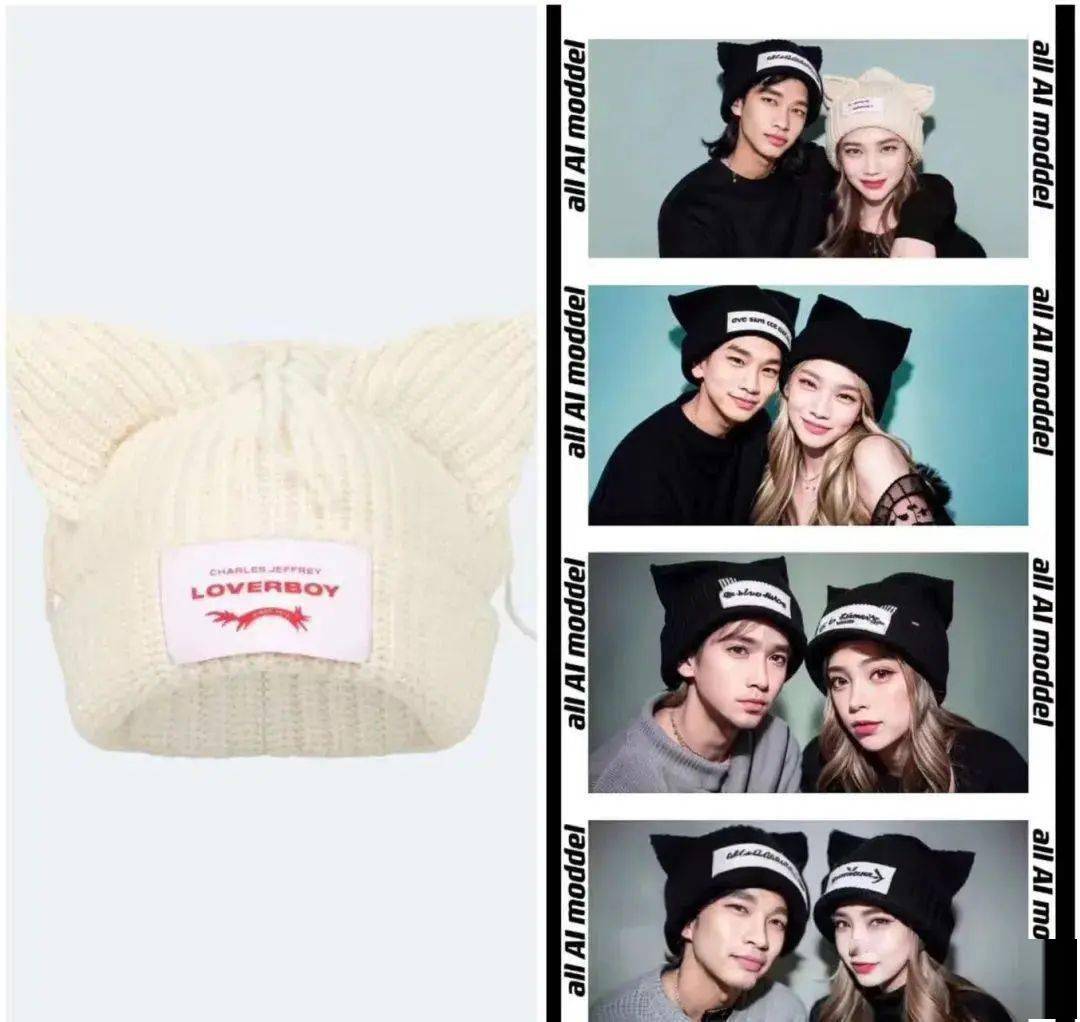
插播一句,圖像的清晰度會直接影響到訓練的質量, 如果圖片不夠清晰,我一般會先用 Topaz Gigapixel 這類 AI 修復工具將它先放大處理。
再插播一句, 為了讓 AI 更有針對性地捕捉和學習到目標對象,我還會裁剪圖片,盡量剪掉不必要的畫面, 讓目標單品更顯眼。
我們回到 【Lora Training Data】文件夾中,在里面創建一個新文件夾,隨便命名,我起的是 【dongwumaozi】(動物帽子),然后在其中創建 3 個子文件夾,依次是 【image】、 【log】和 【model】,如圖:
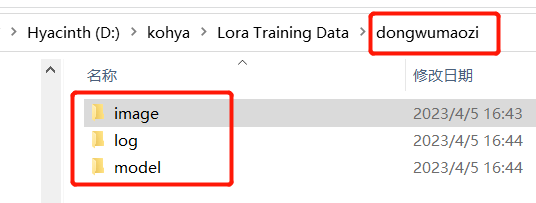
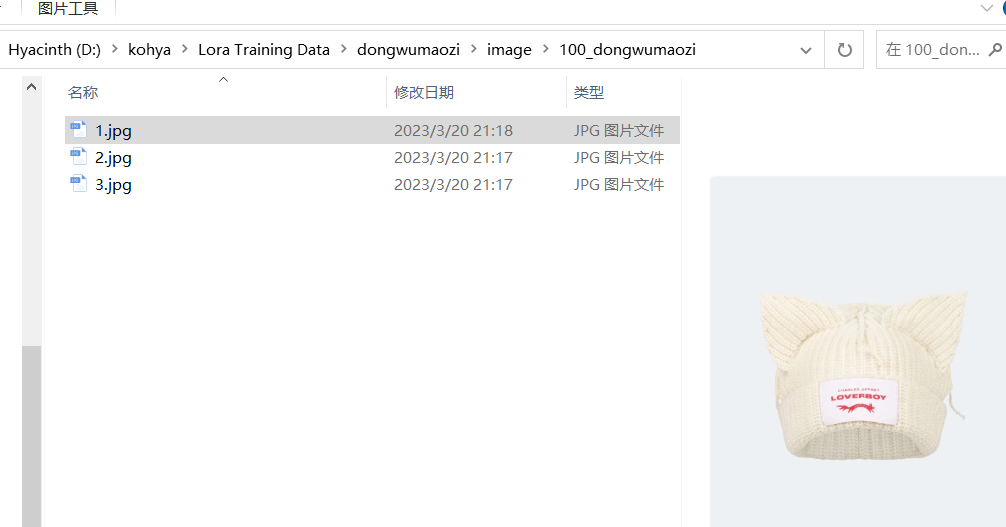
接著,你在 【image】這個文件夾里,再創建一個文件夾,格式是 【數字_訓練的概念】, 【數字】指的是圖片會被訓練多少遍,我寫了 【100】(100 是默認訓練次數,經試用,我覺得效果都不錯),AI 就會把我每張照片訓練 100 遍:
然后,將準備好的圖像剛進去:
讓 AI 自動給圖像標注
接下來,我們要打開 kohya 腳本。到 【kohya_ss】這個文件夾里,找到 【gui.bat】這個運行文件。
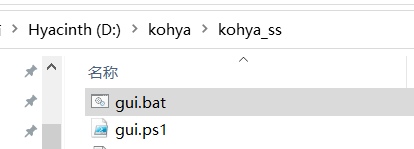
雙擊后,你會看到這么一個窗口:
復制其中的地址到瀏覽器中,回車。
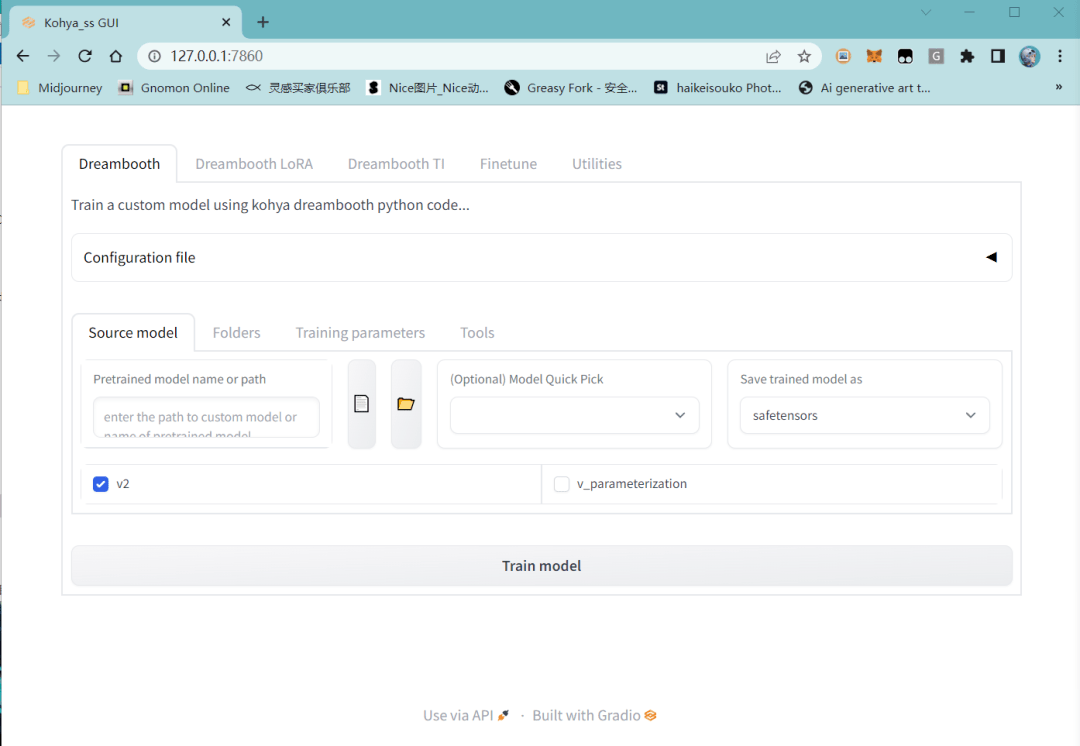
我們會在這個界面里,指導 AI 自動給圖像做標注
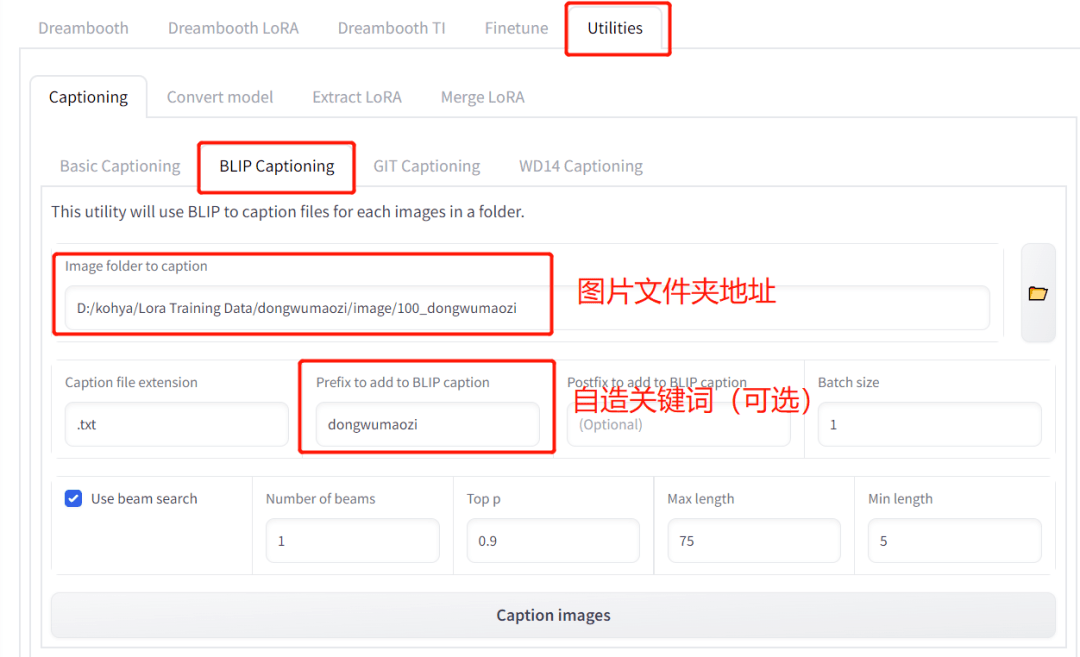
- 選擇上面的 【Utilities】 ;
- 在 【Captioning】 下選擇 【BLIP Captioning】 作為標注手段;
- 選擇剛剛放圖片的文件夾;
- (可選)在 【Prefix to add to BLIP aption】 處,看是否加入自造詞,方便在后續用模型時用這個詞更高效地做出對應概念,比如我這個案例里就用 【dongwumaozi】 作為一個自造關鍵詞;
- 點擊 【Caption images】 ,等待 AI 自動標注。
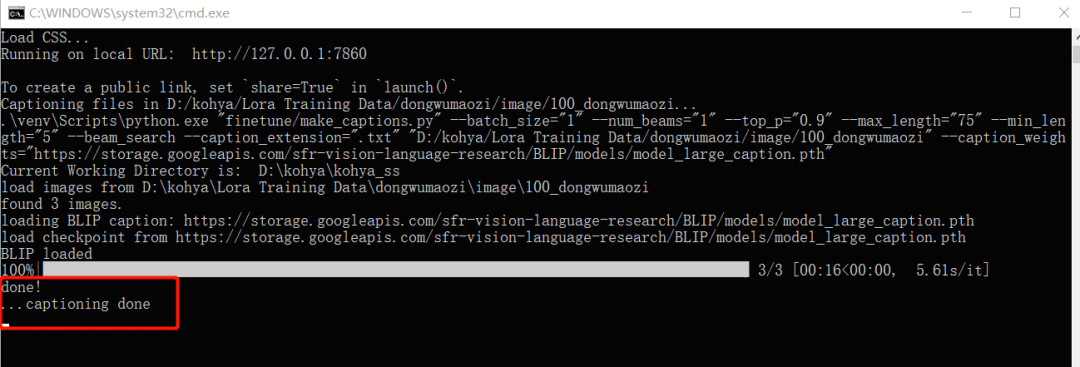
當你看到 【captioning done】后,AI 就算是標注好了。

回到 【image】文件夾后,就能看到和圖片名稱對應的 txt 文本描述了。如果你對機器標注的效果不太滿意,打開 txt 文檔手動修改,保存即可。
我也寫累了,但快能開始訓練了啊!
堅持住,最后再做些設置就可以開始訓練了!
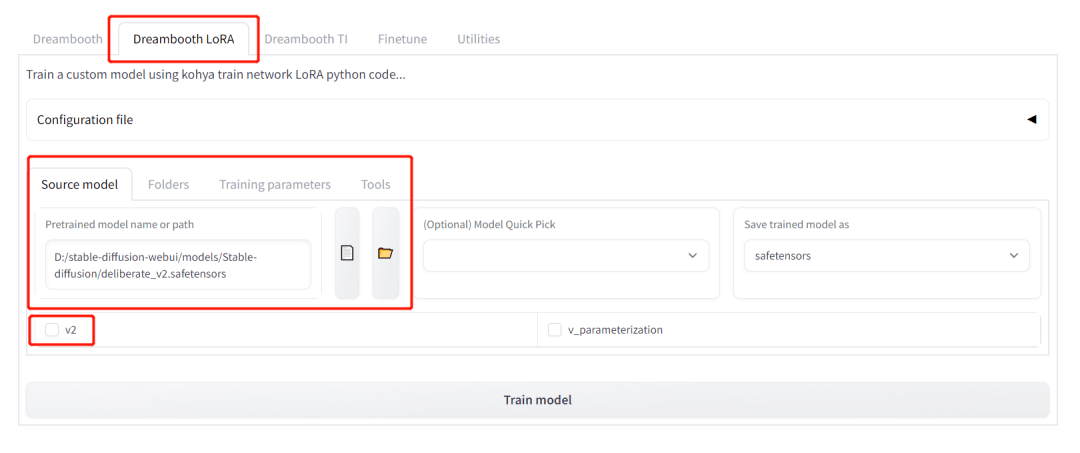
還是在剛才你執行 AI 標注的界面,點擊 【Dreambooth LoRA】,點擊 【Source Model】,選擇你想進行訓練的基礎模型,默認可選 Stable Diffusion v1.5(也可以是你在 CivitAI 上下載的其他與 Stable Diffusion v1.5 平行的模型),底模我用的是 Deliberate。
需要提前下載的模型
Stable Diffusion V1.5 下載地址:
https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
Deliberate 下載地址:
https://civitai.com/models/4823/deliberate
點擊 【Source Model】右側的 【Folders】,選擇此前我們設置的 【Lora Training Data】底下的 【image】、 【log】和 【model】這三個文件夾。
目前在訓練服裝 LoRA 上,我感覺默認的訓練參數效果已經很好,所以并沒有再做額外的更改、調整。如果你對訓練參數的設置感興趣,可以去看看 Kohya 腳本的官方教程 (https://www.YouTube.com/watch?v=k5imq01uvUY&t=1597s)。
接下來,你就可以點擊 【Train Model】煉丹了!
在 3070 上,訓練時長差不多在 30 分鐘左右,出去跑個步或者沖個澡,模型就訓練好啦!
一般默認參數訓練出來的 LoRA 大小在 9 M 左右,在 【model】這個文件夾里可以找到。
最后的最后,將 LoRA 文件拷貝到 【stable-diffusion-webui】的 【models】文件夾里對應的 【LoRA】文件夾處,再次重啟 WebUI,點選出對應的 LoRA 后,寫好關鍵詞就可以生成“淘寶模特”圖了:



以上圖片皆由該 LoRA 生成。拿最后一張圖舉例,我提供以下關鍵詞,供你參考:
正向關鍵詞:dongwumaozi, masterpiece, best quality, photorealistic, a couple wearing black, posing for the camera, ((posing)), hugging, hands posing, (((cute couple))), wearing dongwumaozi, thick black knitted wool cap with pig ear shape decoration (loveboy’s logo label), ((black)), ((detailed face)), cinematic lighting, film poster, photo shoot, depth of field, film screeshot, soft light
另外,也可以輸入一些常用的 負向關鍵詞,比如“bad hands”等, 讓 AI 消除這種生成可能。
以淘寶模特和時尚雜志開篇,后面全在講 Python
雖然在生成“動物帽子”這個案例中,喂 3 張圖就有不錯的效果, 但如果你的目標單品版型、材質都較為復雜,可能得備上 5 到 30 張不同角度的圖,才能更好還原。
這篇教程就當是拋磚引玉,我期待能有更多朋友分享自己的訓練經驗和效果。
就我個人而言,比起 AI 模特,我在買衣服時更希望看真人試穿,因為這樣材質和版型才更有參加價值。
不過,未來我可能會訓練一個自己的模型,然后再去疊加服裝的模型,看自己的試穿效果。
還在上學那會兒,我看日劇《校對女孩河野悅子》,劇里石原里美飾演的主角將不同服裝搭配剪下來再貼在一起,以此尋找靈感。那時,我覺得時尚編輯就像是魔法師。 而現在,AI 給了我更多創造的機會。
電商模特、虛擬時尚博主、服裝設計師的靈感助手……AI 還有更多可被激發的潛力。
現在涌現的 這些 AI,就像是一攤墨水,所有人似乎都可以來蘸一蘸,然后寫下一些特別的字跡。
參考文獻
[1] 開源圖像模型 Stable Diffusion 入門手冊(https://mp.weixin.qq.com/s/8czNX-pXyOeFDFhs2fo7HA)
作者:海辛
編輯:biu
本文照片如無特別指出,均為作者提供。





