

3月21日,比爾·蓋茨發表文章表示,自1980年首次看到圖形用戶界面以來,OpenAI的GPT人工智能模式是他所見過的最具革命性的技術進步。3月23日,OpenAI宣布目前正在逐步推出ChatGPT相關插件。
AI技術的應用比想象中更快,人工智能時代已經到來。各行各業暢想人工智能將在各領域帶來怎樣的改變,AI將給財富管理領域帶來怎樣的變革?本期我們采訪了道樂科技技術總監蔡樹彬,看看他對ChatGPT的技術解讀及金融營銷領域應用的猜想。
ChatGPT技術解析
簡單來說,ChatGPT(及GPT系列)是一種基于深度學習的自然語言處理技術。其基本原理是使用大規模的語料庫進行訓練,以獲得自然語言的語義和語法規則,從而生成自然流暢的對話。ChatGPT主要經由數據準備、模型訓練、模型優化和微調以及模型部署和應用這4個階段形成。
01 數據準備
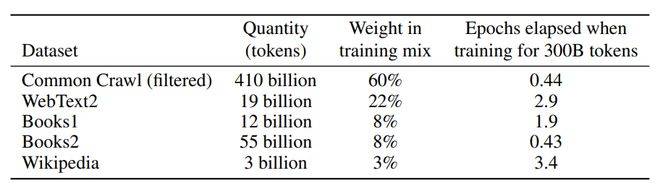
數據準備包括數據收集和數據清洗。OpenAI沒有披露ChatGPT的具體訓練數據集,但ChatGPT是在GPT-3的基礎上形成的,兩者的數據集大致相同。GPT-3的訓練數據集包括但不限于以下維基百科、新聞、社交媒體等超過45TB的數據集:
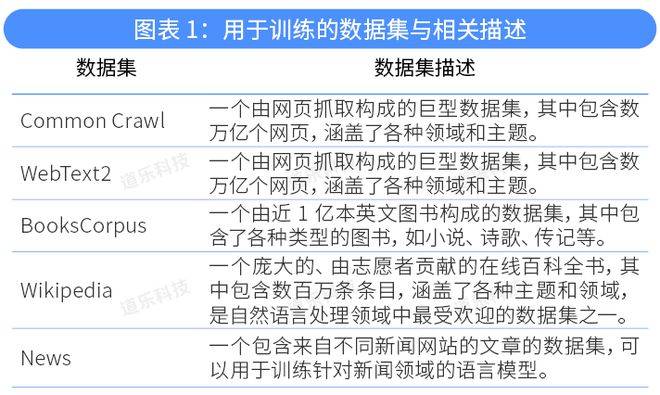
除了這些數據集外,ChatGPT 還利用了其他一些開源的自然語言數據集,如OpenWebText、WebText、Stories等,以擴展模型的語言覆蓋范圍和學習能力。這些數據集的廣泛性和多樣性可以幫助模型學習更豐富和復雜的語言知識和模式。ChatGPT 對這些數據集進行了清洗、預處理和格式化,以保證數據的質量和一致性,提高模型的訓練效果和性能。質量越高的數據集,如Wikipedia,具有更高的權重,在訓練中會被更多地使用到。
數據集信息
02 模型訓練
模型訓練階段,ChatGPT使用了Transformer網絡架構來訓練模型,以預測下一個詞或一段話的概率。Transformer網絡結構的核心是自注意力機制,該機制能夠使模型在計算每個位置的表示時,考慮到所有其他位置的信息。這種機制可以使模型更好地理解文本中的上下文關系,并且能夠捕捉到文本中的長期依賴關系。Transformer的模型架構如下圖所示:
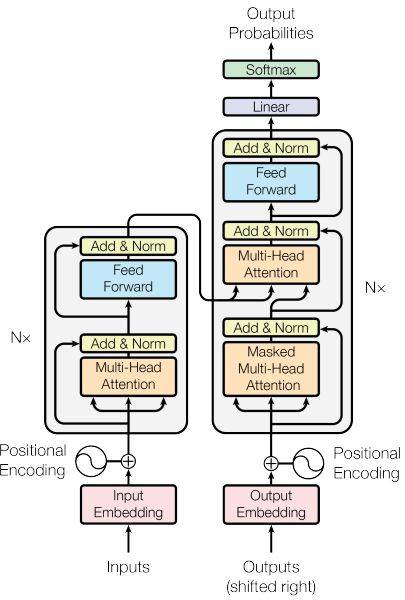
Transformer 模型結構
具體來說,Transformer的模型各部分功能如下:
1. 輸入嵌入(Input Embedding)
將輸入序列中的每個元素轉換成向量表示,通常使用預訓練的詞向量或字符向量來表示。
2. 位置編碼(Positional Encoding)
將輸入序列中每個元素的位置信息編碼到向量中,以便模型能夠識別其在序列中的位置。
3. 編碼器(Encoder)
將輸入序列經過多個編碼器層進行處理,每個編碼器層包含一個自注意力子層和一個全連接前饋神經網絡子層。在自注意力子層中,模型會計算每個輸入元素與其他元素之間的關系,以便更好地捕捉序列中的依賴關系。隨后,在全連接前饋神經網絡子層中,模型會對每個元素進行進一步的處理,以便模型更好的提取特征。
4. 解碼器(Decoder)
將編碼器的輸出序列經過多個解碼器層進行處理,每個解碼器層包含一個自注意力子層、一個編碼器-解碼器注意力子層和一個全連接前饋神經網絡子層。其中,編碼器-解碼器注意力子層會計算輸入序列和輸出序列之間的關系,以便實現翻譯等NLP任務。
5. 輸出層(Output Layer)
將解碼器的輸出序列經過一個全連接層進行處理,得到最終的輸出結果。通常使用SoftMax函數將輸出轉換為概率分布,以進行分類等任務。
總的來說,Transformer架構可以看作是對輸入序列進行編碼和解碼的過程,并使用自注意力機制捕捉序列中的依賴關系,以便更準確地處理長序列數據。
在這個處理過程中,語言文本中的單詞都被轉化為向量表示,這個向量就是詞向量。詞向量將單詞表示為一個固定長度的向量,其中每個維度代表了單詞在不同語境下的含義。向量之間的距離與詞語之間的語義相似度保持一致,這樣單詞之間的相似性和關聯性就可以在詞向量空間中獲得表示。這種方式將單詞轉換為計算機可以處理的數值形式,從而可以方便地進行各種自然語言處理任務。
ChatGPT是使用無監督學習的方式進行訓練的。在訓練ChatGPT模型時,需要定義一個損失函數,它可以幫助我們評估模型的性能并指導其學習——即訓練模型的目標是使損失函數最小化。
在ChatGPT的訓練中,損失函數一般是基于語言模型的交叉熵損失函數。交叉熵損失函數的目標是最小化模型預測的概率分布與實際概率分布之間的差異。兩者之間的差異越小,則代表模型的性能就越好。GPT最早期使用的是一種基于自回歸模型的語言模型,它通過最大化給定輸入序列的下一個單詞出現的概率來預訓練模型。自回歸模型的目標是最大化模型對無標注文本數據的似然性,即最大化模型在給定無標注文本數據下的對數似然函數。這樣,訓練出來的模型可以在當前輸入文本序列的基礎上,預測下一個單詞出現的概率。預測概率的一個重要指標就是似然性,即當前模型預測的結果與實際觀測值之間的相似程度。
在GPT-2,GPT-3中,在模型預訓練階段還引入了掩碼語言模型(MLM,Masked Language Model,和Bert中的一樣)。MLM的目標是在輸入序列中隨機遮蓋一些單詞,并讓模型預測這些被遮蓋的單詞。掩碼語言模型的似然函數表示為:
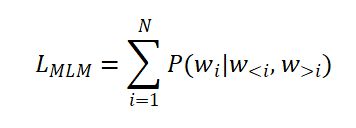
其中Wi表示第i個位置的被遮蔽的單詞,通常在文本中用一個特殊符號“[MASK]”標記,Wi表示第i個位置之后的單詞序列,表示文本序列的長度。使用MLM技術可以迫使模型學習到上下文信息,并在預測下一個標記時考慮到前面已經出現的標記。MLM損失函數的目標是最小化模型預測被替換標記的概率分布與真實標記的概率分布之間的差異,即使上述似然函數最大。
在訓練ChatGPT模型時,需要使用梯度下降算法對模型參數進行優化,以最小化模型的損失函數。ChatGPT 使用隨機梯度下降 (SGD) 的變體進行訓練,稱為 Adam 優化器。Adam 優化器結合了 SGD 和均方根傳播 (RMSProp) 優化算法的優點,在訓練過程中可以自適應地調整學習率,有助于模型更快、更準確地收斂。
從GPT-1到GPT-3,GPT模型的幾個重要參數都在迅速增大。詞向量的維度從768維快速增加到12888維;上下文窗口大小從1024增加到2048;每層Transformer的注意頭從12個增加到96個,Transformer的層數從12層增加到96層。模型參數從1.17億急劇增加到1750億,訓練的代價也從幾百萬美元增加到上億美元。隨著模型參數量急劇增大,模型甚至涌現出一些人們預料之外的能力。
03 模型優化和微調
模型微調的訓練數據來自多個NLP任務(如分類、相似、選擇和蘊含推理等)的公開數據集,這些數據集有明確的標注,規模相對較小。OpenAI未公開所使用的數據集,一些常用的NLP數據集列舉如下:

模型微調時只訓練輸出層和分隔符的嵌入值。利用分隔符使模型能使用相同的方式(預測下一個單詞)來處理不同的NLP任務。ChatGPT微調時使用的數據集包括Cornell Movie Dialogs Corpus、Persona-Chat、DailyDialog等,這些數據集覆蓋了不同領域和類型的對話,包括電影對話、個性化對話、日常對話等。通過使用這些數據集,ChatGPT可以更好地理解和模擬人類對話,從而提高其生成對話的質量和流暢度。
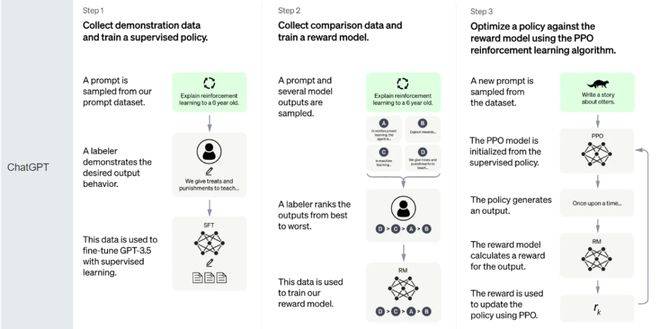
一般的模型在訓練時以預測下一個單詞的方式和最小化損失函數來建模,未能引入人的偏好和主觀意見。ChatGPT在模型優化和微調時使用了指令微調 (Instruction Fine-Tuning,IFT),有監督微調 (Supervised Fine-tuning, SFT)和人類反饋強化學習 (Reinforcement Learning From Human Feedback,RLHF)等方法來提高生成文本的質量。
指令微調可以讓模型學會以正確的方式遵循用戶的指令。指令范式由三個主要部分組成:指令,輸入和輸出。IFT 的訓練數據通常是人工編寫的指令及用語言模型自舉生成的實例的集合。在自舉時,先輸入一些指令樣本給LLM 用于提示它,隨后要求 LLM 生成新的指令、輸入和輸出。每一輪都會從人工編寫的樣本和模型生成的樣本中各選擇一些高質量指令輸入到模型中。然而經過指令微調的模型并不總是生成有幫助的和安全的響應,所以還需要在高質量的人類標注數據上使用SFT來微調模型,以提高有用性和無害性。
RLHF的思想是使用強化學習的方式直接優化帶有人類反饋的語言模型。RLHF使得在一般文本數據語料庫上訓練的語言模型能和復雜的人類價值觀對齊。RLHF的訓練過程可以分解為三個核心步驟:1.預訓練語言模型;2.收集數據并訓練獎勵模型;3.通過強化學習微調LM。RLHF的實現包括兩個重要的組成部分:獎勵模型和人類反饋收集。獎勵模型是一個用于評估生成文本質量的模型,它基于已有的訓練數據和人類反饋,學習生成文本的質量,并給出相應的獎勵或懲罰。獎勵模型的目標是最大化模型得到的總體獎勵。
在ChatGPT中,獎勵模型是通過對人類反饋進行監督學習得到的,這些反饋包括對生成文本的評價和改進建議。人類反饋收集是RLHF的另一個重要組成部分,它用于訓練獎勵模型并提供獎勵或懲罰。在ChatGPT中,人類反饋收集主要通過兩種方式實現。一種是在線收集人類反饋,即讓人類用戶在與聊天機器人對話時,對機器人生成的文本進行評價和反饋。另一種是離線收集人類反饋,即從已有的人類對話記錄中提取生成文本和人類反饋,用于獎勵模型的訓練和模型參數的微調。
最后使用近端策略優化 (Proximal Policy Optimization,PPO) 微調初始 LM 的部分或全部參數。PPO 算法確定的獎勵函數具體計算如下:將提示輸入初始 LM 和當前微調的 LM,分別得到了輸出文本,將來自當前策略的文本傳遞給 RM 得到一個標量的獎勵 ,將兩個模型的生成文本進行比較,計算差異的懲罰項。在每個訓練批次中,這一項被用于懲罰 RL策略生成的文本大幅偏離初始模型,以確保模型輸出合理連貫的文本。最后根據 PPO 算法,我們按當前批次數據的獎勵指標進行優化。PPO 算法是一種信賴域優化 (Trust Region Optimization,TRO) 算法,它使用梯度約束確保更新步驟不會破壞學習過程的穩定性。
ChatGPT 訓練流程
04 模型部署和應用
經訓練后獲得的模型,或換句話說就是訓練得到的權重和偏置矩陣等,則可以部署到所需的應用系統中并對外提供服務。OpenAI將模型部署在微軟的Azure云上后,圍繞該模型設計,應用了賬戶、計費、用戶界面等模塊,同時開放了API接口,形成了我們日常所接觸的ChatGPT。從下圖的接口示例可以看到,該接口使用起來非常簡單(與OpenAI網站的Playground頁面內容一一對應)。

ChatGPT是在大量語料上訓練出來的語言模型。通過綜合提煉這些語料上的語言上下文模式,它能很好地根據輸入,預測下一個詞或下一段話。也即它能通過提示語,生成回答。對比之前其他NLP模型,GPT有一個重要的設計目標是要在不針對特定任務進行微調的情況下,盡可能地提高模型的泛化能力,從而能在多個NLP任務中實現更好的表現。OpenAI的實驗表明,通過利用指令(instruction)和示例(shot),ChatGPT已經能很好地實現這個目標。另一方面,OpenAI通過分析數百萬行現有的代碼和文檔,訓練了Codex模型,學習編程語言的語法和編程模式。Codex模型學習了許多邏輯分析和處理的內容,被認為可能是引發了ChatGPT思維鏈(CoT)的主要原因。通過綜合運用指令、示例和思維鏈,我們可以讓ChatGPT產生更有意思的回答。
AI在金融營銷領域的應用
AI在金融領域早有過不少成功實施的先例。ChatGPT引起的這次AIGC浪潮,以內容生成為其主要特征,將在金融領域各個需要生成內容、使用內容、核對內容的地方獲得各種應用。例如,在金融營銷領域,AIGC可以輔助生成營銷材料;在投資者教育領域,AIGC可以生成專門針對投資者的金融教育材料;在社群運營領域,AIGC可以輔助快速生成回復等等。
以金融營銷領域為例,面對市場快速變化,基金公司需要及時發布、更新相關營銷資料。但基金客戶對基金產品的認識理解差異大,千人一面的營銷材料難以獲得投資者的廣泛認可;基金產品介紹涉及的數據、內容有高度的專業性要求,快速響應的營銷動作容易出現差錯;投資者適當性需要貫徹整個營銷過程,片面追求營銷效果容易導致出現合規性問題。在此背景下,提升營銷效率和精度的重要性日益顯現。
基金行業的精細化營銷可以從以下方面切入:以單客戶畫像為核心實施個性化策略;精準匹配基金標簽和客戶需求;高命中低頻次客戶需求;根據不同客戶特性和畫像推出多版本營銷話術,以期達到營銷方案快速測試、精準客戶觸達、精準效果營銷。為此,道樂科技推出“樂創”產品以賦能基金公司解決上述痛點。
樂創平臺是一款基于人工智能技術的金融營銷內容創作平臺,旨在幫助金融機構提升內容創作效率和內容質量,實現智能化生成文字和圖片等內容。
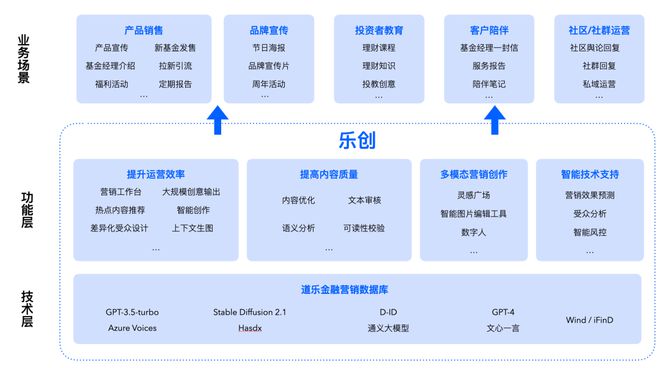
在樂創中,營銷人員可以根據不同的應用場景制定相應的工作臺,如產品宣傳、新基金發售、基金經理介紹、營銷活動策劃、投資者教育專欄等。在每個應用場景下,樂創均內置對應場景的輸入數據,用戶只需要輕松地配置所需內容即可高效地輸出針對不同需求的營銷內容,以幫助金融機構更精準和有效的營銷。
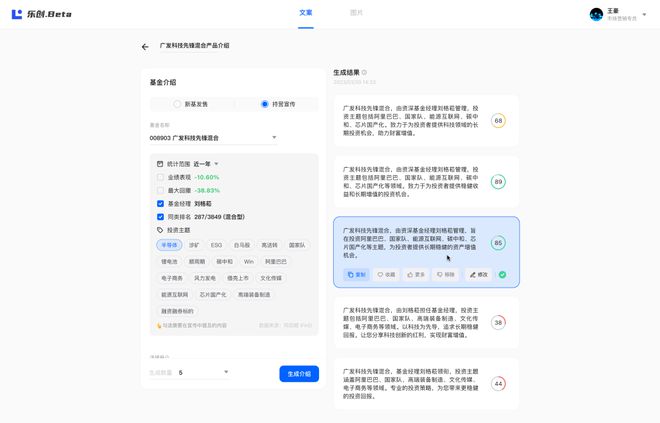
以持營基金內容營銷宣傳為例,用戶只需要根據頁面指示選擇需要宣傳的基金、指定面向的受眾、需要結合的時事熱點,以及配置輸出的規則,如內容人設、文本長度和文本數量等。
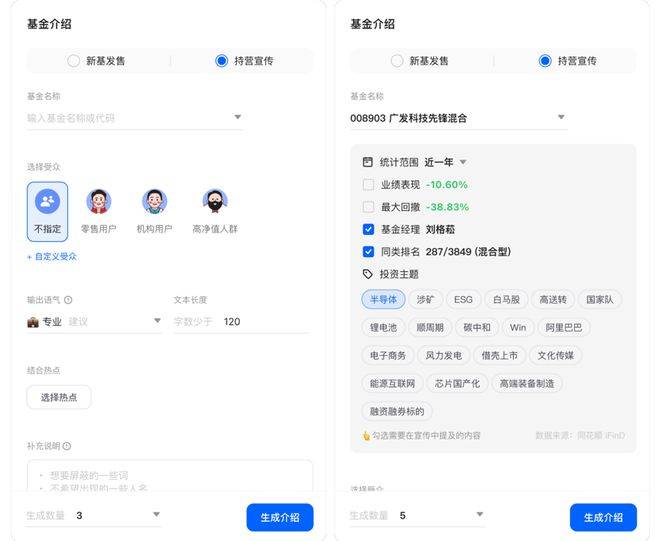
同時,在選擇基金后系統還會自動調用道樂金融營銷數據庫中關于該基金的信息,如在不同統計范圍之內的業績表現、最大回撤、基金經理、同類排名以及投資主題。
用戶可以按不同營銷場景的需要,擇優選取關鍵營銷內容,免去在數據平臺和內容創作平臺之間數據來回復制的麻煩。
金融機構往往同時面對多個目標客戶群體,如零售客戶、機構客戶、高凈值客戶等,需要為每個群體創作不同類型的內容。但由于資源和時間有限,很難同時保證每個群體的內容都能夠得到充分的關注和投入。
樂創的另一大特色是可以內置多個用戶畫像,通過一下點擊切換目標客戶群,調整營銷內容的輸出。
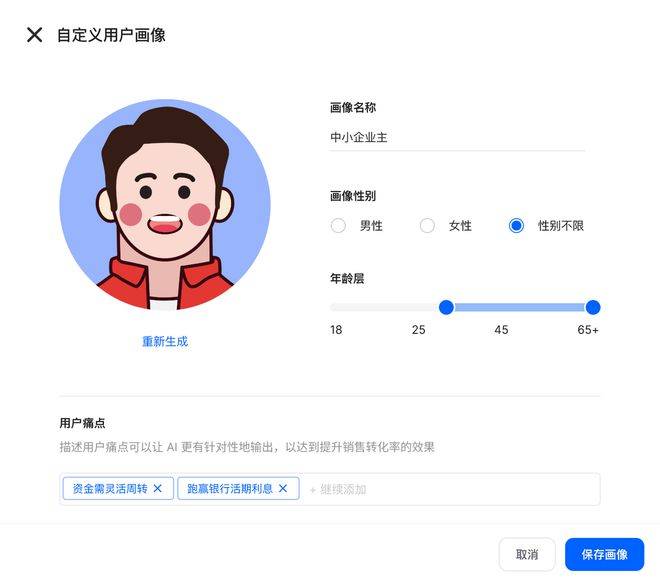
除了內置的畫像,還可以自定義創建無數用戶畫像,只需要輸入性別、年齡層即可對客戶進行精細化分類,還可以對用戶痛點進行設置,讓 AI 輸出的結果更有針對性,以達到提升轉化率的效果。
基金營銷往往與時下政策熱點、投資熱點相關,運營人員需要在不同平臺資訊中來回翻找可供參考的信息,還要抽象和提煉內容的觀點,無疑十分費時費力。為此,樂創整合多個財經平臺資訊供用戶搜索和參考。只需選取相關的熱點標題,樂創即會在后臺進行觀點提煉,幫助用戶節省時間和精力。同時,樂創還根據每一只基金進行相關熱點匹配,方便用戶篩選。

經過簡單的配置和輸入后,樂創會根據輸入的要求瞬間生成多個符合要求的結果,用戶可以根據不同的結果進行復制、收藏以及調優。
金融領域的內容營銷必須符合監管規定和保證信息安全,并且對表達專業性也有要求。因此,樂創會自動為每一條結果進行效果預測、受眾分析和智能風控,以降低內容審核所需的額外時間及成本,以及向不同受眾準確地傳達可信實用的信息。

上述是用戶如何通過樂創快速批量生產營銷短文案的說明。而基金公司除了短文案的生產,往往也需要深度的長文案輸出。以下則通過“指數投資價值分析”案例介紹如何在樂創中智能輸出長文案。
在樂創中,用戶只需要通過兩大步驟即可輸出一篇長文案:配置主題和審核調整。
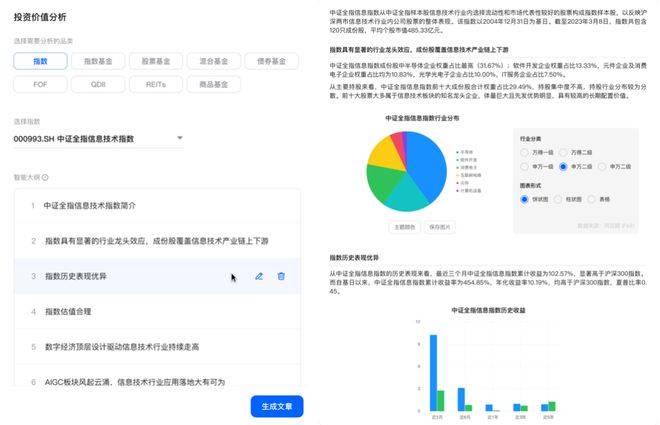
(1)配置主題。以“指數投資價值分析”為例,用戶需要選取需要分析的產品品類(本例中為“指數”),然后選擇具體標的(如“中證全指信息技術指數”),樂創即會在后臺生成智能大綱(下左圖)。用戶通過修改大綱內容確定最終內容輸出的框架,以控制輸出的內容,本例中“指數投資價值分析”的框架是“指數簡介”“指數成分分析”“指數業績分析”“指數估值表現”“與最新政策熱點結合”和“與當前熱點的結合”。(下右圖)
(2)審核調整。樂創會根據智能大綱補充相關細節,用戶在輸出后只需要審閱、調整輸出的內容。在此步驟中,樂創提供了先進的自然語言處理(NLP)技術,對生成的內容進行文本審核,包括語法、拼寫、句法等方面的檢查,避免因為文本錯誤導致內容質量下降;進行自動優化,包括調整詞匯、句子結構、段落結構等,以提高文章的整體質量和流暢性;進行語義分析,保證內容的邏輯性和通順性,避免產生歧義或不通順的內容;進行可讀性分析,分析文章的段落長度、句子長度、使用詞匯、句子結構等,提供具體的改進建議,以提高文章的易讀性和可懂性。如用戶對段落或句子仍不滿意,還可以使用樂創的智能改寫工具進行修改 —— 只需要告訴 AI 想怎樣修改即可,大大降低內容創作成本。
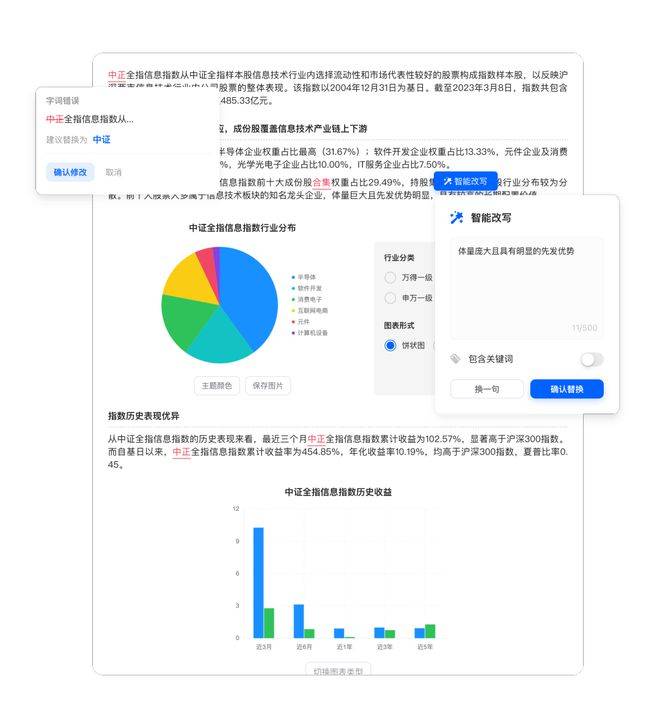
同時,樂創集成了道樂金融營銷數據庫中的內容,擁有強大的金融數據調取能力,用戶可以根據不同的場景需求插入不同的金融圖表。
總之,樂創是一款基于人工智能的全方位金融營銷內容創作解決方案,可以幫助金融機構實現智能化服務和個性化營銷,提高市場競爭力和業務盈利能力。
參考文獻[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.[2] Brown T, Mann B, Ryder N, etal. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.[3] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.[4] OpenAI. GPT-4 Technical Report. OpenAI, 2023.
作者簡介:蔡樹彬,中山大學計算機專業學士、博士。目前擔任道樂科技技術總監,深圳移動互聯網應用中間件技術工程實驗室主任。





