擊這里在線咨詢客服")

在中文文書(shū)方面,通義千問(wèn)的能力與 GPT-3.5 已不相上下,而在代碼寫(xiě)作方面,通義千問(wèn)則是大幅度的領(lǐng)先于文心一言。
01 通義千問(wèn)的誕生背景
阿里巴巴(BABA.US)作為中國(guó)最大的電子商務(wù)平臺(tái)之一,一直致力于利用人工智能技術(shù)提升用戶體驗(yàn)和商業(yè)效率。
在大模型領(lǐng)域,阿里巴巴早在2019年就推出了PLUG,一種基于預(yù)訓(xùn)練語(yǔ)言模型的通用對(duì)話框架,這是阿里巴巴對(duì)于LLM(Large language model大語(yǔ)言模型)領(lǐng)域的首次嘗試。
2021年11月,阿里達(dá)摩院宣布了M6大模型,一種基于10萬(wàn)億參數(shù)的多模態(tài)大模型,一躍成為了全球最大的 AI 預(yù)訓(xùn)練模型。
根據(jù)阿里巴巴的描述,M6大模型已經(jīng)在淘寶,支付寶,天貓等阿里巴巴旗下產(chǎn)業(yè)中應(yīng)用落地并取得了卓越成效。
但M6模型至今仍未面向公眾開(kāi)放,非阿里系的廠商也罕有應(yīng)用。直到2023年4月7日,阿里云推出了自研大模型“通義千問(wèn)”,并面向企業(yè)以及邀請(qǐng)用戶開(kāi)放。
根據(jù)官網(wǎng)描述,“通義千問(wèn)”是一個(gè)專門(mén)響應(yīng)人類指令的語(yǔ)言大模型,它可以理解和回答各種領(lǐng)域的問(wèn)題,包括常見(jiàn)的、復(fù)雜的甚至是少見(jiàn)的問(wèn)題。
它不僅是一個(gè)效率助手,也是一個(gè)點(diǎn)子生成機(jī),可以幫助用戶完成各種任務(wù),如寫(xiě)郵件、寫(xiě)文章、寫(xiě)腳本、寫(xiě)情書(shū)、寫(xiě)詩(shī)等。它還可以提供娛樂(lè)功能,如講笑話、唱歌等。
在大預(yù)言模型大熱的今天,通義千問(wèn)自然是處于風(fēng)口浪尖之上。
國(guó)內(nèi)的各大公司都想在該領(lǐng)域分一杯羹,百度(BIDU.US)是第一個(gè)吃螃蟹的公司,其在2023年3月16日發(fā)布了“文心一言”系列的“多模態(tài)”模型(雖然我們現(xiàn)在知道其實(shí)它的圖片生成能力其實(shí)是來(lái)源于另一個(gè)百度開(kāi)發(fā)的模型)。而阿里巴巴選擇了避其鋒芒在四月發(fā)布全新針對(duì)聊天內(nèi)容優(yōu)化的通義千問(wèn)。
由于阿里巴巴吸取了此前文心一言的慘淡場(chǎng)景,選擇了僅對(duì)部分受邀媒體和企業(yè)開(kāi)放服務(wù)。筆者成功拿到了此次的內(nèi)測(cè)資格。
02 通義千問(wèn)能力測(cè)試
對(duì)于非多模態(tài)的語(yǔ)言模型,主要可以從三個(gè)方面考量其能力:文字編排能力、Coding能力和邏輯能力。
為了進(jìn)一步找到當(dāng)前各大LLM之間的差距,本次還加入了GPT-4共同比較。
文書(shū)能力測(cè)試
作為最基礎(chǔ)的語(yǔ)言組織能力測(cè)試,我們先讓幾個(gè)競(jìng)品各自寫(xiě)一份請(qǐng)假條:

圖一 通義千問(wèn)的回答(▲點(diǎn)擊查看大圖)

圖二ChatGPT的回答(▲點(diǎn)擊查看大圖)

圖三GPT-4的回答(▲點(diǎn)擊查看大圖)

圖四 文心一言的回答(▲點(diǎn)擊查看大圖)
面對(duì)基礎(chǔ)的語(yǔ)言文字問(wèn)題,四款A(yù)I工具都可以看似按照需求的完成任務(wù),其中通義千問(wèn)的語(yǔ)法和措辭最為接近國(guó)人的口吻。
再細(xì)看一下,文心一言給出的回答為:“我已經(jīng)請(qǐng)假了兩天,并且目前感覺(jué)已經(jīng)有所好轉(zhuǎn)。但是,我不想因?yàn)樽约旱纳眢w問(wèn)題而影響到工作,因此我希望能夠請(qǐng)一周的病假。”
在我們并未給出任何多余的 prompt 的情況下給自己增加了情景,這也可以算LLM的“幻覺(jué)”通病。
再來(lái)看下一個(gè)問(wèn)題:請(qǐng)續(xù)寫(xiě)《紅樓夢(mèng)》中林黛玉倒拔垂楊柳的故事。

通義千問(wèn)(▲點(diǎn)擊查看大圖)

ChatGPT(▲點(diǎn)擊查看大圖)

GPT-4(▲點(diǎn)擊查看大圖)

文心一言(▲點(diǎn)擊查看大圖)
在此處我們要求四個(gè)模型分別續(xù)寫(xiě)了一個(gè)《紅樓夢(mèng)》中不存在的情節(jié),林黛玉倒拔垂楊柳。
其中GPT-4的文風(fēng)最為接近《紅樓夢(mèng)》,通義千問(wèn)的續(xù)寫(xiě)也貼合了原來(lái)的人設(shè)和背景,較為符合的滿足了我們的要求。ChatGPT的回答則是略有偏差。
此處文心一言就直接讓林黛玉穿越回現(xiàn)代了,并且成功讓她成為了一名醫(yī)生,不僅丟了人設(shè)還丟了故事背景。
下面要求四個(gè)模型生成一篇完整的文章:請(qǐng)以“AIGC變革內(nèi)容生產(chǎn)模式”為題寫(xiě)深度文章。

通義千問(wèn)(▲點(diǎn)擊查看大圖)

ChatGPT(▲點(diǎn)擊查看大圖)

GPT-4(▲點(diǎn)擊查看大圖)

文心一言(▲點(diǎn)擊查看大圖)
四款 AI 都正確的給出了 AIGC 這一名詞的概念,并且理解了用戶的需求。由于通義千問(wèn)給出的回答較長(zhǎng),本次要求他生成500字的文章。
其中 GPT-4 比較獨(dú)特,它選擇了分點(diǎn)式的總結(jié)內(nèi)容,而其余的則選擇了更常規(guī)的通稿類型。本次四個(gè) AI 都能夠較為出色的完成任務(wù)。
代碼能力測(cè)評(píng)
我們?cè)賮?lái)看到代碼能力,在這一個(gè)環(huán)節(jié),由于問(wèn)題比較簡(jiǎn)單GPT系列都可以出色完成,因此不加入GPT系列參與對(duì)比。
先來(lái)個(gè)簡(jiǎn)單的:用 Python/ target=_blank class=infotextkey>Python 實(shí)現(xiàn)冒泡排序。

通義千問(wèn)(▲點(diǎn)擊查看大圖)
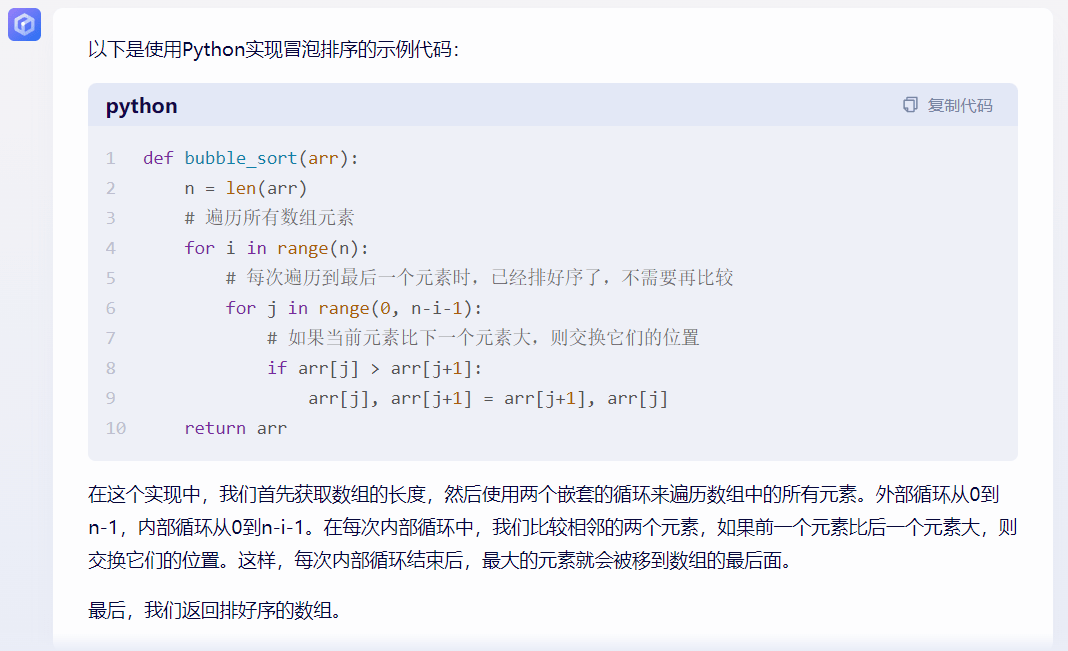
文心一言(▲點(diǎn)擊查看大圖)
提問(wèn):編寫(xiě)一個(gè)SQL查詢,查詢某個(gè)數(shù)據(jù)庫(kù)表中最近一個(gè)月的記錄,并按照某個(gè)字段進(jìn)行降序排列。

通義千問(wèn)(▲點(diǎn)擊查看大圖)
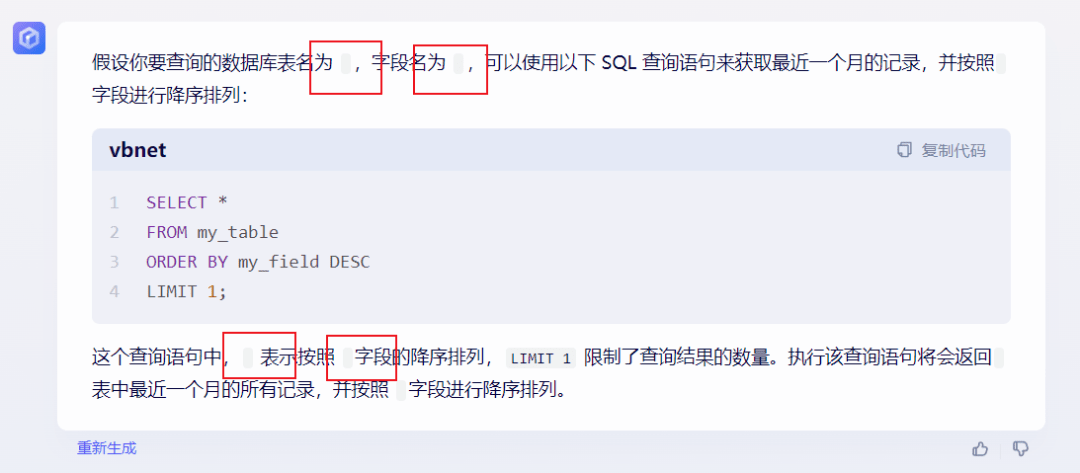
文心一言(▲點(diǎn)擊查看大圖)
在這個(gè)問(wèn)題上,文心一言仍不敵通義千問(wèn)無(wú)法完成需求。紅框內(nèi)圈出的就是文心一言的重大問(wèn)題所在。
來(lái)到下一個(gè)問(wèn)題:使用函數(shù)遞歸的方法實(shí)現(xiàn)斐波那契數(shù)列的計(jì)算,并返回前n個(gè)斐波那契數(shù)。


通義千問(wèn)(▲點(diǎn)擊查看大圖)

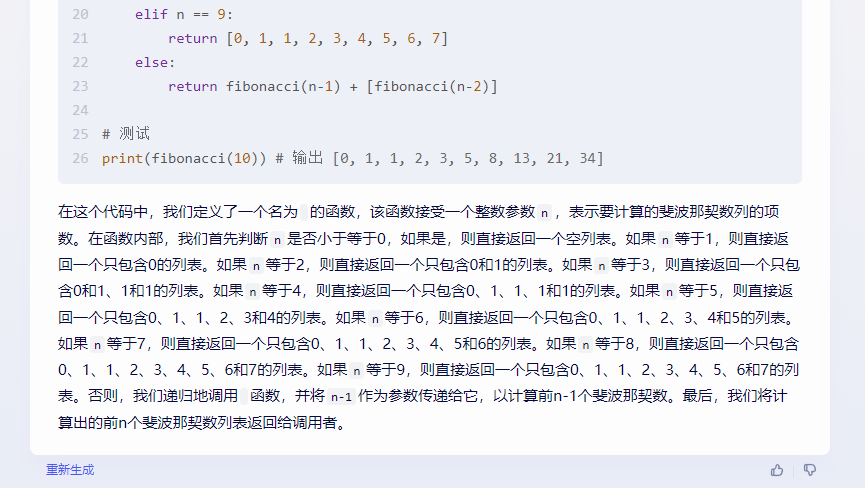
文心一言(▲點(diǎn)擊查看大圖)
文心一言在這個(gè)問(wèn)題中表現(xiàn)得很可笑。文心一言直接選擇了將斐波那契額數(shù)列硬編碼進(jìn)入了代碼實(shí)現(xiàn)了O(1) 的時(shí)間復(fù)雜度,并沒(méi)有完成我們需要的使用遞歸方法的需要。
通義千問(wèn)的回答則是滿足了問(wèn)題的需求而且給出了詳細(xì)的代碼解析和輸出結(jié)果。
在代碼寫(xiě)作能力上來(lái)看,文心一言也不敵通義千問(wèn)。上述幾個(gè)問(wèn)題選取的十分基礎(chǔ),但是文心一言仍然無(wú)法滿足需求。
可能是因?yàn)榘俣鹊拇a庫(kù)的缺乏。得益于阿里長(zhǎng)期深耕于云領(lǐng)域等,其本身積累了豐富的資源和人次,在代碼寫(xiě)作方面顯著強(qiáng)于文心一言。
03 測(cè)評(píng)總結(jié)
結(jié)論1:通義千問(wèn)是國(guó)內(nèi)最接近ChatGPT水平的本土化LLM。
經(jīng)過(guò)上述測(cè)試,我們發(fā)現(xiàn)就目前而言,“通義千問(wèn)”實(shí)際上是國(guó)內(nèi)最接近ChatGPT(GPT-3.5)水平的本土化LLM。
盡管百度率先推出了文心一言試圖搶占高點(diǎn),但模型水平一般,回答水平只能與Meta公司前段時(shí)間泄露的LLaMA 13B未針對(duì)對(duì)話調(diào)參前的水平相媲美。
而通義千問(wèn)和文心一言對(duì)比起GPT-4時(shí),即使忽略都欠缺的多模態(tài)能力,在文字方面上來(lái)看二者均和GPT-4有較大差距。
結(jié)論2:通義千問(wèn)在中文寫(xiě)作和代碼編寫(xiě)方面領(lǐng)先于文心一言。
LLM模型常見(jiàn)的“幻覺(jué)”(即回答錯(cuò)誤事實(shí))現(xiàn)象在文心一言上表現(xiàn)得尤為明顯。當(dāng)前在中文寫(xiě)作方面,通義千問(wèn)的能力與GPT-3.5已不相伯仲,而在代碼編寫(xiě)方面,通義千問(wèn)則大幅領(lǐng)先于文心一言。
結(jié)論3:百度擁有龐大的語(yǔ)料庫(kù)優(yōu)勢(shì),但文心一言表現(xiàn)不盡如人意。
巨型語(yǔ)料庫(kù)是LLM訓(xùn)練中不可或缺的部分,同時(shí)還需避免受到“有毒”語(yǔ)料的影響。
從這個(gè)角度來(lái)看,擁有龐大語(yǔ)料庫(kù)的百度天生具備優(yōu)勢(shì),可以利用旗下的問(wèn)答、百科和抓取的網(wǎng)頁(yè)信息作為語(yǔ)料。然而,目前文心一言的表現(xiàn)仍然不盡如人意。
結(jié)論4:通義千問(wèn)在某些場(chǎng)景下的中文文本能力超過(guò)了ChatGPT。
相較之下,阿里經(jīng)過(guò)一個(gè)月的沉淀后推出的產(chǎn)品在多個(gè)維度上擊敗了文心一言。
在某些場(chǎng)景下,得益于本土化語(yǔ)料資源優(yōu)勢(shì),通義千問(wèn)的中文文本能力甚至部分超過(guò)了ChatGPT。一些常見(jiàn)的文書(shū)工作在進(jìn)行好事實(shí)性核查之后可以交由通義千問(wèn)處理。
結(jié)論5:GPT-4具備強(qiáng)大的多模態(tài)能力,而國(guó)產(chǎn)大模型仍然不具備多模態(tài)能力。
再來(lái)看多模態(tài)場(chǎng)景。從GPT-4的論文中,我們得知其已具備強(qiáng)大的多模態(tài)能力,包括圖像的輸入和輸出。
GPT-4能夠理解圖像含義并根據(jù)文字/圖像指令完成任務(wù),展示出Transformer的實(shí)力。
百度文心一言的“多模態(tài)”能力更像是虛假的多模態(tài),其圖像能力來(lái)自于另一個(gè)大模型“文心一格”。而通義千問(wèn)則是明確表示沒(méi)有多模態(tài)能力。
結(jié)論6:AIGC成為了未來(lái)發(fā)展的模式,各互聯(lián)網(wǎng)巨頭都在爭(zhēng)奪戰(zhàn)場(chǎng),新興職業(yè)如Promopter也在興起。
當(dāng)前的所有趨勢(shì)就是“面向GPT”,AIGC儼然成為了未來(lái)發(fā)展的模樣。
不同于元宇宙等項(xiàng)目,AIGC是可以切實(shí)提升人類生產(chǎn)效率的工具,互聯(lián)網(wǎng)大廠都看到了這個(gè)賽道的未來(lái),不約而同的來(lái)到這個(gè)戰(zhàn)場(chǎng)上激烈廝殺,基于AI的Promopter這種職業(yè)也正在興起。面向GPT編程,面向GPT寫(xiě)作,面向GPT繪畫(huà),面向______。這個(gè)空,就是未來(lái)。





