
一、背景
關于sql調參數、數據傾斜可以搜到很多文章,本文主要講解常見的SQL開發場景、“奇葩”SQL寫法并深入執行計劃,帶你了解如何快速寫出高效率SQL。
二、高效寫法
1、union直接使用效率低嗎?
- 場景介紹
在一些業務場景中,需要將多份數據合并在一起,比如要取客戶信息,客戶信息存在兩張表中有交叉(假設兩張表中交叉的客戶信息是一致的),需先將兩份數據合并在一起。
- 寫法&執行計劃探查
因為兩張表中數據有交叉,所以需要會先將數據去重,然后再去join。去重方式常見于:
SELECT cst_id,cst_info
FROM (
SELECT cst_id,cst_info
FROM @cst_info_a
WHERE dt = '${bizdate}'
UNION
SELECT cst_id,cst_info
FROM cst_info_b
WHERE dt = '${bizdate}'
)cst_info
;
這種情況下,會理解為先將兩兩份數據不做任務處理就合并在一起,導致shuffle、中間臨時寫入的數據量和讀取數據量和數據源都是一致的,然后再去做去重。因為數據量在中間過程沒有沒有減少,所以效率相對來說會低一些。現在來看一下執行計劃:
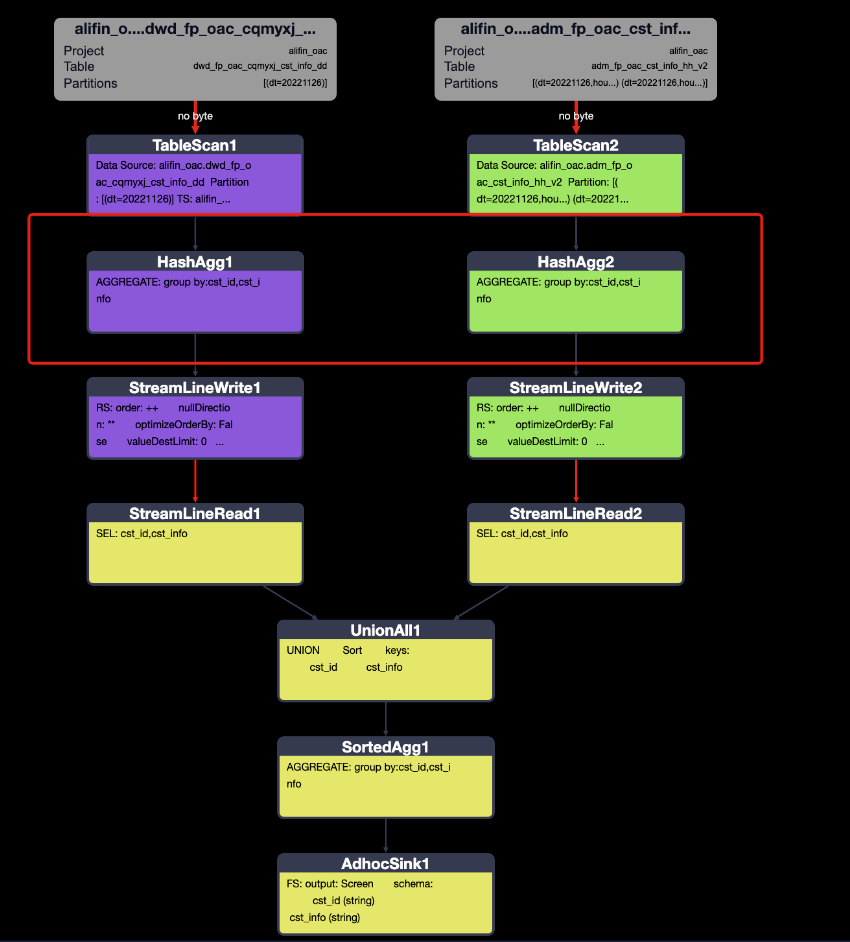
發現執行計劃是做過的優化的,已經是最優執行計劃了。
接下來按照理解中的高效sql寫法來看一下執行計劃:
-- 方式一
SELECT cst_id,cst_info
FROM (
SELECT cst_id,cst_info
FROM @cst_info_a
WHERE dt = '${bizdate}'
GROUP BY cst_id,cst_info
UNION
SELECT cst_id,cst_info
FROM @cst_info_b
WHERE dt = '${bizdate}'
GROUP BY cst_id,cst_info
)cst_info;
--方式二
SELECT cst_id,cst_info
FROM (
SELECT cst_id,cst_info
FROM @cst_info_a
WHERE dt = '${bizdate}'
GROUP BY cst_id,cst_info
UNION ALL
SELECT cst_id,cst_info
FROM @cst_info_b
WHERE dt = '${bizdate}'
GROUP BY cst_id,cst_info
)cst_info
GROUP BY
cst_id,cst_info;
兩種寫法的執行計劃一致,如下:
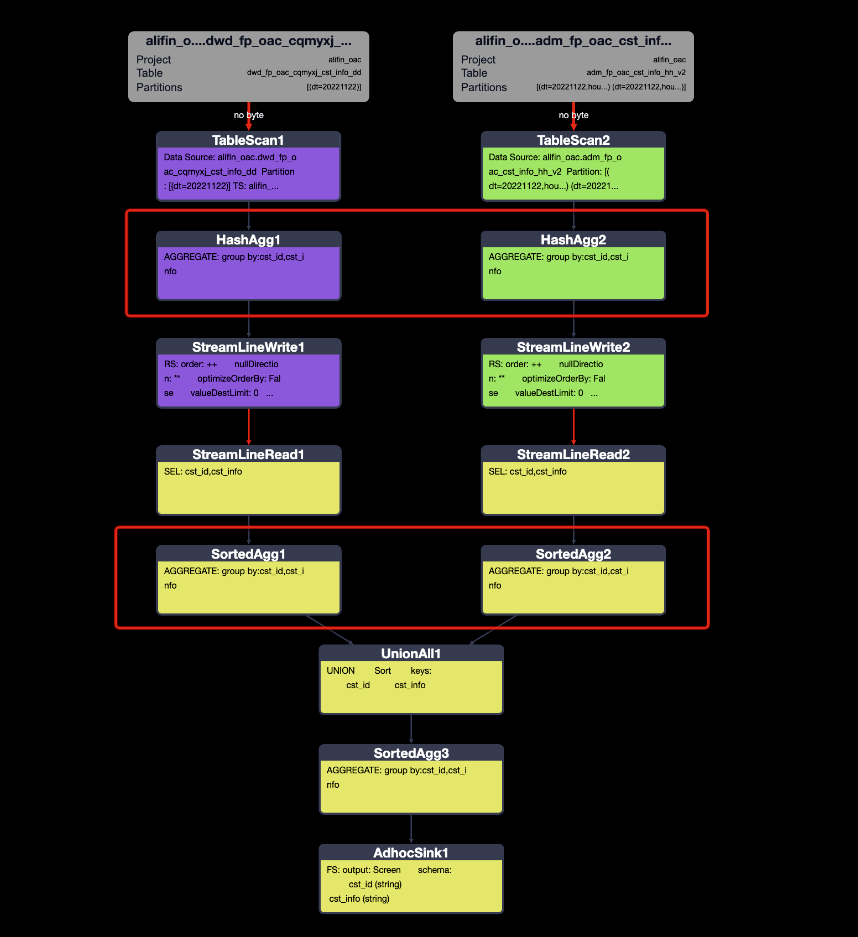
發現自己另外加的聚合處理,反而增加了復雜度。
- 總結
ODPS已經對union做過優化,直接使用就可以了。并且對三個及以上的(X張)表做union,執行計劃是X個MAP任務+1個REDUCE任務;不會像hive是X個MAP任務+(X-1)個REDUCE任務,還需要調整SQL才能實現最優的執行計劃。
2、count distinct真的慢嗎?
- 場景介紹
在開發過程中,經常會遇到一些數據探查,比如探查資產信息表中,有多少用戶數,探查過程中經常會用到count distinct,那么它的效率如何?
- 寫法&執行計劃探查
探查資產信息表中近5天的用戶數,常見的寫法與常規認為的優化寫法:
--選擇近5天的資產來看
--常見寫法,count distinct寫法
SELECT
COUNT(DISTINCT cst_id) AS cst_cnt
FROM @pc_bill_bal
WHERE dt BETWEEN '${bizdate-5}' AND '${bizdate}'
;
--優化寫法
SELECT COUNT(1) AS cst_cnt
FROM (
SELECT
cst_id
FROM @pc_bill_bal
WHERE dt BETWEEN '${bizdate-5}' AND '${bizdate}'
GROUP BY
cst_id
)base
;
一般都會認為直接count distinct效率很低,是這樣嗎?接下來看一下兩個執行計劃對比:
- 常規寫法
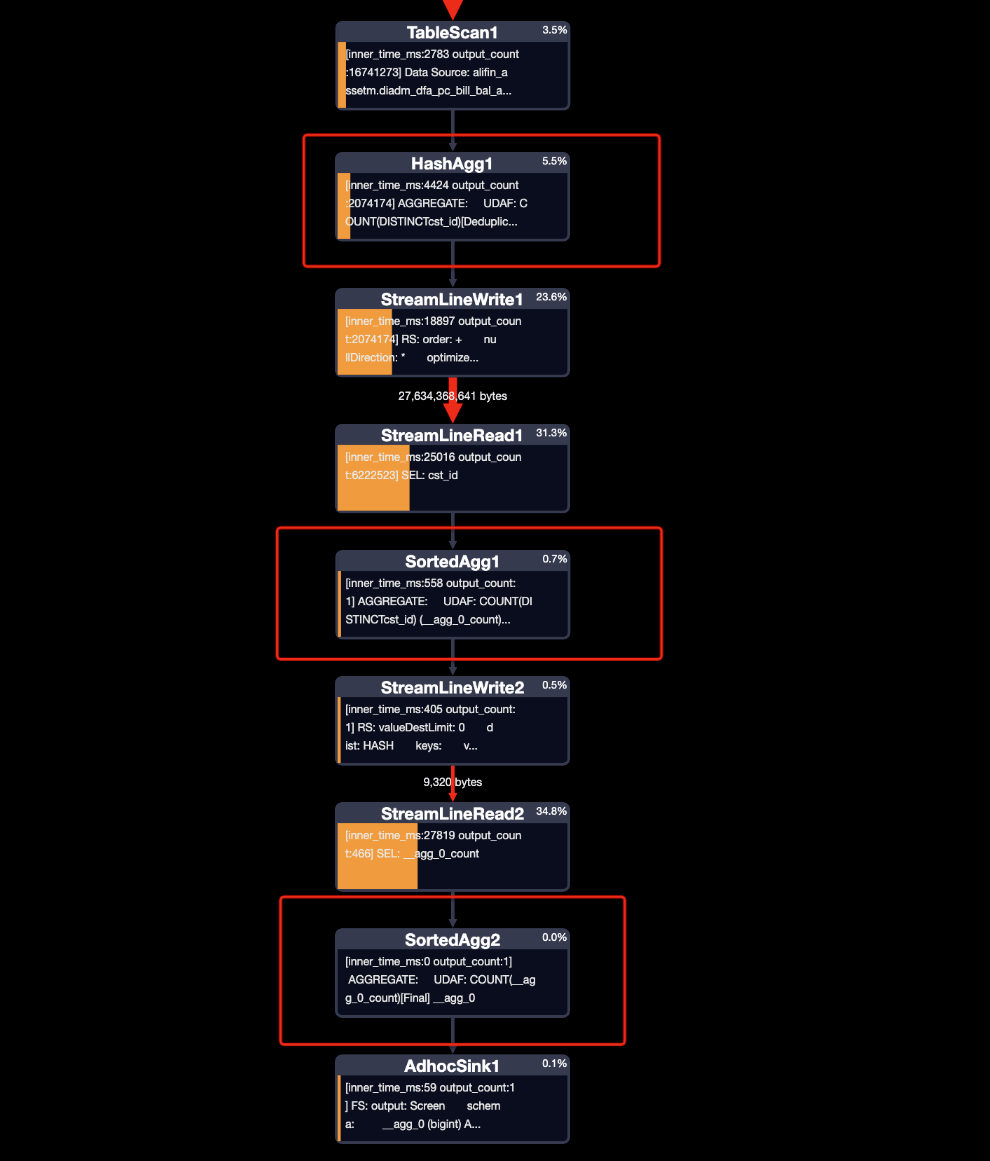
- 優化寫法

從執行計劃可以看出,直接count distinct的寫法被優化成了兩次去重處理,一次計算總和,并不是直接全量來去重計算。再看優化寫法,兩次去重處理,兩次計算總和,反而比count distinct多了一步,不過運行效率還是很快的。最后看一下運行時間和消耗資源,常規寫法比優化寫法快了28%(62s、86s),資源消耗少28%。
那么count distinct可以肆無忌憚的使用了嗎?
接下來看另外一種場景,探查資產信息表中近5天每天的用戶數,常見的寫法與常規認為的優化寫法:
--選擇近5天的資產來看
--常見寫法,count distinct寫法
SELECT
dt
,COUNT(DISTINCT cst_id) AS cst_cnt
FROM @pc_bill_bal
WHERE dt BETWEEN '${bizdate-5}' AND '${bizdate}'
GROUP BY
dt
;
--優化寫法
SELECT
dt
,COUNT(cst_id) AS cst_cnt
FROM (
SELECT
dt
,cst_id
FROM @pc_bill_bal
WHERE dt BETWEEN '${bizdate-5}' AND '${bizdate}'
GROUP BY
dt
,cst_id
)base
GROUP BY
dt
;
看一下這種場景下兩種執行計劃對比:
- 常規寫法(此處額外看一下分配的task)


- 優化寫法


從執行計劃可以看出,直接count distinct的寫法進行了一次去重,就將3億條數據給到了5個task進行去重計算總和,每個task的壓力相當大。再看優化寫法,兩次去重處理,兩次計算總和,每一步都運行的很快,沒有長尾。最后看一下運行時間和消耗資源,常規寫法比優化寫法慢了26倍,資源消耗多出2倍。
- 總結
ODPS對count distinct做了執行計劃優化,但是限于從數據源只讀取1個字段的情況下。當從數據源讀取了多個字段時,應將count distinct寫法改為group by count寫法。
3、多張大表join提速(聚合類型)
- 場景介紹
在日常的開發工作中,經常會遇到多張表關聯取屬性的情況,比如計算用戶在過去一段時間A、B、C...N行為的次數,或者是在資管領域中,統計一個資產池中的所有資產(日初資產+放款資產+買入資產)。
- 寫法&執行計劃探查
假設有3份數據需要關聯得到屬性,常規的寫法為使用2次full outer join + coalesce來關聯取值;或者先將3份數據主體合并在一起,再使用3次left join。
-- 舉例為資產池得到每個用戶的所有資產
-- 使用full outer join + coalesce的寫法
SELECT
COALESCE(tt1.cst_id, tt2.cst_id) as cst_id
,COALESCE(tt1.bal_init_prin, 0) AS bal_init_prin
,COALESCE(tt1.amt_retail_prin, 0) AS amt_retail_prin
,COALESCE(tt2.amt_buy_prin, 0) AS amt_buy_prin
FROM (
SELECT
COALESCE(t1.cst_id, t2.cst_id) as cst_id
,COALESCE(t1.bal_init_prin, 0) AS bal_init_prin
,COALESCE(t2.amt_retail_prin, 0) AS amt_retail_prin
FROM @bal_init t1 -- 日初資產
FULL OUTER JOIN @amt_retail t2 -- 當天放款資產
ON t1.cst_id = t2.cst_id
)tt1
FULL OUTER JOIN @amt_buy tt2 -- 當天買入資產
ON tt1.cst_id = tt2.cst_id
;
接下來看優化寫法:
-- 寫法一
SELECT
cst_id
,SUM(bal_init_prin) as bal_init_prin
,SUM(amt_retail_prin) as amt_retail_prin
,SUM(amt_buy_prin) as amt_buy_prin
FROM (
SELECT cst_id, bal_init_prin, 0 AS amt_retail_prin, 0 AS amt_buy_prin
FROM @bal_init -- 日初資產
union ALL
SELECT cst_id, 0 AS bal_init_prin, amt_retail_prin, 0 AS amt_buy_prin
FROM @amt_retail -- 當天放款資產
UNION ALL
SELECT cst_id, 0 AS bal_init_prin, 0 AS amt_retail_prin, amt_buy_prin
FROM @amt_buy -- 當天買入資產
)t1
GROUP BY
cst_id
;
-- 優化寫法二
SELECT
cst_id
,SUM(IF(flag = 1, prin, 0)) as bal_init_prin
,SUM(IF(flag = 2, prin, 0)) as amt_retail_prin
,SUM(IF(flag = 3, prin, 0)) as amt_buy_prin
FROM (
SELECT cst_id, bal_init_prin AS prin, 1 AS flag
FROM @bal_init -- 日初資產
union ALL
SELECT cst_id, amt_retail_prin AS prin, 2 AS flag
FROM @amt_retail -- 當天放款資產
UNION ALL
SELECT cst_id, amt_buy_prin AS prin, 3 AS flag
FROM @amt_buy -- 當天買入資產
)t1
GROUP BY
cst_id
;
對比join寫法和優化寫法的執行計劃(這兩個執行計劃內部做的事情和任務名稱理解一致,就不展開看了):
- join寫法
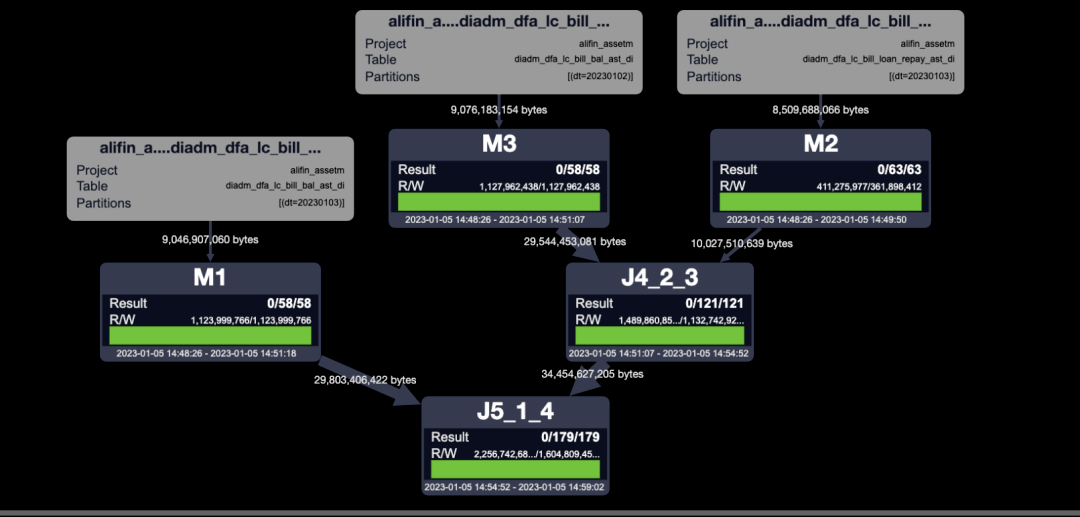
- 優化寫法

從執行計劃可以看出,join寫法的執行步驟要更多,多次shuffle也會消耗更多的資源,串行運行的時間也會更長。優化寫法只需要在讀取所有數據之后,做一次reduce就可以完成。最后對比一下運行時間和資源消耗,優化寫法運行時間快20%,資源使用減少30%。(場景越復雜,效果越好)
- 總結
由于JOIN是離線數據開發中最常出現低效的環節,那么直接干掉JOIN其實是更好的選擇。
當多張表的關聯鍵相同取int類型、聚合的值的場景下,union all + group by寫法運行更快、更節省資源、代碼開發運維更加簡單,并且在表行數越多、關聯表越多、關聯鍵越多的場景下,優勢會更加突出。
關于兩種優化寫法,優化寫法二更加靈活、更好維護、資源占用更少,但是對于需要使用占位數據的場景(比如聚合map),方法一更加適合。
4、多張大表join提速(字符串類型)
- 場景介紹
日常開發中,經常遇到從一個主體多張表取屬性的情況,比如客戶信息相關的數據,A表取地址、B表取電話號、C表取uv、D表取身份信息、E表取偏好。
- 寫法&執行計劃探查
假設有3份數據需要關聯得到屬性,常規的寫法為使用2次full outer join + coalesce來關聯取值;或者先將3份數據主體合并在一起,再使用3次left join。
-- 本案例和上邊案例類似,使用先將主體合并在一起,再使用三次left join
SELECT
base.cst_id AS cst_id
,t1.bal_init_prin AS bal_init_prin
,t2.amt_retail_prin AS amt_retail_prin
,t3.amt_buy_prin AS amt_buy_prin
FROM (
SELECT
cst_id
FROM @bal_init -- 日初資產
UNION
SELECT
cst_id
FROM @amt_retail -- 當天放款資產
UNION
SELECT
cst_id
FROM @amt_buy -- 當天買入資產
)base
LEFT JOIN @bal_init t1 -- 日初資產
ON base.cst_id = t1.cst_id
LEFT JOIN @amt_retail t2 -- 當天放款資產
ON base.cst_id = t2.cst_id
LEFT JOIN @amt_buy t3 -- 當天買入資產
ON base.cst_id = t3.cst_id
;
接下來看優化寫法:
-- STRING數據類型利用json來實現
SELECT
cst_id
,GET_JSON_OBJECT(all_val, '$.bal_init_prin') AS bal_init_prin
,GET_JSON_OBJECT(all_val, '$.amt_retail_prin') AS amt_retail_prin
,GET_JSON_OBJECT(all_val, '$.amt_buy_prin') AS amt_buy_prin
FROM (
SELECT
cst_id
,CONCAT('{',CONCAT_WS(',', COLLECT_SET(all_val)) , '}') AS all_val
FROM (
SELECT
cst_id
,CONCAT('"bal_init_prin":"', bal_init_prin, '"') AS all_val
FROM @bal_init -- 日初資產
UNION ALL
SELECT
cst_id
,CONCAT('"amt_retail_prin":"', amt_retail_prin, '"') AS all_val
FROM @amt_retail -- 當天放款資產
UNION ALL
SELECT
cst_id
,CONCAT('"amt_buy_prin":"', amt_buy_prin, '"') AS all_val
FROM @amt_buy -- 當天買入資產
)t1
GROUP BY
cst_id
)tt1
;
對比join寫法和優化寫法的執行計劃:
- join寫法

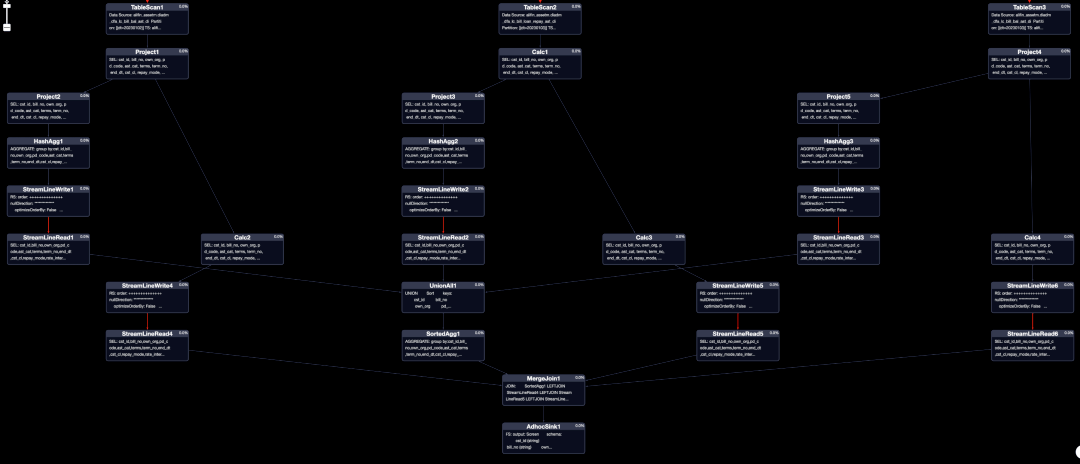
- 優化寫法

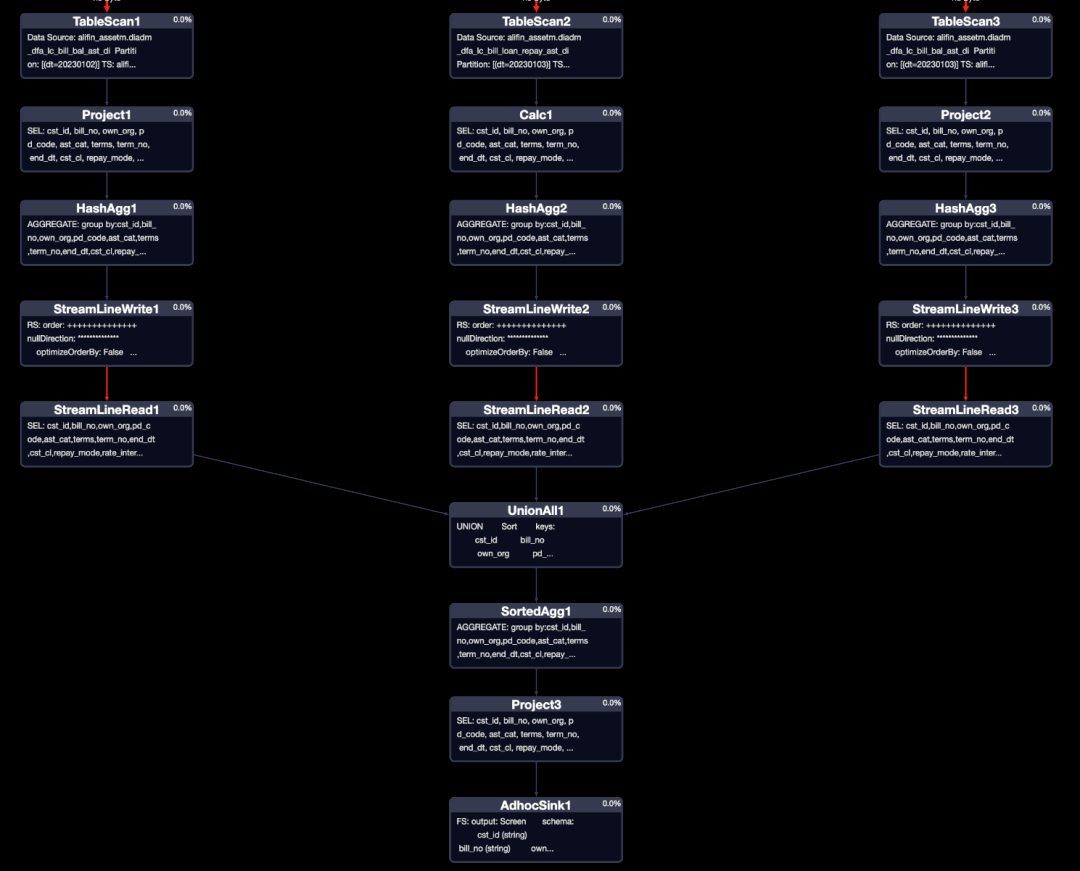
對比兩個執行計劃,join寫法對于每一張表的數據使用了兩次,分別為構建主體和取值,所以每一個MAP、JOIN任務的復雜度還是比較高的,但是優化寫法MAP、REDUCE任務簡潔明了。
并且隨著表的增多,JOIN寫法的JOIN任務負責度會更高。對比運行時間和資源消耗,優化寫法運行快了20%,資源消耗減少20%。(場景越復雜,效果越好)
由于使用到collect_set,所以需要考慮該節點是否存在超內存的問題并進行內存調整,該場景一般情況下不會出現。
- 總結
同大表join(聚合類型),區別在于此方法適用于STRING類型。注意collect_set函數的內存占用。
5、mapjoin為什么快?是否生效了?
- 場景介紹
日常開發中,經常會遇到大表join小表的情況,mapjoin是老生常談的處理方式,但是也要注意寫法、小表內存參數調整以保障mapjoin生效。
- 寫法&執行計劃探查
目前ODPS對mapjoin做了優化可以自動開啟,不用手動寫/* +mapjoin(a,b)*/來開啟了。inner join,大表left join小表都可以直接使mapjoin生效。
- mapjoin生效寫法
-- base為大表,fee_year_rate為小表
-- 方式一,inner join
SELECT
base.*
,fee_year_rate.*
FROM @base base
INNER JOIN @fee_year_rate fee_year_rate
ON (base.terms = fee_year_rate.terms)
;
-- 方式一,LEFT join
SELECT
base.*
,fee_year_rate.*
FROM @base base
LEFT JOIN @fee_year_rate fee_year_rate
ON (base.terms = fee_year_rate.terms)
;
- mapjoin未生效寫法
-- 方式三,right join
SELECT
base.*
,fee_year_rate.*
FROM @base base
RIGHT JOIN @fee_year_rate fee_year_rate
ON (base.terms = fee_year_rate.terms)
;
-- 方式四, full outer join
SELECT
base.*
,fee_year_rate.*
FROM @base base
FULL OUTER JOIN @fee_year_rate fee_year_rate
ON (base.terms = fee_year_rate.terms)
;
對比一下執行計劃:
- mapjoin生效執行計劃
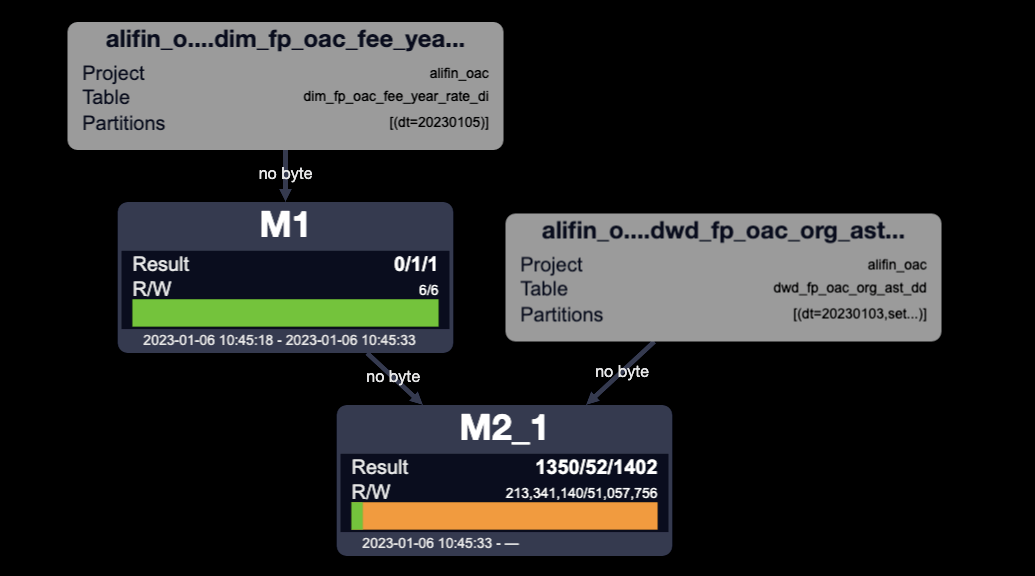
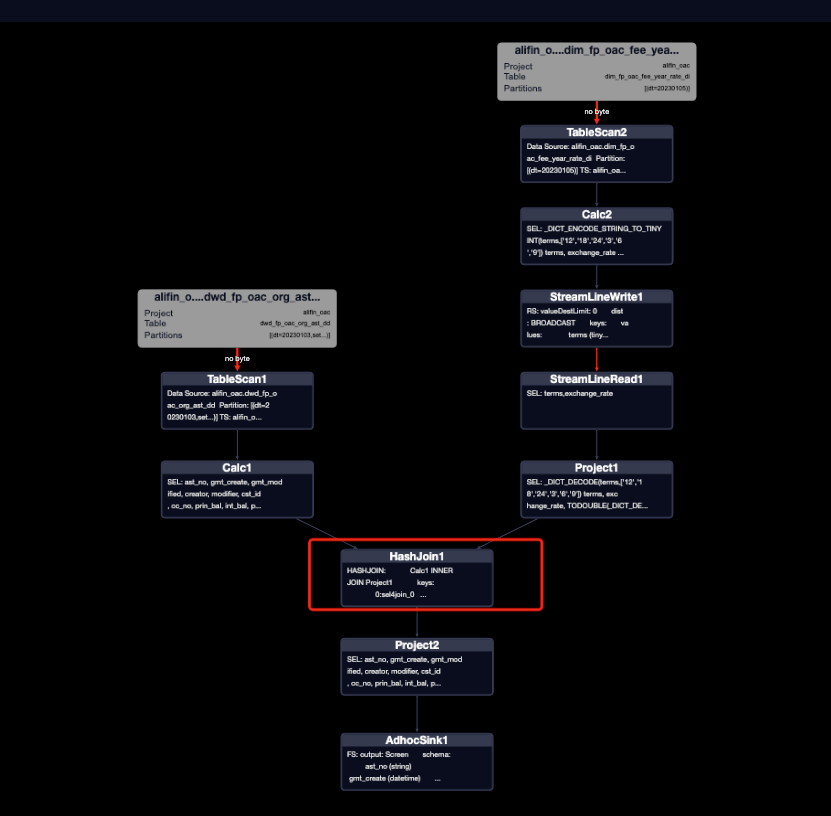
- mapjoin未生效執行計劃
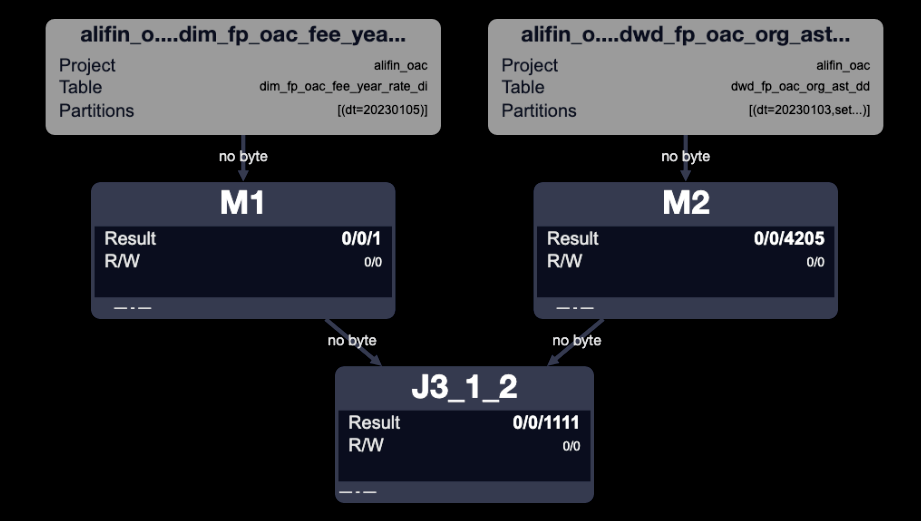
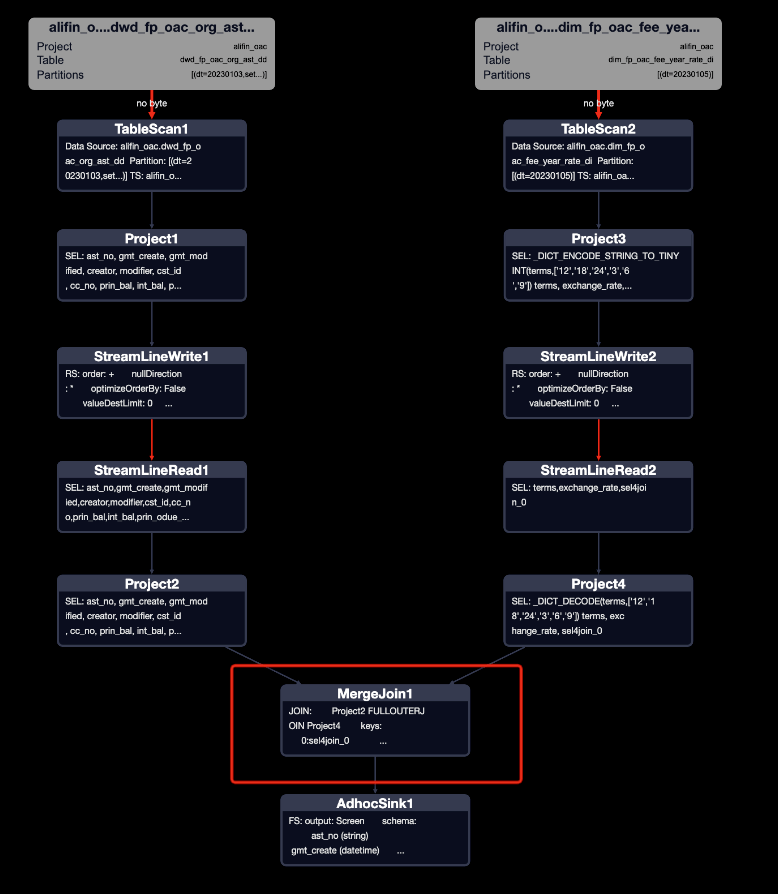
MapJoin簡單說就是在Map階段將小表讀入內存,順序掃描大表完成Join。
對比兩種執行計劃,mapjoin生效之后,只有兩個MAP任務,沒有了JOIN任務,相當于省了一次JOIN。
mapjoin是否生效,可以看是HashJoin還是MergeJoin來判斷。
- 總結
mapjoin開啟之后,運行效率提高明顯,但會因為寫法、小表過大不生效,要從執行計劃中去判斷并做參數調整保障mapjoin生效。
小表大小調整參數:set odps.sql.mapjoin.memory.max=2048(單位M)
6、distmapjoin:加強版mapjoin
- 場景介紹
對于大小表join的場景,小表經常會超出mapjoin的最大內存,那么mapjoin就不會生效了。
ODPS提供了將中型表放入內存的方案,即distmapjoin,用法和mapjoin相似,即在select語句中使用Hint提示/*+distmapjoin(<table_name>(shard_count=<n>,replica_count=<m>))*/才會執行distmapjoin。shard_count(分片數,默認[200M,500M])和replica_count(副本數,默認1)共同決定任務運行的并發度,即并發度=shard_count * replica_count。
- 寫法&執行計劃探查
- 常規寫法
SELECT
base.*
,cst_info.*
FROM @base base
LEFT JOIN @cst_info cst_info
ON (base.cst_id = cst_info.cst_id
AND base.origin_inst_code = cst_info.inst_id)
;
- 優化寫法
SELECT /*+distmapjoin(cst_info(shard_count=20))*/
base.*
,cst_info.*
FROM @base base
LEFT JOIN @cst_info cst_info
ON (base.cst_id = cst_info.cst_id
AND base.origin_inst_code = cst_info.inst_id)
;
對比執行計劃:
- 常規寫法


- 優化寫法
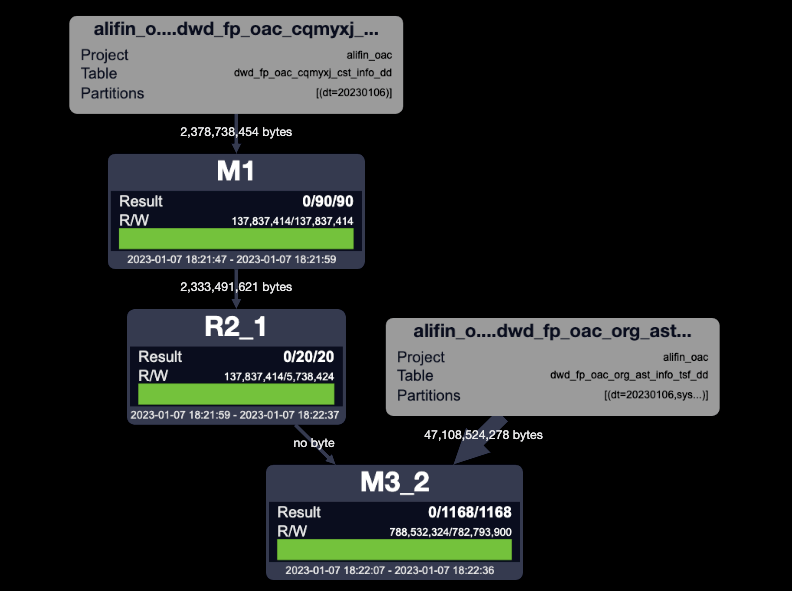
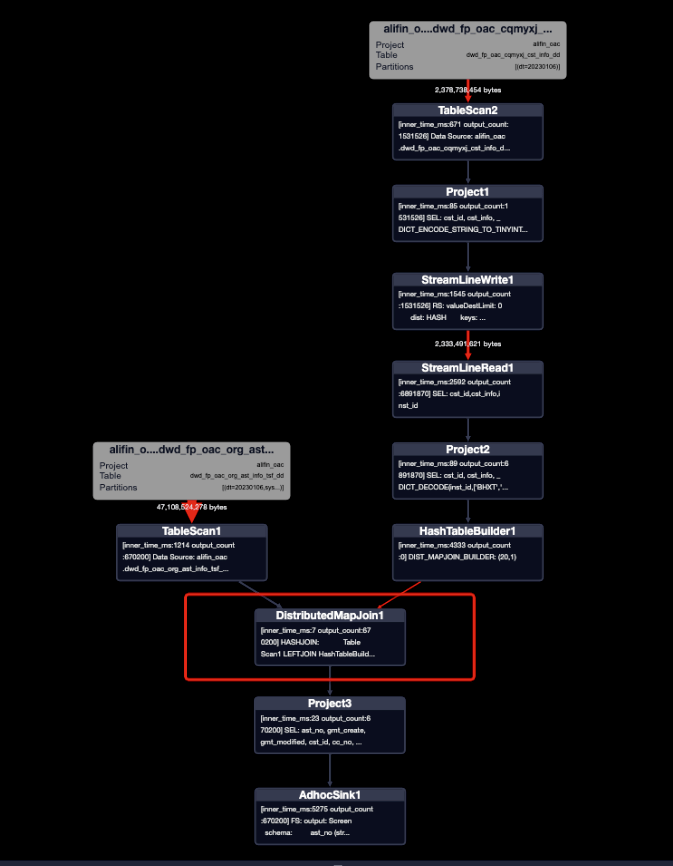
對比兩種執行計劃和mapjoin執行計劃可以發現,優化寫法都省去了JOIN任務,這個在很大程度上加快了運行速度和降低資源消耗,distmapjoin寫法比mapjoin寫法多了一個REDUCE任務,即對小表的分片。
distmapjoin是否生效,可以看是DistributedMapJoin1還是MergeJoin來判斷。
- 總結
同mapjoin總結。
7、where限制條件寫在外層會很慢嗎?
- 場景介紹
日常開發中,大家都習慣性將過濾條件緊跟在讀表之后,這樣可以減少數據量以減少任務運行時間。
- 寫法&執行計劃探查
過濾條件在讀表之后的規范寫法和多表join之后再過濾的非規范寫法:
-- 規范寫法
SELECT
base.*
,fee_year_rate.*
FROM (
SELECT *
FROM @base
where terms = '12'
)base
INNER JOIN @fee_year_rate fee_year_rate
ON (base.terms = fee_year_rate.terms)
;
-- 非規范寫法
SELECT
base.*
,fee_year_rate.*
FROM @base base
INNER JOIN @fee_year_rate fee_year_rate
ON (base.terms = fee_year_rate.terms)
WHERE base.terms = '12'
;
印象中,規范寫法的運行效率肯定會高一些,看一下執行計劃會發現兩種寫法的執行計劃是一樣的,都在join之前做了過濾。
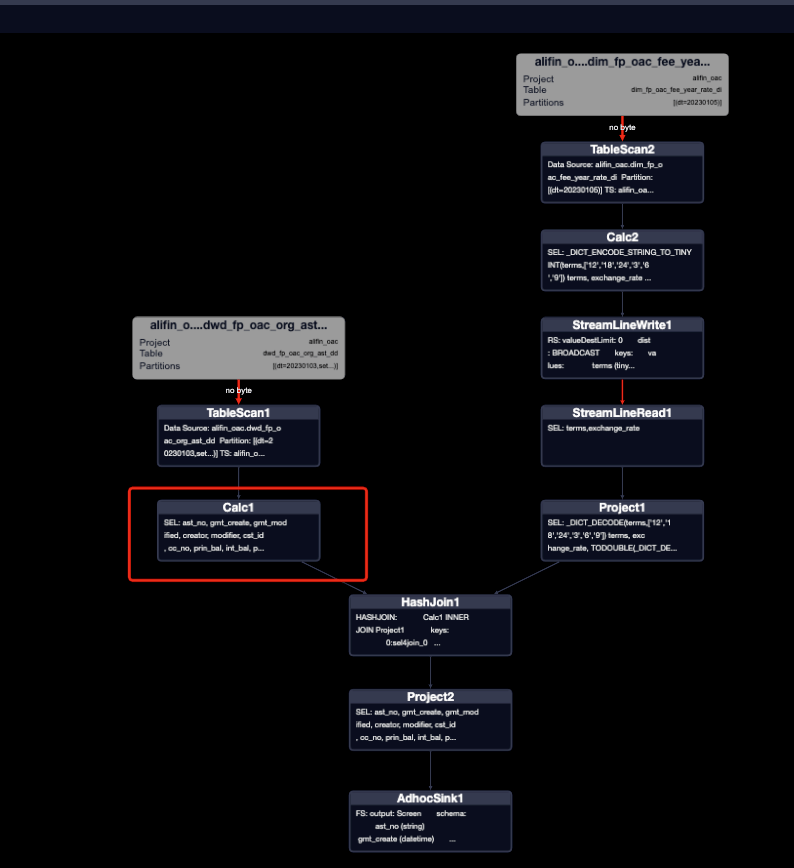
- 總結
ODPS對謂詞前置做了很好的優化,但是日常開發也盡量將過濾條件跟在讀表之后,這樣更加規范,代碼也會具有更好的可讀性。
三、總結
做好SQL開發、優化,得先學會閱讀執行計劃,多動手嘗試可以快速幫助你掌握該技能。(本篇講到的執行計劃,隨著ODPS的優化,會發生改變)
作者丨周潮潮(徽成)
來源丨公眾號:阿里開發者(ID:ali_tech)
dbaplus社群歡迎廣大技術人員投稿,投稿郵箱:editor@dbaplus.cn
關于我們
dbaplus社群是圍繞Database、BigData、AIOps的企業級專業社群。資深大咖、技術干貨,每天精品原創文章推送,每周線上技術分享,每月線下技術沙龍,每季度Gdevops&DAMS行業大會。
關注公眾號【dbaplus社群】,獲取更多原創技術文章和精選工具下載





