擊這里在線咨詢客服")
今天填一下之前的坑,盤一盤 MySQL 相關(guān)的 buffer。
我們來(lái)看一下官網(wǎng)的一張圖:
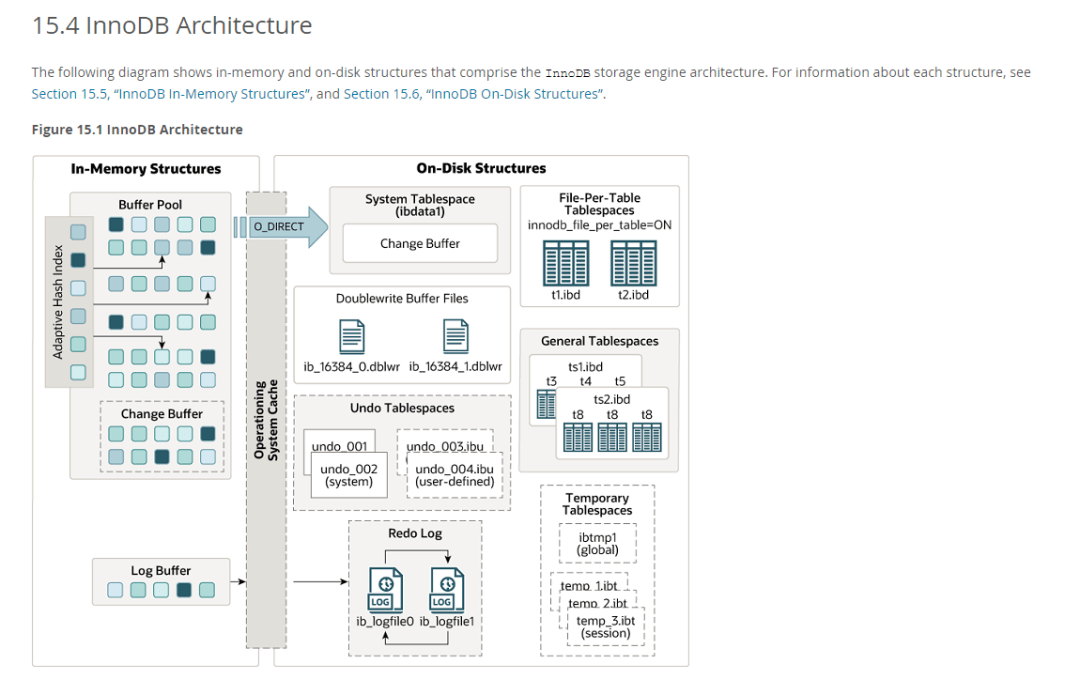
圖片這張圖畫的是 mysql innodb 的架構(gòu),從圖中可以看到有很多 buffer,這篇我們就一個(gè)一個(gè)盤過(guò)去。
發(fā)車!(文檔基于mysql8.0,以下描述的存儲(chǔ)引擎基于 mysql innodb)
buffer pool
首先,我們來(lái)看下 buffer pool。
其實(shí) buffer pool 就是內(nèi)存中的一塊緩沖池,用來(lái)緩存表和索引的數(shù)據(jù)。
我們都知道 mysql 的數(shù)據(jù)最終是存儲(chǔ)在磁盤上的,但是如果讀存數(shù)據(jù)都直接跟磁盤打交道的話,這速度就有點(diǎn)慢了。
所以 innodb 自己維護(hù)了一個(gè) buffer pool,在讀取數(shù)據(jù)的時(shí)候,會(huì)把數(shù)據(jù)加載到緩沖池中,這樣下次再獲取就不需要從磁盤讀了,直接訪問(wèn)內(nèi)存中的 buffer pool 即可。
包括修改也是一樣,直接修改內(nèi)存中的數(shù)據(jù),然后到一定時(shí)機(jī)才會(huì)將這些臟數(shù)據(jù)刷到磁盤上。
看到這肯定有小伙伴有疑惑:直接就在內(nèi)存中修改數(shù)據(jù),假設(shè)服務(wù)器突然宕機(jī)了,這個(gè)修改不就丟了?
別怕,有個(gè) redolog 的存在,它會(huì)持久化這些修改,恢復(fù)時(shí)可以讀取 redolog 來(lái)還原數(shù)據(jù),這個(gè)我們后面的文章再詳盤,今天的主角是 buffer 哈。
回到 buffer pool,其實(shí)緩沖池維護(hù)的是頁(yè)數(shù)據(jù),也就是說(shuō),即使你只想從磁盤中獲取一條數(shù)據(jù),但是 innodb 也會(huì)加載一頁(yè)的數(shù)據(jù)到緩沖池中,一頁(yè)默認(rèn)是 16k。
當(dāng)然,緩沖池的大小是有限的。按照 mysql 官網(wǎng)所說(shuō),在專用服務(wù)器上,通常會(huì)分配給緩沖池高達(dá) 80% 的物理內(nèi)存,不管分配多少,反正內(nèi)存大小正常來(lái)說(shuō)肯定不會(huì)比磁盤大。
也就是說(shuō)內(nèi)存放不下全部的數(shù)據(jù)庫(kù)數(shù)據(jù),那說(shuō)明緩沖池需要有淘汰機(jī)制,淘汰那些不常被訪問(wèn)的數(shù)據(jù)頁(yè)。
按照這個(gè)需求,我們很容易想到 LRU 機(jī)制,最近最少使用的頁(yè)面將被淘汰,即維護(hù)一個(gè)鏈表,被訪問(wèn)的頁(yè)面移動(dòng)到頭部,新加的頁(yè)面也加到頭部,同時(shí)根據(jù)內(nèi)存使用情況淘汰尾部的頁(yè)面。
通過(guò)這樣一個(gè)機(jī)制來(lái)維持內(nèi)存且盡量讓最近訪問(wèn)的數(shù)據(jù)留在內(nèi)存中。
看起來(lái)這個(gè)想法不錯(cuò),但 innodb 的實(shí)現(xiàn)并不是樸素的 LRU,而是一種變型的 LRU。
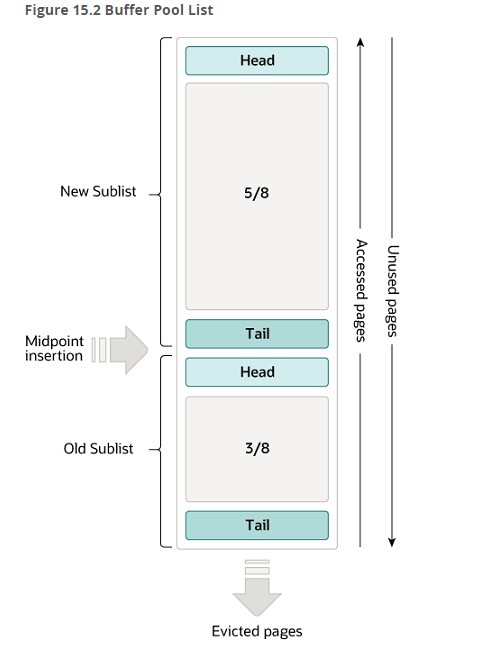
從圖中我們可以看出 buffer pool 分為了老年代(old sublist)和新生代(new sublist)。
老年代默認(rèn)占 3/8,當(dāng)然,可以通過(guò) innodb_old_blocks_pct 參數(shù)來(lái)調(diào)整比例。
當(dāng)有新頁(yè)面加入 buffer pool 時(shí),插入的位置是老年代的頭部,同時(shí)新頁(yè)面在 1s 內(nèi)再次被訪問(wèn)的話,不會(huì)移到新生代,等 1s 后,如果該頁(yè)面再次被訪問(wèn)才會(huì)被移動(dòng)到新生代。
這和我們正常了解的 LRU 不太一樣,正常了解的 LRU 實(shí)現(xiàn)是新頁(yè)面插入到頭部,且老頁(yè)面只要被訪問(wèn)到就會(huì)被移動(dòng)到頭部,這樣保證最近訪問(wèn)的數(shù)據(jù)都留存在頭部,淘汰的只會(huì)是尾部的數(shù)據(jù)。
那為什么要實(shí)現(xiàn)這樣改造的 LRU 呢?
innodb 有預(yù)讀機(jī)制,簡(jiǎn)單理解就是讀取連續(xù)的多個(gè)頁(yè)面后,innodb 認(rèn)為后面的數(shù)據(jù)也會(huì)被讀取,于是異步將這些數(shù)據(jù)載入 buffer pool 中,但是這只是一個(gè)預(yù)判,也就是說(shuō)預(yù)讀的頁(yè)面不一定會(huì)被訪問(wèn)。所以如果直接將新頁(yè)面都加到新生代,可能會(huì)污染熱點(diǎn)數(shù)據(jù),但是如果新頁(yè)面是加到老年代頭部,就沒(méi)有這個(gè)問(wèn)題。
同時(shí)大量數(shù)據(jù)的訪問(wèn),例如不帶 where 條件的 select 或者 mysqldump 的操作等,都會(huì)導(dǎo)致同等數(shù)量的數(shù)據(jù)頁(yè)被淘汰,如果簡(jiǎn)單加到新生代的話,可能會(huì)一次性把大量熱點(diǎn)數(shù)據(jù)淘汰了,所以新頁(yè)面加到老年代頭部就沒(méi)這個(gè)問(wèn)題。
那 1s 機(jī)制是為了什么呢?
這個(gè)機(jī)制其實(shí)也是為了處理大量數(shù)據(jù)訪問(wèn)的情況,因?yàn)榛旧洗髷?shù)據(jù)掃描之后,可能立馬又再次訪問(wèn),正常這時(shí)候需要把頁(yè)移到新生代了,但等這波操作結(jié)束了,后面還有可能再也沒(méi)有請(qǐng)求訪問(wèn)這些頁(yè)面了,但因?yàn)檫@波掃描把熱點(diǎn)數(shù)據(jù)都淘汰了,這就不太美麗了。
于是乎搞了個(gè)時(shí)間窗口,新頁(yè)面在 1s 內(nèi)的訪問(wèn),并不會(huì)將其移到新生代,這樣就不會(huì)淘汰熱點(diǎn)數(shù)據(jù)了,然后 1s 后如果這個(gè)頁(yè)面再次被訪問(wèn),才會(huì)被移到新生代,這次訪問(wèn)大概率已經(jīng)是別的業(yè)務(wù)請(qǐng)求,也說(shuō)明這個(gè)數(shù)據(jù)確實(shí)可能是熱點(diǎn)數(shù)據(jù)。
經(jīng)過(guò)這兩個(gè)改造, innodb 就解決了預(yù)讀失效和一次性大批量數(shù)據(jù)訪問(wèn)的問(wèn)題。
至此,對(duì) buffer pool 的了解就差不多了。
change buffer
從上面的圖我們可以看到, buffer pool 里面其實(shí)有一塊內(nèi)存是留給 change buffer 用的。
那 change buffer 是個(gè)啥玩意呢?
還記得我在 buffer pool 寫的一句話嗎:innodb 直接修改內(nèi)存中的數(shù)據(jù),然后到一定時(shí)機(jī)才會(huì)將這些臟數(shù)據(jù)刷到磁盤上。
也就是修改的時(shí)候直接修改的是 buffer pool 中的數(shù)據(jù),但這個(gè)前提是 buffer pool 中已經(jīng)存在你要修改的數(shù)據(jù)。
假設(shè)我們就直接執(zhí)行一條 update table set name = 'yes' where id = 1,如果此時(shí) buffer pool 里沒(méi)有 id 為 1 的這條數(shù)據(jù),那怎么辦?
難道把這條數(shù)據(jù)先加載到 buffer pool 中,然后再執(zhí)行修改嗎?
當(dāng)然不是,這時(shí)候 change buffer 就上場(chǎng)了。
如果當(dāng)前數(shù)據(jù)頁(yè)不在 buffer pool 中,那么 innodb 會(huì)把更新操作緩存到 change buffer 中,當(dāng)下次訪問(wèn)到這條數(shù)據(jù)后,會(huì)把數(shù)據(jù)頁(yè)加載到 buffer pool 中,并且應(yīng)用上 change buffer 里面的變更,這樣就保證了數(shù)據(jù)的一致性。
所以 change buffer 有什么好處?
當(dāng)二級(jí)索引頁(yè)不在 buffer pool 中時(shí),change buffer 可以避免立即從磁盤讀取對(duì)應(yīng)索引頁(yè)導(dǎo)致的昂貴的隨機(jī)I/O ,對(duì)應(yīng)的更改可以在后面當(dāng)二級(jí)索引頁(yè)讀入 buffer pool 時(shí)候被批量應(yīng)用。
看到我加粗的字體沒(méi),二級(jí)索引頁(yè),沒(méi)錯(cuò) change buffer 只能用于二級(jí)索引的更改,不適用于主鍵索引,空間索引以及全文索引。
還有,唯一索引也不行,因?yàn)槲ㄒ凰饕枰x取數(shù)據(jù)然后檢查數(shù)據(jù)的一致性。
看到這肯定又有小伙伴關(guān)心:更改先緩存在 change buffer 中,假如數(shù)據(jù)庫(kù)掛了,更改不是丟了嗎?
別怕,change buffer 也是要落盤存儲(chǔ)的,從上圖我們看到 change buffer 會(huì)落盤到系統(tǒng)表空間里面,然后 redo log 也會(huì)記錄 chang buffer 的修改來(lái)保證數(shù)據(jù)一致性。
至此,想必你對(duì) change buffer 已經(jīng)有一定了解了吧。
這玩意主要用來(lái)避免于二級(jí)索引頁(yè)修改產(chǎn)生的隨機(jī)I/O,如果你的內(nèi)存夠大能裝下所有數(shù)據(jù),或者二級(jí)索引很少,或者你的磁盤是固態(tài)的對(duì)隨機(jī)訪問(wèn)影響不大,其實(shí)可以關(guān)閉 change buffer,這玩意也增加了復(fù)雜度,當(dāng)然最終還是得看壓測(cè)結(jié)果。
Log Buffer
接下來(lái),我們看看 Log Buffer。
從上面的圖我們可以得知,這玩意就是給 redo log 做緩沖用的。
redo log 我們都知道是重做日志,用來(lái)保證崩潰恢復(fù)數(shù)據(jù)的正確性,innodb 寫數(shù)據(jù)時(shí)是先寫日志,再寫磁盤數(shù)據(jù),即 WAL (Write-Ahead Logging),把數(shù)據(jù)的隨機(jī)寫入轉(zhuǎn)換成日志的順序?qū)憽?/p>
但,即使是順序?qū)?log ,每次都調(diào)用 write 或者 fsync 也是有開銷的,畢竟也是系統(tǒng)調(diào)用,涉及上下文切換。
于是乎,搞了個(gè) Log Buffer 來(lái)緩存 redo log 的寫入。
即寫 redo log 先寫到 Log Buffer 中,等一定時(shí)機(jī)再寫到 redo log 文件里。
我們每次事務(wù)可能涉及多個(gè)更改,這樣就會(huì)產(chǎn)生多條 redo log,這時(shí)會(huì)都先寫到 Log Buffer 中,等事務(wù)提交的時(shí)候,一起將這些 redo log 寫到文件里。
或者當(dāng) Log Buffer 超過(guò)總量的一半(默認(rèn)總量是 16mb),也會(huì)將數(shù)據(jù)刷到 redo log 文件中。
也有個(gè)后臺(tái)線程,每隔 1s 就會(huì)將 Log Buffer 刷到 redo log 文件中。
從上面這些我們得知,Log Buffer 其實(shí)就是一個(gè)寫優(yōu)化操作,把多次 write 優(yōu)化成一次 write,一次處理多數(shù)據(jù),減少系統(tǒng)調(diào)用。
看到這肯定有小伙伴說(shuō),數(shù)據(jù)先寫 Log Buffer 而不刷盤,這數(shù)據(jù)不會(huì)丟嗎?
innodb 其實(shí)給了個(gè)配置,即 innodb_flush_log_at_trx_commit 來(lái)控制 redo log 寫盤時(shí)機(jī)。
- 當(dāng)值為 0,提交事務(wù)不會(huì)刷盤到 redo log,需要等每隔一秒的后臺(tái)線程,將 log buffer 寫到操作系統(tǒng)的 cache,并調(diào)用 fsync落盤,性能最好,但是可能會(huì)丟 1s 數(shù)據(jù)。
- 當(dāng)值為 1,提交事務(wù)會(huì)將 log buffer 寫到操作系統(tǒng)的 cache,并調(diào)用 fsync 落盤,保證數(shù)據(jù)正確,性能最差,這也是默認(rèn)配置。
- 當(dāng)值為 2,提交事務(wù)會(huì)將 log buffer 寫到操作系統(tǒng)的 cache,但不調(diào)用 fsync,而是等每隔 1s 調(diào)用 fsync 落盤,性能折中,如果數(shù)據(jù)庫(kù)掛了沒(méi)事,如果服務(wù)器宕機(jī)了,會(huì)丟 1s 數(shù)據(jù)。
具體如何配置看你的業(yè)務(wù)了。
至此,想必你應(yīng)該了解 Log Buffer 是干啥用了的吧。
Doublewrite Buffer
現(xiàn)在我們來(lái)看最后一個(gè) buffer,即 Doublewrite Buffer。
這玩意又是啥用呢?
我們都知道 innodb 默認(rèn)一頁(yè)是 16K,而操作系統(tǒng) linux 內(nèi)存頁(yè)是 4K,那么一個(gè) innodb 頁(yè)對(duì)應(yīng) 4 個(gè)系統(tǒng)頁(yè)。
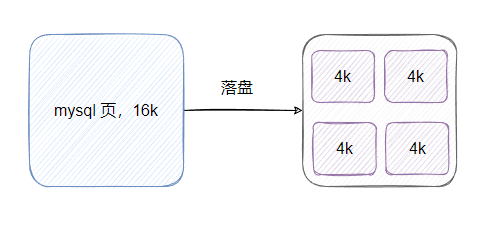
所以 innodb 的一頁(yè)數(shù)據(jù)要刷盤等于需要寫四個(gè)系統(tǒng)頁(yè),那假設(shè)一頁(yè)數(shù)據(jù)落盤的時(shí)候,只寫了一個(gè)系統(tǒng)頁(yè) 就斷電了,那 innodb 一頁(yè)數(shù)據(jù)就壞了,然后就 g 了,恢復(fù)不了。
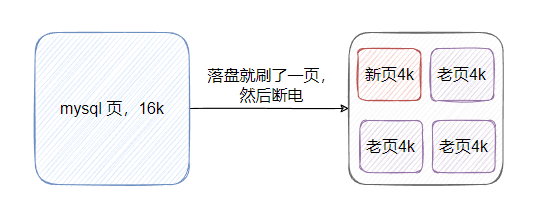
即產(chǎn)生了部分頁(yè)面寫問(wèn)題,因?yàn)閷?innodb 的一頁(yè)無(wú)法保證原子性,所以引入了 Doublewrite Buffer。
其實(shí)就是當(dāng) innodb 要將數(shù)據(jù)落盤的時(shí)候,先將頁(yè)數(shù)據(jù)拷貝到 Doublewrite Buffer 中,然后 Doublewrite Buffer 再刷盤到 Doublewrite Buffer Files,這時(shí)候數(shù)據(jù)已經(jīng)落盤了。
然后再將數(shù)據(jù)頁(yè)刷盤到本該到文件上。
從這個(gè)步驟我們得知,數(shù)據(jù)是寫了兩次磁盤,所以這玩意叫 double write。
之所以這樣操作就是先找個(gè)地方暫存這次刷盤的完整數(shù)據(jù),如果出現(xiàn)斷電這種情況導(dǎo)致的部分頁(yè)面寫而損壞原先的完整頁(yè),可以從 Doublewrite Buffer Files 恢復(fù)數(shù)據(jù)。
但雖然是兩次寫,性能的話也不會(huì)低太多,因此數(shù)據(jù)拷貝到 Doublewrite Buffer 是內(nèi)存拷貝操作,然后寫到 Doublewrite Buffer Files 也是批量寫,且是順序?qū)懕P,所以整體而已,性能損失不會(huì)太多。
有了這玩意,在崩潰恢復(fù)的時(shí)候,如果發(fā)現(xiàn)頁(yè)損壞,就可以從 Doublewrite Buffer Files 里面找到頁(yè)副本,然后恢復(fù)即可。
完美。
最后
好了,關(guān)于 innodb buffer 們介紹完了,我們來(lái)總結(jié)一下:
- buffer pool,緩存數(shù)據(jù)頁(yè),避免頻繁地磁盤交互,內(nèi)部利用定制的 LRU 來(lái)淘汰緩存頁(yè),LRU分老年代和新生代。
- change buffer,用于二級(jí)非唯一索引的新增、修改或刪除操作,當(dāng) buffer pool 沒(méi)有數(shù)據(jù)的時(shí)候,不需要加載數(shù)據(jù)頁(yè)到緩沖池中,而是通過(guò) change buffer 來(lái)記錄此變更,減少隨機(jī) I/O。
- log buffer,用于 redo log 的緩沖,減少 I/O,批處理減少系統(tǒng)調(diào)用。
- doublewrite buffer,用于部分頁(yè)面寫問(wèn)題,雙寫數(shù)據(jù)頁(yè),壞頁(yè)時(shí)可從 doublewrite buffer files 進(jìn)行頁(yè)恢復(fù),保證頁(yè)的完整和數(shù)據(jù)的正確。
>>>>參考資料
- https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html
作者丨是YES呀
來(lái)源丨公眾號(hào):yes的練級(jí)攻略(ID:yes_JAVA)





