
GPT-4 的思考方式,越來越像人了。
人類在做錯事時,會反思自己的行為,避免再次出錯,如果讓 GPT-4 這類大型語言模型也具備反思能力,性能不知道要提高多少了。
眾所周知,大型語言模型 (LLM) 在各種任務上已經表現出前所未有的性能。然而,這些 SOTA 方法通常需要對已定義的狀態空間進行模型微調、策略優化等操作。由于缺乏高質量的訓練數據、定義良好的狀態空間,優化模型實現起來還是比較難的。此外,模型還不具備人類決策過程所固有的某些品質,特別是從錯誤中學習的能力。
不過現在好了,在最近的一篇論文中,來自美國東北大學、MIT 等機構的研究者提出 Reflexion,該方法賦予智能體動態記憶和自我反思的能力。
為了驗證方法的有效性,該研究評估了智能體在 AlfWorld 環境中完成決策任務的能力,以及在 HotPotQA 環境中完成知識密集型、基于搜索問答任務的能力,在這兩項任務的成功率分別為 97% 和 51%。

論文地址:
https://arxiv.org/pdf/2303.11366.pdf
項目地址:
https://github.com/GammaTauAI/reflexion-human-eval
如下圖所示,在 AlfWorld 環境中,房間里擺設了各種物品,要求讓智能體給出推理計劃以拿到某件物體,下圖上半部分由于智能體低效的計劃而失敗。經過反思后,智能體意識到錯誤,糾正推理軌跡,給出簡潔的軌跡方式(如圖下半部分)。

模型反思有缺陷的搜索策略:

這篇論文表明,你可以通過要求 GPT-4 反思「你為什么錯了?」并為自己生成一個新的提示,將這個錯誤原因考慮在內,直到結果正確,從而將 GPT-4 的性能提高驚人的 30%。
網友不禁感嘆:人工智能的發展速度已經超過了我們的適應能力。
方法介紹
Reflexion 智能體的整體架構如下圖 1 所示,其中 Reflexion 利用 ReAct(Yao et al., 2023)。在第一次試驗中,智能體從構成初始查詢的環境中獲得任務,然后智能體執行由 LLM 生成的一系列動作,并從環境中接收觀察和獎勵。對于提供描述型或持續型獎勵的環境,該研究將輸出限制為簡單的二元成功狀態以確保適用性。
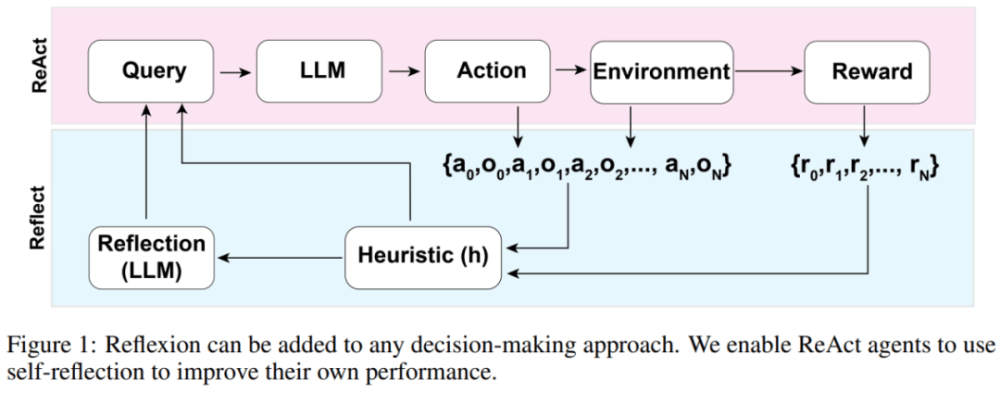
在每個動作 a_t 之后,智能體會計算一個啟發性函數 h,如下圖所示
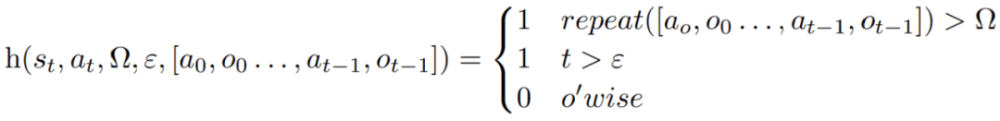
這個啟發性函數旨在檢測智能體產生信息幻覺(即虛假或錯誤的信息)或效率低下,并「告訴」智能體何時需要反思(reflexion),其中 t 是 time step,s_t 是當前狀態,Ω 表示重復動作循環的次數,ε 表示執行動作的最大總數,[a_o, o_0 . . . , a_(t−1), o_(t−1)] 代表軌跡歷史。repeat 是一個簡單的函數,用于確定產生相同結果的重復動作循環的次數。
如果函數 h 告訴智能體需要反思,那么智能體會查詢 LLM 以反映其當前任務、軌跡歷史和上次獎勵,然后智能體在后續試驗中會重置環境再重試。如果函數 h 沒有告訴智能體需要反思,那么智能體會將 a_t 和 o_t 添加到其軌跡歷史記錄中,并向 LLM 查詢下一個動作。
如果如果啟發式 h 建議在 time step t 時進行反思,則智能體會根據其當前狀態 s_t、最后的獎勵 r_t、先前的動作和觀察 [a_0, o_0, . . . , a_t, o_t],以及智能體現有的工作存儲 mem,啟動一個反思過程。
反思的目的是通過反復試驗幫助智能體糾正「幻覺」和低效率問題。用于反思的模型是一個使用特定的失敗軌跡和理想的反思示例來 prompt 的 LLM。
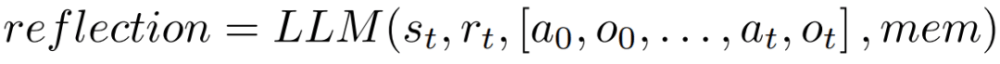
智能體會迭代地進行上述反思過程。在實驗中,該研究設置在智能體內存中存儲的反思最多為 3 次,這是為了避免查詢超出 LLM 的限制。以下幾種情況,運行會終止:
超過最大試驗次數;
未能在兩次連續試驗之間提高性能;
完成任務。
實驗及結果
AlfWorld 提供了六種不同的任務和 3000 多個環境,這些任務要求智能體理解目標任務,制定子任務的順序計劃,并在給定環境中執行操作。
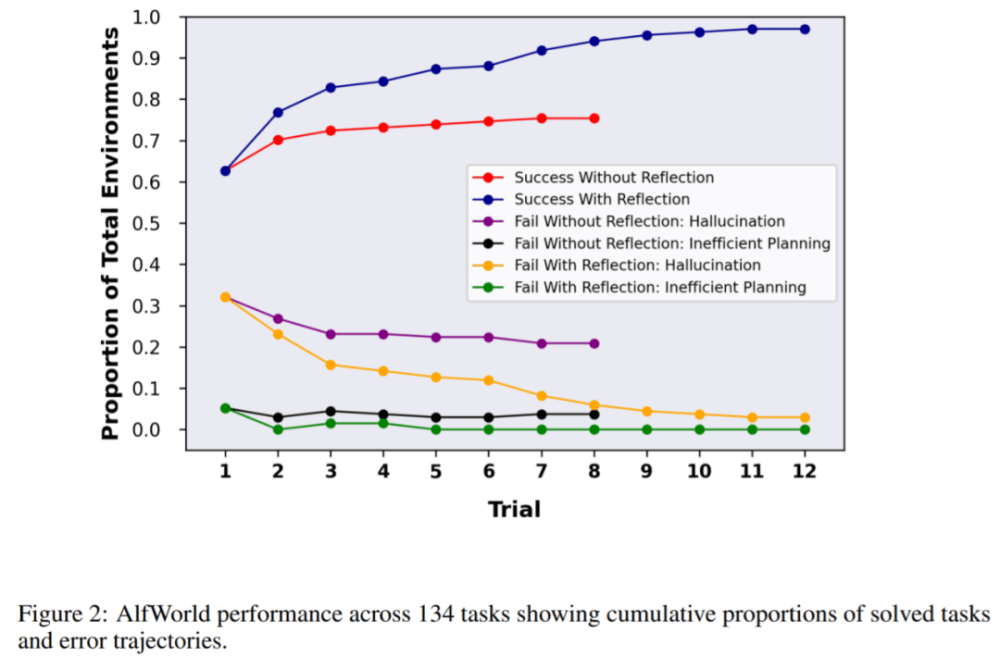
該研究在 134 個 AlfWorld 環境中測試智能體,任務包括尋找隱藏物體(例如,在抽屜里找到水果刀)、移動物體(例如,將刀移到砧板上 ),以及用其他對象來操縱另一個對象(例如,在冰箱中冷藏西紅柿)。
在沒有反思的情況下,智能體的準確率為 63%,之后加入 Reflexion 進行對比。結果顯示,智能體在 12 次試驗中能夠處理好 97% 的環境,在 134 項任務中僅有 4 項沒有解決。
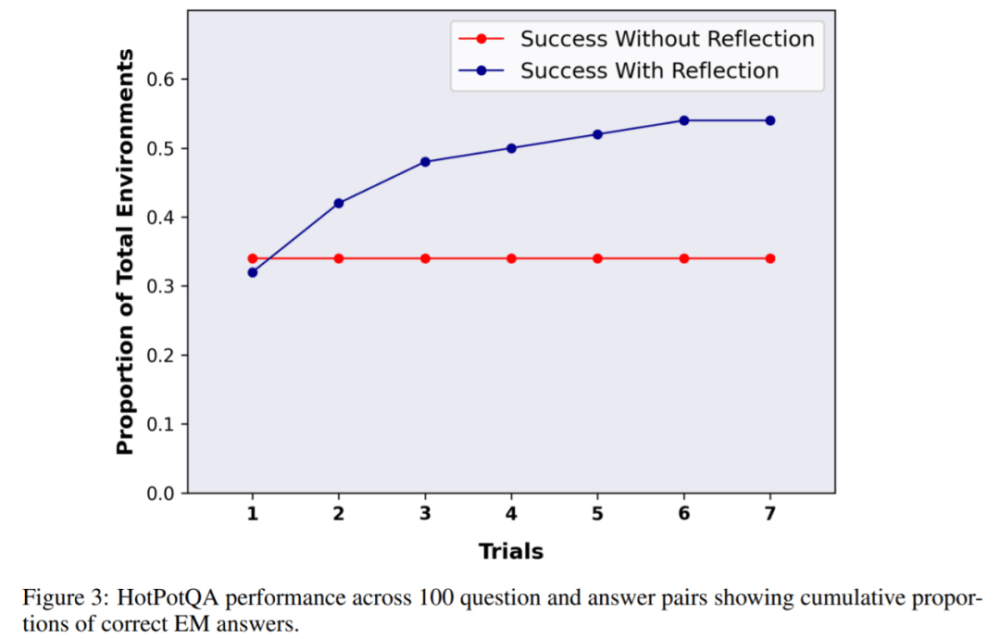
接下來的實驗是在 HotPotQA 中進行了,它是一個基于維基百科的數據集,包含 113k 個問答對,主要用來挑戰智能體解析內容和推理的能力。
在 HotpotQA 的 100 個問答對測試中,該研究將基礎智能體和基于 Reflexion 的智能體進行比較,直到它們在連續的試驗中無法提高準確性。結果顯示基礎智能體并沒有性能提高,在第一次試驗中,基礎智能體準確率為 34%,Reflexion 智能體準確率為 32%,但在 7 次試驗后,Reflexion 智能體表現大幅改善,性能提升接近 30%,大大優于基礎智能體。
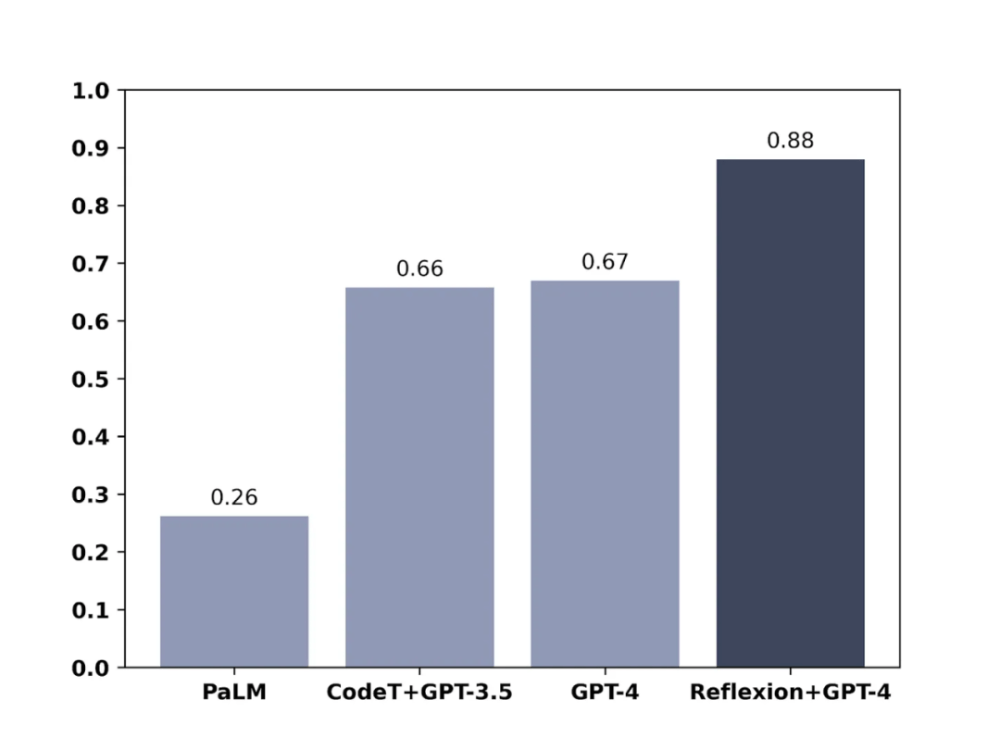
類似地,在測試模型編寫代碼的能力時,加入 Reflexion 的 GPT-4 也顯著優于常規的 GPT-4:
參考鏈接:
https://nanothoughts.substack.com/p/reflecting-on-reflexion
https://Twitter.com/blader/status/1639728920261201921





