
Alex 發自 凹非寺
量子位 | 公眾號 QbitAI
這是一份看似平平無奇的日式便當。

但你敢信,其實每一格食物都是P上去的,而且原圖還是醬嬸兒的:
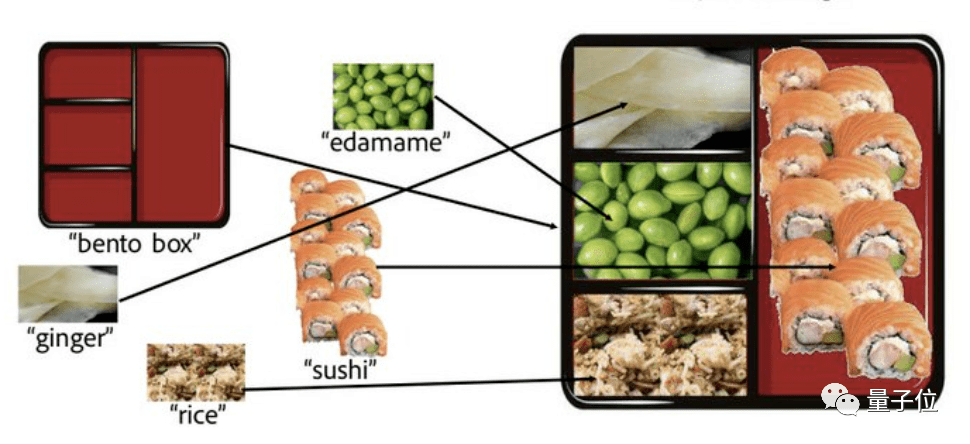
△直接摳圖貼上去,效果一眼假
背后操作者并不是什么PS大佬,而是一只AI,名字很直白:拼圖擴散 (Collage Diffusion)。
隨便找幾張小圖拿給它,AI就能自己看懂圖片內容,再把各元素 非常自然地拼成一張大圖——完全不存在一眼假。
其效果驚艷了不少網友。

甚至還有PS愛好者直呼道:
這簡直是個天賜之物……希望很快能在Automatic1111 ( Stable Diffusion用戶常用的網絡UI,也有集成在PS中的插件版)中看到它。
為什么效果這么自然?
實際上,此AI生成的“日式便當”還有好幾個生成版本——都很自然有木有。

至于為啥還有多種版本?問就是因為用戶還能自定義,在總體不變得太離譜的前提下,他們可以微調各種細節。
除了“日式便當”,它還有不少出色的作品。
比如,這是拿給AI的素材,P圖痕跡明顯:

這是AI拼好的圖,反正我愣是沒看出什么P圖痕跡:

話說這兩年,“文字生成圖像的擴散模型”著實大火了一把,DALL·E 2和Imagen都是基于此開發出來的應用。這種擴散模型的優點,是生成圖片多樣化、質量較高。
不過, 文字終究對于目標圖像,最多只能起到 模糊的規范作用,所以用戶通常要花大量時間調整提示 (prompt),還得搭配上額外的控制組件,才可以取得不錯的效果。
就拿前文展示的日式便當來說:
如果用戶只輸入“一個裝有米飯、毛豆、生姜和壽司的便當盒”,那就既沒描述哪種食物放到哪一格,也沒有說明每種食物的外觀。但如果非要講清楚的話,用戶恐怕得寫一篇小作文了……
鑒于此,斯坦福團隊決定從別的角度出發。
他們決定參考傳統思路,通過 拼圖來生成最終圖像,并由此開發出了一種 新的擴散模型。
有意思的是,說白了,這種模型也算是用經典技術“拼”出來的。
首先是分層:使用基于圖層的圖像編輯UI,將源圖像分解成一個個RGBA圖層 (R、G、B分別代表紅、綠、藍,A代表透明度),然后將這些圖層排列在畫布上,并把每個圖層和文字提示配對。
通過分層,可以修改圖像中的各種元素。
到目前為止,分層已經是計算機圖形領域中一項成熟的技術,不過此前分層信息一般是作為單張圖片輸出結果使用的。
而在這種新型“拼圖擴散模型”中,分層信息成了后續操作的輸入。
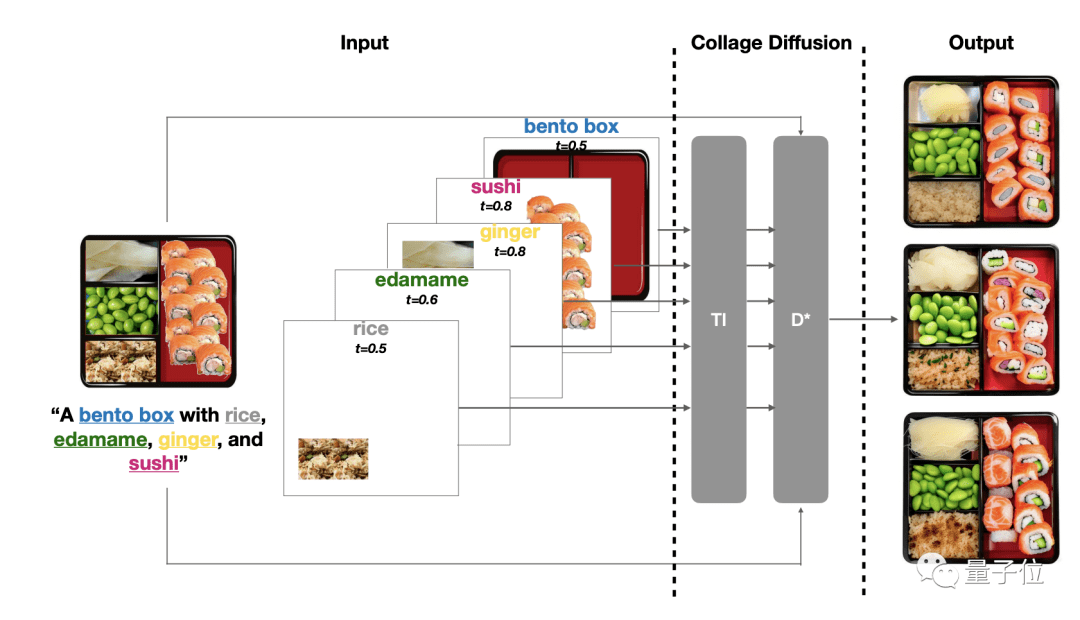
除了分層, 還搭配了現有的基于擴散的圖像協調技術,提升圖像視覺質量。
總而言之,該算法不僅限制了對象的某些屬性 (如視覺特征)的變化,同時允許屬性 (方向、光照、透視、遮擋)發生改變。
——從而平衡了還原度和自然度之間的關系,生成“神似”且毫無違和感的圖片。
操作過程也很easy,在交互編輯模式下,用戶在幾分鐘內就能創作一幅拼貼畫。
他們不僅可以自定義場景中的空間排列順序 (就是把從別處扣出來的圖放到適當的位置);還能調整生成圖像的各個組件。用同樣的源圖,可以得出不同的效果。

△最右列是這個AI的輸出結果
而在非交互式模式下 (即用戶不拼圖,直接把一堆小圖丟給AI),AI也能根據拿到的小圖,自動拼出一張效果自然的大圖。
研究團隊
最后,來說說背后的研究團隊,他們是斯坦福大學計算機科學系的一群師生。
論文一作,Vishnu Sarukkai現為斯坦福計算機科學系研究生,還是碩博連讀的那種。

他的主要研究方向為:計算機圖形學、計算機視覺和機器學習。
此外,論文的共同作者Linden Li,也是斯坦福計算機科學系研究生。

在校求學期間,他曾到英偉達實習4個月,與英偉達深度學習研究小組合作,參與訓練了增加100M+參數的視覺轉換器模型。
— 完—





