
作者 | 陳明雨 責編 | 夢依丹
身處在日新月異的時代,我們見慣了技術的興起與繁榮、變遷與衰落,甚至是朝榮夕滅。信息技術以前所未有的速度更迭,給周遭事物帶來了顛覆性地變化。數據庫亦是如此,無數數據庫悄然湮沒在技術更迭的浪潮里,直到在浩渺如海的代碼片段中都找不到些許印記。而有的則歷久而彌新,經受了時間的考驗,彰顯出強大的生命力,并以更加繁茂的姿態扎根生長。

十年對于數據庫意味著什么?
十年對于數據庫而言,可能是一段從誕生到消逝的完整軟件生命周期,也可能是邁過里程碑之后的全新旅程。
所以從 MySQL 1.0 版本誕生,到具備顛覆性意義的 MySQL 5.7 版本正式發布,時間跨度剛好是十年,而十年之后的故事,大家已經都知道了。
所以從 Benoit、Thierry、Marcin 聯合創建 Snowflake,到在紐交所成功上市、成為軟件行業有史以來最大規模的 IPO,再到全面開啟云數據倉庫時代,時間跨度也差不多十年。
而對于 Apache Doris,十年意味著什么?
留個懸念,在回答這個問題之前,我們不妨來回顧下社區發展歷程。
盡管最早的歷史可以追溯到 2008 年的百度鳳巢廣告系統,但彼時非 SQL 的單機查詢引擎加 KV 存儲系統在產品形態上與 OLAP 還有著較大的差異。
正式確立 OLAP 數據庫這一形態是在 2013 年。通過自研全列式存儲引擎 OLAP Engine 并基于 Apache Impala 改造了全新的 MPP 查詢引擎,自此,Doris 真正成為了具備大數據量下高效支持數據分析能力的 OLAP 數據庫,并在百度內部大規模應用,成為了百度內部統一的 OLAP 分析平臺。
往往一個內部項目的發展會有兩種演進模式,一種是隨著需求的增加系統架構日益臃腫,當面對較為靈活的需求,常因改動成本過大而被徹底重構。另一種則是長期服務某一固定場景、需求逐漸收斂乃至停滯,最終被快速革新的外部技術徹底取代。而開源則是內部項目的一場新生,在更廣闊的應用場景、更多樣的開發者群體以及更高效的研發模式加持下開啟新的篇章。
于是在數個版本的迭代與優化后,2017年 Doris 的前身在 GitHub 上開源,2018 年進入 Apache 基金會孵化,并正式更名為 Apache Doris。(GitHub 地址:https://github.com/apache/doris)
時至 2022 年,正是 Apache Doris 在 OLAP 領域深耕的十年之際。
Apache Doris 2022 回顧
2022 年,外部世界正處在前所未有的變化之中,無數魔幻時刻在現實中發生。需要慶幸的是,技術和開源的力量幫助我們穿越了許多不確定性。而這一年勢必成為 Apache Doris 發展歷程中有著濃墨重彩的一年,我們從幾個角度來回顧一下 Apache Doris 過去一年的發展:
社區重要指標
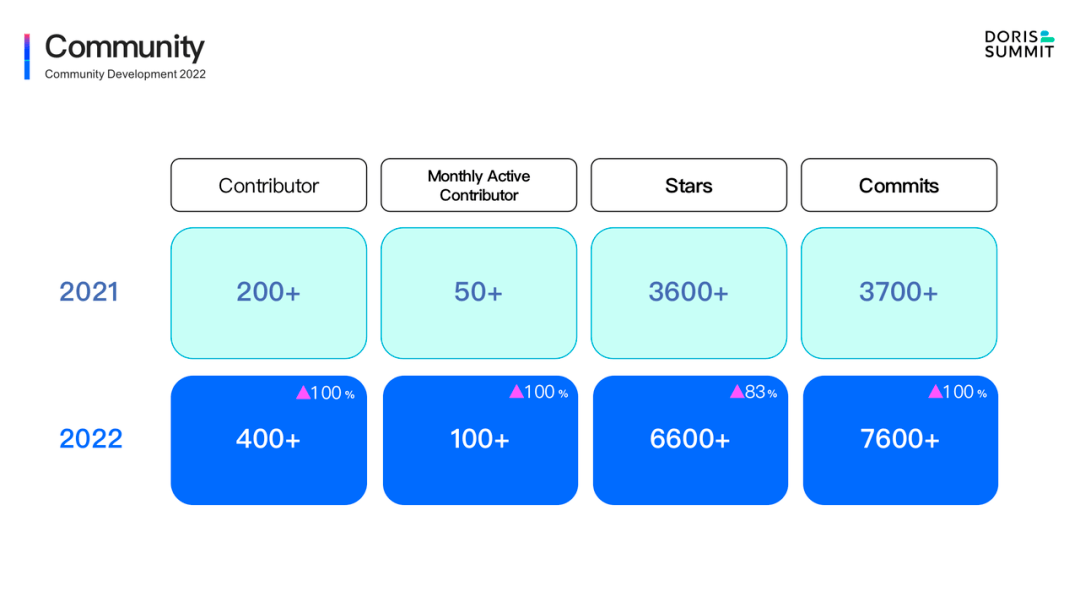
過去一年中:
-
社區累計貢獻者的數量從 200 余位增長至近 420 位,同比增長超過 100%,目前仍在持續上升中。
-
每月活躍貢獻者的數量從 50 位增長至 100 位,同樣呈現翻倍增長的趨勢。
-
GitHub Star 數量從 3.6k 增長至 6.8k,多次登上 GitHub Trengding 日/周/月度榜單前列。
-
全部 Commits 數量從 3.7k 增長至 7.6k,過去一年新提交代碼量超越了以往多年累加總和。
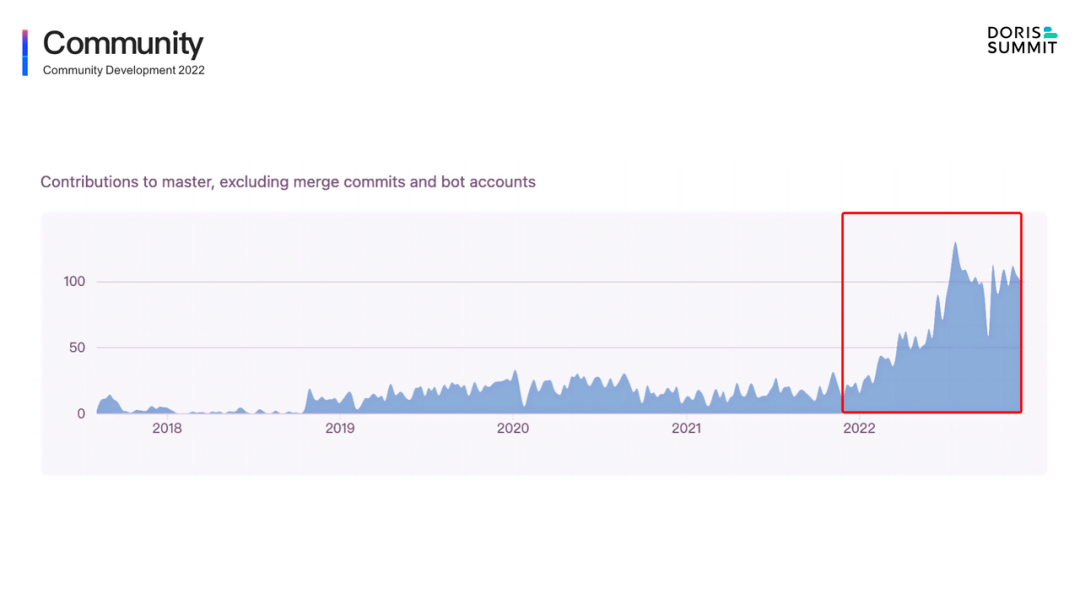
從這些數據中,我們可以感受到 2022 年是 Apache Doris 全面爆發的一年,各個維度數據指標幾乎都有了 100% 的增長。這一年的努力也使 Apache Doris 成為了全球大數據和數據庫領域最為活躍的開源社區之一,上方 GitHub Contribution 增長趨勢圖更是證明了這一點。而這一切,正是由社區所有的用戶和開發者共同創造的。
另外值得紀念的是,在 2022 年 6 月, Apache Doris 迎來了開源以來最重要的里程碑之一,正式從 Apache 孵化器畢業、成為了 Apache 頂級項目。

開源用戶規模
得益于社區成立的專職工程師團隊,為 Apache Doris 社區用戶提供義務的技術支持,2022 年我們在用戶連接與溝通方面變得更加順暢,可以更直面用戶、去傾聽用戶真實的聲音。
在過去的一年里,Apache Doris 已經在互聯網、金融、電信、教育、汽車、制造、物流、能源、政務等數十個行業應用落地,尤其是在以海量數據著稱的互聯網行業。在中國市值或估值排行前 50 的互聯網公司中,有 80% 企業在長期使用 Apache Doris 來解決自身業務中的數據分析問題,其中包含了百度、美團、小米、騰訊、京東、字節跳動、網易、新浪、360、 米哈游、知乎等頭部知名企業。

在全球范圍內,Apache Doris 已經得到了超過 1000 家企業用戶的認可,并且這一數字仍在快速增長中。這 1000 多家企業用戶中,絕大多數與社區有著直接聯系,并通過各種方式參與到社區建設中來。他們中的許多企業用戶也參與到本次 Doris Summit 的議題分享中,將自身基于真實業務場景的實踐經驗分享給大家。
版本更新迭代
如果說過去版本將使用和運維的簡易性作為第一追求的話,那么 2022 年發布版本則是在性能、穩定性、易用性等多方面特性的全面進化。
-
4 月份社區發布了自開源以來的首個 1 位版本—— Apache Doris 1.0,在 1.0 版本中,意義非凡的向量化執行初次與大家見面,標志著 Apache Doris 開始邁入極速數據分析時代。
-
6 月份發布的 1.1 版本,我們對向量化引擎進行了進一步完善和優化,并將其作為正式功能默認開啟。與此同時,社區建立了 LTS 版本發布機制,以每月發布一個 3 位版本的速度,對 1.1 版本進行快速地 Bug 修復和功能優化,力求滿足更多社區用戶在穩定性方面的高要求。
-
在綜合考慮版本迭代節奏和用戶需求后,我們決定將眾多新特性在 1.2 版本中發布。同時期社區的穩定性和質量保障工作也取得了顯著的成效,測試 Case 得到了極大程度地豐富,并在 Master 分支上構建了流水線。通過一系列質量手段,Apache Doris 的代碼質量和穩定性得到進一步提升,這也使得版本發布有著更加嚴格的準出標準。
-
12 月初 1.2 版本正式面世。這一版本的發布不僅使查詢性能有了近十倍的提升,同時我們還推出了過去半年時間里研發的諸多重磅功能,包括 Unique Key 模型 Merge-on-Write 的數據更新模式、支持無縫對接多種數據湖的 Multi-Catalog 多源數據目錄、JAVA UDF 、Array 數組類型和 JSONB 類型等,讓 Apache Doris 在更多數據分析場景具備了更強的適應性和可能性。
-
我們也針對系統穩定性進行了大量的工作,一方面,利用 SQL Smith 等自動化測試工具以及各個知名開源項目的測試用例,構建了數以百萬計的測試用例集;另一方面,通過社區準入流水線和完善的回歸測試框架,保證了代碼合入的質量。因此1.2 版本不論從功能、性能還是穩定性方面,都是一次厚積薄發后的全面進化,也是對所有開發者在 2022 年辛苦付出的最好回報。
核心特性方面,社區的研發力量主要圍繞四個方面開展工作,分別是性能、實時性、半結構化數據支持與 Lakehouse。
-
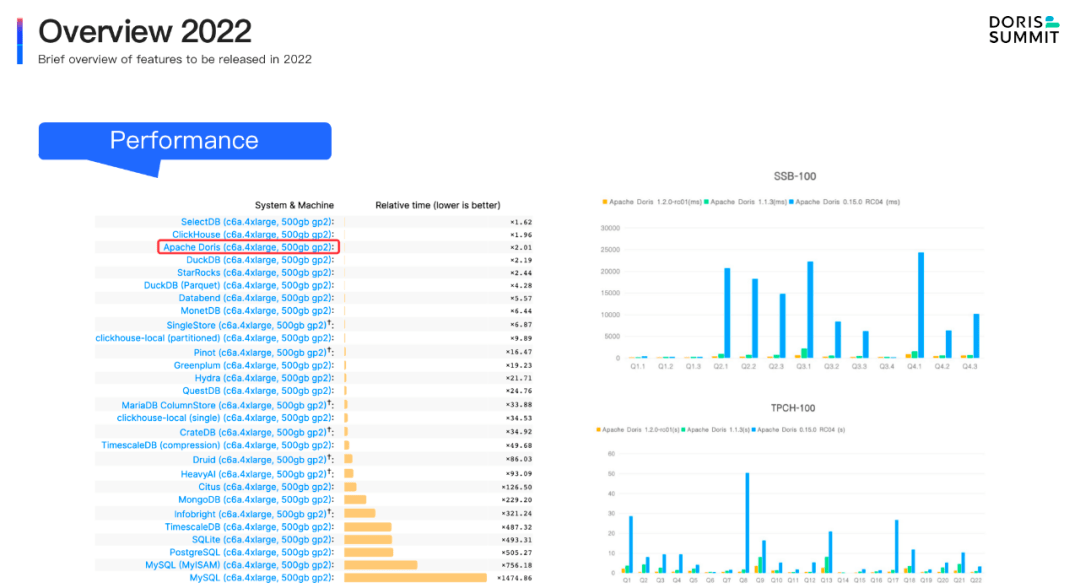
查詢性能提升。從 1.0 版本面世到 1.2 版本發布,Apache Doris 在性能方面取得了極為顯著的成績。在單表場景上,Apache Doris 榮登 Clickhouse 公司推出的 Clickbench 數據庫性能榜單,并取得了前三名的優秀成績。在多表關聯場景上,得益于向量化執行引擎及各種查詢優化技術,相對 2021 年底發布的 0.15 版本 ,Apache Doris 在 SSB 和 TPC-H 等標準測試數據集下均取得了數倍乃至數十倍的性能提升。這一系列性能方面的優化,已經成功讓 Apache Doris 躋身全球數據庫性能最優陣列中!
-
實時場景優化。在 1.2 版本中,我們在原有 Unique Key 數據模型上實現了Merge-On-Write 的數據更新方式,查詢性能在高頻更新時有 5-10 倍的提升,實現了在可更新數據上的低延遲實時分析體驗。另外還實現了輕量 Schema Change 功能,對于數據的加減列不再需要轉換歷史數據,可通過 Flink CDC 等工具快速便捷地同步上游事務數據庫中的 DML 或 DDL 操作,使數據同步工作能夠更加流暢統一。
-
半結構化數據支持。目前 Apache Doris 支持了 Array 和 JSONB 類型,其中 Array 類型不僅能更方便地存儲復雜的數據結構,還可以通過 Array 函數滿足用戶行為分析等場景的業務需求。而 JSONB 是一種二進制 JSON 存儲方式,它不但比純文本 Text JSON 的訪問性能快 4 倍,同時也有更低的內存消耗。通過 JSONB 可以方便地導入各種 JSON 格式的日志數據結構,并能取得優異的查詢效率。這也是 Apache Doris 在日志分析領域所做的探索之一。

-
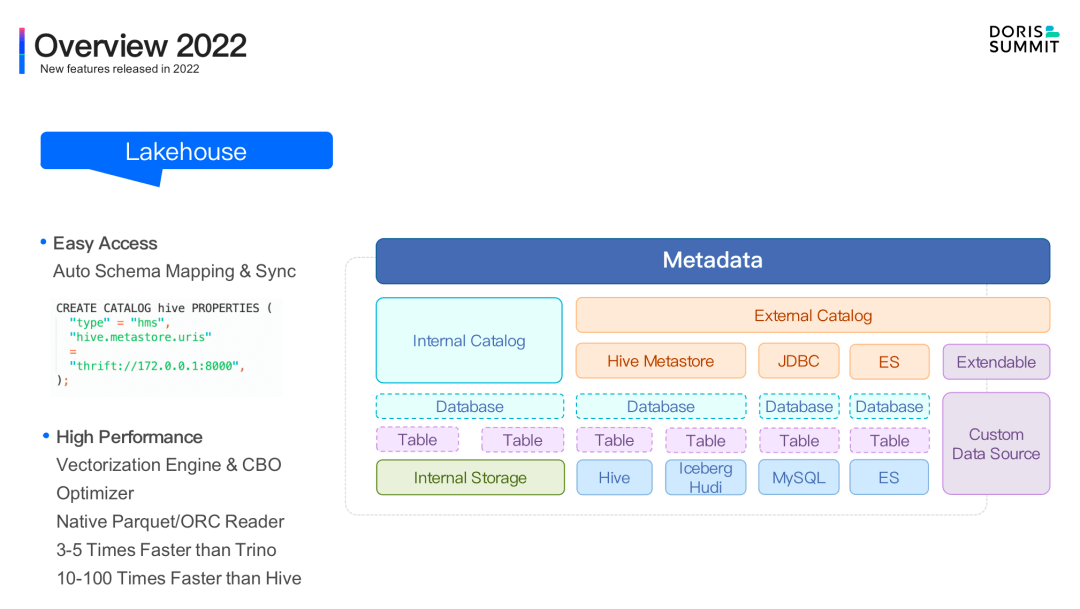
Lakehouse。在最新發布的 1. 2 版本中,我們引入了全新的 Catalog 概念,正式將 Apache Doris 邁入湖倉一體時代。通過簡單的命令便可以方便地連接到各自外部數據源并自動同步元數據,實現統一的分析體驗。通過 Native Format Reader、延遲物化、異步 IO、數據預取等多項針對外部數據源的性能優化,并充分利用自身的高性能執行引擎和查詢優化器,在對外表訪問性能上,Apache Doris 可以達到 Trino/Presto 的 3- 5 倍、Hive 的 10-100 倍。
2023 RoadMap
承前而啟后,2023 年,Apache Doris 社區在以上幾方面特性持續完善的同時,也將開啟更多有意義的工作。全年的 RoadMap 以及明年 Q1 的具體計劃,可以參考以下的全景圖:
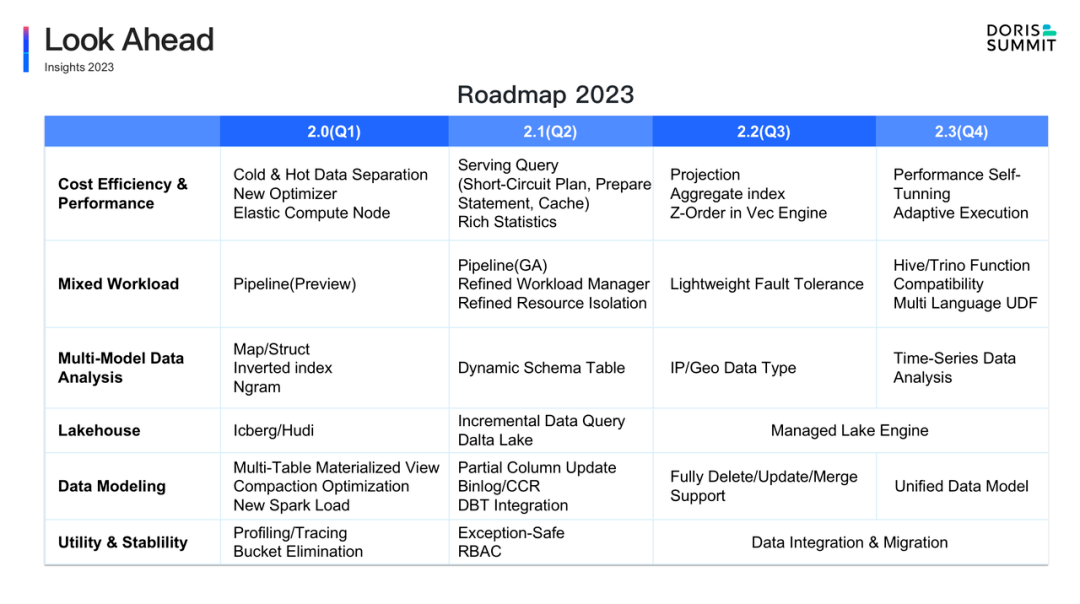
穩定的版本發布和迭代速度對于開源軟件至關重要。在 2023 年,我們將以每季度一個 2 位版本的節奏,開始 Apache Doris 2.x 版本的迭代。同時,針對每個 2 位版本,我們也將以每月一個 3 位版本的速度進行功能維護和優化。
從功能角度來看,后續研發工作將會圍繞以下幾個主要方向展開:
高性能高性能是 Apache Doris 不斷追求的目標,過去一年在 Clickbench、TPC-H 等公開測試數據集上的優異表現,已經證明了其在執行層以及算子優化方面做到了業界領先。未來我們也會不斷優化各個場景下的性能表現,回饋用戶極速的數據分析體驗,具體包括:
-
更復雜SQL性能提升:2022 年我們已經啟動全新查詢優化器的設計與開發,而這一成果在 2023 年一季度就將與大家見面。全新查詢優化器提供了豐富的規則模型,實現了更智能的代價選擇,可以更高效地支撐復雜查詢,能夠完整執行 TPC-DS 全部 99 個SQL。同時全新查詢優化器還具備全查詢場景的自適應優化,便于用戶在面對不同分析負載和業務場景時都獲得一致性的使用體驗。
-
更高的點查詢并發:高并發一直是 Apache Doris 所擅長的場景,而 2023 年我們將會進一步加強這一能力,通過 Short-Circuit Plan、Prepare Statement、Query Cache 等一系列技術,實現單機數萬 QPS 的超高并發支持,并具備隨集群規模的拓展進而線性提升并發的能力。
-
更靈活的多表物化視圖:在過去版本中,通過強一致的單表物化視圖,Apache Doris 加速了固定維度數據的分析效率。而全新的多表物化視圖將會解耦 Base 表與 MV 表的生命周期,通過異步刷新和靈活的增量計算方式,滿足多表關聯以及更復雜 SQL 的預計算加速需求,這一特性將在接下來的 2023 年第一季度與大家見面!
-
更低的存儲成本:我們將探索與云上對象存儲系統和文件系統的結合,幫助用戶進一步降低存儲成本,包括更完善的冷熱數據分離能力,將冷數據智能轉移至更廉價的對象存儲或文件系統中。結合單一遠程副本、冷數據 Cache 以及冷熱智能轉換等技術,保證業務查詢效率不受影響的同時實現存儲成本大幅降低,這一功能將于 2023 年第一季度發布。
-
更彈性的計算資源:剝離存儲與計算狀態,引入僅用于計算的 Elastic Compute Node 。由于不存儲數據,彈性計算節點具備更加快速的彈性伸縮能力,便于用戶在業務高峰期進行快速擴容,進一步提升在海量數據計算場景(如數據湖分析)的分析效率,這一功能已經處于最終調試階段,即將與大家見面。后續我們還將通過對集群內存和 CPU 運行指標的監控和自動策略配置,實現自動的節點擴縮容(Auto-scaling)。
-
更靈活的 Pipeline 執行引擎:與傳統的火山模型相比,Pipeline 模型無需手動設置并發度,可以實現不同管道之間的并行計算,充分利用多核的計算能力,實現更靈活的執行調度,提升在混合負載場景下的綜合性能表現。
-
Workload Manager:在性能提升的同時,也亟需完善的資源隔離和劃分的能力。我們將會基于 Pipeline 執行引擎實現更細粒度和更靈活的負載管理、資源隊列以及共享隔離等功能,兼顧多種混合負載場景下的查詢性能與穩定性。
-
輕量級容錯:輕量級容錯能力也是我們后續持續完善的地方,既能利用 MPP 的高效率又能對錯誤進行容忍,以更好適應用戶在 ETL/ELT 場景的挑戰。
-
函數兼容與多語言UDF:與此同時,后續也將支持 Hive/Trino/Spark 函數的兼容性以及多語言的 UDF,來幫助用戶更靈活地進行數據加工,也可以更方便地從其他數據庫系統遷移到 Apache Doris。
-
更豐富的復雜數據類型:除 Array/JSONB 類型以外,2023 年第一季度我們將增加對 Map/Struct 類型的支持,包括高效寫入、存儲、分析函數以及類型之間的相互嵌套,以更好滿足多模態數據分析的支持。后續將支持更加豐富的數據類型,包括 IP、GEO 地理信息等數據類型,并會探索在時序數據場景的高效數據分析。
-
更高效的文本分析算法:對于文本數據,我們將引入更多的文本分析算法,包括自適應 Like、高性能子串匹配、高性能正則匹配,Like 語句的謂詞下推、Ngram Bloomfilter 等,同時基于倒排索引實現全文檢索能力,在日志分析場景提供比 ES 更高性能和性價比的分析能力。這些功能都已經處于就緒階段,將在 2023 年初與大家見面。
-
動態 Schema 表:傳統數據庫在設計之初 Schema 是靜態的,Schema 變更時需要執行 DDL ,而這一操作往往具有阻塞性。在越來越多的現代數據分析場景中,表結構會隨時間推移而變化,因此我們引入了 Dynamic Table,可以根據數據寫入自動適應 Schema ,不再需要執行 DDL,由過去的人工干預數據結構進化為數據自驅動,極大提升了靈活數據分析的便捷性。這一功能將在 2022 年第一季度正式發布。
-
更簡易的數據對接:在 1.2 版本中我們發布了 Multi-Catalog,支持了多種異構數據源的元數據自動映射與同步,實現了數據湖的無縫對接,后續將對 Delta Lake 的支持以及 Iceberg、Hudi 等更多數據格式的支持。
-
更完整的數據湖能力支持:提供數據湖上數據的增量更新與查詢,還會支持將分析結果寫回數據湖、外表寫入內表,實現數據分析流程的全閉環。同時還將支持多版本 Snapshot 讀取和刪除,并進一步在 Apache Doris 為數據湖數據提供物化視圖。
-
更穩定的數據寫入:通過一系列 Compaction 操作和批量數據寫入方面的優化,節省資源開銷,降低寫放大問題,并結合全新的內存管理框架提升寫入過程的內存穩定性,進而提升系統穩定性。
-
更完善的數據更新支持:過去部分列更新是通過 Agg 模型上的 Replace_if_not_null 來實現的,后續我們將會增加 Unique Key 模型上的部分列更新支持,并完整實現 Delete、Update、 Merge 等數據更新的操作。
-
更統一的數據模型:當前 Apache Doris 的三種數據模型在各個場景均有豐富的應用,后續我們將嘗試統一現有幾種數據模型,使用戶在使用體驗上更加統一。
-
簡化建表:目前 Apache Doris 在建表時分區已經支持了時間函數,后續我們將進一步消除 Bucket 設置,幫助用戶最大程度簡化建表建模。
-
安全性:目前已經實現基于 RBAC 模型的權限管理機制,使用戶權限更安全可靠;并對 ID-federation、行列級別權限,數據脫敏等進行了優化,后續將進一步完善。
-
可觀測性:Profile 是定位查詢性能問題的重要手段,后續我們將加強對 Profile 的監控并提供可視化 Profile 工具,幫助用戶更快定位問題。
-
更好的 BI 兼容性和更完善的數據集成遷移方案:當前各 BI 工具可以通過 MySQL 協議連接到 Apache Doris,后續我們將對主流 BI 軟件進一步適配,保證更佳的查詢體驗。隨著 DBT、Airbyte 等新興數據集成和遷移工具的興起,越來越多用戶使用此類系統將數據同步至 Apache Doris ,后續我們也會提供對此些系統的官方支持。
開啟下一個十年!
或許有讀者或聽眾還記得我在開頭提的問題,對于 Apache Doris,十年意味著什么?
有兩層含義,上一個十年和下一個十年。
上一個十年,是 Apache Doris 起源的十年。從誕生到開源、從默默無聞到被越來越多人熟知和使用,開源賦予了 Apache Doris 更加旺盛的生命力和創造力。
而下一個十年,則是一場新的旅程。
正如我在本次 Doris Summit 分享的主題,New Journey of Apache Doris。如果說過去 Apache Doris 更多是服務于在線報表場景和 Ad-hoc 分析的 OLAP 引擎的話,那么在所有社區和開發者的努力下,當前 Apache Doris 已經具備了更為廣闊的定位,即極速、易用、實時、統一的多模分析型數據庫。
這其中的統一,既包含了架構的統一、也包含了業務和數據的統一。用戶可以通過 Apache Doris 構建多種不同場景的數據分析服務、同時支撐在線與離線的業務負載、高吞吐的交互式分析與高并發的點查詢;通過一套架構實現湖和倉的統一、在數據湖和多種異構存儲之上提供無縫且極速的分析服務;也可通過對日志/文本等半結構化乃至非結構化的多模數據進行統一管理和分析、來滿足更多樣化數據分析的需求。
這是我們希望 Apache Doris 能夠帶給用戶的價值,不再讓用戶在多套系統之間權衡,僅通過一個系統解決絕大部分問題,降低復雜技術棧帶來的開發、運維和使用成本,最大化提升生產力。
“我們已經出發了太久,以至于忘記了為什么出發。”
希望通過這一定位的轉變迎接下一個十年的挑戰,或許技術趨勢會有變化,架構將會革新,但我們解決用戶數據分析問題的初衷不會改變。
希望繼續帶著上一個十年出發的初心,開啟下一個十年的旅程。
本文來自于 Doris Summit 2022 演講實錄,演講人:陳明雨





