
作者 | 火山引擎EMR團隊
眾所周知,基于 Hadoop 的 EMR 體系發(fā)展到現(xiàn)在,經(jīng)歷了很多個階段。從基于 IDC 機房通過 CDH 去部署的 1. 0 階段,演進到在公有云上面按照存算分離的辦法去進行的 2. 0 階段。
而在這些基礎(chǔ)上,火山引擎數(shù)智平臺 VeDI 的 EMR 團隊又探索出了無狀態(tài)的 EMR 3.0 演進階段。上個月底,火山引擎 EMR 正式上線瞬態(tài)集群新功能,該能力基于業(yè)界領(lǐng)先的 EMR Stateless 理念,可以實現(xiàn)集群級別的彈性伸縮,即無業(yè)務(wù)需求時釋放集群,有業(yè)務(wù)需求時再拉起集群,從而幫助企業(yè)大幅降低產(chǎn)品使用和平臺運維成本。
什么是瞬態(tài)集群,什么是 Stateless 理念,本文從基礎(chǔ)概念、架構(gòu)體系、演進過程、實際運用場景&使用價值等多個角度全方位介紹 EMR Stateless 的創(chuàng)新理念以及應(yīng)用。

什么是 Stateless?
Stateless——它的本質(zhì)是一個瞬態(tài)集群的概念,但又不完全是瞬態(tài)集群,它屬于一個輕量級交付的、無狀態(tài)的瞬態(tài)集群。那無狀態(tài)的瞬態(tài)集群又是什么意思呢?
首先,Stateless 的集群是在存算分離的基礎(chǔ)上,進一步演化而得來的一個瞬態(tài)集群。普通的存算分離集群,像 Hadoop 體系里的相關(guān)內(nèi)容都是綁定在集群中的,沒有徹底將這些有狀態(tài)的內(nèi)容剝離出來成為一個獨立的服務(wù)。而 Stateless 是把 Hive Metastore 以及 History Server 等進行了服務(wù)化,也就是從計算集群中把它們剝離出來了。
在 Stateless 的加持下,我們所指的 Hadoop 體系中的 Master、Core、Task 等節(jié)點就組成一個無狀態(tài)的輕量級瞬態(tài)集群,可以被隨時創(chuàng)建或釋放,并擁有多個副本,這無疑可以讓集群具備一個更好的擴展性。基于此,接下來就能夠在云原生的基礎(chǔ)上,以集群的視野,去更好的做能力的成長以及成本的優(yōu)化。

接下來,為大家對比一下 Stateful 模式和 Stateless 模式,它們兩個之間有什么典型的差異點?
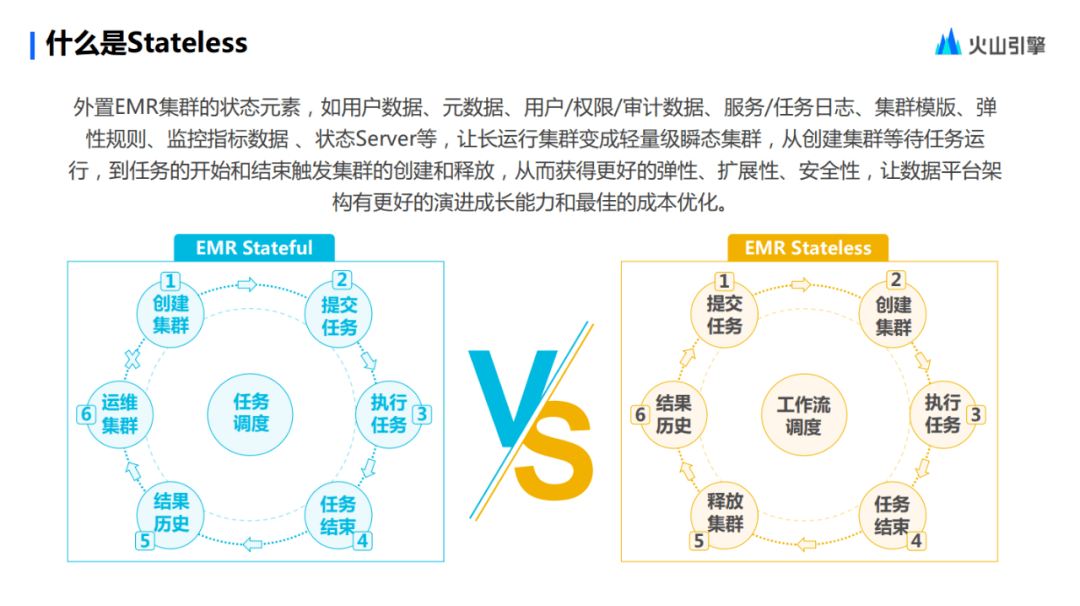
左邊這個流程圖,是一個傳統(tǒng)的 Stateful 模式。
在這個模式下,大家要提交一個任務(wù)的數(shù)據(jù)流程通常是這樣的,首先必須要有一個長時間運行的集群,有了集群以后,再將任務(wù)提交上去,接下來無論是通過 IO 的直接返回,還是把數(shù)據(jù)寫入到 HDFS 或是對象存儲,執(zhí)行結(jié)束后都將拿到歷史結(jié)果。
站在大數(shù)據(jù)維護視角來看,在提交任務(wù)的流程結(jié)束以后,運維長時間運行的集群,無論是對它的運行狀態(tài)進行監(jiān)控,看看它是否出現(xiàn)了故障,還是對它存在的服務(wù)進行日志采集,這些動作都會產(chǎn)生一定量的運維成本。同時,在任務(wù)結(jié)束后,這些集群事實上變?yōu)榱艘粋€空置的集群。站在總成本承受的角度上來講,這其實是一個不利的選項,以上就是典型的Stateful模式。
而在 Stateless 的模式下,這一切就會有所變化。
首先,操作的第一步直接變?yōu)榱颂峤蝗蝿?wù)。在提交任務(wù)以后,集群會被及時地、按需地創(chuàng)建出來用于運行任務(wù)。當(dāng)任務(wù)運行完成以后,集群將會被釋放掉。在用戶拿到計算結(jié)果之后,意味著整個的任務(wù)提交過程隨之結(jié)束。
在這個過程中,由于 Stateless 已經(jīng)把具有狀態(tài)屬性的,像日志服務(wù)之類的功能外置于集群。在集群釋放以后,用戶仍可以通過日志服務(wù)查詢到任何一個時間段內(nèi),在 Stateless 集群模板下面的集群里執(zhí)行過的任何一個任務(wù)結(jié)果。
在這樣的流程中,用戶是不需要去運維執(zhí)行集群的。這就是 Stateful 和 Stateless 最大的不同點。

看了以上的內(nèi)容,大家肯定會產(chǎn)生一些問題,有一些概念性的普遍問題,在這里可以先跟大家講解一下。
1.Stateless 跟 Serverless 的區(qū)別?
首先,Serverless 相比于 Stateless,其實就是全托管和半托管的區(qū)別。在半托管的情況下,用戶需要自我的去運維一些集群資源以及集群配置相關(guān)的內(nèi)容,而在全托管的情況下,用戶可以省去這部分的配置,但是也會失去了一些自定義配置集群的靈活性。
而 Stateless 其實是處于一個半托管的場景下面,基于 on cluster 形態(tài)的云原生優(yōu)化體系,它和 Serverless 這種全托管的形態(tài)是沒有什么本質(zhì)聯(lián)系的。它們相似之處,是在對資源的使用上面都比較充分,只有在執(zhí)行任務(wù)時才會有計算資源存在。
2.Stateless 瞬態(tài)集群,瞬態(tài)怎么理解?
關(guān)于這個問題,更深層次的一個點就是瞬態(tài),達到怎樣一種時間粒度才叫瞬態(tài)?
首先,我們來對比一下瞬態(tài)集群和普通的云上 EMR 集群。普通 EMR 集群是長時間部署的,可能會部署一周兩周,甚至一個月兩個月的時間。而瞬態(tài)集群是當(dāng)有任務(wù)到來時,我們?yōu)檫@些任務(wù)創(chuàng)建一個集群,任務(wù)運行完就把集群釋放掉。
同樣的,在第二次創(chuàng)建的時候,就可以直接進行一個類似復(fù)制的操作,集群的配置和規(guī)格和之前都是一致的。對用戶來講,做到這個程度是沒有任何代價的。用戶只需要去定義這個集群,Stateless 就能按需創(chuàng)建出這樣的一個瞬態(tài)集群,并且這個瞬態(tài)集群的時間粒度是分鐘級的,無需考慮間隔得太久會發(fā)生什么錯誤。
3.Stateless 它適合哪些業(yè)務(wù)場景?
基于我們的實踐場景來談,首先它適合需要存算分離的用戶,并且更適合離線跑批的場景。計算量比較大,并且具有明顯的潮汐性質(zhì)特征時,在節(jié)約成本上面的體現(xiàn)是非常明顯的。
4.Stateless是否需要用戶改變使用習(xí)慣?
在用戶使用方面,并不需要對流程進行改變。Stateless只是在云原生管控層面進行了優(yōu)化,并且是在無狀態(tài)服務(wù)剝離層面的優(yōu)化。對于用戶接口,無論是開源的 web UI還是開源引擎的對外接口,任務(wù)提交流程無任何變化,這些完全都是開源兼容的,大家可以一直享受開源社區(qū)版本迭代所帶來的技術(shù)紅利。
Stateless 大數(shù)據(jù)體系
了解完以上內(nèi)容,大家應(yīng)該對 Stateless 有一個初步的認識了,接下來再給大家介紹該體系是怎么實現(xiàn)的。
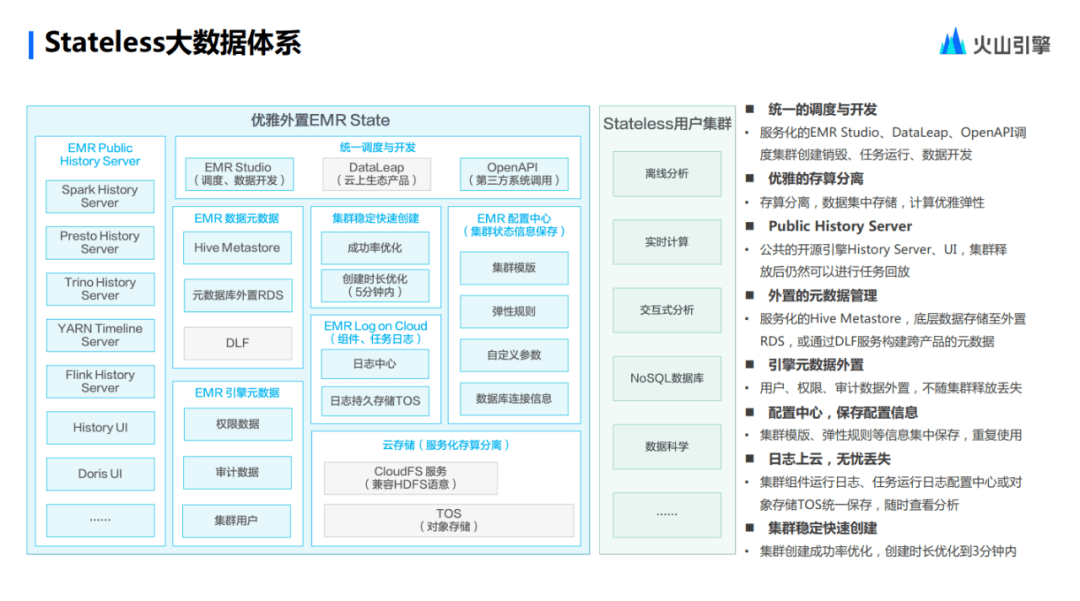
首先,在 Stateless 的架構(gòu)體系里,用戶集群包含了離線分析(Hadoop 體系)、實時計算( Flink 體系)、交互式分析、 NoSQL 數(shù)據(jù)庫以及機器學(xué)習(xí)等相關(guān)內(nèi)容。這個是帶有計算特性的集群中,所有帶有狀態(tài)部分的內(nèi)容都被剝離了。Stateless把 History Serverhe 和 UI 相關(guān)的內(nèi)容都剝離成為獨立服務(wù),包含 Spark History Server, Presto History Server, YARN Timeline Server 等。不管集群是否存在,這些服務(wù)都在。
其次,通過 Open API 做了統(tǒng)一的調(diào)度和開發(fā)封裝。同時將 EMR Studio服務(wù)化( EMR Studio可以理解成類似于 Oozie、Airflow、 DolphinScheduler 等的調(diào)度引擎)。用戶可以在火山引擎 EMR 上面直接使用這些服務(wù),而不需要通過提交機器來部署。
依托于火山引擎豐富的云上生態(tài),Stateless 還可以無縫對接數(shù)據(jù)研發(fā)類產(chǎn)品。除此以外,EMR 元數(shù)據(jù),包括 Hive Metastore 內(nèi)置元數(shù)據(jù)庫、外置的 RDS 等,也被抽取到統(tǒng)一的服務(wù)里。相信使用過 Hive Metastore 的小伙伴,肯定沒有少被 Metastore 的 RDS 給坑過,RDS 有個風(fēng)吹草動,那么 Hive Metastore 就會有問題,但這些問題現(xiàn)在都可以被云原生服務(wù)有效解決 。
同時,配置中心也對集群做了一層集群,如集群配置、所需組件等,都會以虛擬形式存儲。同時,引擎的元數(shù)據(jù)做了服務(wù)化,包括權(quán)限管控、用戶體系等。
最后,Stateless 解決了非常困擾運維的一個問題——日志把本地磁盤寫滿。在 Stateless 體系下面不會再有這樣的問題,通過 TOS 對象存儲,日志都是落在一個按需的對象存儲上面。對象存儲可以被認為是無限大的,所以無需為它所占的磁盤空間去擔(dān)心,只需要去定義好它的生命周期,這個問題就能被解決。
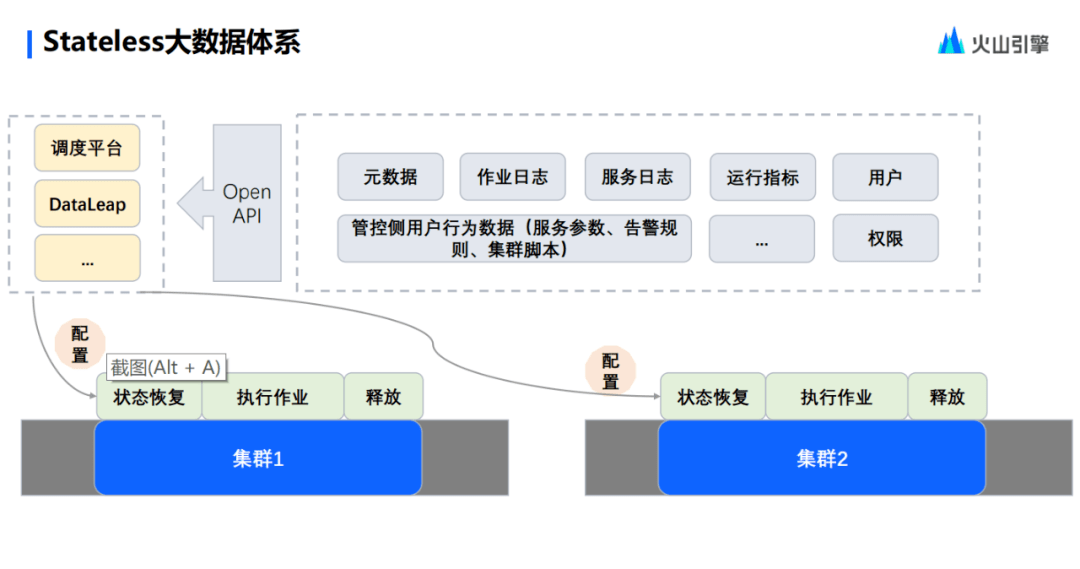
上文提到了 Stateless 基礎(chǔ)的大數(shù)據(jù)體系,現(xiàn)在就進入一個環(huán)節(jié),在狀態(tài)流上用一個 case 為大家講解一下剛才的體系。
首先,從上圖可以看到,虛線框框住的就是 Stateless 從實體集群里抽象出來的,像元數(shù)據(jù)服務(wù)、管控服務(wù)等一系列服務(wù),有 Web UI,也有 Open API。這些 Open API 會作為控制集群創(chuàng)建和銷毀的 trigger,相關(guān)指令會交到調(diào)度平臺上,例如 Airflow, DolphinScheduler 等。調(diào)度平臺在提交任務(wù)的時候,會通過接口對集群的生命周期做一些影響。
其次,再到 trigger 這一層,主要通過云原生提供的 Open API就能夠去控制集群了。如果要提交任務(wù),就會去新起一個集群,并且對集群做一個狀態(tài)的恢復(fù),這是指任務(wù)希望有一個什么樣的集群配置。這個配置可能是版本參數(shù),也有可能是一些機型的配置。無論是什么樣的配置,Stateless 都能忠實地將集群恢復(fù)到初始化的樣子。因為集群是無狀態(tài)的,執(zhí)行作業(yè)完成后, 就會釋放掉實體的集群,它的生命周期也就結(jié)束了。
上面的這個 case,講的是單獨一個任務(wù)的提交。但在實踐的過程中,往往集群可能會被提交多個任務(wù)上來,這種情況下直到所有任務(wù)執(zhí)行完畢,實體集群就會被釋放。當(dāng)集群釋放完以后,如果又有任務(wù)需要提交了,同理,只需要再去起一個配置相同的集群,再來做任務(wù)的執(zhí)行,執(zhí)行完了以后再釋放。這就是Stateless 體系運轉(zhuǎn)的大致流程。
Stateless 演進過程
理解完概念性和結(jié)構(gòu)性的內(nèi)容以后,接下來再分享一下 EMR Stateless 的演進過程。EMR Stateless,聽上去是一個比較新的東西,我們?yōu)槭裁匆@么去做這個呢?
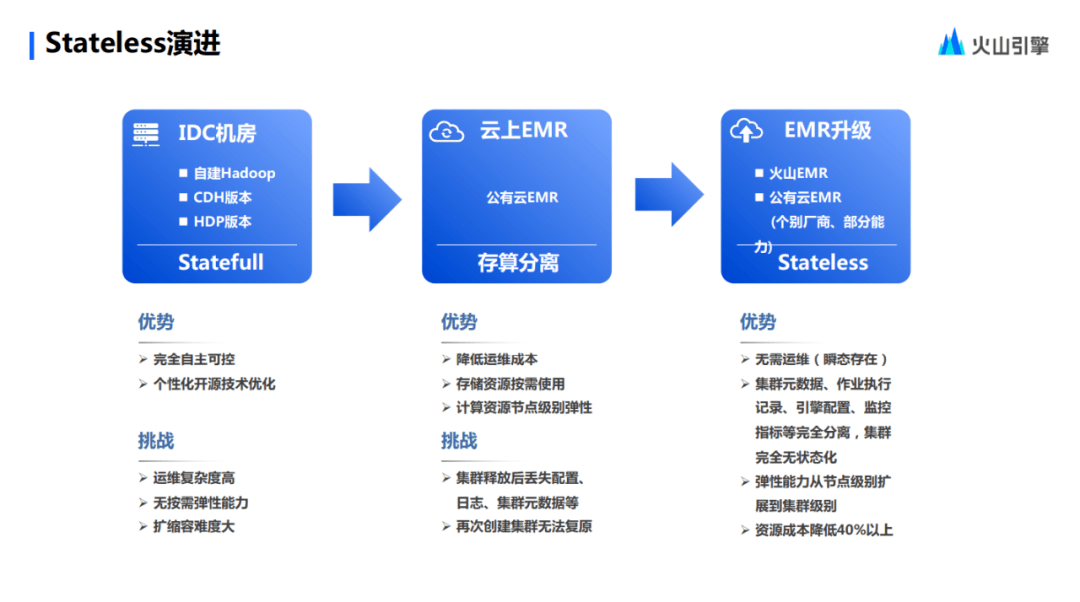
在開篇中,跟大家分享了基于 Hadoop 的 EMR 體系的很多個階段。
首先是基于 IDC 機房通過 CDH 去部署的 1. 0 階段,到現(xiàn)在仍有不少的用戶是基于1.0這個體系在做運營。它也有它的好處,無論加資源還是其他操作,是完全可控的。當(dāng)然也存在很多問題,比如運維的復(fù)雜度很高,并且由于存算一體的架構(gòu),閑置了很大的計算資源,沒有辦法進行按需計算的場景。
基于這些問題,演進出了在公有云上按照存算分離的辦法去建設(shè)的 2.0 階段。通過把存儲資源和計算資源分開,讓計算資源盡量地做到按需分配。當(dāng)然這也有限制和前提,它的計算資源是按照節(jié)點去做彈性的。所以在 2.0時代,它解決的最根本的問題還是一個計算和存儲之間的解耦。
但是,火山引擎的 EMR 團隊發(fā)現(xiàn) 2.0 時代的一些問題,影響到了日常的運維和集群的穩(wěn)定性。基于這兩點,我們首先考慮到了彈性的能力,對集群整體去做一個彈性的伸縮,而做這個的前提條件是要解耦集群和相關(guān)的集群元數(shù)據(jù),在這些基礎(chǔ)上做了集群無狀態(tài)化,也就是集群服務(wù)的剝離。
談到這里,Stateless的 優(yōu)勢其實就體現(xiàn)出來了。首先,Stateless 集群是百分之百不用去運維的,因為它只在運行時瞬態(tài)地出現(xiàn)。其次,集群的服務(wù)也無需用戶去擔(dān)心,并且它還保留了半托管模式的優(yōu)點。在經(jīng)過技術(shù)研判和綜合判斷后,相比起 EMR 1.0時代的IDC機房線下部署模式,使用 EMR Stateless 的資源成本能夠達到百分之四十以上的優(yōu)化。
以上就是EMR Stateless 演進的過程,以及火山引擎EMR團隊關(guān)于Stateless的考慮思路和歷程。
接下來,再跟大家詳細地分享一下各個feature是怎么去演進的。
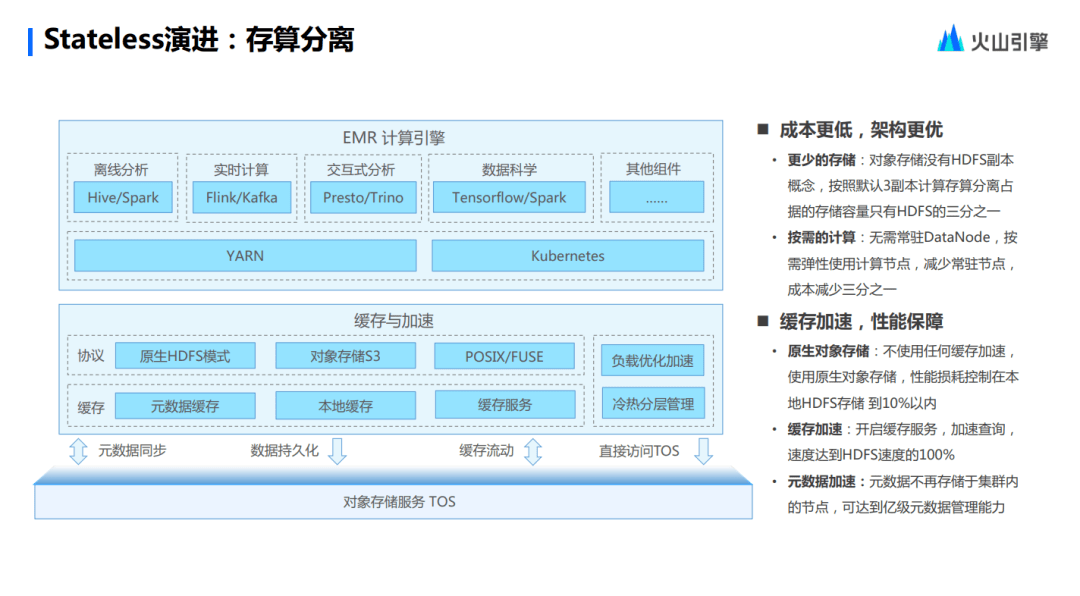
首先,存算分離其實是 EMR 2.0 時代的產(chǎn)物。到了Stateless的環(huán)境下,首先保留了所有EMR 2.0 里的一些 feature 。而在新的這一層上面,最主要的功能就是對負載進行了優(yōu)化加速,這個可以認為是本地的 local shuffer,這樣速度會更快。
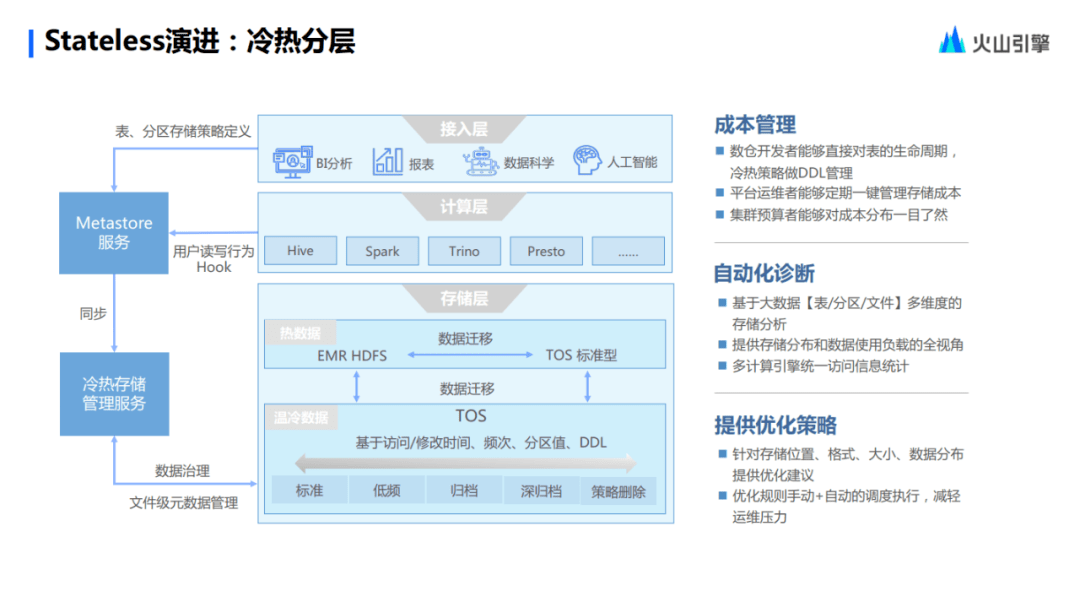
并且進一步提供了冷熱分層的管理,可以直接的去控制和定義冷熱分層的行為,這也是成本節(jié)約的前提。計算資源已經(jīng)做到極致優(yōu)化,所以存儲資源上面也需要及時優(yōu)化。
首先平臺會自動地去診斷用戶的冷熱分層,診斷的前提是什么?從上圖中來看, 用戶在火山 EMR 這一側(cè)的所有讀寫行為,會經(jīng)過 Metastore 服務(wù),了解哪些是冷數(shù)據(jù),哪些是熱數(shù)據(jù)。
基于用戶對表的定義,接下來再做自動化的診斷,并且把這些診斷以及預(yù)測,暴露給運維的人員,讓他們看到診斷的結(jié)果,并且給出平臺的建議。再由人工的判斷,三位一體的來讓冷數(shù)據(jù)找到自己最終的歸宿。在這個話題上面,Stateless提供的冷數(shù)據(jù)分層層次也是比較多的,從標(biāo)準(zhǔn)到低頻,再到歸檔,再到冷藏,再到最后的刪除,能夠給不同特點的數(shù)據(jù)找到最合適的存儲點。這個也是Stateless為用戶賦能的一個方面。
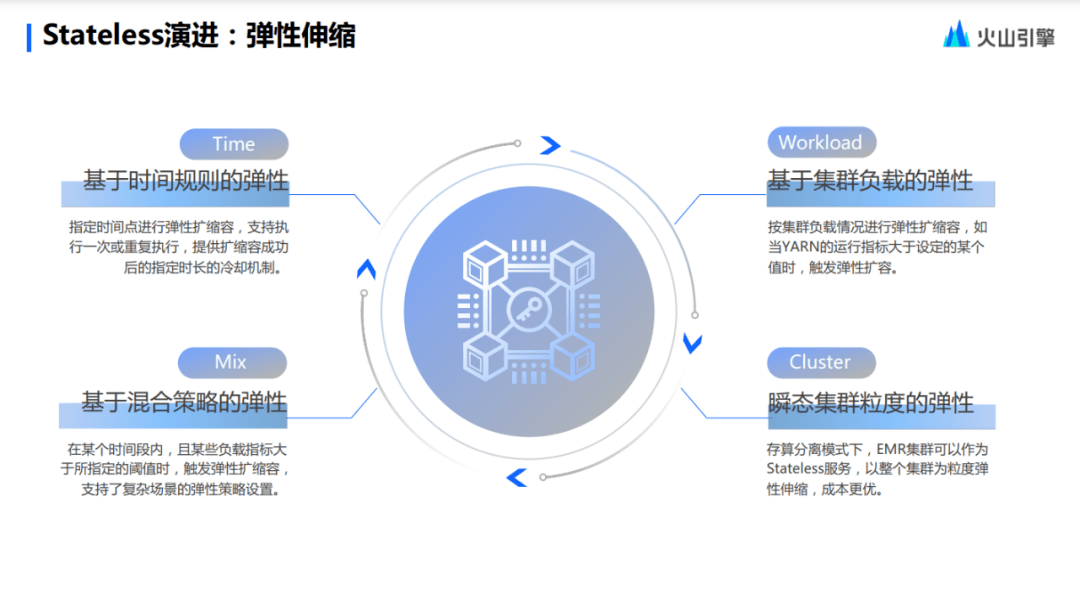
彈性伸縮,這也是演進 Stateless 產(chǎn)生出來的一個重大 feature。
對于彈性伸縮,主流分成兩種,第一種是基于時間的彈性伸縮,比如運維人員知道幾點到幾點是高峰,幾點到幾點是低谷。第二種是基于負載指標(biāo)的一個彈性伸縮,因為可能會有特殊情況出現(xiàn),比如說在一個時間范圍內(nèi),數(shù)值突然變大或者變小,或者是基于負載情況。
關(guān)于這一點,火山引擎 EMR 有獨有的設(shè)定,可以把時間和負載混合起來用。并且,這樣的混合彈性模式除了作用在 Hadoop 集群的節(jié)點上以外,它還可以作用在整個的瞬態(tài)集群上面。
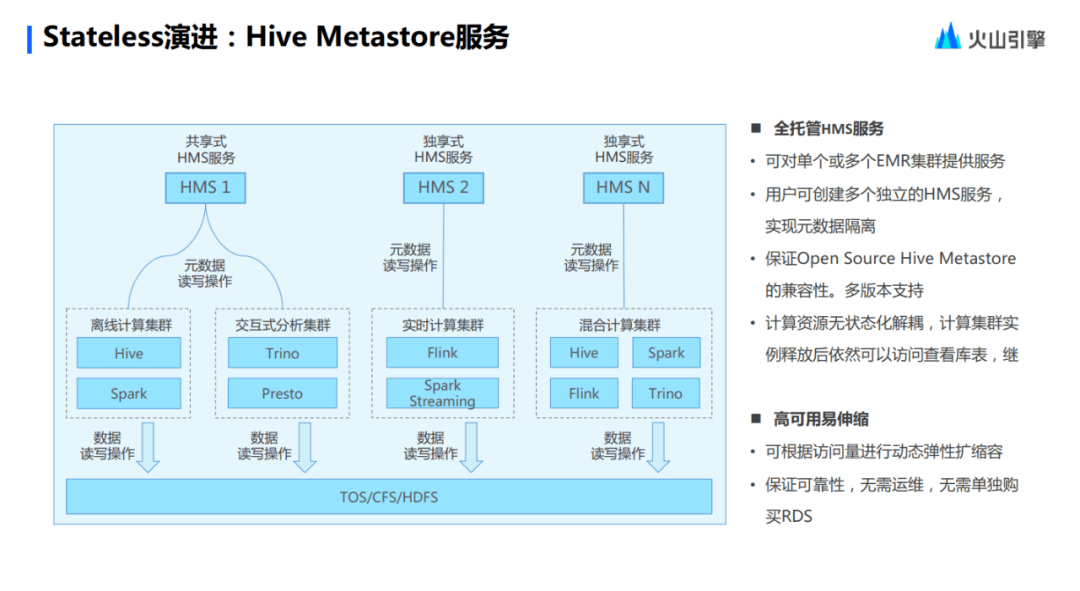
Hive Metastore 服務(wù)上文也有提到過,無論是離線任務(wù)的元數(shù)據(jù)也好,或者是對實時以及實時離線混部,它的元數(shù)據(jù)其實都是可以托管至 Hive Metastore 。
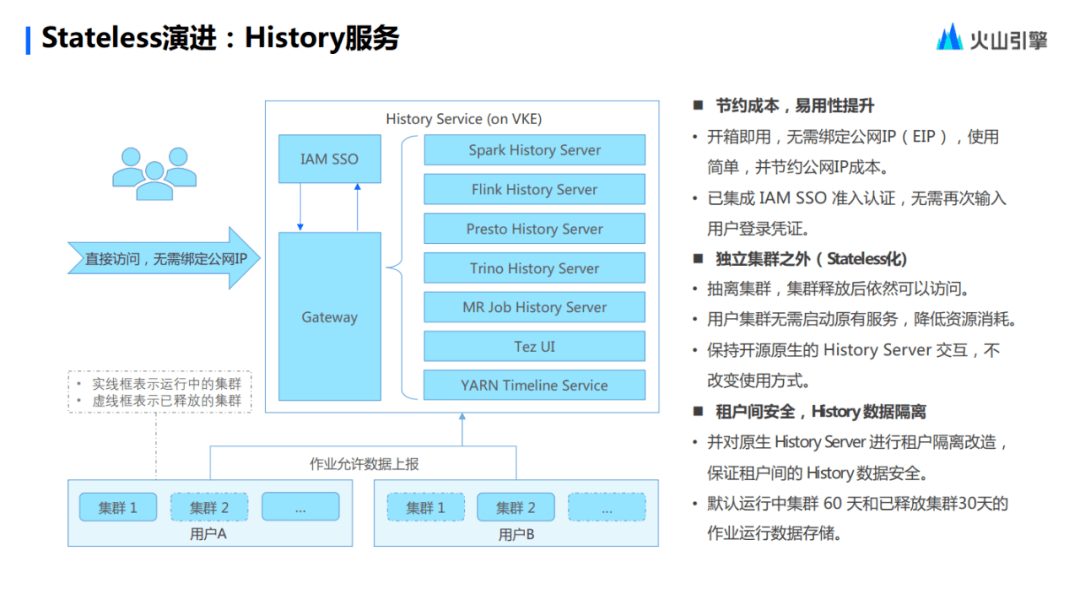
目前,Stateless 已經(jīng)實現(xiàn)了 Public History Server 一系列的服務(wù)。它是可以獨立于集群實體而存在的,并且在集群運行的時候,這些作業(yè)就會上報數(shù)據(jù)到 Public History Server 服務(wù)。用戶可以直接地通過域名去訪問,不用進行綁定 IP 這些比較繁雜的一些環(huán)節(jié)。
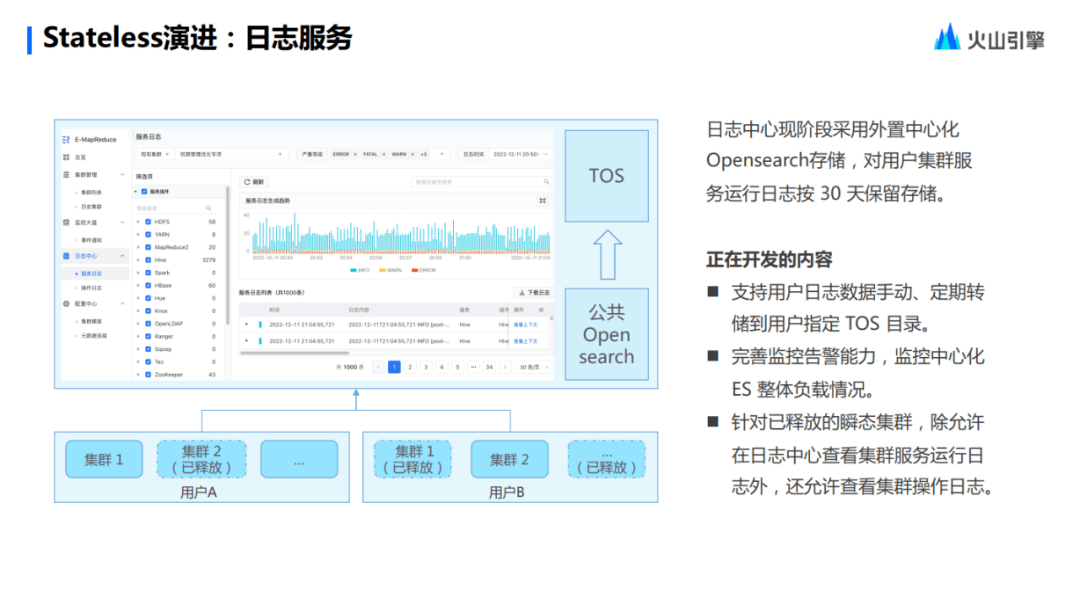
依托于云上產(chǎn)品生態(tài),Stateless 也升級了日志服務(wù),它基于 OpenSearch,最終數(shù)據(jù)落地在 TOS 上面。面對數(shù)據(jù)的丟失,或者是數(shù)據(jù)磁盤的影響,這些用戶都不需要去考慮和運維,但目前這部分功能還沒有徹底的成熟,還需要一段時間完善。
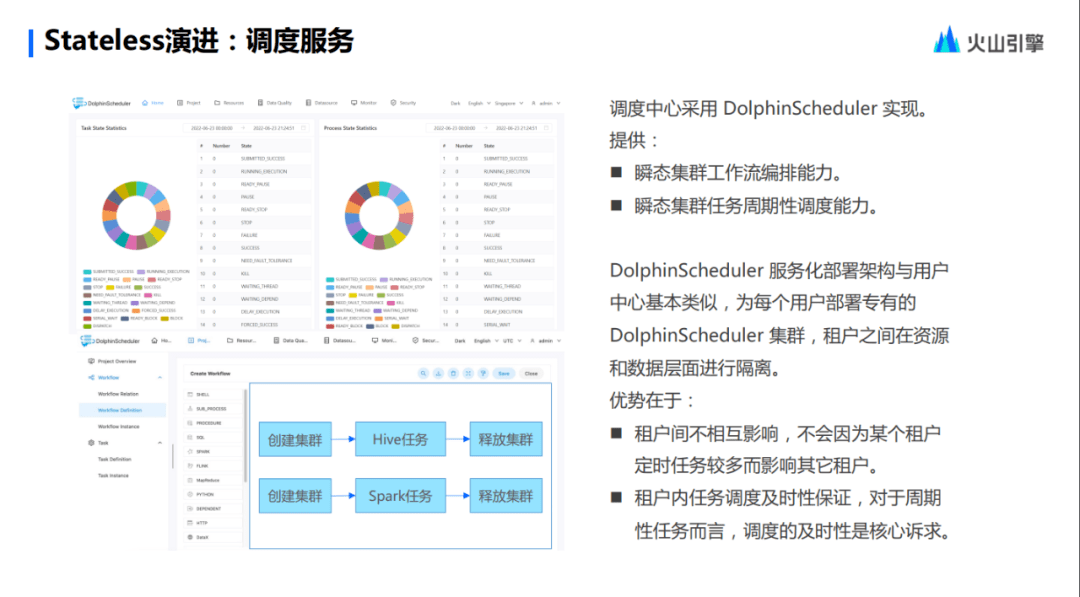
關(guān)于調(diào)度服務(wù),我們對 DolphinScheduler, Airflow 等這些具備調(diào)度能力的服務(wù)也做到了集成,為什么會去集成這些內(nèi)容?是因為這些組件會去調(diào)創(chuàng)建集群的 API 任務(wù),會隨著調(diào)度系統(tǒng)里邊的任務(wù)提交去觸發(fā),Stateless 把這些方法全部都集成服務(wù)化,用戶無需自己去部署,可以直接做到一個開箱即用。
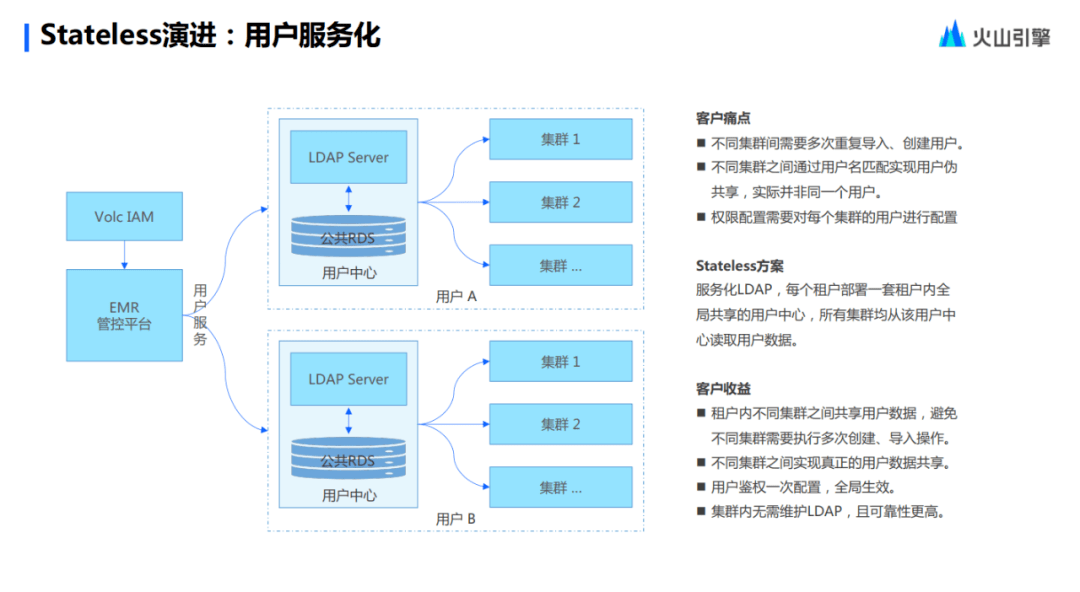
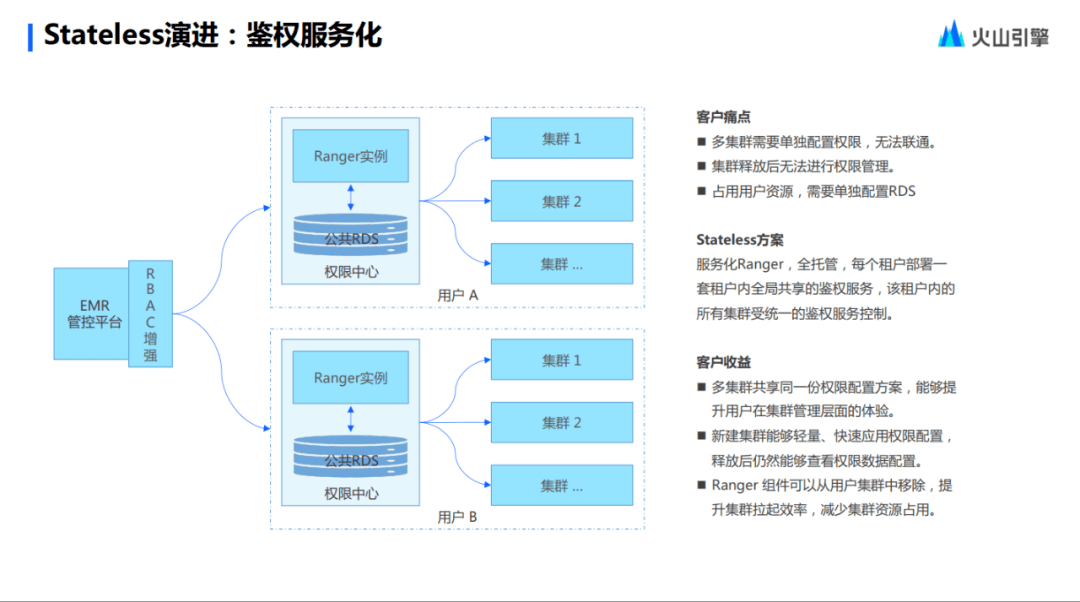
最后,把用戶服務(wù)化以及鑒權(quán)服務(wù)化的內(nèi)容合并分享給大家。第一是用戶的服務(wù)化以及用戶權(quán)限的服務(wù)化。用戶的服務(wù)化,就是把 LDAP 集成為統(tǒng)一的用戶管理服務(wù)。當(dāng)然還是保留 LDAP 這一層級的,比如用戶習(xí)慣用 LDAP 的 UI ,這些用戶自己操作也沒有任何問題,不用反復(fù)操作一個集群去導(dǎo)入用戶的體系,這是收益最大的一件事。
同理,Stateless 鑒權(quán)服務(wù)使用 Ranger ,因為 Ranger是 RBAC 的概念,而在 RBAC 的概念上面,Stateless還抽象了 RBAC 的這一層概念,讓用戶可以去做更豐富的權(quán)限的一套配置。并且,這個權(quán)限和用戶的系統(tǒng)是互通的,做到了一套用戶系統(tǒng)加一套權(quán)限,可以覆蓋所有的跟用戶和角色權(quán)限相關(guān)的 RPC 模型,這也是Stateless演進過程中很重要的一個能力。
Stateless 業(yè)務(wù)價值
最后跟大家分享一下 Stateless 的業(yè)務(wù)價值。
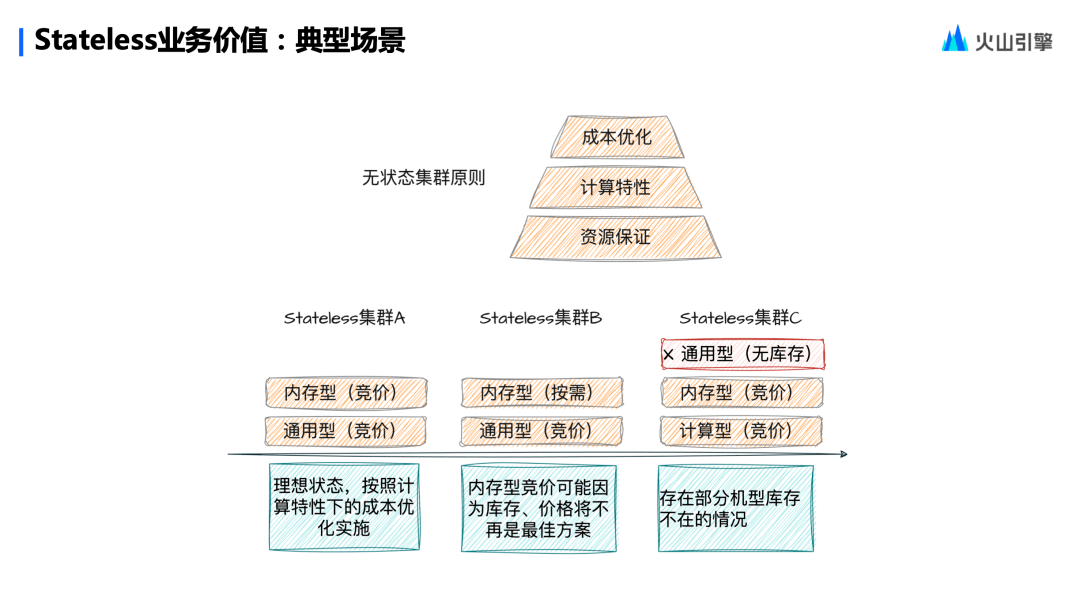
首先介紹下體現(xiàn)業(yè)務(wù)價值的一個典型場景——
無狀態(tài)集群是一些什么樣的集群?如何把成本做到優(yōu)化呢?
第一,為用戶創(chuàng)建的無狀態(tài)集群時,所選云服務(wù)器的機型可能會不一樣。首先它是一個金字塔結(jié)構(gòu),在最下面一層,首先保證用戶的計算資源。
第二,盡量滿足用戶的計算特性。比如 word count 或者 CPU 密集型的計算用不了多少內(nèi)存,我們會盡量幫用戶節(jié)約內(nèi)存的資源,選擇 CPU 和內(nèi)存比例比較接近的機型。
第三,幫用戶做成本優(yōu)化。兩種計價模型,一種是按需、一種是競價。原則上來講,競價比按需便宜,且因為無狀態(tài)集群時間短,我們會盡量地給用戶選便宜機型。比如說用戶傾向的一個機型無庫存了,怎么辦?我們盡量在價格以及配置上面選擇跟用戶定義類似的機型,以保證用戶的計算任務(wù)是能夠執(zhí)行的。
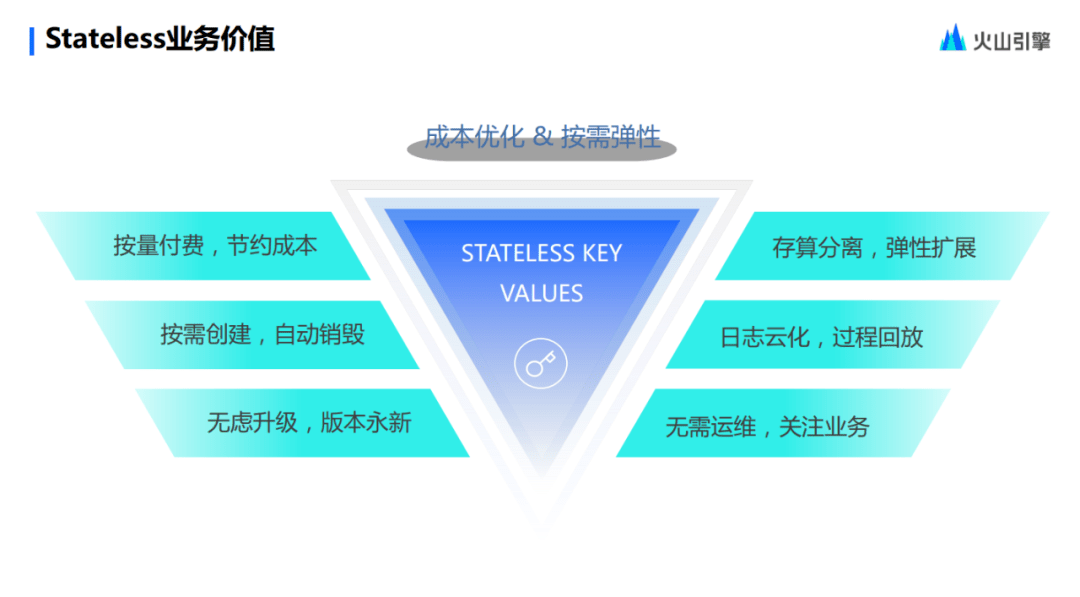
最后,做一個簡單的總結(jié),Stateless 都有什么好處?
首先,其實就是很簡單的按量付費。按需創(chuàng)建,自動銷毀,用戶無需關(guān)心集群的狀態(tài),因為它隨著任務(wù)總會有的。其次,它永遠處于一個迭代的狀態(tài),大家可以永遠地去享受開源社區(qū)版本迭代帶來的一個紅利,因為我們是永遠擁抱開源的,這也是我們火山引擎 EMR 不會放棄的一個初心。
然后就是存算分離和彈性擴展,彈性擴展具有一定先進性,可以在集群的力度上完成。日志是冪等的且上云的,隨時都能看到,用戶不用對日志有過多的運維。
最后,談到運維,Stateless把有狀態(tài)的服務(wù)抽取出來,用戶無需再去關(guān)心跟集群服務(wù)相關(guān)的內(nèi)容,只用關(guān)心運行計算、計算debug和計算診斷這些方面就足夠了。





