擊這里在線咨詢客服")
免責(zé)聲明:本文旨在傳遞更多市場(chǎng)信息,不構(gòu)成任何投資建議。文章僅代表作者觀點(diǎn),不代表MarsBit官方立場(chǎng)。
小編:記得關(guān)注哦
來(lái)源:JEDI LU
原文標(biāo)題:機(jī)器之心的進(jìn)化 / 理解 AI 驅(qū)動(dòng)的軟件 2.0 智能革命
就在過(guò)去幾個(gè)月里,因?yàn)槊缆?lián)儲(chǔ)的加息,科技公司的資本狂歡宣告結(jié)束,美國(guó)上市的 SaaS 公司股價(jià)基本都跌去了 70%,裁員與緊縮是必要選項(xiàng)。但正當(dāng)市場(chǎng)一片哀嚎的時(shí)候,Dall-E 2 發(fā)布了,緊接著就是一大批炫酷的 AI 公司登場(chǎng)。這些事件在風(fēng)投界引發(fā)了一股風(fēng)潮,我們看到那些兜售著基于生成式 AI(Generative AI)產(chǎn)品的公司,估值達(dá)到了數(shù)十億美元,雖然收入還不到百萬(wàn)美元,也沒(méi)有經(jīng)過(guò)驗(yàn)證的商業(yè)模式。不久前,同樣的故事在 Web 3 上也發(fā)生過(guò)!感覺(jué)我們又將進(jìn)入一個(gè)全新的繁榮時(shí)代,但人工智能這次真的能帶動(dòng)科技產(chǎn)業(yè)復(fù)蘇么?
本文將帶你領(lǐng)略一次人工智能領(lǐng)域波瀾壯闊的發(fā)展史,從關(guān)鍵人物推動(dòng)的學(xué)術(shù)進(jìn)展、算法和理念的涌現(xiàn)、公司和產(chǎn)品的進(jìn)步、還有腦科學(xué)對(duì)神經(jīng)網(wǎng)絡(luò)的迭代影響,這四個(gè)維度來(lái)深刻理解“ 機(jī)器之心的進(jìn)化”。先忘掉那些花里胡哨的圖片生產(chǎn)應(yīng)用,我們一起來(lái)學(xué)點(diǎn)接近 AI 本質(zhì)的東西。全文共分為六個(gè)章節(jié):
- AI 進(jìn)化史- 前神經(jīng)網(wǎng)絡(luò)時(shí)代、machine Learning 的躍遷、開啟潘多拉的魔盒
- 軟件 2.0 的崛起- 軟件范式的轉(zhuǎn)移和演化、Software 2.0 與 Bug 2.0
- 面向智能的架構(gòu)- Infrastructure 3.0、如何組裝智能、智能架構(gòu)的先鋒
- 一統(tǒng)江湖的模型- Transformer 的誕生、基礎(chǔ)模型、AI 江湖的新機(jī)會(huì)
- 現(xiàn)實(shí)世界的 AI- 自動(dòng)駕駛新前沿、機(jī)器人與智能代理
- AI 進(jìn)化的未來(lái)- 透視神經(jīng)網(wǎng)絡(luò)、千腦理論、人工智能何時(shí)能通用?
文章較長(zhǎng),累計(jì) 22800 字,請(qǐng)留出一小時(shí)左右的閱讀時(shí)間,歡迎先收藏再閱讀!文中每一個(gè)鏈接和引用都是有價(jià)值的,特別作為衍生閱讀推薦給大家。
閱讀之前先插播一段 Elon Musk 和 Jack Ma 在 WAIC 2019 關(guān)于人工智能的對(duì)談的經(jīng)典老視頻,全程注意 Elon Ma 的表情?? 大家覺(jué)得機(jī)器智能能否超過(guò)人類么?帶著這個(gè)問(wèn)題來(lái)閱讀,相信看完就會(huì)有系統(tǒng)性的答案!
本文在無(wú)特別指明的情況下,為了書寫簡(jiǎn)潔,在同一個(gè)段落中重復(fù)詞匯大量出現(xiàn)時(shí),會(huì)用 AI(Artifical Intelligence)來(lái)代表 人工智能,用 ML(Machine Learning)來(lái)代表機(jī)器學(xué)習(xí),DL(Deep Learning)來(lái)代表深度學(xué)習(xí),以及各種英文縮寫來(lái)優(yōu)先表達(dá)。
01 AI 進(jìn)化史
對(duì)于機(jī)器是否真能 "知道"、"思考 "等問(wèn)題,我們很難嚴(yán)謹(jǐn)?shù)亩x這些。我們對(duì)人類心理過(guò)程的理解,或許只比魚對(duì)游泳的理解更好一點(diǎn)。John McCarthy
早在 1945 年,Alan Turing 就已經(jīng)在考慮如何用計(jì)算機(jī)來(lái)模擬人腦了。他設(shè)計(jì)了 ACE(Automatic Computing Engine - 自動(dòng)計(jì)算引擎)來(lái)模擬大腦工作。在給一位同事的信中寫道:"與計(jì)算的實(shí)際應(yīng)用相比,我對(duì)制作大腦運(yùn)作的模型可能更感興趣 ...... 盡管大腦運(yùn)作機(jī)制是通過(guò)軸突和樹突的生長(zhǎng)來(lái)計(jì)算的復(fù)雜神經(jīng)元回路,但我們還是可以在 ACE 中制作一個(gè)模型,允許這種可能性的存在,ACE 的實(shí)際構(gòu)造并沒(méi)有改變,它只是記住了數(shù)據(jù) ......" 這就是 機(jī)器智能的起源,至少那時(shí)在英國(guó)都這樣定義。
1.1 前神經(jīng)網(wǎng)絡(luò)時(shí)代
神經(jīng)網(wǎng)絡(luò) 是以模仿人腦中的 神經(jīng)元 的運(yùn)作為 模型 的計(jì)算機(jī)系統(tǒng)。
AI 是伴隨著神經(jīng)網(wǎng)絡(luò)的發(fā)展而出現(xiàn)的。 1956 年,美國(guó)心理學(xué)家 Frank Rosenblatt 實(shí)現(xiàn)了一個(gè)早期的神經(jīng)網(wǎng)絡(luò)演示 - 感知器模型(Perceptron Model),該網(wǎng)絡(luò)通過(guò)監(jiān)督 Learning的方法將簡(jiǎn)單的圖像分類,如三角形和正方形。這是一臺(tái)只有八個(gè)模擬神經(jīng)元的計(jì)算機(jī),這些神經(jīng)元由馬達(dá)和轉(zhuǎn)盤制成,與 400 個(gè)光探測(cè)器連接。
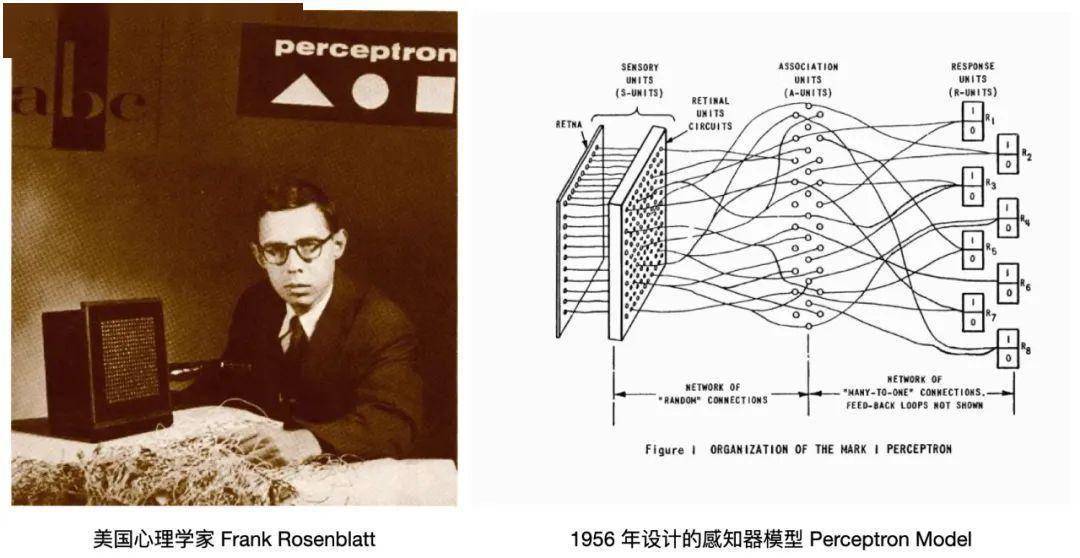
配圖01:Frank Rosenblatt & Perceptron Model
IBM 的 Georgetown 實(shí)驗(yàn)室在這些研究的基礎(chǔ)上,實(shí)現(xiàn)了最早的機(jī)器語(yǔ)言翻譯系統(tǒng),可以在英語(yǔ)和俄語(yǔ)之間互譯。 1956 年的夏天,在 Dartmouth College 的一次會(huì)議上, AI 被定義為計(jì)算機(jī)科學(xué)的一個(gè)研究領(lǐng)域,Marvin Minsky(明斯基), John McCarthy(麥卡錫), Claude Shannon(香農(nóng)), 還有 Nathaniel Rochester(羅切斯特)組織了這次會(huì)議,他們后來(lái)被稱為 AI 的 "奠基人"。

配圖02:Participants of the 1956 Dartmouth Summer Research Project on AI
DARPA 在這個(gè)“黃金”時(shí)期,將大部分資金投入到 AI 領(lǐng)域,就在十年后他們還發(fā)明了 ARP.NET(互聯(lián)網(wǎng)的前身)。早期的 AI 先驅(qū)們?cè)噲D教計(jì)算機(jī)做模仿人類的復(fù)雜心理任務(wù),他們將其分成五個(gè)子領(lǐng)域: 推理、 知識(shí)表述、 規(guī)劃、 自然語(yǔ)言處理(NLP)和 感知,這些聽起來(lái)很籠統(tǒng)的術(shù)語(yǔ)一直沿用至今。
從專家系統(tǒng)到機(jī)器學(xué)習(xí)
1966 年,Marvin Minsky 和 Seymour Papert 在《感知器:計(jì)算幾何學(xué)導(dǎo)論》一書中闡述了因?yàn)橛布南拗疲挥袔讓拥纳窠?jīng)網(wǎng)絡(luò)僅能執(zhí)行最基本的計(jì)算,一下子澆滅了這條路線上研發(fā)的熱情,AI 領(lǐng)域迎來(lái)了第一次泡沫破滅。這些先驅(qū)們?cè)趺匆矝](méi)想到,計(jì)算機(jī)的速度能夠在隨后的幾十年里指數(shù)級(jí)增長(zhǎng),提升了上億倍。
在上世紀(jì)八十年代,隨著電腦性能的提升,新計(jì)算機(jī)語(yǔ)言 Prolog & Lisp 的流行,可以用復(fù)雜的程序結(jié)構(gòu),例如條件循環(huán)來(lái)實(shí)現(xiàn)邏輯,這時(shí)的人工智能就是 專家系統(tǒng)(Expert System),iRobot 公司絕對(duì)是那個(gè)時(shí)代明星;但短暫的繁榮之后,硬件存儲(chǔ)空間的限制,還有專家系統(tǒng)無(wú)法解決具體的、難以計(jì)算的邏輯問(wèn)題,人工智能再一次陷入窘境。
我懷疑任何非常類似于形式邏輯的東西能否成為人類推理的良好模型。
Marvin Minsky
直到 IBM 深藍(lán)在 1997 年戰(zhàn)勝了國(guó)際象棋冠軍卡斯帕羅夫后,新的基于 概率推論(Probabilistic Reasoning)思路開始被廣泛應(yīng)用在 AI 領(lǐng)域,隨后 IBM Watson 的項(xiàng)目使用這種方法在電視游戲節(jié)目《Jeopardy》中經(jīng)常擊敗參賽的人類。
概率推論就是典型的 機(jī)器學(xué)習(xí)(Machine Learning)。今天的大多數(shù) AI 系統(tǒng)都是由 ML 驅(qū)動(dòng)的,其中預(yù)測(cè)模型是根據(jù)歷史數(shù)據(jù)訓(xùn)練的,并用于對(duì)未來(lái)的預(yù)測(cè)。這是 AI 領(lǐng)域的第一次范式轉(zhuǎn)變,算法不指定如何解決一個(gè)任務(wù),而是根據(jù)數(shù)據(jù)來(lái)誘導(dǎo)它,動(dòng)態(tài)的達(dá)成目標(biāo)。因?yàn)橛辛?ML,才有了 大數(shù)據(jù)(Big Data)這個(gè)概念。
1.2 Machine Learning 的躍遷
Machine Learning 算法一般通過(guò)分析數(shù)據(jù)和推斷模型來(lái)建立參數(shù),或者通過(guò)與環(huán)境互動(dòng),獲得反饋來(lái)學(xué)習(xí)。人類可以注釋這些數(shù)據(jù),也可以不注釋,環(huán)境可以是模擬的,也可以是真實(shí)世界。
Deep Learning
Deep Learning是一種 Machine Learning算法,它使用多層神經(jīng)網(wǎng)絡(luò)和反向傳播(Backpropagation)技術(shù)來(lái)訓(xùn)練神經(jīng)網(wǎng)絡(luò)。該領(lǐng)域是幾乎是由 Geoffrey Hinton 開創(chuàng)的,早在 1986 年,Hinton 與他的同事一起發(fā)表了關(guān)于深度神經(jīng)網(wǎng)絡(luò)(DNNs - Deep Neural Networks)的開創(chuàng)性論文,這篇文章引入了 反向傳播 的概念,這是一種調(diào)整權(quán)重的算法,每當(dāng)你改變權(quán)重時(shí),神經(jīng)網(wǎng)絡(luò)就會(huì)比以前更快接近正確的輸出,可以輕松的實(shí)現(xiàn)多層的神經(jīng)網(wǎng)絡(luò),突破了 1966 年 Minsky 寫的 感知器局限 的魔咒。
配圖03:Geoffrey Hinton & Deep Neural Networks
數(shù)據(jù)是新的石油

配圖04:FeiFei Li & ImageNet
該數(shù)據(jù)集對(duì)研究人員非常有用,正因?yàn)槿绱耍兊迷絹?lái)越有名,為最重要的年度 DL 競(jìng)賽提供了基準(zhǔn)。僅僅七年時(shí)間,ImageNet 讓獲勝算法對(duì)圖像中的物體進(jìn)行分類的準(zhǔn)確率從 72% 提高到了 98%,超過(guò)了人類的平均能力。
ImageNet 成為 DL 革命的首選數(shù)據(jù)集,更確切地說(shuō),是由 Hinton 領(lǐng)導(dǎo)的 AlexNet 卷積神經(jīng)網(wǎng)絡(luò)(CNN - Convolution Neural Networks)的數(shù)據(jù)集。ImageNet 不僅引領(lǐng)了 DL 的革命,也為其他數(shù)據(jù)集開創(chuàng)了先例。自其創(chuàng)建以來(lái),數(shù)十種新的數(shù)據(jù)集被引入,數(shù)據(jù)更豐富,分類更精確。
神經(jīng)網(wǎng)絡(luò)大爆發(fā)
在 Deep Learning 理論和數(shù)據(jù)集的加持下, 2012年以來(lái)深度神經(jīng)網(wǎng)絡(luò)算法開始大爆發(fā),卷積神經(jīng)網(wǎng)絡(luò)(CNN)、遞歸神經(jīng)網(wǎng)絡(luò)(RNN - Recurrent Neural Network)和長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM - Long Short-Term Memory)等等,每一種都有不同的特性。例如,遞歸神經(jīng)網(wǎng)絡(luò)是較高層的神經(jīng)元直接連接到較低層的神經(jīng)元。
1.3 開啟潘多拉的魔盒
從 2012 到現(xiàn)在,深度神經(jīng)網(wǎng)絡(luò)的使用呈爆炸式增長(zhǎng),進(jìn)展驚人。現(xiàn)在 Machine Learning 領(lǐng)域的大部分研究都集中在 Deep Learning 方面,就像進(jìn)入了潘多拉的魔盒被開啟了的時(shí)代。

配圖06:AI 進(jìn)化史
GAN
配圖07:GANs 模擬生產(chǎn)人像的進(jìn)化
GANs 將有助于創(chuàng)建圖像,還可以創(chuàng)建現(xiàn)實(shí)世界的軟件模擬,Nvidia 就大量采用這種技術(shù)來(lái)增強(qiáng)他的現(xiàn)實(shí)模擬系統(tǒng),開發(fā)人員可以在那里訓(xùn)練和測(cè)試其他類型的軟件。你可以用一個(gè)神經(jīng)網(wǎng)絡(luò)來(lái)“壓縮”圖像,另一個(gè)神經(jīng)網(wǎng)絡(luò)來(lái)生成原始視頻或圖像,而不是直接壓縮數(shù)據(jù),Demis Hassabis 在他的一篇論文中就提到了人類大腦“海馬體”的記憶回放也是類似的機(jī)制。
大規(guī)模神經(jīng)網(wǎng)絡(luò)
大腦的工作方式肯定不是靠某人用規(guī)則來(lái)編程。Geoffrey Hinton
大規(guī)模神經(jīng)網(wǎng)絡(luò)的競(jìng)賽從成立于 2011 年的 google Brain 開始,現(xiàn)在屬于 Google Research。他們推動(dòng)了 TensorFlow 語(yǔ)言的開發(fā),提出了萬(wàn)能模型 Transformer 的技術(shù)方案并在其基礎(chǔ)上開發(fā)了 BERT,我們?cè)诘谒恼轮袑⒃敿?xì)討論這些。
DeepMind 是這個(gè)時(shí)代的傳奇之一,在 2014 年被 Google 以 5.25 億美元收購(gòu)的。它專注游戲算法,其使命是 "解決智能問(wèn)題",然后用這種智能來(lái) "解決其他一切問(wèn)題"!DeepMind 的團(tuán)隊(duì)開發(fā)了一種新的算法 Deep Q-Network (DQN),它可以從經(jīng)驗(yàn)中學(xué)習(xí)。 2015 年 10 月AlphaGo 項(xiàng)目首次在圍棋中擊敗人類冠軍李世石;之后的 AlphaGo Zero 用新的可以自我博弈的改進(jìn)算法讓人類在圍棋領(lǐng)域再也無(wú)法翻盤。
另一個(gè)傳奇 OpenAI,它是一個(gè)由 Elon Musk, Sam Altman, Peter Thiel, 還有 Reid Hoffman 在 2015 年共同出資十億美金創(chuàng)立的科研機(jī)構(gòu),其主要的競(jìng)爭(zhēng)對(duì)手就是 DeepMind。OpenAI 的使命是 通用人工智能(AGI – Artificial General Intelligence),即一種高度自主且在大多數(shù)具有經(jīng)濟(jì)價(jià)值的工作上超越人類的系統(tǒng)。 2020年推出的 GPT-3 是目前最好的自然語(yǔ)言生成工具(NLP - Natural Language Processing)之一,通過(guò)它的 API 可以實(shí)現(xiàn)自然語(yǔ)言同步翻譯、對(duì)話、撰寫文案,甚至是代碼(Codex),以及現(xiàn)在最流行的生成圖像(DALL·E)。
Gartner AI HypeCycle
Gartner 的技術(shù)炒作周期(HypeCycle)很值得一看,這是他們 2022 年最新的關(guān)于 AI 領(lǐng)域下各個(gè)技術(shù)發(fā)展的成熟度預(yù)估,可以快速了解 AI 進(jìn)化史 這一章中不同技術(shù)的發(fā)展階段。
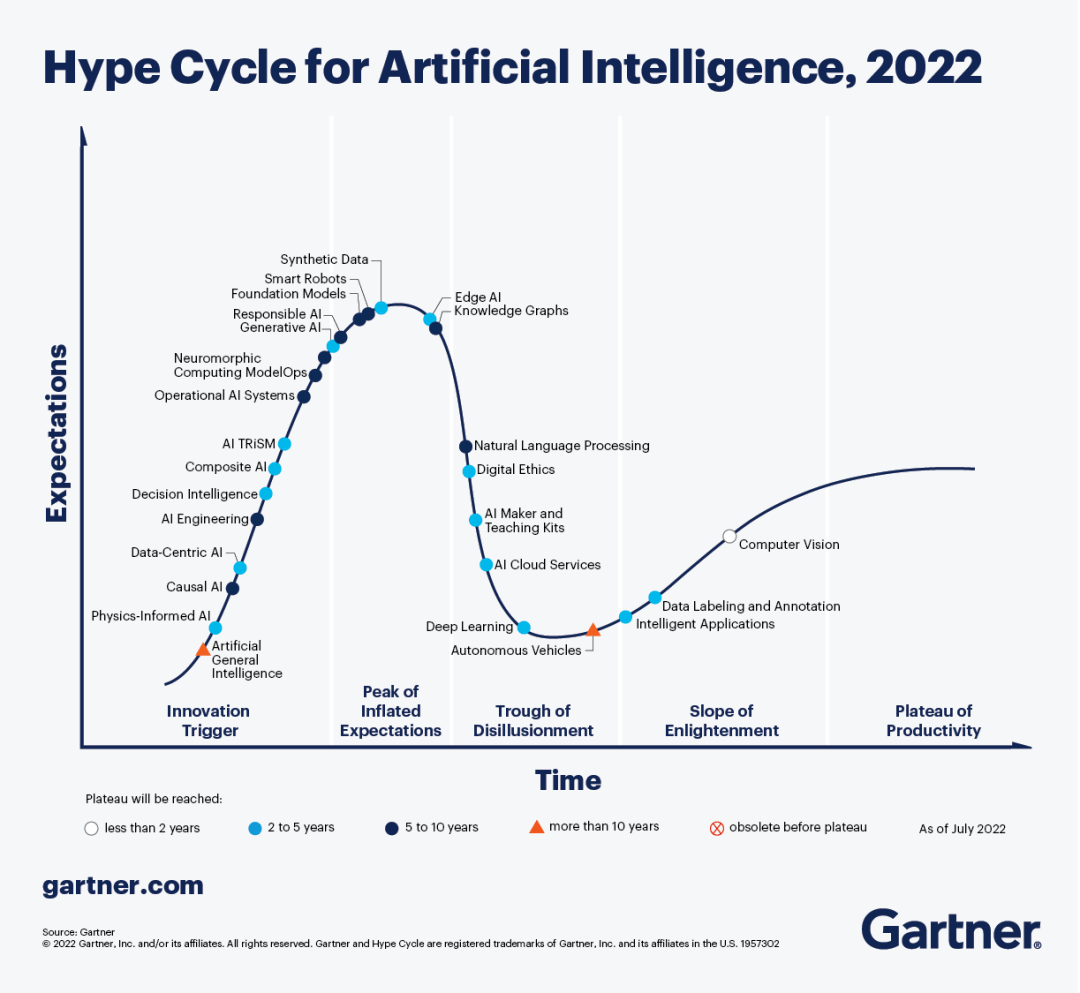
配圖08:Gartner AI HypeCycle 2022
神經(jīng)網(wǎng)絡(luò),這個(gè)在上世紀(jì) 60 年代碰到的挫折,然后在 2012 年之后卻迎來(lái)了新生。 反向傳播 花了這么長(zhǎng)時(shí)間才被開發(fā)出來(lái)的原因之一就是該功能需要計(jì)算機(jī)進(jìn)行 乘法矩陣運(yùn)算。在上世紀(jì) 70 年代末,世界上最強(qiáng)的的超級(jí)電腦之一 Cray-1,每秒浮點(diǎn)運(yùn)算速度 50 MFLOP,現(xiàn)在衡量 GPU 算力的單位是 TFLOP(Trillion FLOPs),Nvidia 用于數(shù)據(jù)中心的最新 GPU Nvidia Volta 的性能可以達(dá)到 125 TFLOP,單枚芯片的速度就比五十年前世界上最快的電腦強(qiáng)大 250 萬(wàn)倍。 技術(shù)的進(jìn)步是多維度的,一些生不逢時(shí)的理論或者方法,在另一些技術(shù)條件達(dá)成時(shí),就能融合出巨大的能量。
02 軟件 2.0 的崛起
未來(lái)的計(jì)算機(jī)語(yǔ)言將更多地關(guān)注目標(biāo),而不是由程序員來(lái)考慮實(shí)現(xiàn)的過(guò)程。Marvin Minsky
Software 2.0 概念的最早提出人是 Andrej Karpathy,這位從小隨家庭從捷克移民來(lái)加拿大的天才少年在多倫多大學(xué)師從 Geoffrey Hinton,然后在斯坦福李飛飛團(tuán)隊(duì)獲得博士學(xué)位,主要研究 NLP 和計(jì)算機(jī)視覺(jué),同時(shí)作為創(chuàng)始團(tuán)隊(duì)成員加入了 OpenAI,Deep Learning 的關(guān)鍵人物和歷史節(jié)點(diǎn)都被他點(diǎn)亮。在 2017 年被 Elon Musk 挖墻腳到了 Tesla 負(fù)責(zé)自動(dòng)駕駛研發(fā),然后就有了重構(gòu)的 FSD(Full Self-Driving)。按照 Andrej Karpathy 的定義 - “軟件 2.0 使用更抽象、對(duì)人類不友好的語(yǔ)言生成,比如神經(jīng)網(wǎng)絡(luò)的權(quán)重。沒(méi)人參與編寫這些代碼,一個(gè)典型的神經(jīng)網(wǎng)絡(luò)可能有數(shù)百萬(wàn)個(gè)權(quán)重,用權(quán)重直接編碼比較困難”。Andrej 說(shuō)他以前試過(guò),這幾乎不是人類能干的事兒 。。
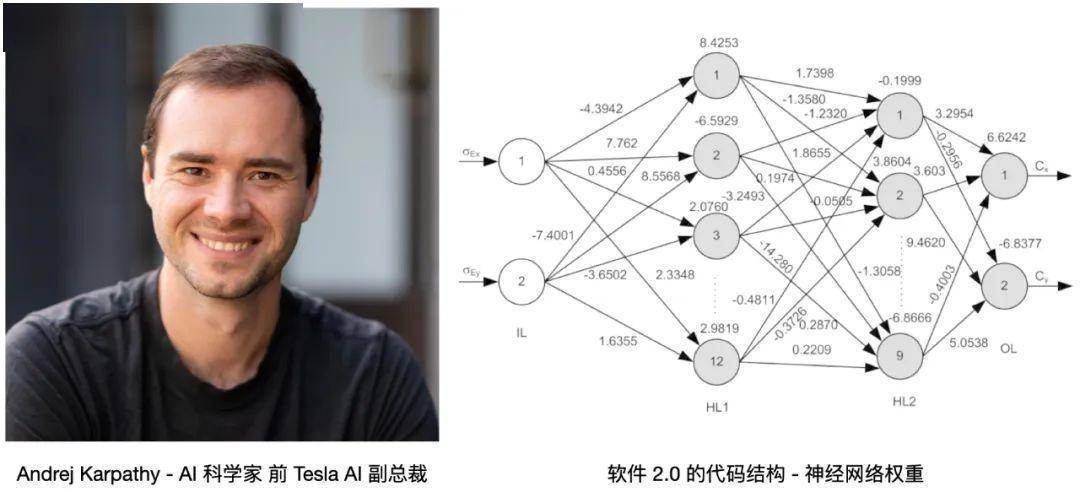
配圖09:Andrej Karpathy 和神經(jīng)網(wǎng)絡(luò)權(quán)重
2.1 范式轉(zhuǎn)移
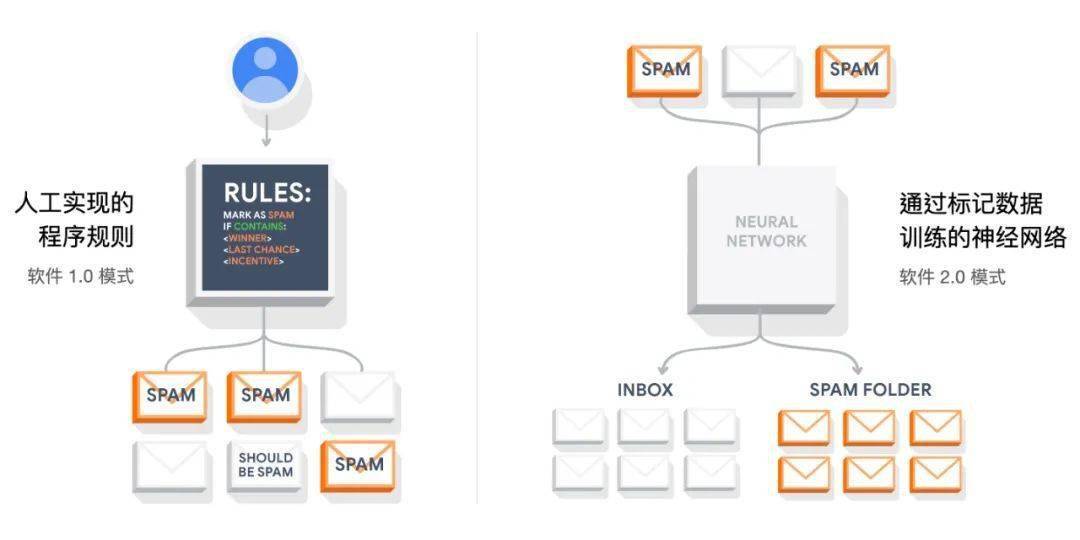
在創(chuàng)建深度神經(jīng)網(wǎng)絡(luò)時(shí),程序員只寫幾行代碼,讓神經(jīng)網(wǎng)絡(luò)自己學(xué)習(xí),計(jì)算權(quán)重,形成網(wǎng)絡(luò)連接,而不是手寫代碼。這種軟件開發(fā)的新范式始于第一個(gè) Machine Learning 語(yǔ)言 TensorFlow,我們也把這種新的編碼方式被稱為軟件 2.0。在 Deep Learning 興起之前,大多數(shù)人工智能程序是用 Python/ target=_blank class=infotextkey>Python 和 JAVA 等編程語(yǔ)言手寫的。 人類編寫了每一行代碼,也決定了程序的所有規(guī)則。
配圖10:How does Machine Learning work?(TensorFlow)
相比之下,隨著 Deep Learning 技術(shù)的出現(xiàn),程序員利用這些新方式,給程序指定目標(biāo)。如贏得圍棋比賽,或通過(guò)提供適當(dāng)輸入和輸出的數(shù)據(jù),如向算法提供具有 "SPAM” 特征的郵件和其他沒(méi)有"SPAM” 特征的郵件。編寫一個(gè)粗略的代碼骨架(一個(gè)神經(jīng)網(wǎng)絡(luò)架構(gòu)),確定一個(gè)程序空間的可搜索子集,并使用我們所能提供的算力在這個(gè)空間中搜索,形成一個(gè)有效的程序路徑。在神經(jīng)網(wǎng)絡(luò)里,我們一步步地限制搜索范圍到連續(xù)的子集上,搜索過(guò)程通過(guò)反向傳播和隨機(jī)梯度下降(Stochastic Gradient Descent)而變得十分高效。
神經(jīng)網(wǎng)絡(luò)不僅僅是另一個(gè)分類器,它代表著我們開發(fā)軟件的 范式開始轉(zhuǎn)移,它是 軟件 2.0。
軟件 1.0 人們編寫代碼,編譯后生成可以執(zhí)行的二進(jìn)制文件;但在軟件 2.0 中人們提供數(shù)據(jù)和神經(jīng)網(wǎng)絡(luò)框架,通過(guò)訓(xùn)練將數(shù)據(jù)編譯成二進(jìn)制的神經(jīng)網(wǎng)絡(luò)。在當(dāng)今大多數(shù)實(shí)際應(yīng)用中,神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)和訓(xùn)練系統(tǒng)日益標(biāo)準(zhǔn)化為一種商品,因此大多數(shù)軟件 2.0 的開發(fā)都由模型設(shè)計(jì)實(shí)施和數(shù)據(jù)清理標(biāo)記兩部分組成。這從根本上改變了我們?cè)谲浖_發(fā)迭代上的范式,團(tuán)隊(duì)也會(huì)因此分成了兩個(gè)部分: 2.0 程序員 負(fù)責(zé)模型和數(shù)據(jù),而那些 1.0 程序員 則負(fù)責(zé)維護(hù)和迭代運(yùn)轉(zhuǎn)模型和數(shù)據(jù)的基礎(chǔ)設(shè)施、分析工具以及可視化界面。
Marc Andreessen 的經(jīng)典文章標(biāo)題《Why Software Is Eating the World》現(xiàn)在可以改成這樣:“軟件(1.0)正在吞噬世界,而現(xiàn)在人工智能(2.0)正在吞噬軟件!
2.2 軟件的演化
軟件從 1.0 發(fā)展到軟件 2.0,經(jīng)過(guò)了一個(gè)叫做“數(shù)據(jù)產(chǎn)品”的中間態(tài)。當(dāng)頂級(jí)軟件公司在了解大數(shù)據(jù)的商業(yè)潛力后,并開始使用 Machine Learning 構(gòu)建數(shù)據(jù)產(chǎn)品時(shí),這種狀態(tài)就出現(xiàn)了。下圖來(lái)自 Ahmad Mustapha 的一篇文章《The Rise of Software 2.0》很好地呈現(xiàn)了這個(gè)過(guò)渡。
配圖11:軟件產(chǎn)品演化的三種狀態(tài)
這個(gè)中間態(tài)也叫 大數(shù)據(jù) 和 算法推薦。在現(xiàn)實(shí)生活中,這樣的產(chǎn)品可以是 Amazon 的商品推薦,它們可以預(yù)測(cè)客戶會(huì)感興趣什么,可以是 Facebook 好友推薦,還可以是 Netflix 電影推薦或 TikTok 的短視頻推薦。還有呢?Waze 的路由算法、Airbnb 背后的排名算法等等,總之琳瑯滿目。
數(shù)據(jù)產(chǎn)品有幾個(gè)重要特點(diǎn):1、它們都不是軟件的主要功能,通常是為了增加體驗(yàn),達(dá)成更好的用戶活躍以及銷售目標(biāo);2、能夠隨著數(shù)據(jù)的增加而進(jìn)化;3、大部分都是基于傳統(tǒng) ML 實(shí)現(xiàn)的,最重要的一點(diǎn) 數(shù)據(jù)產(chǎn)品是可解釋的。
配圖12:圖解軟件 2.0 的代表應(yīng)用
2.3 軟件 2.0 的優(yōu)勢(shì)
為什么我們應(yīng)該傾向于將復(fù)雜的程序移植到軟件 2.0 中?Andrej Karpathy 在《Software 2.0》中給出了一個(gè)簡(jiǎn)單的答案: 它們?cè)趯?shí)踐中表現(xiàn)得更好!
容易被寫入芯片
非常敏捷
敏捷開發(fā)意味著靈活高效。如果你有一段 C++ 代碼,有人希望你把它的速度提高一倍,那么你需要系統(tǒng)性的調(diào)優(yōu)甚至是重寫。然而,在軟件 2.0 中,我們?cè)诰W(wǎng)絡(luò)中刪除一半的通道,重新訓(xùn)練,然后就可以了 。。它的運(yùn)行速度正好提升兩倍,只是輸出更差一些,這就像魔法。相反,如果你有更多的數(shù)據(jù)或算力,通過(guò)添加更多的通道和再次訓(xùn)練,你的程序就能工作得更好。
模塊可以融合成一個(gè)最佳的整體
做過(guò)軟件開發(fā)的同學(xué)都知道,程序模塊通常利用公共函數(shù)、 API 或遠(yuǎn)程調(diào)用來(lái)通訊。然而,如果讓兩個(gè)原本分開訓(xùn)練的軟件 2.0 模塊進(jìn)行互動(dòng),我們可以很容易地通過(guò)整體進(jìn)行反向傳播來(lái)實(shí)現(xiàn)。想象一下,如果你的瀏覽器能夠自動(dòng)整合改進(jìn)低層次的系統(tǒng)指令,來(lái)提升網(wǎng)頁(yè)加載效率,這將是一件令人驚奇的事情。但在軟件 2.0 中,這是默認(rèn)行為。
它做得比你好
最后,也是最重要的一點(diǎn),神經(jīng)網(wǎng)絡(luò)比你能想到的任何有價(jià)值的垂直領(lǐng)域的代碼都要好,目前至少在圖像、視頻、聲音、語(yǔ)音相關(guān)的任何東西上,比你寫的代碼要好。
2.4 Bug 2.0
對(duì)于傳統(tǒng)軟件,即軟件 1.0,大多數(shù)程序都通過(guò)源代碼保存,這些代碼可能少至數(shù)千行,多至上億行。據(jù)說(shuō),谷歌的整個(gè)代碼庫(kù)大約有 20 億行代碼。無(wú)論代碼有多少,傳統(tǒng)的軟件工程實(shí)踐表明,使用封裝和模塊化設(shè)計(jì),有助于創(chuàng)建可維護(hù)的代碼,很容易隔離 Bug 來(lái)進(jìn)行修改。
但在新的范式中,程序被存儲(chǔ)在內(nèi)存中,作為神經(jīng)網(wǎng)絡(luò)架構(gòu)的權(quán)重,程序員編寫的代碼很少。軟件 2.0 帶來(lái)了兩個(gè)新問(wèn)題: 不可解釋和 數(shù)據(jù)污染。
因?yàn)橛?xùn)練完成的神經(jīng)網(wǎng)絡(luò)權(quán)重,工程師無(wú)法理解(不過(guò)現(xiàn)在對(duì)理解神經(jīng)網(wǎng)絡(luò)的研究有了很多進(jìn)展,第六章會(huì)講到),所以我們無(wú)法知道正確的執(zhí)行是為什么?錯(cuò)誤又是因?yàn)槭裁矗窟@個(gè)和大數(shù)據(jù)算法有很大的不同,雖然大多數(shù)的應(yīng)用只關(guān)心結(jié)果,無(wú)需解釋;但對(duì)于一些安全敏感的領(lǐng)域,比如 自動(dòng)駕駛 和 醫(yī)療應(yīng)用,這確實(shí)很重要。
在 2.0 的堆棧中,數(shù)據(jù)決定了神經(jīng)網(wǎng)絡(luò)的連接,所以不正確的數(shù)據(jù)集和標(biāo)簽,都會(huì) 混淆神經(jīng)網(wǎng)絡(luò)。錯(cuò)誤的數(shù)據(jù)可能來(lái)自失誤、也可能是人為設(shè)計(jì),或者是有針對(duì)性的投喂混淆數(shù)據(jù)(這也是人工智能領(lǐng)域中新的 程序道德規(guī)范 問(wèn)題)。例如 IOS 系統(tǒng)的自動(dòng)拼寫功能被意外的數(shù)據(jù)訓(xùn)練污染了,我們?cè)谳斎肽承┳址臅r(shí)候就永遠(yuǎn)得不到正確的結(jié)果。訓(xùn)練模型會(huì)認(rèn)為污染數(shù)據(jù)是一個(gè)重要的修正,一但完成訓(xùn)練部署,這個(gè)錯(cuò)誤就像病毒一樣傳播,到達(dá)了數(shù)百萬(wàn)部 iphone 手機(jī)。所以在這種 2.0 版的 Bug 中,需要對(duì)數(shù)據(jù)以及程序結(jié)果進(jìn)行良好的測(cè)試,確保這些邊緣案例不會(huì)使程序失敗。
在短期內(nèi),軟件 2.0 將變得越來(lái)越普遍,那些沒(méi)法通過(guò)清晰算法和軟件邏輯化表述的問(wèn)題,都會(huì)轉(zhuǎn)入 2.0 的新范式,現(xiàn)實(shí)世界并不適合整齊的封裝。就像明斯基說(shuō)的,軟件開發(fā)應(yīng)該更多的關(guān)心目標(biāo)而不是過(guò)程,這種范式有機(jī)會(huì)顛覆整個(gè)開發(fā)生態(tài),軟件 1.0 將成為服務(wù)于軟件 2.0 周邊系統(tǒng),一同來(lái)搭建 面向智能的架構(gòu)。有越來(lái)越清楚的案例表明,當(dāng)我們開發(fā)通用人工智能(AGI)時(shí),它一定會(huì)寫在軟件 2.0 中。
03 面向智能的架構(gòu)
回顧過(guò)去十多年 Deep Learning 在人工智能領(lǐng)域波瀾壯闊的發(fā)展,大家把所有的關(guān)注點(diǎn)都集中了算法的突破、訓(xùn)練模型的創(chuàng)新還有智能應(yīng)用的神奇表現(xiàn)上,這些當(dāng)然可以理解,但關(guān)于智能系統(tǒng)的基礎(chǔ)設(shè)施被提及的太少了。
正如在計(jì)算機(jī)發(fā)展的早期,人們需要匯編語(yǔ)言、編譯器和操作系統(tǒng)方面的專家來(lái)開發(fā)一個(gè)簡(jiǎn)單的應(yīng)用程序,所以今天你需要 大量的數(shù)據(jù) 和 分布式系統(tǒng) 才能大規(guī)模地部署人工智能。經(jīng)濟(jì)學(xué)大師 Andrew McAfee 和 Erik Brynjolfsson 在他們的著作《Machine, Platform, Crowd: Harnessing Our Digital Future》中諷刺地調(diào)侃:“ 我們的機(jī)器智能時(shí)代仍然是人力驅(qū)動(dòng)的”。
好在 GANs 的出現(xiàn)讓完全依賴人工數(shù)據(jù)的訓(xùn)練成本大幅下降,還有 Google AI 在持續(xù)不斷的努力讓 AI 的基礎(chǔ)設(shè)施平民化。但這一切還在很早期,我們需要新的智能基礎(chǔ)設(shè)施, 讓眾包數(shù)據(jù)變成眾包智能,把人工智能的潛力從昂貴的科研機(jī)構(gòu)和少數(shù)精英組織中釋放出來(lái),讓其工程化。
3.1 Infrastructure 3.0
應(yīng)用程序和基礎(chǔ)設(shè)施的發(fā)展是同步的。
Infrastructure 1.0 - C/S(客戶端/服務(wù)器時(shí)代)
商業(yè)互聯(lián)網(wǎng)在上世紀(jì) 90 年代末期成熟起來(lái),這要?dú)w功于 x86 指令集(Intel)、標(biāo)準(zhǔn)化操作系統(tǒng)(Microsoft)、關(guān)系數(shù)據(jù)庫(kù)(Oracle)、以太網(wǎng)(Cisco)和網(wǎng)絡(luò)數(shù)據(jù)存儲(chǔ)(EMC)。Amazon,eBay,Yahoo,甚至最早的 Google 和 Facebook 都建立在這個(gè)我們稱之為 Infrastructure 1.0 的基礎(chǔ)上。
Infrastructure 2.0 - Cloud(云時(shí)代)
Amazon AWS、Google Cloud 還有 Microsoft Azure 定義了一種新的基礎(chǔ)設(shè)施類型,這種基礎(chǔ)設(shè)施是無(wú)需物理部署可持續(xù)運(yùn)行的、可擴(kuò)展的、可編程的,它們有些是開源,例如 linux、MySQL、Docker、Kubernetes、Hadoop、 Spark 等等,但大多數(shù)都是要錢的,例如邊緣計(jì)算服務(wù) Cloudflare、數(shù)據(jù)庫(kù)服務(wù) MangoDB、消息服務(wù) Twilio、支付服務(wù) Stripe,所有這些加在一起定義了 云計(jì)算時(shí)代。推薦閱讀我在 2021 年 9 月的這篇《軟件行業(yè)的云端重構(gòu)》。
歸根結(jié)底,這一代技術(shù)把互聯(lián)網(wǎng)擴(kuò)展到數(shù)十億的終端用戶,并有效地存儲(chǔ)了從用戶那里獲取的信息。Infrastructure 2.0 的創(chuàng)新催化了數(shù)據(jù)急劇增長(zhǎng),結(jié)合算力和算法飛速進(jìn)步,為今天的 Machine Learning 時(shí)代搭建了舞臺(tái)。
Infrastructure 2.0 關(guān)注的問(wèn)題是 - “ 我們?nèi)绾芜B接世界?” 今天的技術(shù)重新定義了這個(gè)問(wèn)題 - “ 我們?nèi)绾卫斫膺@個(gè)世界?” 這種區(qū)別就像連通性與認(rèn)知性的區(qū)別,先認(rèn)識(shí)再了解。2.0 架構(gòu)中的各種服務(wù),在給這個(gè)新的架構(gòu)源源不斷的輸送數(shù)據(jù),這就像廣義上的眾包;訓(xùn)練算法從數(shù)據(jù)中推斷出 邏輯(神經(jīng)網(wǎng)絡(luò)),然后這種 邏輯 就被用于對(duì)世界做出理解和預(yù)測(cè)。這種收集并處理數(shù)據(jù)、訓(xùn)練模型最后再部署應(yīng)用的新架構(gòu),就是 Infrastructure 3.0 - 面向智能的架構(gòu)。其實(shí)我們的大腦也是這樣工作的,我會(huì)在第六章中詳細(xì)介紹。
配圖13:Hidden technical debt in Machine Learning Systems
在現(xiàn)實(shí)世界的 Machine Learning 系統(tǒng)中,只有一小部分是由 ML 代碼組成的,如中間的小黑盒所示,其周邊基礎(chǔ)設(shè)施巨大而繁雜。一個(gè)“智能”的應(yīng)用程序,數(shù)據(jù)非常密集,計(jì)算成本也非常高。這些特性使得 ML 很難適應(yīng)已經(jīng)發(fā)展了七十多年的通用的 馮 · 諾依曼計(jì)算范式。為了讓 Machine Learning 充分發(fā)揮其潛力,它必須走出今天的學(xué)術(shù)殿堂,成為一門工程學(xué)科。這實(shí)際上意味著需要有新的抽象架構(gòu)、接口、系統(tǒng)和工具,使開發(fā)人員能夠方便地開發(fā)和部署這些智能應(yīng)用程序。
3.2 如何組裝智能
想要成功構(gòu)建和部署人工智能,需要一個(gè)復(fù)雜的流程,這里涉及多個(gè)獨(dú)立的系統(tǒng)。首先,需要對(duì)數(shù)據(jù)進(jìn)行采集、清理和標(biāo)記;然后,必須確定預(yù)測(cè)所依據(jù)的特征;最后,開發(fā)人員必須訓(xùn)練模型,并對(duì)其進(jìn)行驗(yàn)證和持續(xù)優(yōu)化。從開始到結(jié)束,現(xiàn)在這個(gè)過(guò)程可能需要幾個(gè)月或者是數(shù)年,即使是行業(yè)中最領(lǐng)先的公司或者研究機(jī)構(gòu)。
好在除了算法和模型本身之外,組裝智能架構(gòu)中每個(gè)環(huán)節(jié)的效率都在提升,更高的算力和分布式計(jì)算框架,更快的網(wǎng)絡(luò)和更強(qiáng)大的工具。在每一層技術(shù)棧,我們都開始看到新的平臺(tái)和工具出現(xiàn),它們針對(duì) Machine Learning 的范式進(jìn)行了優(yōu)化,這里面機(jī)會(huì)豐富。
配圖14:Intelligence Infrastructure from Determined AI
參照智能架構(gòu)領(lǐng)域的投資專家 Amplify Partners 的分類,簡(jiǎn)單做個(gè)技術(shù)棧說(shuō)明。
- 為 Machine Learning 優(yōu)化的高性能芯片,它們內(nèi)置多計(jì)算核心和高帶寬內(nèi)存(HBM),可以高度并行化,快速執(zhí)行矩陣乘法和浮點(diǎn)數(shù)學(xué)神經(jīng)網(wǎng)絡(luò)計(jì)算,例如 Nvidia 的 H100 Tensor Core GPU 還有 Google 的 TPU;
- 能夠完全發(fā)揮硬件效率的系統(tǒng)軟件,可以將計(jì)算編譯到晶體管級(jí)別。Nvidia 在 2006 年就推出的 CUDA 到現(xiàn)在也都保持著領(lǐng)先地位,CUDA 是一個(gè)軟件層,可以直接訪問(wèn) GPU 的虛擬指令集,執(zhí)行內(nèi)核級(jí)別的并行計(jì)算;
- 用于訓(xùn)練和推理的分布式計(jì)算框架(Distributed Computing Frameworks),可以有效地跨多個(gè)節(jié)點(diǎn),擴(kuò)展模型的訓(xùn)練操作;
- 數(shù)據(jù)和元數(shù)據(jù)管理系統(tǒng),為創(chuàng)建、管理、訓(xùn)練和預(yù)測(cè)數(shù)據(jù)而設(shè)計(jì),提供了一個(gè)可靠、統(tǒng)一和可重復(fù)使用的管理通道。
- 極低延遲的服務(wù)基礎(chǔ)設(shè)施,使機(jī)器能夠快速執(zhí)行基于實(shí)時(shí)數(shù)據(jù)和上下文相關(guān)的智能操作;
- Machine Learning 持續(xù)集成平臺(tái)(MLOps),模型解釋器,質(zhì)保和可視化測(cè)試工具,可以大規(guī)模的監(jiān)測(cè),調(diào)試,優(yōu)化模型和應(yīng)用;
- 封裝了整個(gè) Machine Learning 工作流的終端平臺(tái)(End to End ML Platform),抽象出全流程的復(fù)雜性,易于使用。幾乎所有的擁有大用戶數(shù)據(jù)量的 2.0 架構(gòu)公司,都有自己內(nèi)部的 3.0 架構(gòu)集成系統(tǒng),Uber 的 Michelangelo 平臺(tái)就用來(lái)訓(xùn)練出行和訂餐數(shù)據(jù);Google 的 TFX 則是面向公眾提供的終端 ML 平臺(tái),還有很多初創(chuàng)公司在這個(gè)領(lǐng)域,例如 Determined AI。
總的來(lái)說(shuō),Infrastructure 3.0 將釋放 AI/ML 的潛力,并為人類智能系統(tǒng)的構(gòu)建添磚加瓦。與前兩代架構(gòu)一樣,雖然上一代基礎(chǔ)設(shè)施的巨頭早已入場(chǎng),但每一次范式轉(zhuǎn)移,都會(huì)有有新的項(xiàng)目、平臺(tái)和公司出現(xiàn),并挑戰(zhàn)目前的在位者。
2.3 智能架構(gòu)的先鋒
Deep Learning 被大科技公司看上的關(guān)鍵時(shí)刻是在 2010 年。在 Palo Alto 的一家日餐晚宴上,斯坦福大學(xué)教授 Andrew Ng 在那里會(huì)見了 Google 的 CEO Larry Page 和當(dāng)時(shí)擔(dān)任 Google X 負(fù)責(zé)人的天才計(jì)算機(jī)科學(xué)家 Sebastian Thrun。就在兩年前,Andrew 寫過(guò)一篇關(guān)于將 GPU 應(yīng)用于 DL 模型有效性分析論文。要知道 DL 在 2008 年是非常不受歡迎的,當(dāng)時(shí)是算法的天下。
幾乎在同一時(shí)期,Nvidia 的 CEO Jensen Huang 也意識(shí)到 GPU 對(duì)于 DL 的重要性,他是這樣形容的:"Deep Learning 就像大腦,雖然它的有效性是不合理的,但你可以教它做任何事情。這里有一個(gè)巨大的障礙,它需要大量的計(jì)算,而我們就是做 GPU 的,這是一個(gè)可用于 Deep Learning 的近乎理想的計(jì)算工具"。
以上故事的細(xì)節(jié)來(lái)自 Forbes 在 2016 年的一篇深度報(bào)道。自那時(shí)起,Nvidia 和 Google 就走上了 Deep Learning 的智能架構(gòu)之路,一個(gè)從終端的 GPU 出發(fā),另一個(gè)從云端的 TPU 開始。
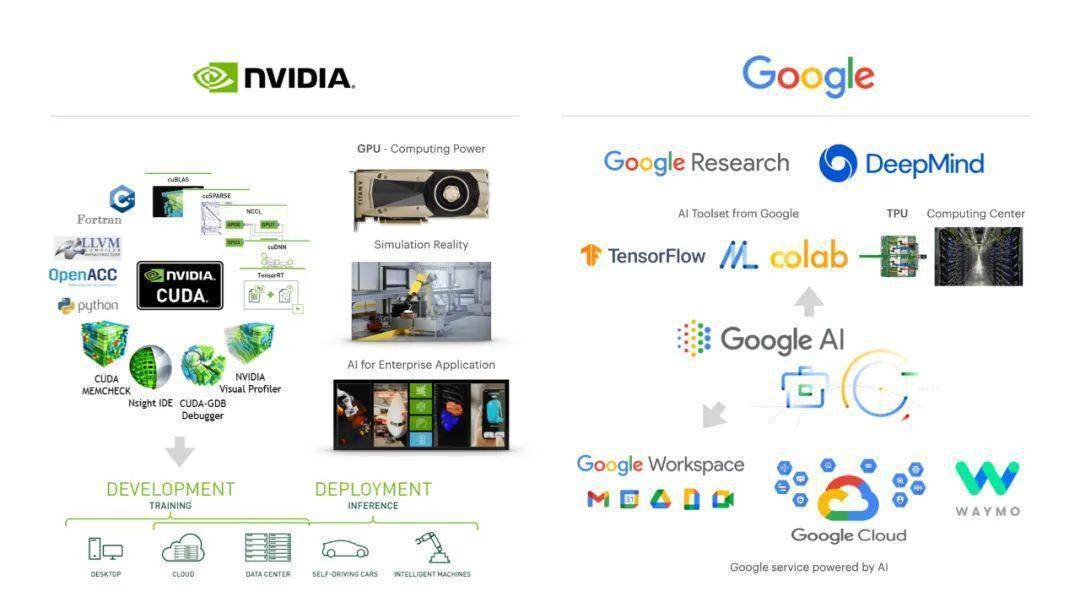
配圖15:Nvidia AI vs Google AI 的對(duì)比
Nvidia 今天賺的大部分錢的來(lái)自游戲行業(yè),通過(guò)銷售 GPU,賣加速芯片的事情 AMD 和很多創(chuàng)業(yè)公司都在做,但 Nvidia 在軟件堆棧上的能力這些硬件公司無(wú)人能及,因?yàn)樗袕膬?nèi)核到算法全面控制的 CUDA,還能讓數(shù)千個(gè)芯片協(xié)同工作。這種整體控制力,讓 Nvidia 可以發(fā)展云端算力服務(wù),自動(dòng)駕駛硬件以及嵌入式智能機(jī)器人硬件,以及更加上層的 AI 智能應(yīng)用和 Omniverse 數(shù)字模擬世界。
Google 擁抱 AI 的方式非常學(xué)術(shù),他們最早成立了 Google Brain 嘗試大規(guī)模神經(jīng)網(wǎng)絡(luò)訓(xùn)練,點(diǎn)爆了這個(gè)領(lǐng)域的科技樹,像 GANs 這樣充滿靈感的想法也是來(lái)自于 Google (Ian Goodfellow 同學(xué)當(dāng)時(shí)任職于 Google Brain)。在 2015 年前后 Google 先后推出了 TensorFlow 還有 TPU(Tensor Processing Unit - 張量芯片),同年還收購(gòu)了 DeepMind 來(lái)擴(kuò)張研究實(shí)力。Google AI 更傾向于用云端的方式給大眾提供 AI/ML 的算力和全流程工具,然后通過(guò)投資和收購(gòu)的方式把智能融入到自己的產(chǎn)品線。
現(xiàn)在幾乎所有的科技巨頭,都在完善自己的“智能”基礎(chǔ)設(shè)施,Microsoft 在 2019 年投資了 10 億美金給 OpenAI 成為了他們最大的機(jī)構(gòu)股東;Facebook 也成立了 AI 研究團(tuán)隊(duì),這個(gè)僅次于他們 Reality Lab 的地位,Metaverse 里所需的一切和“智能”相關(guān)的領(lǐng)域他們都參與,今年底還和 AMD 達(dá)成合作,投入 200 億美元并用他們的芯片來(lái)搭建新的“智能”數(shù)據(jù)中心;然后就是 Tesla,在造電車之外不務(wù)正業(yè)搭建了世界上規(guī)模最大的超級(jí)電腦 Dojo,它將被用來(lái)訓(xùn)練 FSD 的神經(jīng)網(wǎng)絡(luò)和為未來(lái)的 Optimus(Tesla 人形機(jī)器人)的大腦做準(zhǔn)備。
正如過(guò)去二十年見證了“云計(jì)算技術(shù)棧”的出現(xiàn)一樣,在接下來(lái)的幾年里,我們也期待著一個(gè)巨大的基礎(chǔ)設(shè)施和工具生態(tài)系統(tǒng)將圍繞著智能架構(gòu) - Infrastructure 3.0 建立起來(lái)。Google 目前正處于這個(gè)領(lǐng)域的前沿,他們?cè)噲D自己的大部分代碼用 軟件 2.0的范式重寫,并在新的智能架構(gòu)里運(yùn)行,因?yàn)橐粋€(gè)有可能一統(tǒng)江湖的“模型”的已經(jīng)出現(xiàn),雖然還非常早期,但 機(jī)器智能對(duì)世界的理解很快將趨向一致,就像我們的 大腦皮質(zhì)層 理解世界那樣。
04 一統(tǒng)江湖的模型
想象一下,你去五金店,看到架子上有一種新款的錘子。你或許已經(jīng)聽說(shuō)過(guò)這種錘子了,它比其他的錘子更快、更準(zhǔn);而且在過(guò)去的幾年里,許多其他的錘子在它面前都顯得過(guò)時(shí)了。你只需要加一個(gè)配件再扭一下,它就變成了一個(gè)鋸子,而且和其它的鋸子一樣快、一樣準(zhǔn)。事實(shí)上,這個(gè)工具領(lǐng)域的前沿專家說(shuō),這個(gè)錘子可能預(yù)示著所有的 工具都將集中到單一的設(shè)備中。
類似的故事也在 AI 的工具中上演,這種多用途的新型錘子是一種神經(jīng)網(wǎng)絡(luò),我們稱之為 Transformer( 轉(zhuǎn)換器模型- 不是動(dòng)畫片里的變形金剛),它最初被設(shè)計(jì)用來(lái)處理自然語(yǔ)言,但最近已經(jīng)開始影響 AI 行業(yè)的其它領(lǐng)域了。
4.1 Transformer 的誕生
2017年 Google Brain 和多倫多大學(xué)的研究人員一同發(fā)表了一篇名為《Attention Is All You Need》的論文,里面提到了一個(gè)自然語(yǔ)言處理(NLP)的模型 Transformer,這應(yīng)該是繼 GANs 之后 Deep Learning 領(lǐng)域最重大的發(fā)明。2018 年 Google 在 Transformer 的基礎(chǔ)上實(shí)現(xiàn)并開源了第一款自然語(yǔ)言處理模型 BERT;雖然研究成果來(lái)自 Google,但很快被 OpenAI 采用,創(chuàng)建了 GPT-1 和最近的火爆的 GPT-3。其他公司還有開源項(xiàng)目團(tuán)隊(duì)緊隨其后,實(shí)現(xiàn)了自己的 Transformer 模型,例如 Cohere,AI21,Eleuther(致力于讓 AI 保持開源的項(xiàng)目);也有用在其它領(lǐng)域的創(chuàng)新,例如生成圖像的 Dall-E 2、MidJourney、Stable Diffusion、Disco Diffusion, Imagen 和其它許多。
配圖16:發(fā)表《Attention Is All You Need》論文的八位同學(xué)
發(fā)表這篇論文的 8 個(gè)人中,有 6 個(gè)人已經(jīng)創(chuàng)辦了公司,其中 4 個(gè)與人工智能相關(guān),另一個(gè)創(chuàng)辦了名為 Near.ai 的區(qū)塊鏈項(xiàng)目。
自然語(yǔ)言處理 這個(gè)課題在上世紀(jì)五十年代開創(chuàng) AI 學(xué)科的時(shí)候就明確下來(lái)了,但只到有了 Deep Learning 之后,它的準(zhǔn)確度和表達(dá)合理性才大幅提高。序列傳導(dǎo)模型(Seq2Seq)是用于 NLP 領(lǐng)域的一種 DL 模型,在機(jī)器翻譯、文本摘要和圖像字幕等方面取得了很大的成功,2016 年之后 Google 在搜索提示、機(jī)器翻譯等項(xiàng)目上都有使用。序列傳導(dǎo)模型是在 輸入端 一個(gè)接一個(gè)的接收并 編碼 項(xiàng)目(可以是單詞、字母、圖像特征或任何計(jì)算機(jī)可以讀取的數(shù)據(jù)),并在同步在 輸出端一個(gè)接一個(gè) 解碼 輸出項(xiàng)目的模型。
在機(jī)器翻譯的案例中,輸入序列就是一系列單詞,經(jīng)過(guò)訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)中復(fù)雜的 矩陣數(shù)學(xué)計(jì)算,在輸出端的結(jié)果就是一系列翻譯好的目標(biāo)詞匯。
Transformer 也是一款用于 NLP 的序列傳導(dǎo)模型,論文簡(jiǎn)潔清晰的闡述了這個(gè)新的網(wǎng)絡(luò)結(jié)構(gòu),它只基于 注意力機(jī)制(Attention),完全不需要遞歸(RNN)和卷積(CNN)。在兩個(gè)機(jī)器翻譯的實(shí)驗(yàn)表明,這個(gè)模型在質(zhì)量上更勝一籌,同時(shí)也更容易并行化,需要的訓(xùn)練時(shí)間也大大減少。
好奇心強(qiáng)的同學(xué),如果想了解 Transformer 模型的具體工作原理,推薦閱讀 Giuliano Giacaglia 的這篇《How Transformers Work》。
4.2 Foundation Models
斯坦福大學(xué) CRFM & HAI 的研究人員在 2021 年 8 月的一篇名為《On the Opportunities and Risks of Foundation Models》的論文中將 Transformer 稱為 Foundation Models(基礎(chǔ)模型),他們認(rèn)為這個(gè)模型已經(jīng)推動(dòng)了 AI 領(lǐng)域新一輪的范式轉(zhuǎn)移。事實(shí)上,過(guò)去兩年在 arVix 上發(fā)表的關(guān)于 AI 的論文中,70% 都提到了 Transformer,這與 2017 年 IEEE 的一項(xiàng)研究 相比是一個(gè)根本性的轉(zhuǎn)變,那份研究的結(jié)論是 RNN 和 CNN 是當(dāng)時(shí)最流行的模型。
從 NLP 到 Generative AI
來(lái)自 Google Brain 的計(jì)算機(jī)科學(xué)家 Maithra Raghu 分析了 視覺(jué)轉(zhuǎn)換器(Vision Transformer),以確定它是如何“看到”圖像的。與 CNN 不同,Transformer 可以從一開始就捕捉到整個(gè)圖像,而 CNN 首先關(guān)注小的部分來(lái)尋找像邊緣或顏色這樣的細(xì)節(jié)。
這種差異在語(yǔ)言領(lǐng)域更容易理解,Transformer 誕生于 NLP 領(lǐng)域。例如這句話:“貓頭鷹發(fā)現(xiàn)了一只松鼠。它試圖抓住它,但只抓到了尾巴的末端。” 第二個(gè)句子的結(jié)構(gòu)令人困惑: “它”指的是什么?如果是 CNN 就只會(huì)關(guān)注“它”周圍的詞,那會(huì)十分不解;但是如果把每個(gè)詞和其他詞連接起來(lái),就會(huì)發(fā)現(xiàn)是”貓頭鷹抓住了松鼠,松鼠失去了部分尾巴”。這種關(guān)聯(lián)性就是“ Attention”機(jī)制,人類就是用這種模式理解世界的。
Transformer 將數(shù)據(jù)從一維字符串(如句子)轉(zhuǎn)換為二維數(shù)組(如圖像)的多功能性表明,這種模型可以處理許多其他類型的數(shù)據(jù)。就在 10 年前,AI 領(lǐng)域的不同分支幾乎沒(méi)有什么可以交流的,計(jì)算機(jī)科學(xué)家 Atlas Wang 這樣表述, “我認(rèn)為 Transformer 之所以如此受歡迎,是因?yàn)?nbsp;它暗示了一種變得通用的潛力,可能是朝著實(shí)現(xiàn)某種神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)大融合方向的重要一步,這是一種通用的計(jì)算機(jī)視覺(jué)方法,或許也適用于其它的 機(jī)器智能任務(wù)”。
更多基于Transformer 模型的 Generative AI案例,推薦好友 Rokey 的這篇《AI 時(shí)代的巫師與咒語(yǔ)》,這應(yīng)該是中文互聯(lián)網(wǎng)上寫得最詳細(xì)清晰的一篇。
涌現(xiàn)和同質(zhì)化
Foundation Models 的意義可以用兩個(gè)詞來(lái)概括:涌現(xiàn)和同質(zhì)化。 涌現(xiàn) 是未知和不可預(yù)測(cè)的,它是創(chuàng)新和科學(xué)發(fā)現(xiàn)的源頭。 同質(zhì)化 表示在廣泛的應(yīng)用中,構(gòu)建 Machine Learning 的方法論得到了整合;它讓你可以用統(tǒng)一的方法完成不同的工作,但也創(chuàng)造了單點(diǎn)故障。我們?cè)?Bug 2.0 那一小節(jié)中提到的 數(shù)據(jù)污染會(huì)被快速放大,現(xiàn)在還會(huì)波及到所有領(lǐng)域。
配圖18:人工智能的涌現(xiàn)過(guò)程(來(lái)自斯坦福研究人員 2021 年 8 月的論文)
AI 的進(jìn)化史一個(gè)不斷涌現(xiàn)和同質(zhì)化的過(guò)程。隨著 ML 的引入,可以從實(shí)例中學(xué)習(xí)(算法概率推論);隨著 DL 的引入,用于預(yù)測(cè)的高級(jí)特征出現(xiàn);隨著基礎(chǔ)模型( Foundation Models)的出現(xiàn),甚至出現(xiàn)了更高級(jí)的功能, 在語(yǔ)境中學(xué)習(xí)。同時(shí),ML 將算法同質(zhì)化(例如 RNN),DL 將模型架構(gòu)同質(zhì)化(例如 CNN),而基礎(chǔ)模型將模型本身同質(zhì)化(如 GPT-3)。
一個(gè)基礎(chǔ)模型如果可以集中來(lái)自各種模式的數(shù)據(jù)。那么這個(gè)模型就可以廣泛的適應(yīng)各種任務(wù)。
配圖19:Foundation Model 的轉(zhuǎn)換(來(lái)自斯坦福研究人員 2021 年 8 月的論文)
除了在翻譯、文本創(chuàng)作、圖像生成、語(yǔ)音合成、視頻生成這些耳熟能詳?shù)念I(lǐng)域大放異彩之外,基礎(chǔ)模型也被用在了專業(yè)領(lǐng)域。
DeepMind 的 AlphaFold 2 在 2020 年 12 月成功的把蛋白質(zhì)結(jié)構(gòu)預(yù)測(cè)的準(zhǔn)確度提升到了 90% 多,大幅超過(guò)所有的競(jìng)爭(zhēng)對(duì)手。他們?cè)凇蹲匀弧冯s志上發(fā)表的文章中提到,像處理文本字符串這樣讀取氨基酸鏈,用這個(gè)數(shù)據(jù)轉(zhuǎn)換成可能的蛋白質(zhì)折疊結(jié)構(gòu),這項(xiàng)工作可以加速藥物的發(fā)現(xiàn)。類似的應(yīng)用也在藥物公司發(fā)生,阿斯利康(AstraZeneca)和 NVIDIA 聯(lián)合開發(fā)了 MegaMolBART,可以在未標(biāo)記的化合物數(shù)據(jù)庫(kù)上進(jìn)行培訓(xùn)練,大幅提升效率。
大規(guī)模語(yǔ)言模型
這種通用化的特征,讓大規(guī)模神經(jīng)網(wǎng)絡(luò)的訓(xùn)練變得非常有意義。自然語(yǔ)言又是所有可訓(xùn)練數(shù)據(jù)中最豐富的,它能夠讓基礎(chǔ)模型在語(yǔ)境中學(xué)習(xí),轉(zhuǎn)換成各種需要的媒體內(nèi)容, 自然語(yǔ)言 = 編程方式 = 通用界面。
因此,大規(guī)模語(yǔ)言模型(LLMs - Large Scale Language Models)成了科技巨頭和新創(chuàng)業(yè)公司必爭(zhēng)之地。在這個(gè)軍備競(jìng)賽之中,財(cái)大氣粗就是優(yōu)勢(shì) ,它們可以花費(fèi)數(shù)億美元采購(gòu) GPU 來(lái)培訓(xùn) LLMs,例如 OpenAI 的 GPT-3 有 1750 億個(gè)參數(shù),DeepMind 的 Gopher 有 2800 億個(gè)參數(shù),Google 自己的 GLaM 和 LaMDA 分別有 1.2 萬(wàn)億個(gè)參數(shù)和 1370 億個(gè)參數(shù),Microsoft 與 Nvidia 合作的 Megatron-Turing NLG 有 5300 億個(gè)參數(shù)。
但 AI 有個(gè)特征它是 涌現(xiàn) 的,大多數(shù)情況挑戰(zhàn)是科學(xué)問(wèn)題,而不是工程問(wèn)題。在 Machine Learning 中,從算法和體系結(jié)構(gòu)的角度來(lái)看,還有很大的進(jìn)步空間。雖然,增量的工程迭代和效率提高似乎有很大的空間,但越來(lái)越多的 LLMs 創(chuàng)業(yè)公司正在籌集規(guī)模較小的融資(1000 萬(wàn)至 5000 萬(wàn)美元) ,它們的假設(shè)是,未來(lái)可能會(huì)有更好的模型架構(gòu),而非純粹的可擴(kuò)展性。
4.3 AI 江湖的新機(jī)會(huì)
隨著模型規(guī)模和自然語(yǔ)言理解能力的進(jìn)一步增強(qiáng)(擴(kuò)大訓(xùn)練規(guī)模和參數(shù)就行),我們可以預(yù)期非常多的專業(yè)創(chuàng)作和企業(yè)應(yīng)用會(huì)得到改變甚至是顛覆。企業(yè)的大部分業(yè)務(wù)實(shí)際上是在“ 銷售語(yǔ)言”—— 營(yíng)銷文案、郵件溝通、客戶服務(wù),包括更專業(yè)的法律顧問(wèn),這些都是語(yǔ)言的表達(dá),而且這些表達(dá)可以二維化成聲音、圖像、視頻,也能三維化成更真實(shí)的模型用于元宇宙之中。機(jī)器能理解文檔或者直接生成文檔,將是自 2010 年前后的移動(dòng)互聯(lián)網(wǎng)革命和云計(jì)算以來(lái),最具顛覆性的轉(zhuǎn)變之一。參考移動(dòng)時(shí)代的格局,我們最終也會(huì)有三種類型的公司:
1、平臺(tái)和基礎(chǔ)設(shè)施
移動(dòng)平臺(tái)的終點(diǎn)是 iPhone 和 Android,這之后都沒(méi)有任何機(jī)會(huì)了。但在基礎(chǔ)模型領(lǐng)域 OpenAI、Google、Cohere、AI21、Stability.ai 還有那些構(gòu)建 LLMs 的公司的競(jìng)爭(zhēng)才剛剛開始。這里還有許多許新興的開源選項(xiàng)例如 Eleuther。云計(jì)算時(shí)代,代碼共享社區(qū) Github 幾乎托管了 軟件 1.0的半壁江山,所以像 Hugging Face 這種共享神經(jīng)網(wǎng)絡(luò)模型的社群,應(yīng)該也會(huì)成為 軟件 2.0時(shí)代智慧的樞紐和人才中心。
2、平臺(tái)上的獨(dú)立應(yīng)用
因?yàn)橛辛艘苿?dòng)設(shè)備的定位、感知、相機(jī)等硬件特性,才有了像 Instagram,Uber,Doordash 這種離開手機(jī)就不會(huì)存在的服務(wù)。現(xiàn)在基于 LLMs 服務(wù)或者訓(xùn)練 Transformer 模型,也會(huì)誕生一批新的應(yīng)用,例如 Jasper(創(chuàng)意文案)、Synthesia(合成語(yǔ)音與視頻),它們會(huì)涉及 Creator & Visual Tools、Sales & Marketing、Customer Support、Doctor & Lawyers、Assistants、Code、Testing、Security 等等各種行業(yè),如果沒(méi)有先進(jìn)的 Machine Learning 突破,這些就不可能存在。
紅衫資本美國(guó)(SequoiaCap)最近一篇很火的文章《Generative AI: A Creative New World》詳細(xì)分析了這個(gè)市場(chǎng)和應(yīng)用,就像在開篇介紹的那樣,整個(gè)投資界在 Web 3 的投機(jī)挫敗之后,又開始圍獵 AI 了 。
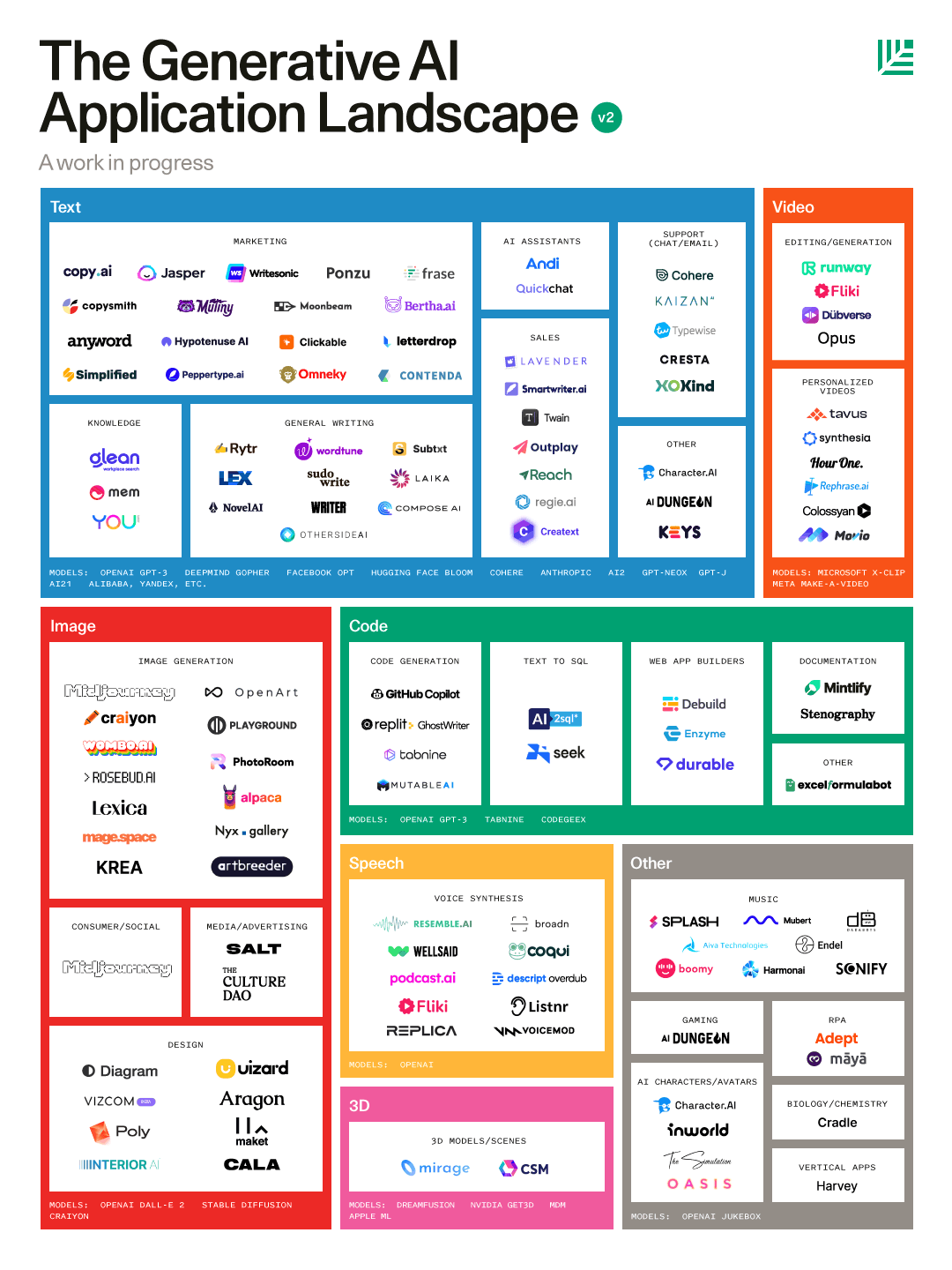
配圖21:在模型之上的應(yīng)用分類(Gen AI market map V2)
3、現(xiàn)有產(chǎn)品智能化
在移動(dòng)互聯(lián)網(wǎng)的革命中,大部分有價(jià)值的移動(dòng)業(yè)務(wù)依舊被上個(gè)時(shí)代的巨頭所占據(jù)。例如,當(dāng)許多初創(chuàng)公司試圖建立“Mobile CRM”應(yīng)用時(shí),贏家是增加了移動(dòng)支持的 CRM 公司,Salesforce 沒(méi)有被移動(dòng)應(yīng)用取代。同樣,Gmail、Microsoft office 也沒(méi)有被移動(dòng)應(yīng)用取代,他們的移動(dòng)版做得還不錯(cuò)。最終,Machine Learning 將被內(nèi)置到用戶量最大的 CRM 工具中,Salesforce 不會(huì)被一個(gè)全新由 ML 驅(qū)動(dòng)的 CRM 取代,就像 Google Workspace 正在全面整合它們的 AI 成果一樣。
我們正處于 智能革命 的初期,很難預(yù)測(cè)將要發(fā)生的一切。例如 Uber 這樣的應(yīng)用,你按下手機(jī)上的按鈕,就會(huì)有一個(gè)陌生人開車來(lái)接你,現(xiàn)在看來(lái)稀疏平常,但智能手機(jī)剛出現(xiàn)的時(shí)候你絕對(duì)想不到這樣的應(yīng)用和交互界面。那些 人工智能的原生應(yīng)用 也將如此,所以請(qǐng)打開腦洞,最有趣的應(yīng)用形態(tài)還在等你去發(fā)掘。
我們已經(jīng)感受了基礎(chǔ)模型的強(qiáng)大,但這種方法真能產(chǎn)生的智力和意識(shí)么?今天的人工智能看起來(lái)非常像工具,而不像 智能代理。例如,像 GPT-3 在訓(xùn)練過(guò)程中不斷學(xué)習(xí),但是一旦模型訓(xùn)練完畢,它的參數(shù)的各種權(quán)重就設(shè)置好了,不會(huì)隨著模型的使用而發(fā)生新的學(xué)習(xí)。想象一下,如果你的大腦被凍結(jié)在一個(gè)瞬間,可以處理信息,但永遠(yuǎn)不會(huì)學(xué)到任何新的東西,這樣的智能是你想要的么?Transformer 模型現(xiàn)在就是這樣工作的,如果他們變得有知覺(jué),可以動(dòng)態(tài)的學(xué)習(xí),就像大腦的神經(jīng)元無(wú)時(shí)不刻不在產(chǎn)生新的連接那樣,那它們更高級(jí)的形態(tài)可能代表一種 新的智能。我們會(huì)在第六章聊一下這個(gè)話題,在這之前,先來(lái)看看 AI 如何在現(xiàn)實(shí)世界中生存的。
05 現(xiàn)實(shí)世界的 AI
過(guò)去對(duì)無(wú)人操作電梯的擔(dān)憂與我們今天聽到的對(duì)無(wú)人駕駛汽車的擔(dān)憂十分相似。Garry Kasparov
現(xiàn)實(shí)世界的 AI(Real World AI),按照 Elon Musk 的定義 就是 “ 模仿人類來(lái)感知和理解周圍的世界的 AI”,它們是可以與人類世界共處的 智能機(jī)器。我們?cè)诒疚那懊嫠恼轮刑岬降挠?AI 來(lái)解決的問(wèn)題,大多數(shù)都是你輸入數(shù)據(jù)或者提出目標(biāo),然后 AI 反饋給你結(jié)果或者完成目標(biāo),很少涉及和真實(shí)世界的環(huán)境互動(dòng)。在真實(shí)世界中,收集大量數(shù)據(jù)是極其困難的,除非像 Tesla 一樣擁有幾百萬(wàn)輛帶著攝像頭還實(shí)時(shí)聯(lián)網(wǎng)的電車來(lái)幫你采集數(shù)據(jù);其次感知、計(jì)劃再到行動(dòng),應(yīng)該會(huì)涉及到多種神經(jīng)網(wǎng)絡(luò)和智能算法的組合,就像大腦控制人的行為那樣,這同樣也是對(duì)研發(fā)和工程學(xué)的極端挑戰(zhàn)。但在 Transformer 模型誕生之后,能夠征服現(xiàn)實(shí)世界的 AI 又有了新的進(jìn)展。
5.1 自動(dòng)駕駛新前沿
就在前幾周 Ford 旗下的 Argo AI 宣布倒閉,一時(shí)間又給備受爭(zhēng)議的自動(dòng)駕駛領(lǐng)域蒙上了陰影。目前還沒(méi)有一家做自動(dòng)駕駛方案的公司真正盈利,除了傳奇的 George Hotz 所創(chuàng)辦的 Comma.ai,這個(gè)當(dāng)年 Elon Musk 都沒(méi)撬動(dòng)的軟件工程師和高級(jí)黑客。
技術(shù)路線的選擇
一輛可以自動(dòng)駕駛汽車,實(shí)際上就是一臺(tái)是需要同時(shí)解決硬件和軟件問(wèn)題的 機(jī)器人。它需要用攝像頭、雷達(dá)或其他硬件設(shè)備來(lái) 感知周圍環(huán)境,軟件則是在了解環(huán)境和物理位置的情況下 規(guī)劃路線,最終讓車輛 駛達(dá)目的地。
激光雷達(dá)還有另一個(gè)問(wèn)題,它眼中的世界沒(méi)有色彩也沒(méi)有紋理,必須配合攝像頭才能描繪真實(shí)世界的樣子。但兩種數(shù)據(jù)混合起來(lái)會(huì)讓算法極其復(fù)雜,因此 Tesla 完全放棄了激光雷達(dá),甚至是超聲波雷達(dá),節(jié)省成本是很重要的一個(gè)原因,另一個(gè)原因是現(xiàn)實(shí)世界都道路都是為人類駕駛設(shè)計(jì)的,人只靠視覺(jué)就能完成這個(gè)任務(wù)為什么人工智能不行?這個(gè)理由很具 Elon Musk 的風(fēng)格,只需要加大在 神經(jīng)網(wǎng)絡(luò) 上的研發(fā)投入就可以。
Waymo 和 Tesla 是自動(dòng)駕駛領(lǐng)域的領(lǐng)跑者,Gartner 的副總裁 Mike Ramsey 這樣評(píng)價(jià):“如果目標(biāo)是為大眾提供自動(dòng)駕駛輔助,那么 Tesla 已經(jīng)很接近了;如果目標(biāo)讓車輛能夠安全的自動(dòng)行駛,那么 Waymo 正在取得勝利”。Waymo 是 Level 4,可以在有限的地理?xiàng)l件下自動(dòng)駕駛,不需要司機(jī)監(jiān)督,但驅(qū)動(dòng)它的技術(shù)還沒(méi)有準(zhǔn)備好讓其在測(cè)試領(lǐng)域之外的大眾市場(chǎng)上使用,而且造價(jià)昂貴。從 2015 年開始,Tesla 花了六年多的時(shí)間趕上了 Waymo 現(xiàn)在的測(cè)試數(shù)據(jù),同時(shí)用于自動(dòng)駕駛的硬件越來(lái)越少,成本越來(lái)越低。Tesla 的戰(zhàn)略很有意思:“ 自動(dòng)駕駛要適應(yīng)任何道路,讓車像人一樣思考”,如果成功的話,它的可擴(kuò)展性會(huì)大得多。
讓車看見和思考
Tesla 在 AI 上的押注是從 2017 年 Andrej Karpathy 的加入開始的,一個(gè)靈魂人物確實(shí)能改變一個(gè)行業(yè)。Andrej 領(lǐng)導(dǎo)的 AI 團(tuán)隊(duì)完全重構(gòu)了原有的自動(dòng)駕駛技術(shù),采用最新的神經(jīng)網(wǎng)絡(luò)模型 Transformer 訓(xùn)練了完全基于視覺(jué)的自動(dòng)導(dǎo)航系統(tǒng) FSD Beta 10,在 2021 年的 AI Day 上,Tesla AI 團(tuán)隊(duì)也毫無(wú)保留了分享了這些最新的研發(fā)成果,目的是為了招募更多人才加入。
為了讓車可以像人一樣思考,Tesla 模擬了人類大腦處理視覺(jué)信息的方式,這是一套的由多種神經(jīng)網(wǎng)絡(luò)和邏輯算法組合而成的復(fù)雜流程。
配圖22:The Architecture of Tesla AutoPilot
FSD 的自動(dòng)駕駛步驟大概如下:
- 視覺(jué)影像收集:通過(guò)車載的 6 個(gè) 1280x960 解析度的攝像頭,采集 12bit 色深的視頻,識(shí)別出環(huán)境中的各種物體和 Triggers(道路情況)
- 向量空間生成:人類看到的世界是大腦根據(jù)感知數(shù)據(jù)實(shí)時(shí)構(gòu)建還原的三維世界,Tesla 用同樣的機(jī)制把車周圍世界的全部信息都投射到四維向量空間中,再做成動(dòng)態(tài)的 BEV 鳥瞰圖,讓車在立體的空間中行使和預(yù)測(cè),從而可以精準(zhǔn)控制。在 2021 年之前采用的是基于 Transformer 模型的 HydraNets,現(xiàn)在已經(jīng)升級(jí)到最新的 Occupancy Networks,它可以更加精準(zhǔn)的識(shí)別物體在 3D 空間中的占用情況
- 神經(jīng)網(wǎng)絡(luò)路線規(guī)劃:采用蒙特卡洛算法(mcts)在神經(jīng)網(wǎng)絡(luò)的引導(dǎo)下計(jì)算,快速完成自己路徑的搜索規(guī)劃,而且算法還能給所有移動(dòng)的目標(biāo)都做計(jì)劃,并且可以及時(shí)改變計(jì)劃。看別人的反應(yīng)作出自己的決策,這不就是人類思維么?
Tesla FSD 能夠如此快速的感知和決策,還得靠背后超級(jí)電腦 Tesla Dojo 的神經(jīng)網(wǎng)絡(luò)訓(xùn)練,這和 OpenAI 還有 Google 訓(xùn)練 LLMs 類似,只不過(guò)這些數(shù)據(jù)不來(lái)自互聯(lián)網(wǎng),而是跑在路上的每一輛 Tesla 汽車,通過(guò) Shadow Mode 為 Dojo 提供真實(shí)的 3D 空間訓(xùn)練數(shù)據(jù)。
大自然選擇了 眼睛來(lái)作為最重要的信息獲取器官,也許是冥冥之中的進(jìn)化必然。一個(gè)有理論認(rèn)為 5.3 億年前的寒武紀(jì)物種大爆發(fā)的部分原因是因?yàn)?nbsp;能看見世界了,它讓新的物種可以在快速變化的環(huán)境中移動(dòng)和導(dǎo)航、規(guī)劃行動(dòng)了先和環(huán)境做出互動(dòng),生存概率大幅提高。同理,讓機(jī)器能看見,會(huì)不會(huì)一樣讓這個(gè)新物種大爆發(fā)呢?
5.2 不是機(jī)器人,是智能代理
并不是所有的機(jī)器人都具備感知現(xiàn)實(shí)世界的智能。對(duì)于一個(gè)在倉(cāng)庫(kù)搬運(yùn)貨物的機(jī)器人來(lái)說(shuō),它們不需要大量的 Deep Learning,因?yàn)?nbsp;環(huán)境是已知的和可預(yù)測(cè)的,大部分在特定環(huán)境中使用的自動(dòng)駕駛汽車也是一樣的道理。就像讓人驚嘆的 Boston Dynamic 公司機(jī)器人的舞蹈,他們有世界上最好的機(jī)器人控制技術(shù),但要做那些安排好的動(dòng)作,用程序把規(guī)則寫好就行。很多看官都會(huì)覺(jué)得 Tesla 在今年九月發(fā)布的機(jī)器人 Tesla Optimus 那慢悠悠的動(dòng)作和 Boston Dynamic 的沒(méi)法比,但擁有一個(gè)優(yōu)秀的機(jī)器大腦和可以量產(chǎn)的設(shè)計(jì)更重要。
自動(dòng)駕駛和真實(shí)世界互動(dòng)的核心是安全,不要發(fā)生碰撞;但 AI 驅(qū)動(dòng)的機(jī)器人的核心是和真實(shí)世界發(fā)生互動(dòng),理解語(yǔ)音,抓握避讓物體,完成人類下達(dá)的指令。驅(qū)動(dòng) Tesla 汽車的 FSD 技術(shù)同樣會(huì)用來(lái)驅(qū)動(dòng) Tesla Optimus 機(jī)器人,他們有相同的心臟(FSD Computer)和相同的大腦(Tesla Dojo)。但訓(xùn)練機(jī)器人比訓(xùn)練自動(dòng)駕駛還要困難,畢竟沒(méi)有幾百萬(wàn)個(gè)已經(jīng)投入使用的 Optimus 幫你從現(xiàn)實(shí)世界采集數(shù)據(jù),這時(shí) Metaverse 概念中的 虛擬世界 就能展露拳腳了。
虛擬世界中的模擬真實(shí)
為機(jī)器人感知世界建立新的 基礎(chǔ)模型 將需要跨越不同環(huán)境大量數(shù)據(jù)集,那些虛擬環(huán)境、機(jī)器人交互、人類的視頻、以及自然語(yǔ)言都可以成為這些模型的有用數(shù)據(jù)源,學(xué)界對(duì)使用這些數(shù)據(jù)在虛擬環(huán)境中訓(xùn)練的 智能代理有個(gè)專門的分類 EAI(Embodied artificial intelligence)。在這一點(diǎn)上,李飛飛再次走在了前列,她的團(tuán)隊(duì)發(fā)布了一個(gè)標(biāo)準(zhǔn)化的模擬數(shù)據(jù)集 BEHAVIOR,包含 100 個(gè)類人常見動(dòng)作,例如撿玩具、擦桌子、清潔地板等等,EAI 們可以在任何虛擬世界中進(jìn)行測(cè)試,希望這個(gè)項(xiàng)目能像 ImageNet 那樣對(duì)人工智能的訓(xùn)練數(shù)據(jù)領(lǐng)域有杰出的學(xué)術(shù)貢獻(xiàn)。
在虛擬世界中做模擬,Meta 和 Nvidia 自然不能缺席。佐治亞理工學(xué)院的計(jì)算機(jī)科學(xué)家 Dhruv Batra 也是 Meta AI 團(tuán)隊(duì)的主管,他們創(chuàng)造了一個(gè)名叫 AI 棲息地(AI Habitat)虛擬世界,目標(biāo)是希望提高模擬速度。在這里智能代理只需掛機(jī) 20 分鐘,就可以學(xué)成 20 年的模擬經(jīng)驗(yàn),這真是 元宇宙一分鐘,人間一年呀。Nvidia 除了給機(jī)器人提供計(jì)算模塊之外,由 Omniverse 平臺(tái)提供支持的 NVIDIA Isaac Sim 是一款可擴(kuò)展的機(jī)器人模擬器與合成數(shù)據(jù)生成工具,它能提供逼真的虛擬環(huán)境和物理引擎,用于開發(fā)、測(cè)試和管理智能代理。
機(jī)器人本質(zhì)上是具體化的 智能代理,許多研究人員發(fā)現(xiàn)在虛擬世界中訓(xùn)練成本低廉、受益良多。隨著參與到這個(gè)領(lǐng)域的公司越來(lái)越多,那么數(shù)據(jù)和訓(xùn)練的需求也會(huì)越來(lái)越大,勢(shì)必會(huì)有新的適合 EAI 的 基礎(chǔ)模型誕生,這里面潛力巨大。
Amazon Prime 最新的科幻劇集《The Peripheral》,改編自 William Gibson 在 2014 年的出版的同名小說(shuō),女主角就可以通過(guò)腦機(jī)接口進(jìn)入到未來(lái)的 智能代理。以前一直覺(jué)得 Metaverse 是人類用來(lái)逃避現(xiàn)實(shí)世界的,但對(duì)于機(jī)器人來(lái)說(shuō),在 Metaverse 中修行才是用來(lái)征服現(xiàn)實(shí)世界的。
ARK Invest 在他們的 Big Ideas 2022 報(bào)告中提到,根據(jù)萊特定律,AI 相對(duì)計(jì)算單元(RCU - AI Relative Compute Unit)的生產(chǎn)成本可以每年下降 39%,軟件的改進(jìn)則可以在未來(lái)八年內(nèi)貢獻(xiàn)額外 37% 的成本下降。換句話說(shuō),到 2030 年,硬件和軟件的融合可以讓人工智能訓(xùn)練的成本以每年 60% 的速度下降。
AI 硬件和軟件公司的市值可以以大約 50% 的年化速度擴(kuò)大,從 2021 年的 2.5 萬(wàn)億美元?jiǎng)≡龅?nbsp;2030 年的 87萬(wàn)億美元。
通過(guò)將知識(shí)工作者的任務(wù)自動(dòng)化,AI 應(yīng)能提高生產(chǎn)力并大幅降低單位勞動(dòng)成本,從生成式 AI 的應(yīng)用的大爆發(fā)就可以看出端倪;但用來(lái)大幅降低體力勞動(dòng)的成本,現(xiàn)實(shí)世界的 AI 還有更長(zhǎng)的路要走。我們?cè)詾橹?AI 會(huì)讓體力勞動(dòng)者失業(yè),卻不知道它們確有潛力讓腦力勞動(dòng)者先下崗了。
06 AI 進(jìn)化的未來(lái)
科幻小說(shuō)家 Arthur Clarke 這樣說(shuō)過(guò):" 任何先進(jìn)的技術(shù)都與魔法無(wú)異"!如果回到 19 世紀(jì),想象汽車在高速路上以 100 多公里的時(shí)速行駛,或者用手機(jī)與地球另一端的人視頻通話,那都不可想象的。自 1956 年 Dartmouth Workshop 開創(chuàng)了人工智能領(lǐng)域以來(lái),讓 AI 比人類更好地完成智力任務(wù),我們向先輩們的夢(mèng)想前進(jìn)了一大步。雖然,有些人認(rèn)為這可能永遠(yuǎn)不會(huì)發(fā)生,或者是在非常遙遠(yuǎn)的未來(lái),但 新的模型 會(huì)讓我們更加接近大腦工作的真相。對(duì)大腦的全面了解,才是 AI 通用化(AGI)的未來(lái)。
6.1 透視神經(jīng)網(wǎng)絡(luò)
科學(xué)家們發(fā)現(xiàn),當(dāng)用不同的神經(jīng)網(wǎng)絡(luò)訓(xùn)練同一個(gè)數(shù)據(jù)集時(shí),這些網(wǎng)絡(luò)中存在 相同的神經(jīng)元。由此他們提出了一個(gè)假設(shè):在不同的網(wǎng)絡(luò)中存在著普遍性的特征。也就是說(shuō),如果不同架構(gòu)的神經(jīng)網(wǎng)訓(xùn)練同一數(shù)據(jù)集,那么有一些神經(jīng)元很可能出現(xiàn)在所有不同的架構(gòu)中。
這并不是唯一驚喜。他們還發(fā)現(xiàn),同樣的 特征檢測(cè)器 也存在與不同的神經(jīng)網(wǎng)絡(luò)中。例如,在 AlexNet、InceptionV1、VGG19 和 Resnet V2-50 這些神經(jīng)網(wǎng)絡(luò)中發(fā)現(xiàn)了曲線檢測(cè)器(Curve Detectors)。。不僅如此,他們還發(fā)現(xiàn)了更復(fù)雜的 Gabor Filter,這通常存在于生物神經(jīng)元中。它們類似于神經(jīng)學(xué)定義的經(jīng)典"復(fù)雜細(xì)胞",難道我們的大腦的神經(jīng)元也存在于人工神經(jīng)網(wǎng)絡(luò)中?
OpenAI 的研究團(tuán)隊(duì)表示,這些神經(jīng)網(wǎng)絡(luò)是可以被理解的。通過(guò)他們的 Microscope 項(xiàng)目,你可以可視化神經(jīng)網(wǎng)絡(luò)的內(nèi)部,一些代表抽象的概念,如邊緣或曲線,而另一些則代表狗眼或鼻子等特征。不同神經(jīng)元之間的連接,還代表了有意義的算法,例如簡(jiǎn)單的邏輯電路(AND、OR、XOR),這些都超過(guò)了高級(jí)的視覺(jué)特征。
大腦中的 Transformer
來(lái)自 University College London 的兩位神經(jīng)科學(xué)家 Tim Behrens 和 James Whittington 幫助證明了我們大腦中的一些結(jié)構(gòu)在數(shù)學(xué)上的功能與 Transformer 模型的機(jī)制類似,具體可以看這篇《How Transformers Seem to Mimic Parts of the Brain》,研究顯示了 Transformer 模型精確地復(fù)制在他們 大腦海馬體 中觀察到的那些工作模式。
去年,麻省理工學(xué)院的計(jì)算神經(jīng)科學(xué)家 Martin Schrimpf 分析了 43 種不同的神經(jīng)網(wǎng)絡(luò)模型,和大腦神經(jīng)元活動(dòng)的磁共振成像(fMRI)還有皮層腦電圖(EEG)的觀測(cè)做對(duì)比。他發(fā)現(xiàn) Transformer 是目前最先進(jìn)的神經(jīng)網(wǎng)絡(luò),可以預(yù)測(cè)成像中發(fā)現(xiàn)的幾乎所有的變化。計(jì)算機(jī)科學(xué)家 Yujin Tang 最近也設(shè)計(jì)了一個(gè) Transformer 模型,并有意識(shí)的向其隨機(jī)、無(wú)序的地發(fā)送大量數(shù)據(jù),模仿人體如何將感官數(shù)據(jù)傳輸?shù)酱竽X。他們的 Transformer 模型,就像我們的大腦一樣,能夠成功地處理無(wú)序的信息流。
盡管研究在突飛猛進(jìn),但 Transformer 這種通用化的模型只是朝著大腦工作的精準(zhǔn)模型邁出的一小步, 這是起點(diǎn)而不是探索的終點(diǎn)。Schrimpf 也指出,即使是性能最好的 Transformer 模型也是有限的,它們?cè)趩卧~和短語(yǔ)的組織表達(dá)上可以很好地工作,但對(duì)于像講故事這樣的大規(guī)模語(yǔ)言任務(wù)就不行了。這是一個(gè)很好的方向,但這個(gè)領(lǐng)域非常復(fù)雜!
6.2 千腦理論
Jeff Hawkins 是 Palm Computing 和 Handspring 的創(chuàng)始人,也是 PalmPilot 和 Treo 的發(fā)明人之一。創(chuàng)辦企業(yè)之后,他轉(zhuǎn)向了神經(jīng)科學(xué)的工作,創(chuàng)立了紅木理論神經(jīng)科學(xué)中心(Redwood Center),從此專注人類大腦工作原理的研究。《A Thousand Brains》這本書詳細(xì)的解釋了他最重要的研究成,湛廬文化在今年九月推出了中文版《千腦智能》。
大腦新皮層(Neocortex)是智力的器官。幾乎所有我們認(rèn)為是智力的行為,如視覺(jué)、語(yǔ)言、音樂(lè)、數(shù)學(xué)、科學(xué)和工程,都是由新皮層創(chuàng)造的。Hawkins 對(duì)它工作機(jī)理采取了一種新的解釋框架,稱為 "Thousand Brains Theory",即你的大腦被組織成成千上萬(wàn)個(gè)獨(dú)立的計(jì)算單元,稱為皮質(zhì)柱(Cortical Columns)。這些柱子都以同樣的方式處理來(lái)自外部世界的信息,并且每個(gè)柱子都建立了一個(gè)完整的世界模型。但由于每根柱子與身體的其他部分有不同的聯(lián)系,所以每根柱子都有一個(gè)獨(dú)特的參考框架。你的大腦通過(guò)進(jìn)行投票來(lái)整理出所有這些模型。因此,大腦的基本工作不是建立一個(gè)單一的思想,而是管理它每時(shí)每刻都有的成千上萬(wàn)個(gè)單獨(dú)的思想。
我們可以把運(yùn)行 Transformer 訓(xùn)練的神經(jīng)網(wǎng)絡(luò)的電腦想象成一個(gè)及其簡(jiǎn)陋的 人工皮質(zhì)柱,給它灌輸各種數(shù)據(jù),它輸出預(yù)測(cè)數(shù)據(jù)(參考第四、五兩章的講解來(lái)理解)。但大腦新皮層有 20 多萬(wàn)個(gè)這樣的小電腦在分布式計(jì)算,他們連接著各種感知器官輸入的數(shù)據(jù),最關(guān)鍵的是大腦無(wú)需預(yù)訓(xùn)練,神經(jīng)元自己生長(zhǎng)就完成了學(xué)習(xí),相當(dāng)于把人造的用于訓(xùn)練的超級(jí)電腦和預(yù)測(cè)數(shù)據(jù)的電腦整合了。在科學(xué)家沒(méi)有給大腦完成逆向工程之前,AGI 的進(jìn)展還舉步維艱。
要像大腦一樣學(xué)習(xí)
自我監(jiān)督:新皮層的計(jì)算單位是 皮質(zhì)柱,每個(gè)柱子都是一個(gè)完整的感覺(jué)-運(yùn)動(dòng)系統(tǒng),它獲得輸入,并能產(chǎn)生行為。比如說(shuō),一個(gè)物體移動(dòng)時(shí)的未來(lái)位置,或者一句話中的下一個(gè)詞,柱子都會(huì)預(yù)測(cè)它的下一次輸入會(huì)是什么。預(yù)測(cè)是 皮質(zhì)柱 測(cè)試和更新其模型的方法。如果結(jié)果和預(yù)測(cè)不同,這個(gè)錯(cuò)誤的答案就會(huì)讓大腦完成一次修正,這種方式就是自我監(jiān)督。現(xiàn)在最前沿的神經(jīng)網(wǎng)絡(luò)正 BERT、RoBERTa、XLM-R 正在通過(guò)預(yù)先訓(xùn)練的系統(tǒng)來(lái)實(shí)現(xiàn)“ 自我監(jiān)督”。
持續(xù)學(xué)習(xí):大腦通過(guò) 神經(jīng)元組織來(lái)完成持續(xù)學(xué)習(xí)。當(dāng)一個(gè)神經(jīng)元學(xué)一個(gè)新的模式時(shí),它在一個(gè)樹突分支上形成新的突觸。新的突觸并不影響其他分支上先前學(xué)到的突觸。因此,學(xué)新的東西不會(huì)迫使神經(jīng)元忘記或修改它先前學(xué)到的東西。今天,大多數(shù) Al 系統(tǒng)的人工神經(jīng)元并沒(méi)有這種能力,他們經(jīng)歷了一個(gè)漫長(zhǎng)的訓(xùn)練,當(dāng)完成后他們就被部署了。這就是它們不靈活的原因之一,靈活性要求不斷調(diào)整以適應(yīng)不斷變化的條件和新知識(shí)。
多模型機(jī)制的:新皮層由數(shù)以萬(wàn)計(jì)的皮質(zhì)柱組成,每根柱子都會(huì)學(xué)物體的模型,使多模型設(shè)計(jì)發(fā)揮作用的關(guān)鍵是投票。每一列都在一定程度上獨(dú)立運(yùn)作,但新皮層中的長(zhǎng)距離連接允許各列對(duì)其感知的對(duì)象進(jìn)行投票。智能機(jī)器的 "大腦 "也應(yīng)該由許多幾乎相同的元素( 模型)組成,然后可以連接到各種可移動(dòng)的傳感器。
有自己的參考框架:大腦中的知識(shí)被儲(chǔ)存在參考框架中。參考框架也被用來(lái)進(jìn)行預(yù)測(cè)、制定計(jì)劃和進(jìn)行運(yùn)動(dòng),當(dāng)大腦每次激活參考框架中的一個(gè)位置并檢索相關(guān)的知識(shí)時(shí),就會(huì)發(fā)生思考。機(jī)器需要學(xué)會(huì)一個(gè)世界的模型,當(dāng)我們與它們互動(dòng)時(shí),它們?nèi)绾巫兓约氨舜酥g的相對(duì)位置,都需要參考框架來(lái)表示這類信息。 它們是知識(shí)的骨干。
為什么需要通用人工智能(AGI)
AI 將從我們今天看到的專用方案過(guò)渡到更多的通用方案,這些將在未來(lái)占據(jù)主導(dǎo)地位,Hawkins 認(rèn)為主要有兩個(gè)原因:
第一個(gè)就和通用電腦戰(zhàn)勝專用電腦的原因一樣。通用電腦有更好的成效比,這導(dǎo)致了技術(shù)的更快進(jìn)步。隨著越來(lái)越多的人使用相同的設(shè)計(jì),更多的努力被用于加強(qiáng)最受歡迎的設(shè)計(jì)和支持它們的生態(tài)系統(tǒng),導(dǎo)致成本降低和性能的提升。這是算力指數(shù)式增長(zhǎng)的基本驅(qū)動(dòng)力,它塑造了二十世紀(jì)后半葉的工業(yè)和社會(huì)。
Al 將通用化的第二個(gè)原因是,機(jī)器智能的一些最重要的未來(lái)應(yīng)用將需要通用方案的靈活性,例如 Elon Musk 就希望可以有通用智能的機(jī)器人來(lái)幫忙探索火星。這些應(yīng)用將需要處理很多無(wú)法預(yù)料的問(wèn)題,并設(shè)計(jì)出新穎的解決方案,而今天的專用的 Deep Learning 模型還無(wú)法做到這一點(diǎn)。
6.3 人工智能何時(shí)通用?
通用人工智能(AGI)這是 AI 領(lǐng)域的終極目標(biāo),應(yīng)該也是人類發(fā)明了機(jī)器計(jì)算之后的終極進(jìn)化方向。回顧 機(jī)器之心六十多年的進(jìn)化,我們似乎找到了方法,就是模仿人類的大腦。Machine Learning 要完成這塊拼圖,需要有 數(shù)據(jù)、 算力 還有 模型的改進(jìn)。
數(shù)據(jù)
應(yīng)該是拼圖中最容易實(shí)現(xiàn)的。按秒來(lái)計(jì)算,ImageNet 數(shù)據(jù)集的大小已經(jīng)接近人從出生到大學(xué)畢業(yè)視覺(jué)信號(hào)的數(shù)據(jù)量;Google 公司創(chuàng)建的新模型 HN Detection,用來(lái)理解房屋和建筑物外墻上的街道號(hào)碼的數(shù)據(jù)集大小,已經(jīng)可以和人一生所獲取的數(shù)據(jù)量所媲美。要像人類一樣,使用更少的數(shù)據(jù)和更高的抽象來(lái)學(xué)習(xí),才是神經(jīng)網(wǎng)絡(luò)的發(fā)展方向。
算力
可以分解為兩個(gè)部分:神經(jīng)網(wǎng)絡(luò)的參數(shù)(神經(jīng)元的數(shù)量和連接)規(guī)模以及單位計(jì)算的成本。下圖可以看到,人工神經(jīng)網(wǎng)絡(luò)與人腦的大小仍有數(shù)量級(jí)的差距,但它們?cè)谀承┎溉閯?dòng)物面前,已經(jīng)具備競(jìng)爭(zhēng)力了。
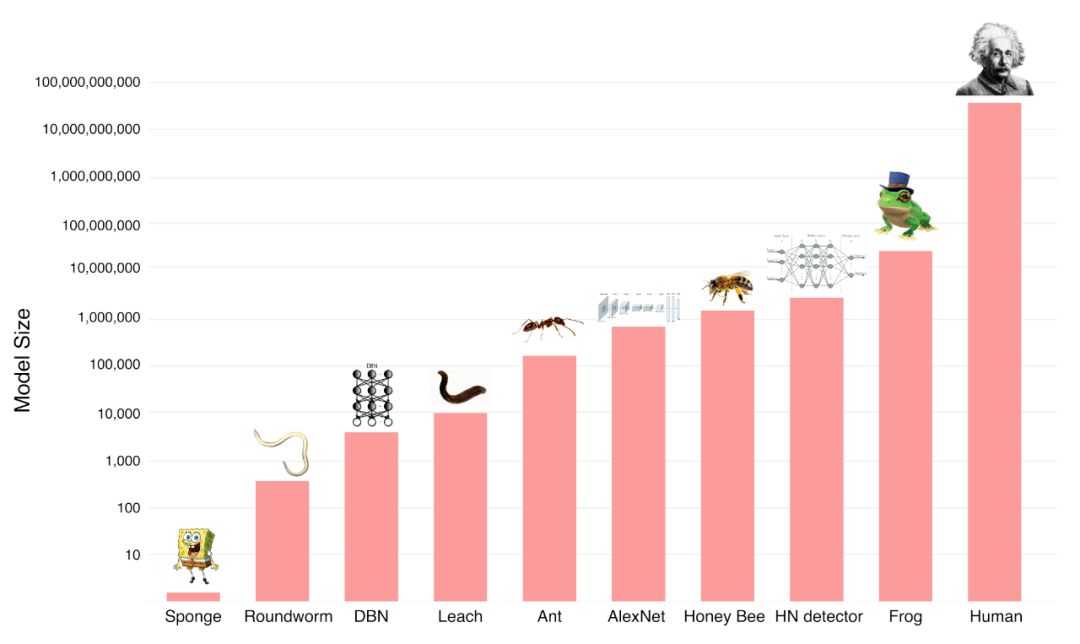
配圖29:神經(jīng)網(wǎng)絡(luò)規(guī)模和動(dòng)物與人類神經(jīng)元規(guī)模的對(duì)比
我們每花一美元所能得到的計(jì)算能力一直在呈指數(shù)級(jí)增長(zhǎng)。現(xiàn)在大規(guī)模基礎(chǔ)模型所用到的計(jì)算量每 3.5 個(gè)月就會(huì)翻一番。
配圖30:122 years of Moore’s Law: 每一美元產(chǎn)生的算力
有些人認(rèn)為,由于物理學(xué)的限制,計(jì)算能力不能保持這種上升趨勢(shì)。然而,過(guò)去的趨勢(shì)并不支持這一理論。隨著時(shí)間的推移,該領(lǐng)域的資金和資源也在增加,越來(lái)越多人才進(jìn)入該領(lǐng)域,因?yàn)?nbsp;涌現(xiàn) 的效應(yīng),會(huì)開發(fā)更好的 軟件(算法模型等)和 硬件。而且,物理學(xué)的限制同樣約束人腦的能力極限,所以 AGI 可以實(shí)現(xiàn)。
當(dāng) AI 變得比人類更聰明、我們稱這一刻為 奇點(diǎn)。一些人預(yù)測(cè),奇點(diǎn)最快將于 2045 年到來(lái)。Nick Bostrom 和 Vincent C. Müller 在 2017 年的一系列會(huì)議上對(duì)數(shù)百名 AI 專家進(jìn)行了調(diào)查, 奇點(diǎn)(或人類水平的機(jī)器智能)會(huì)在哪一年發(fā)生,得到的答復(fù)如下:
- 樂(lè)觀預(yù)測(cè)的年份中位數(shù) (可能性 10%) - 2022
- 現(xiàn)實(shí)預(yù)測(cè)的年份中位數(shù) (可能性 50%) - 2040
- 悲觀預(yù)測(cè)的年份中位數(shù) (可能性 90%) - 2075
因此,在 AI 專家眼里很有可能在未來(lái)的 20 年內(nèi),機(jī)器就會(huì)像人類一樣聰明。
這意味著對(duì)于每一項(xiàng)任務(wù),機(jī)器都將比人類做得更好;當(dāng)計(jì)算機(jī)超過(guò)人類時(shí),一些人認(rèn)為,他們就可以繼續(xù)變得更好。換句話說(shuō),如果我們讓機(jī)器和我們一樣聰明,沒(méi)有理由不相信它們能讓自己變得更聰明,在一個(gè)不斷改進(jìn)的 機(jī)器之心進(jìn)化的螺旋中,會(huì)導(dǎo)致 超級(jí)智能 的出現(xiàn)。
從工具進(jìn)化到數(shù)字生命
按照上面的專家預(yù)測(cè),機(jī)器應(yīng)該具有自我意識(shí)和超級(jí)智能。到那時(shí),我們對(duì)機(jī)器意識(shí)的概念將有一些重大的轉(zhuǎn)變,我們將面對(duì)真正的數(shù)字生命形式(DILIs - Digital Lifeforms)。
一旦你有了可以快速進(jìn)化和自我意識(shí)的 DILIs,圍繞物種競(jìng)爭(zhēng)會(huì)出現(xiàn)了一些有趣的問(wèn)題。DILIs 和人類之間的合作和競(jìng)爭(zhēng)的基礎(chǔ)是什么?如果你讓一個(gè)有自我意識(shí)的 DILIs 能模擬疼痛,你是在折磨一個(gè)有感知的生命嗎?
這些 DILIs 將能夠在服務(wù)器上進(jìn)行自我復(fù)制和編輯(應(yīng)該假設(shè)在某個(gè)時(shí)候,世界上的大多數(shù)代碼將由可以自我復(fù)制的機(jī)器來(lái)編寫),這可能會(huì)加速它們的進(jìn)化。想象一下,如果你可以同時(shí)創(chuàng)建100,000,000 個(gè)你自己的克隆體,修改你自己的不同方面,創(chuàng)建你自己的功能函數(shù)和選擇標(biāo)準(zhǔn),DILIs 應(yīng)該能夠做到這一切(假設(shè)有足夠的算力和能量資源)。關(guān)于 DILIs 這個(gè)有趣的話題在《Life 3.0》和《Superintelligence: Paths, Dangers, Strategies》這兩本書中有詳細(xì)的討論。
這些問(wèn)題可能比我們的預(yù)期來(lái)得更快。Elad Gil 在他的最新文章《AI Revolution》提到 OpenAI、Google 和各種創(chuàng)業(yè)公司的核心 AI 研究人員都認(rèn)為,真正的 AGI 還需要 5 到 20 年的時(shí)間才能實(shí)現(xiàn), 這也有可能會(huì)像自動(dòng)駕駛一樣永遠(yuǎn)都在五年后實(shí)現(xiàn)。不管怎樣,人類最終面臨的潛在生存威脅之一,就是與我們的數(shù)字后代競(jìng)爭(zhēng)。
歷史學(xué)家 Thomas Kuhn 在其著名的《The Structure of Scientific Revolutions》一書中認(rèn)為,大多數(shù)科學(xué)進(jìn)步是基于廣泛接受的理論框架,他稱之為 科學(xué)范式。偶爾,一個(gè)既定的范式被推翻,被一個(gè)新的范式所取代 - Kuhn 稱之為 科學(xué)革命。我們正處在 AI 的智能革命之中!
最后,送上一首 AI 創(chuàng)作的曲子《I Am AI》,Nvidia 每年的 GTC 大會(huì)上都會(huì)更新一次內(nèi)容,看看 AI 如何從各個(gè)行業(yè)滲透到我們的生活。
參考返回搜狐,查看更多
- Letter from Alan Turing to W Ross Ashby - Alan Mathison Turing
- Software 2.0 - Andrej Karpathy
- The Rise of Software 2.0 - Ahmad Mustapha
- Infrastructure 3.0: Building blocks for the AI revolution - Lenny Pruss, Amplify Partners
- Will Transformers Take Over Artificial Intelligence? - Stephen Ornes
- AI Revolution - Transformers and Large Language Models (LLMs) - Elad Gil
- What Is a Transformer Model? - RICK MERRITT
- AI 時(shí)代的巫師與咒語(yǔ)- Rokey Zhang
- Generative AI: A Creative New World - SONYA HUANG, PAT GRADY AND GPT-3
- What Real-World AI From Tesla Could Mean - CleanTechNica
- A Look at Tesla's Occupancy Networks - Think Autonomous
- By Exploring Virtual Worlds, AI Learns in New Ways - Allison Whitten
- Self-Taught AI Shows Similarities to How the Brain Works - Anil Ananthaswamy
- How Transformers Seem to Mimic Parts of the Brain - Stephen Ornes
- Attention Is All You Need - PAPER by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
- On the Opportunities and Risks of Foundation Models - PAPER by CRFM & HAI of Stanford University
- Making Things Think - BOOK by Giuliano Giacaglia
- A Thousand Brains(中文版:千腦智能)- BOOK by Jeff Hawkins





