
UCloud優(yōu)刻得在2015年推出了為云主機磁盤提供持續(xù)數(shù)據(jù)保護(hù)(CDP)的數(shù)據(jù)方舟(UDataArk)產(chǎn)品,支持最小精確到秒級的恢復(fù),針對數(shù)據(jù)刪除或者丟失事件,能夠最大程度的挽回數(shù)據(jù)。數(shù)據(jù)方舟已經(jīng)在多個數(shù)據(jù)安全案例中得到應(yīng)用,并得到了眾多客戶的認(rèn)可。
近些年,隨著用戶高性能存儲場景需求的增多,SSD云盤和RSSD云盤成為主流選擇, 但是數(shù)據(jù)方舟只針對本地盤及普通云盤,SSD云盤和RSSD云盤缺乏高效的備份手段成為用戶的痛點。為此UCloud優(yōu)刻得推出了磁盤快照服務(wù)(USnap),USnap基于數(shù)據(jù)方舟CDP技術(shù)并進(jìn)一步升級,以更低的成本為全系列云盤(普通/SSD/RSSD)提供了數(shù)據(jù)備份功能。
如何接入SSD/RSSD云盤等高性能設(shè)備以及如何降低連續(xù)數(shù)據(jù)保護(hù)功能的實現(xiàn)成本,是USnap產(chǎn)品要解決的兩個核心問題。這不僅僅需要在數(shù)據(jù)方舟架構(gòu)層面上做出改進(jìn),所有IO路徑的相關(guān)模塊也需要做重新設(shè)計。本文將詳細(xì)介紹UCloud優(yōu)刻得USnap是如何使用數(shù)據(jù)方舟CDP技術(shù)并對其升級改造的技術(shù)細(xì)節(jié)。
Client捕獲用戶寫IO
方舟備份存儲集群獨立于UDisk存儲集群,是我們重要的設(shè)計前提,這保證了即使出現(xiàn)了UDisk集群遭遇故障而導(dǎo)致數(shù)據(jù)丟失的極端事件,用戶仍能從備份存儲集群中恢復(fù)數(shù)據(jù)。對此,我們實現(xiàn)了一個ark plug-in,集成到了UDisk的client中,這個plug-in會異步的捕獲UDisk的寫IO,并將其推送到方舟備份存儲集群。
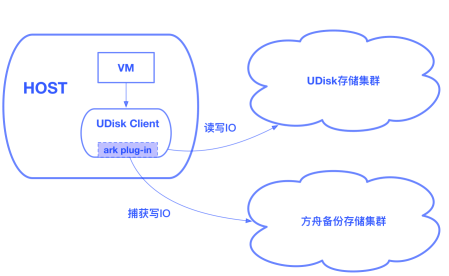
如何高效的捕獲UDisk IO是個重要的問題,我們希望對UDisk的IO路徑影響到最低。對于SSD UDisk client和RSSD UDisk client,IO的捕獲模式是完全不同的。
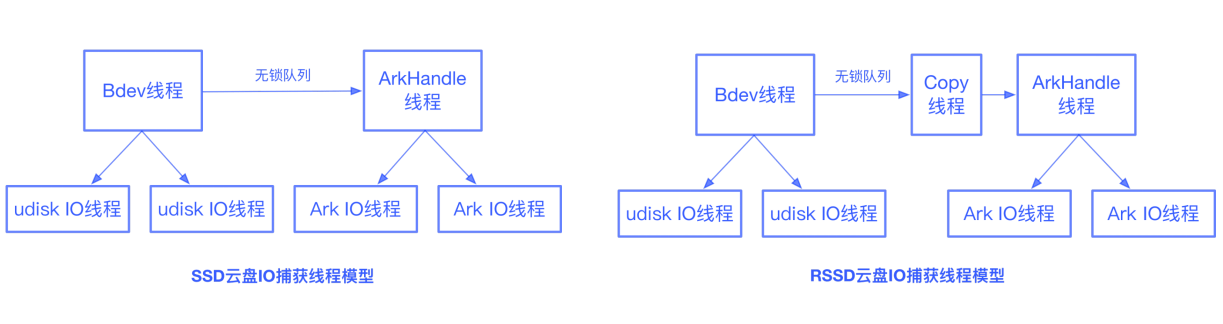
對于SSD UDisk,Bdev線程在接受一個IO后,先提交到UDisk的IO線程中,如果是寫IO還需要推送至方舟備份存儲集群。對此Bdev線程會構(gòu)建一個ArkIORequest,拷貝一份包含data的智能指針對象,加入到無鎖隊列中。ArkHandle線程從無鎖隊列中獲取IO,轉(zhuǎn)發(fā)給ArkIO線程進(jìn)行推送。UDisk IO完成后,無需等待方舟IO完成即可返回成功。UDisk IO和方舟IO均完成后,data才會被釋放。
對于RSSD UDisk,由于采用SPDK Vhost方案,Vhost和guest VM共享內(nèi)存,UDisk IO完成后,data內(nèi)存空間會立即被guest VM使用。為此我們加入了一個copy線程,由copy線程從無鎖隊列中獲取bdev_io,進(jìn)行數(shù)據(jù)copy,數(shù)據(jù)copy完畢后再構(gòu)建一個ArkIORequest轉(zhuǎn)發(fā)給ArkIO線程進(jìn)行推送,方舟IO完成后data由方舟plug-in中的ArkHandle進(jìn)行釋放。
我們模擬了各種類型的IO場景,研究方舟plug-in對UDisk性能的影響。發(fā)現(xiàn)在低io_depth的場景下,方舟功能對于UDisk性能的影響最大不會超過5%,在高io_depth的場景下,方舟功能對于UDisk性能的影響接近0%。可見方舟plug-in實現(xiàn)了高效的數(shù)據(jù)捕獲與轉(zhuǎn)發(fā),不會影響用戶的線上業(yè)務(wù)。
塊層IO可以理解為一個三元組(sector, sector_num, data),代表讀寫位置、讀寫大小和實際數(shù)據(jù)。對于CDP系統(tǒng),IO的三元組信息是不夠的,需要標(biāo)記額外信息,才能夠恢復(fù)到任何一個時間點。在數(shù)據(jù)捕獲時,所有的寫IO都會標(biāo)記好序列號(seq_num),序列號保證嚴(yán)格連續(xù)遞增,這是我們保證塊級數(shù)據(jù)一致性的基礎(chǔ)。并且所有的寫IO也會打上時間戳,方舟plug-in會保證即使在出現(xiàn)時鐘跳變的情況下,時間戳也不會出現(xiàn)回退。這樣數(shù)據(jù)變化及其時間戳都被保存下來,后端可以根據(jù)這些信息通過某種方式回放,恢復(fù)到過去的任意時刻,這就是CDP技術(shù)的基本原理。在推送到方舟備份存儲集群前,方舟plug-in會對IO進(jìn)行合并,這可以顯著減少方舟接入層的IOPS。
Front實時IO接入層
方舟備份集群采用分層存儲,實時IO接入層使用少量的NVME等高速存儲設(shè)備,承接海量實時IO,實時IO會定期下沉到采用大量HDD設(shè)備構(gòu)建的容量存儲層。方舟的接入層(Front)是整個數(shù)據(jù)方舟系統(tǒng)的門戶,其性能關(guān)系到能否接入SSD/RSSD云盤等高性能的設(shè)備。
原始的Front是基于Log-structured的設(shè)計,每塊邏輯盤會被分配一組Front節(jié)點,對于一次簡單的磁盤IO寫入操作,client將IO轉(zhuǎn)發(fā)到Primary Front節(jié)點,Primary Front節(jié)點將此次的IO追加寫入到最新的Log中,并將IO同步到Slavery Front節(jié)點。
分析可知該設(shè)計存在以下問題:1. 一塊邏輯盤的實時IO只落在一組(Primary-Slavery)Front節(jié)點上,所以系統(tǒng)對于單塊邏輯盤的接入性能受到Front單節(jié)點性能限制。這種設(shè)計是無法接入RSSD云盤這種超高性能設(shè)備的。2.雖然通過hash的方式將用戶邏輯盤打散分布到整個接入層集群,但是可能出現(xiàn)分配在同一組Front節(jié)點的多塊邏輯盤同時存在高IO行為,由此產(chǎn)生了熱點問題,雖然可以通過運維手段將其中的部分邏輯盤切換到空閑的Front節(jié)點上,但這并不是解決問題的最佳方式。
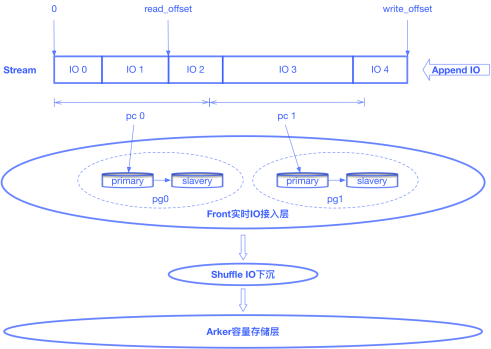
針對于此,我們提出了基于Stream數(shù)據(jù)流的設(shè)計,以滿足高IO場景下業(yè)務(wù)對于接入能力的要求。Stream數(shù)據(jù)流的概念即是將邏輯盤的所有寫入數(shù)據(jù)抽象成為一段數(shù)據(jù)流,數(shù)據(jù)只在Stream尾部進(jìn)行追加寫。Stream按照固定大小分片,每個分片按照一致性hash算法映射到一個歸置組,歸置組代表一個副本組,由存儲資源按照一定策略組成。這樣就將一塊邏輯盤的實時IO打散到了所有接入層集群上,這不僅解決了接入RSSD云盤這種超高性能設(shè)備的問題,同時還解決了接入層熱點的問題。
Stream數(shù)據(jù)流符合Buffer的特性,即從尾部寫入、從頭部讀出。我們使用一組數(shù)據(jù)來標(biāo)識Stream數(shù)據(jù)流的有效區(qū)域:read_offset和write_offset。當(dāng)Stream有實時數(shù)據(jù)寫入,write_offset增長。Shuffle模塊會處理實時IO下沉到容量存儲層的工作。Shuffle會從Front定期拉取數(shù)據(jù),在內(nèi)存中進(jìn)行分片(sharding),并組織為Journal數(shù)據(jù),推送至下層的Arker容量存儲層。推送Arker成功后,read_offset更新。對于已經(jīng)下沉到方舟Arker容量存儲層的數(shù)據(jù),我們會對其進(jìn)行回收以釋放存儲資源。
Arker容量存儲層
CDP數(shù)據(jù)需要按照粒度(Granu)進(jìn)行組織。根據(jù)業(yè)務(wù)需要,Granu被分為5種類型:journal、hour、day、base和snapshot,journal是秒級數(shù)據(jù),包含用戶的原始寫請求;hour代表小時級別的增量數(shù)據(jù);day代表天級別的增量數(shù)據(jù);base是CDP的最底層數(shù)據(jù);snapshot是用戶的手動快照數(shù)據(jù)。Granu會按照設(shè)定的備份策略進(jìn)行合并。以默認(rèn)的支持恢復(fù)到12小時內(nèi)任意一秒、24小時內(nèi)的任意整點以及3天內(nèi)的任意零點為例,journal至少會被保留12小時,超過12小時的journal會被合并為hour,此時數(shù)據(jù)的tick信息會被丟棄,之后的時間區(qū)間無法再恢復(fù)到秒級,超過24小時的hour會被合并為day,超過3天的day會和base合并為新的base,對于snapshot則會長久保留除非用戶主動刪除了快照。
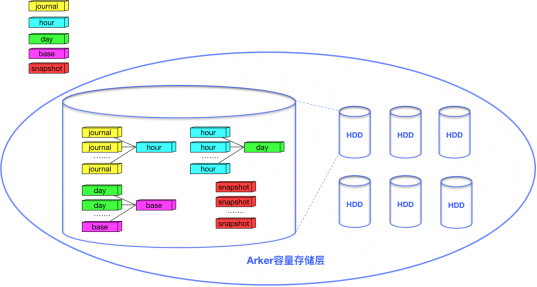
作為方舟的容量存儲層,Arker為5類不同的Granu提供了統(tǒng)一的存儲;對于5種類型的Granu,又存在3種存儲格式:BASE Blob、CUT Blob和JOURNAL Bob。其中base和snapshot兩類Granu以BASE Blob格式存儲,day和hour兩類Granu以CUT Blob格式存儲,journal類型的Granu以JOURNAL Blob格式存儲。
對于journal、hour和day三類Granu,我們直接按分片進(jìn)行存儲,每個有數(shù)據(jù)存在的分片都唯一對應(yīng)了一個inode對象,這個inode對象關(guān)聯(lián)一個JOURNAL Blob或CUT Blob。對于base和snapshot兩類Granu,我們將分片中的數(shù)據(jù)進(jìn)一步細(xì)化,切分成一系列的TinyShard作為重刪單元,每個TinyShard也會唯一對應(yīng)一個inode對象,這個inode對象會關(guān)聯(lián)一個BASE Blob,數(shù)據(jù)相同的TinyShard會指向同一個inode對象,復(fù)用BASE Blob,由此達(dá)到了重刪的目的。
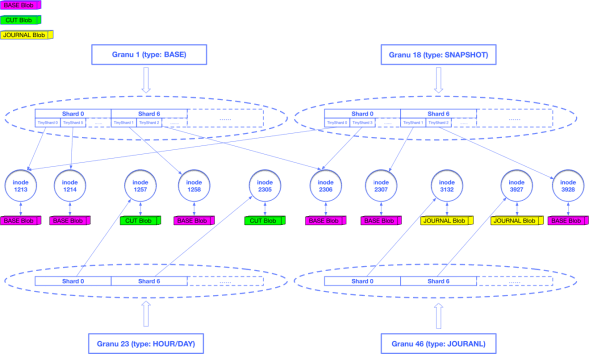
為了提高合并效率,我們還將索引和數(shù)據(jù)的存儲進(jìn)行分離,以上所有業(yè)務(wù)元數(shù)據(jù)(Granu、Shard/TinyShard、Inode)都以key-value的形式存儲在KVDevice中,Blob數(shù)據(jù)經(jīng)過壓縮后存儲在FSDevice中,數(shù)據(jù)壓縮算法采用zstd算法,比起原先使用的snappy算法,又節(jié)約了至少30%的存儲成本。
一次完整的回滾流程
整個回滾流程由調(diào)度模塊Chrono進(jìn)行控制。當(dāng)用戶指定了一個回滾時間點,Chrono首先通過查詢Granu元數(shù)據(jù)確認(rèn)該目標(biāo)點數(shù)據(jù)命中的位置。命中位置只有兩種情況,一種是目標(biāo)點數(shù)據(jù)還在Front接入層,尚未被Shuffle推送至Arker容量存儲層,另一種是已經(jīng)被Shuffle推送至Arker容量存儲層。
如果是第一種情況,Chrono會命令Shuffle主動拉取這部分?jǐn)?shù)據(jù)至Arker容量存儲層。在確認(rèn)目標(biāo)點數(shù)據(jù)已經(jīng)在Arker容量存儲層后,Chrono會查詢獲取到所有需要合并的Granu以及需要合并到哪個seq_num,并分發(fā)合并任務(wù)至所有Arker。Arker容量存儲層會對這些Granu進(jìn)行合并,對于一個合并任務(wù),會首先進(jìn)行索引合并,隨后會根據(jù)已經(jīng)合并完成的索引進(jìn)行數(shù)據(jù)合并,合并完成后最終會生成一份新版本的BASE,這就是恢復(fù)后的全量數(shù)據(jù)。在得到恢復(fù)后的全量數(shù)據(jù)后,再將數(shù)據(jù)寫回到UDisk集群中。

我們可以看到,數(shù)據(jù)合并階段是以shard為單位并發(fā)進(jìn)行的,能利用到所有容量層磁盤的IO能力;數(shù)據(jù)回吐UDisk階段,也利用了方舟和UDisk都是分布式存儲,可以采取分片并發(fā)對拷的方式將數(shù)據(jù)寫入到UDisk集群。因此恢復(fù)的RTO也能得到保證,1TB的數(shù)據(jù)恢復(fù)時間通常在30min以內(nèi)。
總結(jié)
本文圍繞著公有云CDP備份系統(tǒng)如何構(gòu)建、CDP系統(tǒng)如何接入高性能IO設(shè)備以及CDP系統(tǒng)如何降低實現(xiàn)成本等幾個主要問題,介紹了UCloud優(yōu)刻得磁盤快照服務(wù)USnap在業(yè)務(wù)架構(gòu)、存儲引擎等多方面的設(shè)計考慮和優(yōu)化方案。
后續(xù)UCloud優(yōu)刻得還會在多個方面繼續(xù)提升磁盤快照服務(wù)USnap的使用體驗。產(chǎn)品上將會提供可以自定義備份時間范圍的增值服務(wù),讓用戶可以自定義秒級、小時級、天級的保護(hù)范圍,滿足用戶的不同需求。技術(shù)上,則會引入全量全刪和Erasure Coding等技術(shù)進(jìn)一步降低成本,以及使用Copy On Read技術(shù)加快回滾速度,讓用戶能夠享受到更先進(jìn)技術(shù)帶來的豐富功能、性能提升和價格紅利。





