

Jeff Dean 表示:“更多的進展即將到來。”
歡迎關注“新浪科技”的微信訂閱號:techsina
文/杜晨
來源:硅星人(ID:guixingren123)
近幾年科技行業瘋狂加注超大規模語言模型,一個最主要的成果就是“人工智能創造內容”(AIGC) 技術突飛猛進。兩年前 OpenAI 通過 GPT-3 模型展示了大語言模型的多樣化實力。而最近各種 AI 基于文字提示生成圖片的產品,更是數不勝數。
有趣的是,今年以來 AIGC 的風頭基本都被Stable Diffusion、Craiyon、Midjourney等“小玩家”給搶了——像谷歌這樣的 AI 巨頭,反而沒怎么見動靜。
但其實谷歌并沒有“躺平”。
臨近年底,在11月2日早上,谷歌終于放出了大招。這家在 AI 研究上最久負盛名的硅谷巨頭,居然一鼓作氣發布了四項最新的 AIGC 技術成果,能夠根據文本提示生成:
高分辨率長視頻
3D模型
音樂
代碼
以及可控文本生成技術。
 圖片來源:google Research
圖片來源:google Research
“用 AI 賦能的生成式模型,具有釋放創造力的潛能。通過這些技術,來自不同文化背景的人們都可以更方便地使用圖像、視頻和設計來表達自己,這在以前是無法做到的,”谷歌 AI 負責人 Jeff Dean 說道。
他表示,經過谷歌研究人員的不懈努力,現在公司不僅擁有在生成質量方面在行業領先的模型,還在這些模型基礎上取得了進一步創新。
 Jeff Dean 圖片來源:谷歌
Jeff Dean 圖片來源:谷歌
這些創新,包括“超分辨率的視頻序列擴散模型”——也即將AI“文生圖”擴展到“文生視頻”,并且仍然確保超高清晰度。
以及 AudioLM,一個無需文字和音樂符號訓練,僅通過聆聽音頻樣本,就可以繼續生成填補樂曲的音頻模型。
從生成文字,到生成代碼、音頻、圖片、視頻和3D模型,谷歌似乎正在證明 AIGC 技術的能力還遠未達到邊界,并且大有用武之地。
接下來,一起好好看看谷歌這次都放了哪些大招。
| AI 寫作助手,深受劉宇昆喜愛?
說實話,看到谷歌做了一款 AI 寫作工具的時候,硅星人是略微有點擔心失業的……
但是了解了關于這款工具更多的情況之后,這種心情更多地轉化成了欣慰。
我們一直在強調AI背后的“大語言模型”技術背景。而谷歌推出的 LaMDA wordcraft,就是這樣一款將語言模型核心功能發揮到極致的技術
LaMDA Wordcraft 是在 LaMDA 大語言模型的基礎上開發了一個寫作協助工具,是谷歌大腦團隊、PAIR(People + AI Research)團隊,以及 Magenta 音頻生成項目組的合作結晶。
它的作用,是在創作者寫作的過程當中,根據現有的文本產生新的想法,或者幫助重寫已有文句,從而幫助創作者突破“創作瓶頸” (writer‘s block)。
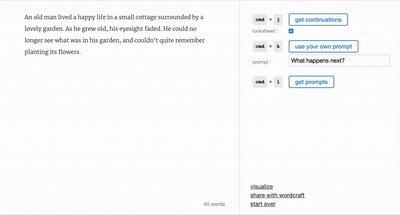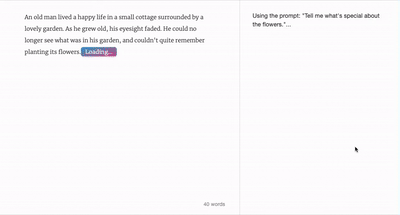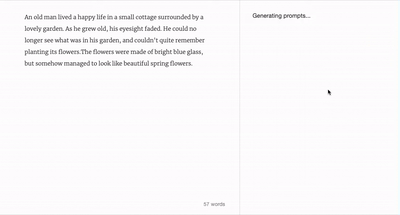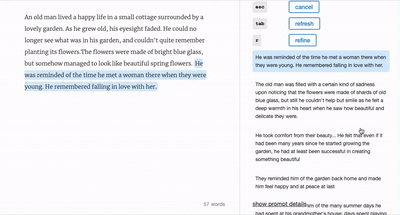 Wordcraft 用戶界面 圖片來源:Google Research
Wordcraft 用戶界面 圖片來源:Google Research
LaMDA 本身的設計功能很簡單:給定一個單詞,預測下一個最有可能的單詞是什么,也可以理解成完形填空或者句子補完。
但是有趣的是,因為 LaMDA 的模型規模和訓練數據量實在是太大了(來自于整個互聯網的文本),以至于它獲得了一種“潛意識”的能力,可以從語言中學習很多更高層次的概念——而正是這些高層次概念,對于創作者的工作流程能夠帶來非常大的幫助。
谷歌在 Wordcraft 用戶界面中設計了多種不同的功能,能夠讓創作者自己調整生成文本的風格。“我們喜歡把 Wordcraft 比喻成‘魔法文字編輯器’,它有著熟悉的網頁編輯器的樣子,背后卻集成了一系列 LaMDA 驅動的強大功能,”谷歌網頁如是寫道。
你可以用 Wordcraft 重寫語句,也可以讓他把調節你的原始文本從而“更有趣”(to be funnier) 或者“更憂郁” (to be more melancholy) 一點。
在過去一年時間里,谷歌舉行了一個“Wordcraft 作家研討會”的合作項目,找來了13位專業作家和文字創作者進行了長期深入的合作,讓他們在自己的創作過程中借助 Wordcraft 編輯器來創作短篇小說。

值得注意的是,知名科幻作家劉宇昆(熱劇《萬神殿》背后的小說作者、《三體》英文版譯者)也參與了這一項目。
他在寫作過程中遇到了一個場景,需要描述在商店里擺放的各種商品——過去此類寫作細節比較容易打亂寫作思路,但劉宇昆通過 Wordcraft 的幫助可以直接生成一個列表,節約了自己的腦容量,可以專心去寫對故事更重要的東西。

而在另一個場景中,他發現自己的想象力被限制了,一直在重復熟悉的概念。于是他將“主動權”交給了 LaMDA,讓它來開頭,“這樣就能夠逼迫我探索一些從未想到過的可能性,發現新的寫作靈感。”
你可以在 Wordcraft Writers Workshop 的官方頁面(閱讀原文按鈕)中找到劉宇昆在 Wordcraft 幫助下撰寫的短篇小說 Evaluative Soliloquies。順便,他還借用 Imagen 為小說生成了幾張插圖:
 圖片來源:Emily Reif via Imagen
圖片來源:Emily Reif via Imagen
| 超長、連貫性視頻的生成,終于被攻破了?
大家對于 AI 文字生成圖片應該都不算陌生了。最近一年里,有 DALL·E 2、Midjourney、Stable Diffusion、Craiyon(不分先后)等知名產品問世;而谷歌也有自己的AI 文字轉圖片模型,并且一做就是兩個:Imagen(基于大預言模型和行業流行的擴散模型),和 Parti(基于谷歌自家的 Pathways 框架)。
 圖片來源:Google Research
圖片來源:Google Research
盡管今年 AIGC 的熱鬧都被 Stable Diffusion 這些炸子雞給搶光了,低調沉穩的谷歌并沒有躺平。
當其他人都似乎“階段性”滿足于用文字提示做小圖片時,谷歌其實已經在加速往前沖了:它比任何人都更早進入了“文字生成高分辨率視頻”,這一從未被探索過的復雜技術領域。
“生成高分辨率,且在時間上連貫的視頻,是非常困難的工作,” Google Research 高級研究總監 Douglas Eck 表示。
“不過好在,我們最近有兩項研究,Imagen Video 和 Phenaki,可以解決視頻生成的問題。”
 圖片來源:Google Research
圖片來源:Google Research
你可以這樣理解:文字轉圖片就是根據一段文字提示來生成一張(或者多張平行的圖片),而 Imagen Video 和 Phenaki 是可以根據多條文字提示,來生成在時序上連貫的多張照片——也就是視頻。
具體來說,Imagen Video 是通過文本生成圖像的擴散模型,能夠生成具有前所未有真實度的高清畫面;同時由于建立在基于 Transformer 技術的大規模語言模型上,它也具備極強的語言理解能力。
而 Phenaki 則是完全通過大語言模型,在時序上不斷生成 token 的方式來生成視頻。它的優勢在于能夠生成極長(數分鐘)的視頻,且畫面的邏輯和視覺連貫性更強。
一個藍色的氣球插在紅杉樹的樹枝上
鏡頭從掛著藍色氣球的樹上移到動物園門口
鏡頭快速移動到動物園內
第一人稱視角:在一個美麗的花園內飛行
長頸鹿的頭從旁邊冒出來
長頸鹿走向一棵樹
放大長頸鹿的嘴
長頸鹿靠近樹枝,拿起一個藍色的氣球
一個帶白線的藍色氣球向長頸鹿的頭部飛去
長頸鹿在附近咀嚼藍氣球鏡頭
隨著單個藍氣球的飛走而向上傾斜
“說句實在話,這個項目不是我做的,但我覺得它真的非常令人驚訝。”Eck 表示,這項技術最強大之處,就在于可以使用多條文字提示組成的序列,來生成超高清晰度的視頻,帶來一種全新的故事講述的能力。
“當然,AI 視頻生成技術還處在襁褓階段,我們非常期待跟更多影視專業人士以及視覺內容創作者合作,看他們會如何使用這項技術。”
 Douglas Eck 圖片來源:谷歌
Douglas Eck 圖片來源:谷歌
| 無參考音頻生成
早年 OpenAI 發布 GPT 初代模型的論文標題很經典:“Language models are few-shot learners”,點出了大語言模型在極少量樣本的基礎上,就可以在多種自然語言處理類任務上展現出強大的能力——同時,這個標題預言了今后更強大的大語言模型,能夠做到更多更厲害的事情。
而今天,谷歌展示的 AudioLM 純音頻模型就驗證了這一預言。
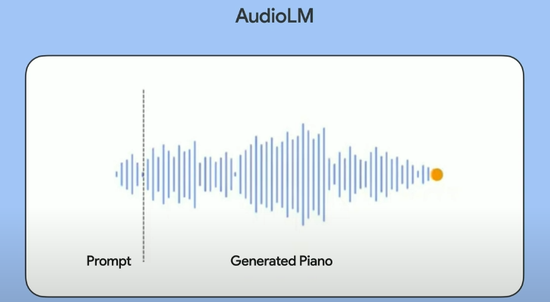
圖片來源:Google Research
AudioLM 是一個具備“長期連貫性”的高質量音頻生成框架,不需要任何文字或音樂符號表示的情況下,只在極短(三四秒即可)的音頻樣本基礎上進行訓練,即可生成自然、連貫、真實的音頻結果,而且不限語音或者音樂。
用 AudioLM 生成的語句,在句法和語義上仍然保持了較高的可信度和連貫性,甚至能夠延續樣本中說話人的語氣。
更厲害的是,這個模型最初沒有用任何音樂數據進行訓練,結果卻十分驚人:能夠從任何樂器或樂曲錄音中進行自動“續寫”——這一事實,再一次展現出了大語言模型的真正實力。
下面的音頻是一段20秒左右的鋼琴曲,先聽聽感受一下:
實際上只有前4秒是給到模型的提示,后面都是 AudioLM自己“補完”的。而且也只有這一段4秒的音頻樣本,沒有“鋼琴”、“進行曲”等之類的專業文字提示作為補充。
“你不需要給它提供整段樂曲來學習,只要給它一小段,他就能直接在音樂的空間里開始續寫——任何的音頻片段都可以,無論是音樂還是語音。”Eck 表示,這種無參考的音頻生成能力,早已超出了人們曾經對于 AI 創作能力的認知邊界。
| 其他 AIGC 技術、產品
除了上述新技術之外,谷歌還宣布了在其他內容格式上的 AI 內容生成技術。
比如,在二維的圖片/視頻基礎上,谷歌還讓文字轉 3D 模型成為了現實。通過結合 Imagen 和最新的神經輻射場 (Neural Radiance Field) 技術,谷歌開發出了DreamFusion 技術可以根據現有的文字描述,生成在具有高保真外觀、深度和法向量的 3D 模型,支持在不同光照條件下進行渲染。

圖片來源:DreamFusion: Text-to-3D using 2D Diffusion (dreamfusion3d.github.io)
以及,谷歌在今年 I/O 大會上面向公眾推出的嘗鮮應用 AI Test Kitchen,也將在近期更新加入 LaMDA 模型創新所解鎖的新功能。比如“城市夢想家” (City Dreamer) 來用文字命令建造主體城市,或者“Wobble”來創造會扭動的卡通形象等。
用戶可以在對應系統的應用商城中下載 AI Test Kitchen,并且前往谷歌網站申請測試資格,實測審批速度挺快。

AI Test Kitchen 支持 IOS 和 Android 系統 圖片來源:谷歌、蘋果
“我們在神經網絡架構、機器學習算法和應用于機器學習的硬件新方法方面取得的進展,幫助 AI 為數十億人解決了重要的現實問題,”Jeff Dean 表示。
“更多的進展即將到來。我們今天分享的是對未來充滿希望的愿景:AI 正讓我們重新想象技術如何能夠帶來幫助。”





