
有很長一段時間,AI(人工智能)這個詞變得沒那么讓人興奮了。
人們已經躲不開它,但同時也發覺,無論是AI的技術演進還是商業應用,似乎都遇到了瓶頸。人們有很多年沒再體驗到AlphaGo那樣的驚艷,業界也沒再經歷像語音助手普及那樣的商業機會,甚至許多投資人也只是在實在沒什么新鮮故事時,才不情愿的又轉身回頭看起了AI的機會。
不過,就在這個全人類都忙著卷來卷去的2022,AI卻正在經歷一次近年來最大的一次進化。
AI突然翻紅
就在10月18號,因為推出 Stable Diffusion 文本-圖像AI生成模型而大火的人工智能公司 StabilityAI 宣布完成1.01億美元的種子輪融資,讓整個公司估值達到10億美金,成為所謂“獨角獸”企業。這距離 StabilityAI 成立僅有兩年時間。
圖源:StabilityAI 官網

即便以科技互聯網產業發展的標準看,StabilityAI 的成長速度也是驚人的,這種速度是2022年以來全球AI產業爆發式增長的一個縮影,此刻距 StabilityAI 旗下的 Stable Diffusion 開源模型風靡全球尚不足2個月。
這種疾風驟雨的突飛猛進堪稱一場真正的革命,尤其在全球經濟預期轉弱的大背景下。
同所有的革命一樣,這場AI革命也不是一夜之間完成的。
一直以來人們都有一個夢想,即借助人工智能AI技術來拓展現有人類智慧、知識和創造力的邊界,但人腦復雜結構帶來的學習能力遠超人類構建AI的能力,于是AI只能通過各種特定深度學習模型來單點突破某些特定領域,比如 alphaGO 用來學習圍棋,又比如通過天文大數據幫助尋找脈沖星候選體。
而AIGC,即基于AI能力的內容創作(包括文字、圖片和視頻等等)也是其中一個重要類別,2022年之前,囿于核心技術的局限性,這個領域一直不溫不火,因為AI并沒有點石成金的法術,它不具備人類憑空創造的能力。AI的“深度學習”訓練并不是擁有自我意識的自主學習,是通過收集大量樣本讓AI從海量數據中總結規律,再根據人類的指令,基于規律進行內容再生產的過程,它同時受核心算法、硬件條件、數據庫樣本等多方面的限制。
一幅2018年時由神經網絡生成的作品,研究員 Robbie Barrat 用大量裸體繪畫(主要是女性)訓練而成。 圖源:https://www.fastcompany.com/90165906/this-ai-dreams-in-nude-portraits-and-landscape-paintings
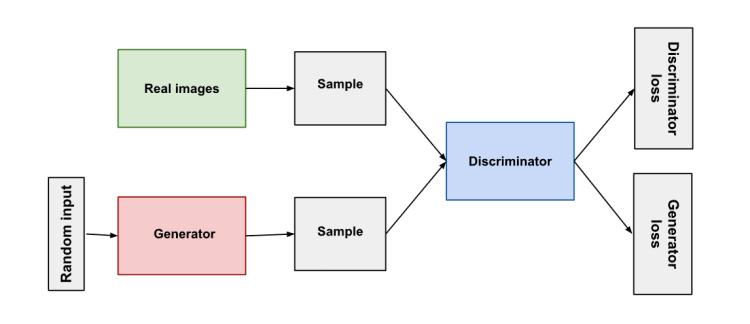
在2022年之前,AIGC領域使用最多的算法模型名為對抗生成網絡 GAN (Generative adversarial.NETworks),顧名思義就是讓AI內部的兩個程序互相對比,從而生成最接近人類心目中的正確形象。但這個算法有一個嚴重問題,由于程序互相對比的標準是現成的樣本,因此生成的內容實質上是對現有內容無限逼近的模仿,而模仿,意味著它無法真正突破。
圖源:https://developers.google.com/machine-learning/gan/gan_structure
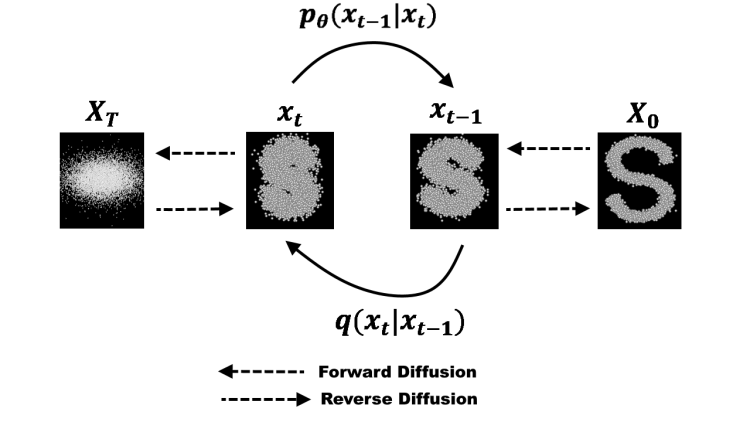
GAN的缺點被最終被 diffusion 擴散化模型克服,它正是今年以來陸續涌現的包括 Stable Diffusion 開源模型在內的諸多 AIGC 圖片生成模型的技術核心。
diffusion 擴散化模型的原理類似給照片去噪點,通過學習給一張圖片去噪的過程來理解有意義的圖像是如何生成,因此diffusion 模型生成的圖片相比 GAN 模型精度更高,更符合人類視覺和審美邏輯,同時隨著樣本數量和深度學習時長的累積,diffusion 模型展現出對藝術表達風格較好的模仿能力。
圖源:https://towardsdatascience.com/diffusion-models-made-easy-8414298ce4da
從今年初引起廣泛關注的 Disco Diffusion ,再到 DALL-E2、MidJourney 等模型都是基于Diffusion模型,而拿到融資的 Stable Diffusion 是其中最受歡迎的。由于 StabilityAI 對科技社區氛圍的擁護和對技術中立原則的認同,Stable Diffusion 主動開放了自己的源代碼,不僅方便人們部署在本地使用(普通消費級顯卡既能滿足 Stable Diffusion 的硬件要求),還帶來了魔術般的用戶體驗:打開網址,輸入你想要畫面的關鍵字,等待幾分鐘,模型就會生成完成度非常高的圖片作品。普通人使用最尖端AI技術的門檻因此被降到最低,上線以來,僅通過官方平臺 DreamStudio 制作的生成圖片就超過1.7萬億張。
圖源:由Stable Diffusion 生成的圖片。 圖源:StabilityAI 官網

AIGC沉寂許久的革命火種,瞬間燎原。
絢爛的藍海
以 StabilityAI 為代表的的AIGC圖片生成模型在如此短的時間內發展到極為成熟的地步,預示著它從比較傳統的設計繪圖、插畫、游戲視覺,電子商務等領域到大熱的元宇宙和虛擬現實技術都擁有巨大的發展潛力。
圖源:輸入 AI wins 后 DreamStudio 基于 Stable Diffusion 生成的圖像

想象一下,在未來的VR/AR虛擬世界里,你腦海中想到的畫面可以借助ai生成技術實時渲染出來,這將會對人們娛樂和獲取信息的方式產生怎樣的顛覆?
但這不是市場在如今經濟大環境極為低迷之際為AI投下贊成票的全部原因,廣泛的商業潛力固然吸引人,但更值得投入的是AI技術本身。這場革命還未完結,它的下一篇章已經向人們走來。
那就是生成視頻。
從本質上講,視頻是連續的靜態圖像,隨著 ai 圖片生成技術的日益成熟,許多人都把目光投向生成視頻領域,9月以來,Meta 和 Google 先后公布了自己在這一 AIGC 最前沿領域的最新成果。
Meta 的模型名為Make-A-Video,通過學習大量文本-圖像組合樣本數據和無文本標記的視頻來理解真實世界中物體的運動邏輯,Make-A-Video能夠初步在構建圖像的基礎上讓圖像動起來,同時擁有理解三維物體立體結構的能力。
圖源:Meta 公布的相關論文https://arxiv.org/pdf/2209.14792.pdf
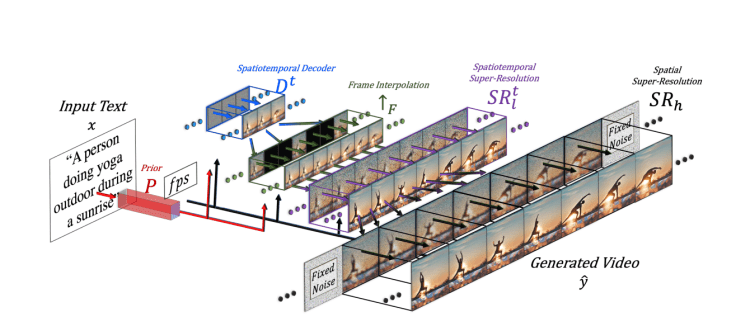
名為 imagen video 的模型則通過被稱為聯級擴散系列模型的方法生成視頻。也就是先通過基礎擴散模型生成分辨率較小的視頻,然后再通過一系列時間、空間超分辨率模型提升視頻的分辨率和幀數。
圖源:imagen video 官網
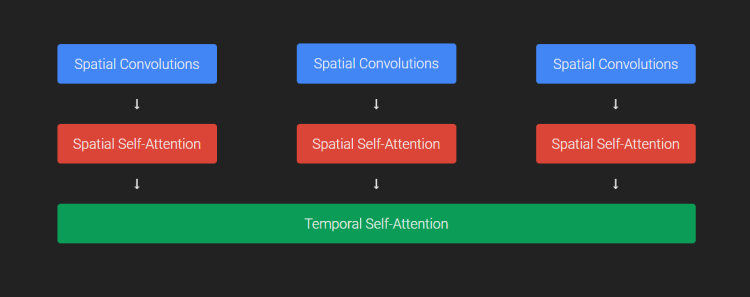
橫向比較來看,imagen 的視頻分辨率(1280X768 )高于Make-A-Video,時長也略長一些。
圖源:Google 公布的相關論文 https://imagen.research.google/video/paper.pdf

但突破還不止于此,另一個名為 Phenaki 的AI視頻生成模型(也來自Google團隊)公布了其能夠根據文本內容生成可變時長視頻的技術,也就是說 Phenaki 有從文本中提煉理解故事情節并將其轉化為視頻的能力。
公布的demo中,Phenaki 基于幾百個單詞組成的一連串有前后邏輯關系的文本指令生成了一段2分多鐘的連貫視頻,這種充滿鏡頭感、豐富情節和轉場的故事片雛形假以時日勢必對未來整個視頻行業,包括短視頻、電視電影等產生廣泛沖擊。
生成視頻模型尚在起步階段,在具體運動的細節、畫面精細度、不同物體和人的互動等方面尚顯稚嫩,從分辨率到畫質上也有濃濃的“人工智能”痕跡,然而回想AI圖片生成模型同樣經歷了從全網群嘲到逆襲的過程,后之視今亦猶今之視昔,誰又能說這未嘗不是AIGC革命下一個高潮即將來臨的預言?
圖源:Midjourney 根據指令 AI wins 生成的圖片

劇變帶來的爭議
劇烈的變化總是伴隨著爭議,以 Stable Diffusion 為代表的AIGC革命“圖像階段”也是如此,我們試著將其歸納為下面幾個問題并做出初步回答。
(1)AI生成內容的版權問題該如何界定?
中國的著作權法中規定只有自然人或組織可以被認定為作者,因此ai生成內容并沒有享有著作權的實體。如果沒有更多協定約束,AI生成內容可以被任意使用,包括商業使用在內。Midjourney、Dell-e等都明確表示用戶擁有自己生成作品的所有權。
圖源:StabilityAI 官網關于版權問題的回應

圖源:StabilityAI 官網關于版權問題的回應

值得一提的是,很多AI生成技術深度學習訓練所使用的數據庫中可能包含了侵權內容,但因此導致用戶生成內容侵權的可能性非常低,因為生成內容本身是充滿高度隨機和不確定性的,即使陷入版權爭議,舉證過程也會極為困難。
(2)AI生成內容是否具有藝術性?如果有,該如何評價與界定?
AI生成內容的藝術性在半年之前還是個看著有些無聊的問題,但在《歌劇院空間》作品獲獎后,人們開始越來越多的談論它。
圖源:紐約時報 https://www.nytimes.com/2022/09/02/technology/ai-artificial-intelligence-artists.html

總的來說,AI生成的內容并不是自己創造的,它受自身模型算法和數據庫樣本容量影響,這也是許多人聲稱ai生成內容“沒有靈魂”的原因。
然而僅僅把AI生成技術看做純粹的工具也是不公平的,因為它不僅可以模仿,而且算法和樣本一同提供了現有人類所不能完全提供的創作視角。
圖源:由Stable Diffusion 生成的圖片。 圖源:StabilityAI 官網

現有的AI生成圖像技術已經讓人們參與圖像創作的門檻變得無限低,因此對生成作品的藝術性鑒賞或許應該從更細分的角度入手,正如 NFT 之于傳統藝術品一樣,它的價值需要經過市場的檢驗,而藝術品市場對此正處于理解和接受的初級階段。
(3)AIGC革命的“圖像階段”對圖像工作者和藝術創作者來說意味著什么?
隨著AI生成技術“民主化”,未來中低端繪畫內容和它的市場會被AI代替,這意味著大批腰部及以下的圖像工作者、插畫師、設計師等會失去現有工作。
隨著AI生成圖像內容越來越豐富和逼真,它們也正在根本上解構著商業圖片庫賴以生存的運營模式——如果圖片可以自己生成的話,誰還要花錢買圖呢?
圖源:gettyimages 關于AI生成內容的聲明
但AI生成技術同樣拓展了人們對繪畫工具能力的理解。對藝術創作者來說,AI生成技術將有利于他們基于自身理念(而不是技法)創造更多維度,更具創造性的作品。
未來將會是創作者創造力的比拼,因為AI“消除了外行表達創造力的障礙。”(比約恩·奧姆所說,他的團隊開發出了 Stable Diffusion 最初的基礎算法。)
圖源:由Stable Diffusion 生成的圖片。 圖源:StabilityAI 官網

(4)AI生成內容應該如何監管,如何防止虛假信息和不適宜信息的傳播?
秉持技術中立態度的研究者例如 StabilityAI 會盡量減少對內容的控制和干預。他們認為一個開放和充分討論的社區將會逐步形成對信息內容傳播的監督機制。
“使用者自己需要為如何使用這項技術負責,這包括道德和法律上的合規性。”Stability AI 公司 CEO Emad Mostaque 曾在采訪中如此表示。
圖源:由Stable Diffusion 生成的圖片。 圖源:StabilityAI 官網

與此同時,盡管深度學習所用到的數據庫經過了嚴格的篩選,屏蔽了色情、暴力、恐怖等內容,但有關社會刻板偏見、種族歧視等內容尚無法從技術上完全消除,更重要的是,關于如何界定所謂偏見在倫理學上仍然是一個頗受爭議的問題。正因如此,Google 決定在排除相關風險前推遲公開發布 imagen video 模型,而許多已發布的模型選擇為其生成作品加上不可去掉的水印來避免潛在爭議。
AIGC革命如火如荼進行中,它不是將來時,而是進行時。我們已經身處其中。
現在就是未來。





