
作者:rangobai,騰訊CSIG數據工程師
| 導語要有性能意識,量變引起質變,簡單如一行日志都會在高并發的情況引發血案,考驗著研發的技術功底
一 案件背景
9月的某個上午,業務側突然反饋線上數據服務響應慢,造成任務積壓,正常情況下耗時5ms的服務,單次響應達到了5s量級. 收到反饋后我們馬上開始排查服務狀況,但發現各項指標很健康,接口平均耗時3ms,p99約為1s,和經驗值比無太大差別. 業務側隨后補充反饋是某些請求很慢,感覺是若干pod有問題,當流量打到這幾臺機器時就會變慢.
開始懷疑是網絡問題,但沒有證據.隨后小庫網關的一臺機器突然宕機,這個現象引起了我們注意.在上次迭代中,我們服務有一次重大升級,所有請求均會經過網關服務轉發,以實現Server/DB單元化綁定,問題可能出在轉發環節.
為了驗證猜想,我們重啟了網關,隨后業務側積壓現象迅速消失,排查范圍鎖定網關服務.
二 調查過程
小庫網關本身無太多業務邏輯,依賴項非常少,為了實現時間最小損耗,技術框架采用spring cloud gateway,底層WebFlux 則使用了高性能的 Reactor 模式.在上線前的多次壓測中,網關服務表現非常優秀,時間損耗基本在毫秒級別.萬萬沒想到上線沒幾天就挖了個大坑,必須要刨根問底調查清楚
2.1 第一次定位
由于剛遷移到新私密機房,可用于問題還原的監控手段不多,剛開始只能從查看pod云監控以及日志著手.
首先查看日志異常 :可以看到確實有大量PT5S超時存在,但是根據traceId追蹤大多數超時請求在服務側均為毫秒級響應.
其次查看業務側請求量變化:雖然我們服務有過qps破萬的表現,但是問題時間段請求量異常的平穩,甚至略有降低.
最后查看問題時間段性能表現:cpu在40%左右,無突增現象.Pod內存監控由于JVM提前分配,無太大參考價值.I/O流量在問題時間段沒有波動.
磁盤滿了
此時沒有清晰的調查方向,就在我們黔驢技窮的時候,又一臺網關pod重啟了,我們同學迅速登錄機器,查看案發現場-磁盤爆滿, 200G的云硬盤在上線的兩天內就被打滿,請求block.線上請求量其實大大超出我們的預估,生產日志量接近10G/小時/臺, 日志保留7天的策略頓時顯得不合時宜.
隨后我們清理了所有pod的日志,并采取了兩個策略:
- 日志清理策略設為保留1天,因為有日志本身上報cls,保留太久日志沒有必要
- 清理無效日志,打印要有技巧性,不是越多越好,高并發下對服務傷害性越大.
修改上線后,服務運行平穩,再也沒出現上午的問題,調查小組愉快的度過了第一天.
2.2 第二次定位
就在以為我們萬事大吉的時候,現實光速打臉,第二天早上8點半,生命線里出現大量異常警告,隨后網關服務陸續重啟,登錄機器,磁盤利用率10%,尷了個尬.
CPU問題三板斧
因為自動重啟沒有保留案發現場,所以只能在昨天的基礎上繼續調查.
第一個合理懷疑的方向是CPU,雖然CPU利用率40%不能算很高, 但網關和業務機器比達到了1:2,對于僅轉發請求的網關來說仍然是不正常的高了.排查此類問題就要啟動CPU問題三板斧了
第一板斧: jps查看JAVA進程ID 46
第二板斧: top -Hp 46 查看進程所有線程的活動
可以看出仍然是log4j2的101線程占用了最多的CPU能力,
最后一板斧: jstack pid 查看線程活動,以定位線程堆棧
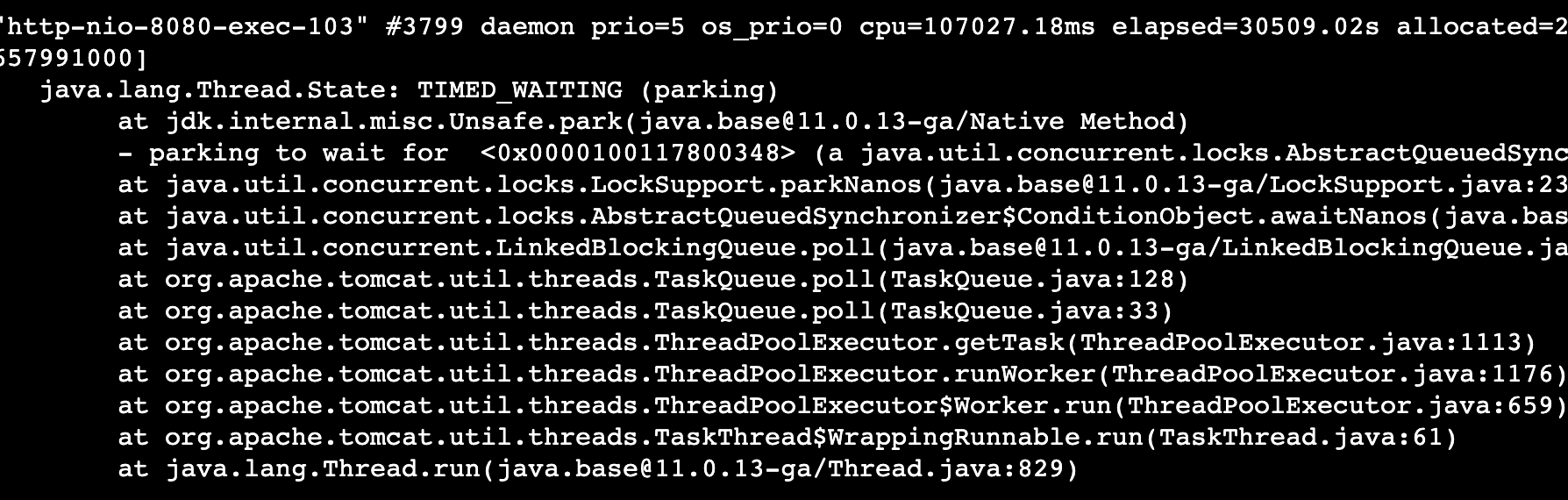
這個時候,日志打印占用了最多cpu已經一目了然.
最大利器Arthas
但是作為成熟的研發,我們當然不滿足于三板斧調查問題,這時候就要請出線上另一大殺器arthas :profiler | arthas,以下介紹來自官網:
Arthas 是一款線上監控診斷產品,通過全局視角實時查看應用 load、內存、gc、線程的狀態信息,并能在不修改應用代碼的情況下,對業務問題進行診斷,包括查看方法調用的出入參、異常,監測方法執行耗時,類加載信息等,大大提升線上問題排查效率Arthas(阿爾薩斯)能為你做什么?這個類從哪個 jar 包加載的?為什么會報各種類相關的 Exception?我改的代碼為什么沒有執行到?難道是我沒 commit?分支搞錯了?遇到問題無法在線上 debug,難道只能通過加日志再重新發布嗎?線上遇到某個用戶的數據處理有問題,但線上同樣無法 debug,線下無法重現!是否有一個全局視角來查看系統的運行狀況?有什么辦法可以監控到 JVM 的實時運行狀態?怎么快速定位應用的熱點,生成火焰圖?怎樣直接從 JVM 內查找某個類的實例?
不得不說,阿里在java技術積淀遠超我司.因為之前已在鏡像里面集成了阿爾薩斯,我們立即啟動cpu profiler采樣生成火焰圖.

果然除了日志打印以外,我們又發現了一處CPU熱點

這兩個地方合計占掉了60%以上的性能.
CPU高的原因
首先分析一下日志占用過高,這是一個使用log4j2的問題,涉及日志打印參數調優,我們之前已經優化過一輪的參數
#RingBuffer大小 AsyncLogger.RingBufferSize=524288#日志等待策略sleepAsyncLogger.WaitStrategy=SLEEP#Ringbuffer滿了后直接丟棄log4j2.AsyncQueueFullPolicy=Discard
理論上這已經是性能最好的日志策略,為什么會出現占用CPU負載的問題?
問題出在LockSupport.parkNanos上,簡單來說當日志消費速度趕不上生產速度的時候,日志線程會調用這個方法自旋等待若干納秒,在線程數少的時候性能影響不明顯,但是在高并發的情況下會造成大量線程在短時間內頻繁喚醒/等待,從而影響業務性能.解決方案:是把自旋的時間間隔調大,如下
AsyncLogger.RingBufferSize=524288AsyncLogger.WaitStrategy=SLEEPlog4j2.AsyncQueueFullPolicy=DiscardAsyncLogger.SleepTimeNs=500
分析下第二個CPU熱點,這個問題沒那么復雜

是一個對象深拷貝的性能問題,每次請求來的時候都會將一個大對象先序列化在反序列化,這個在請求量低的時候影響較小,但是在我們每天幾千萬的請求量沖擊下,性能瓶頸非常明顯.
講一下對象拷貝的四種解決方案:
JSON : 非常規,吃CPU
Apache BeanUtils :性能最差,不建議使用
Spring BeanUtils: 性能稍好
MapStruct MapStruct – Java bean mAppings, the easy way!,性能無損,推薦!!
具體各自的拷貝原理不再深入分析,大家可以搜資料查看
熱點問題解決了
給一下優化前后的CPU對比,以下優化結果是在請求量翻倍同時pod數減半的CPU表現:
優化前: 45%+
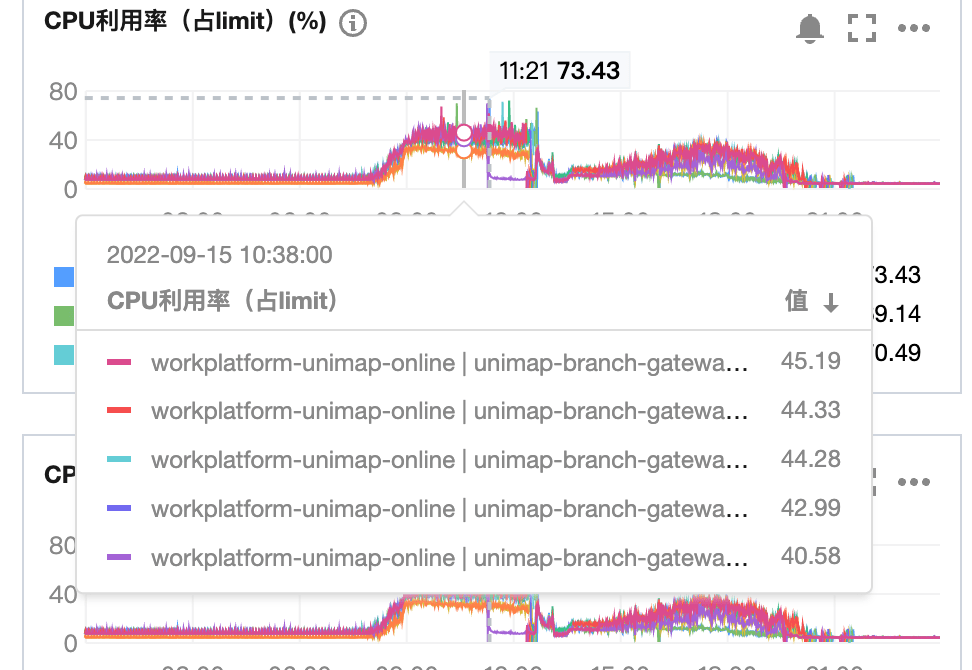
優化后: 11%

2.3 最終定位
隨著一步步的分析,我們也越來越接近問題的真相: CPU雖然有點高,但仍不足以解釋緩慢和重啟的現象,另外問題是在線上請求量增大以及隨時間推移逐漸暴漏的,幾乎可以斷定網關存在內存泄漏.于是我們把調查重點投向JVM內存,布下天羅地網,靜等兇手再次犯案.
功夫不負有心人,在部署約一天后,幾臺服務器又開始重啟,我們迅速登錄還未重啟的機器,執行以下操作
- 首先查看jvm內存已經逼近100%
- GC非常活躍且無效,大量的內存無法回收
- 通過火焰圖查看的CPU絕大部分在執行GC
- jmap -dump:format=b,file=heapdump.phrof pid 生成內存dump并上傳cos
這個時候就要請出排查內存問題的另一大殺器Jprofile,具體資料可以在網上搜,這里主要介紹定位過程.
首先查看內存分布,有1000W+的ImmutableTag,不是我們的業務對象...非常意外
其次查看大對象,SimpleMeterRegistry占用了80%的內存空間!!!
這兩個類均屬于io.micrometer的核心組件,用來暴漏服務參數供監控使用.Micrometer中包含的SimpleMeterRegistry,它在內存中維護每個meter的最新值.
再一次分析內存中保留的對象內容
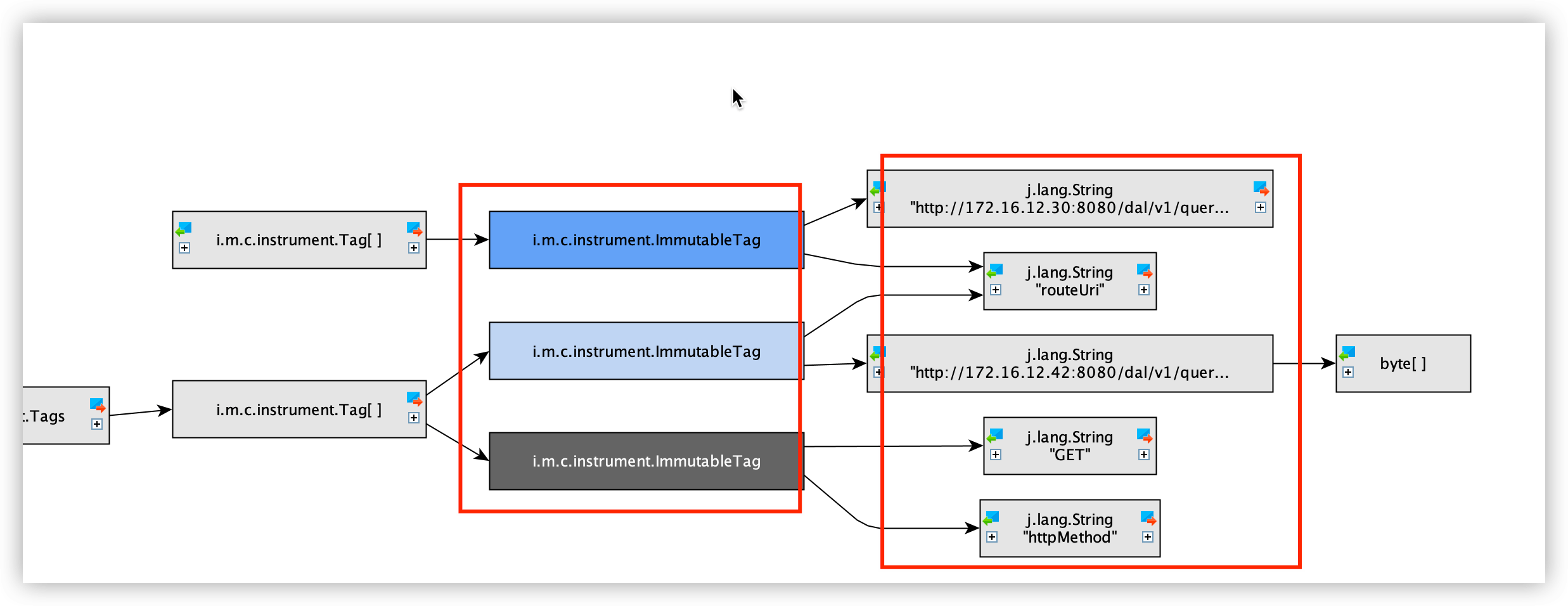
可以看出1000W+的對象中,全部記錄的是我們每次請求的RouteUri Method 耗時等信息,通過關鍵字定位,這些對象生產的源頭是GateWay的 GatewayMetricsFilter組件,這里會記錄所有路由請求的信息apply到micrometer中.而這個GatewayMetricsFilter的啟用條件是存在Spring Boot Actuator組件.我們業務中剛好引用了該組件.
至此兇手歸案,我們下線Actuator,并手動將GatewayMetricsFilter啟動設置為False后,問題徹底解決.
三 內存泄漏原因
但是為什么呢?一個Spring官方提供的監控組件會導致內存泄漏?為什么對象持續無法回收?直覺告訴我們一定是哪個地方不太對勁.珍貴的食材往往需要最簡單的烹飪方式,最復雜的場景往往用最樸素的手段抽絲剝繭
3.1 DEBUG過程
幸好我們有一套完整可用的開發環境,足夠做場景復現,打好斷點觸發請求.經過幾輪分析,犯案原因也隨之浮出水面.
首先還是從SimpleMeterRegistry的引用鏈開始,(過程比較無聊,不再贅述)
這里存在一條清晰的引用關系,查看MeterRegistry源碼,有一個ConcurrentHashMap全局變量
就是這個全局的Hashmap保存了到ImmutableTag的引用關系,導致GC Roots判定引用路徑存在,對象存活無法回收.關鍵代碼:
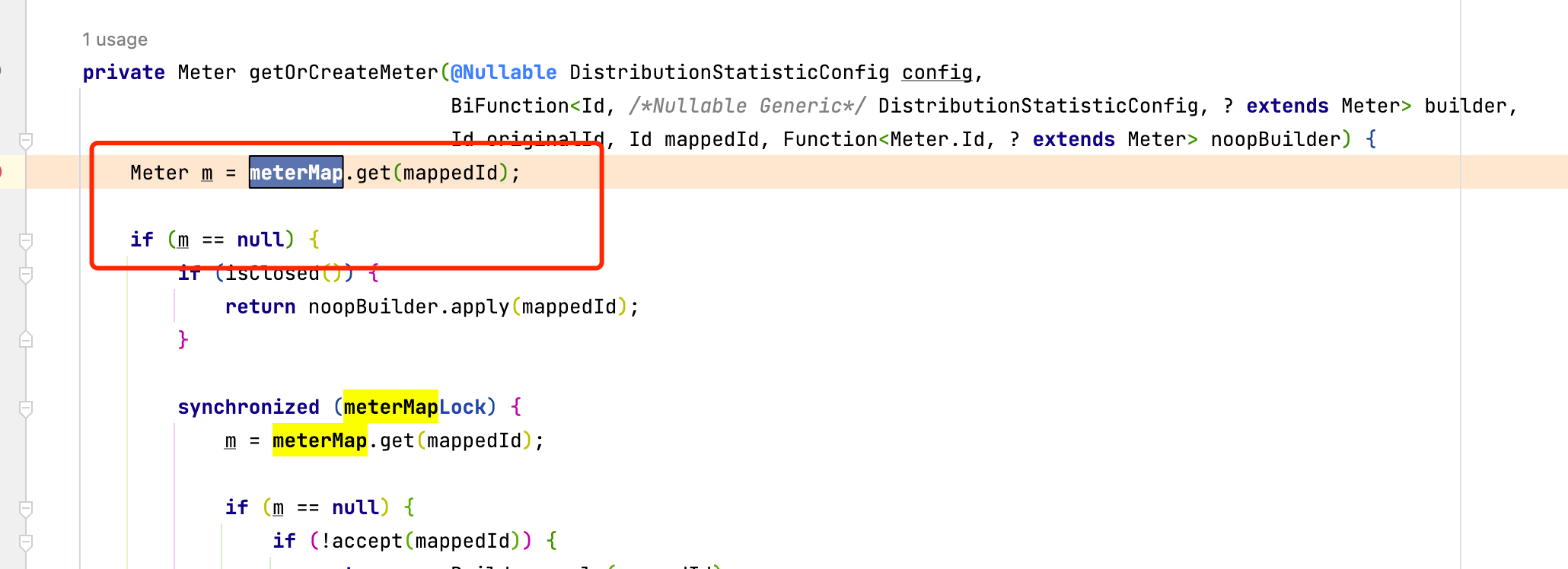
這里判定如果meterMap中不存在mappedId就創建,mappedId是一個DefaultMeter對象,針對我們的業務場景,這個Meter根據Route對象生成.看一下我們的使用方法,為了做到動態路由效果,我們使用了一個全局的filter攔截請求,然后根據算法確定需要轉發的目標IP,每次請求都會生成一個新的Route對象

3.2 水落石出
壞就壞在這個newRoute上,因為每次請求的參數不一樣,導致我們生成的Route對象也不一樣.我們認為Route是請求級別的動態的,每次請求后自然消亡,實際上也是如此.但是萬萬沒想到,站在SpringCloud GateWay或者說站在GatewayMetricsFilter的視角,這個Route是全局的靜態,由此引發內存泄漏.
四 經驗總結
第一, 要有性能意識,量變引起質變,簡單如一行日志都會在高并發的情況引發一起血案,考驗著研發的技術功底.
第二,工欲善其事,必先利其器,一款好的工具能夠極大提升研發生產力





