擊這里在線咨詢客服")

來源丨網(wǎng)絡(luò)
AutoML是指自動(dòng)機(jī)器學(xué)習(xí)。它說明了如何在組織和教育水平上自動(dòng)化機(jī)器學(xué)習(xí)的端到端過程。機(jī)器學(xué)習(xí)模型基本上包括以下步驟:
-
數(shù)據(jù)讀取和合并,使其可供使用。
-
數(shù)據(jù)預(yù)處理是指數(shù)據(jù)清理和數(shù)據(jù)整理。
-
優(yōu)化功能和模型選擇過程的位置。
-
將其應(yīng)用于應(yīng)用程序以預(yù)測(cè)準(zhǔn)確的值。
最初,所有這些步驟都是手動(dòng)完成的。但是現(xiàn)在隨著AutoML的出現(xiàn),這些步驟可以實(shí)現(xiàn)自動(dòng)化。AutoML當(dāng)前分為三類:
-
用于自動(dòng)參數(shù)調(diào)整的AutoML(相對(duì)基本的類型)
-
用于非深度學(xué)習(xí)的AutoML,例如AutoSKlearn。此類型主要應(yīng)用于數(shù)據(jù)預(yù)處理,自動(dòng)特征分析,自動(dòng)特征檢測(cè),自動(dòng)特征選擇和自動(dòng)模型選擇。
-
用于深度學(xué)習(xí)/神經(jīng)網(wǎng)絡(luò)的AutoML,包括NAS和ENAS以及用于框架的Auto-Keras。
機(jī)器學(xué)習(xí)的需求日益增長(zhǎng)。組織已經(jīng)在應(yīng)用程序級(jí)別采用了機(jī)器學(xué)習(xí)。仍在進(jìn)行許多改進(jìn),并且仍然有許多公司正在努力為機(jī)器學(xué)習(xí)模型的部署提供更好的解決方案。
為了進(jìn)行部署,企業(yè)需要有一個(gè)經(jīng)驗(yàn)豐富的數(shù)據(jù)科學(xué)家團(tuán)隊(duì),他們期望高薪。即使企業(yè)確實(shí)擁有優(yōu)秀的團(tuán)隊(duì),通常也需要更多的經(jīng)驗(yàn)而不是AI知識(shí)來決定哪種模型最適合企業(yè)。機(jī)器學(xué)習(xí)在各種應(yīng)用中的成功導(dǎo)致對(duì)機(jī)器學(xué)習(xí)系統(tǒng)的需求越來越高。即使對(duì)于非專家也應(yīng)該易于使用。AutoML傾向于在ML管道中自動(dòng)執(zhí)行盡可能多的步驟,并以最少的人力保持良好的模型性能。
AutoML具有三個(gè)主要優(yōu)點(diǎn):
-
它通過自動(dòng)化最重復(fù)的任務(wù)來提高效率。這使數(shù)據(jù)科學(xué)家可以將更多的時(shí)間投入到問題上,而不是模型上。
-
自動(dòng)化的ML管道還有助于避免由手工作業(yè)引起的潛在錯(cuò)誤。
-
AutoML是朝著機(jī)器學(xué)習(xí)民主化邁出的一大步,它使每個(gè)人都可以使用ML功能。
讓我們看看以不同的編程語言提供的一些最常見的AutoML庫:
以下是用Python/ target=_blank class=infotextkey>Python實(shí)現(xiàn)auto-sklearn
auto-sklearn是一種自動(dòng)機(jī)器學(xué)習(xí)工具包,是scikit-learn估計(jì)器的直接替代品。Auto-SKLearn將機(jī)器學(xué)習(xí)用戶從算法選擇和超參數(shù)調(diào)整中解放出來。它包括功能設(shè)計(jì)方法,例如一站式,數(shù)字功能標(biāo)準(zhǔn)化和PCA。該模型使用SKLearn估計(jì)器來處理分類和回歸問題。Auto-SKLearn創(chuàng)建管道并使用貝葉斯搜索來優(yōu)化該渠道。在ML框架中,通過貝葉斯推理為超參數(shù)調(diào)整添加了兩個(gè)組件:元學(xué)習(xí)用于使用貝葉斯初始化優(yōu)化器,并在優(yōu)化過程中評(píng)估配置的自動(dòng)集合構(gòu)造。
Auto-SKLearn在中小型數(shù)據(jù)集上表現(xiàn)良好,但無法生成在大型數(shù)據(jù)集中具有最先進(jìn)性能的現(xiàn)代深度學(xué)習(xí)系統(tǒng)。
詳細(xì)原理與案例請(qǐng)見 (點(diǎn)擊查看):一文徹底搞懂自動(dòng)機(jī)器學(xué)習(xí)AutoML:Auto-Sklearn
例importsklearn.model_selection
importsklearn.datasets
importsklearn.metrics
importautosklearn.regression
defmain:
X, y = sklearn.datasets.load_boston(return_X_y= True)
feature_types = ([ 'numerical'] * 3) + [ 'categorical'] + ([ 'numerical'] * 9)
X_train, X_test, y_train, y_test =
sklearn.model_selection.train_test_split(X, y, random_state= 1)
automl = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task= 120,
per_run_time_limit= 30,
tmp_folder= '/tmp/autosklearn_regression_example_tmp',
output_folder= '/tmp/autosklearn_regression_example_out',
)
automl.fit(X_train, y_train, dataset_name= 'boston',
feat_type=feature_types)
print(automl.show_models)
predictions = automl.predict(X_test)
print( "R2 score:", sklearn.metrics.r2_score(y_test, predictions))
if__name__ == '__main__':
main
FeatureTools
它是用于自動(dòng)功能工程的python庫。
安裝
用pip安裝
python -m pip install featuretools
或通過conda上的Conda-forge頻道:
conda install -c conda-forge featuretools
附加組件
我們可以運(yùn)行以下命令單獨(dú)安裝或全部安裝附件
python -m pip install featuretools[complete]
更新檢查器—接收有關(guān)FeatureTools新版本的自動(dòng)通知
python -m pip install featuretools[update_checker]
TSFresh基本體-在Featuretools中使用tsfresh中的60多個(gè)基本體
python -m pip install featuretools[tsfresh]
例importfeaturetools asft
es = ft.demo.load_mock_customer(return_entityset= True)
es.plot
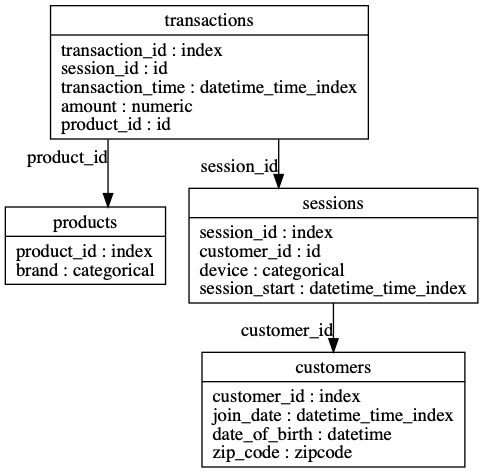
Featuretools可以為任何"目標(biāo)實(shí)體"自動(dòng)創(chuàng)建一個(gè)特征表
feature_matrix, features_defs = ft.dfs(entityset=es,
target_entity= "customers")
feature_matrix.head( 5)
MLBox官方網(wǎng)站
https://featuretools.alteryx.com/cn/stable/
MLBox是功能強(qiáng)大的自動(dòng)化機(jī)器學(xué)習(xí)python庫。 詳細(xì)原理與案例請(qǐng)見(點(diǎn)擊查看)一文徹底掌握自動(dòng)機(jī)器學(xué)習(xí)AutoML:MLBox
根據(jù)官方文檔,它具有以下功能:
-
快速讀取和分布式數(shù)據(jù)預(yù)處理/清理/格式化
-
高度強(qiáng)大的功能選擇和泄漏檢測(cè)以及精確的超參數(shù)優(yōu)化
-
最新的分類和回歸預(yù)測(cè)模型(深度學(xué)習(xí),堆疊,LightGBM等)
-
使用模型解釋進(jìn)行預(yù)測(cè),MLBox已在Kaggle上進(jìn)行了測(cè)試,并顯示出良好的性能。
-
管道
MLBox主軟件包包含3個(gè)子軟件包:
-
預(yù)處理:讀取和預(yù)處理數(shù)據(jù)
-
優(yōu)化:測(cè)試或優(yōu)化各種學(xué)習(xí)者
-
預(yù)測(cè):預(yù)測(cè)測(cè)試數(shù)據(jù)集上的目標(biāo)
TPOT官方網(wǎng)站
https://github.com/AxeldeRomblay/MLBox
TPOT代表基于樹的管道優(yōu)化工具,它使用遺傳算法優(yōu)化機(jī)器學(xué)習(xí)管道.TPOT建立在scikit-learn的基礎(chǔ)上,并使用自己的回歸器和分類器方法。TPOT探索了數(shù)千種可能的管道,并找到最適合數(shù)據(jù)的管道。
TPOT通過智能地探索成千上萬的可能管道來找到最適合我們數(shù)據(jù)的管道,從而使機(jī)器學(xué)習(xí)中最繁瑣的部分自動(dòng)化。
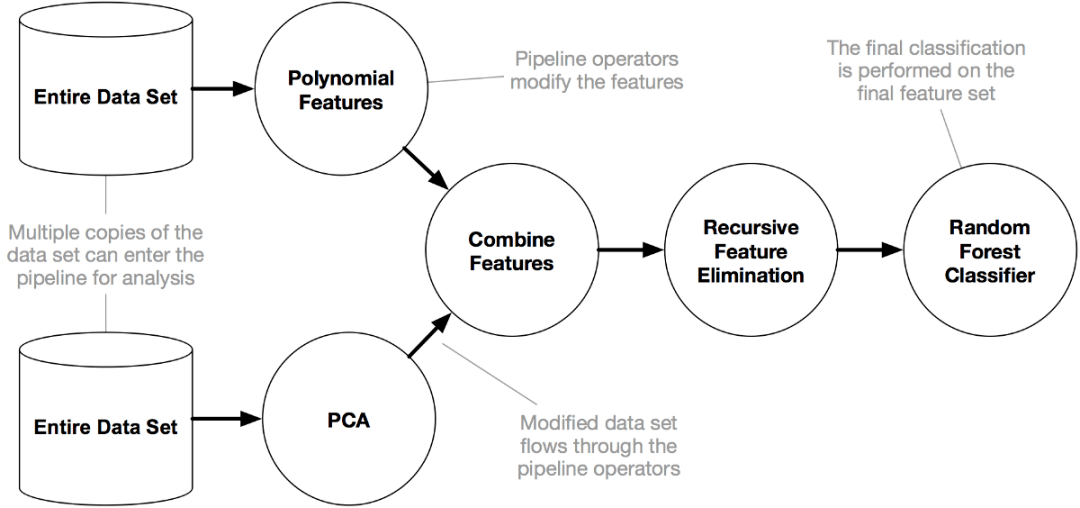
TPOT建立在scikit-learn的基礎(chǔ)上,因此它生成的所有代碼都應(yīng)該看起來很熟悉……無論如何,如果我們熟悉scikit-learn。 詳細(xì)原理與案例請(qǐng)見(點(diǎn)擊查看) 一文徹底搞懂自動(dòng)機(jī)器學(xué)習(xí)AutoML:TPOT
TPOT仍在積極開發(fā)中。
例子分類 fromtpot importTPOTClassifier
fromsklearn.datasets importload_digits
fromsklearn.model_selection importtrain_test_split
digits = load_digits
X_train, X_test, y_train, y_test = train_test_split(digits.data,
digits.target,
train_size= 0.75,
test_size= 0.25,
random_state= 42)
tpot = TPOTClassifier(generations= 5, population_size= 50,
verbosity= 2, random_state= 42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export( 'tpot_digits_pipeline.py')
此代碼將發(fā)現(xiàn)達(dá)到98%的測(cè)試精度的管道。應(yīng)將相應(yīng)的Python代碼導(dǎo)出到tpot_digits_pipeline.py文件,其外觀類似于以下內(nèi)容:
importnumpy asnp
importpandas aspd
fromsklearn.ensemble importRandomForestClassifier
fromsklearn.linear_model importLogisticRegression
fromsklearn.model_selection importtrain_test_split
fromsklearn.pipeline importmake_pipeline, make_union
fromsklearn.preprocessing importPolynomialFeatures
fromtpot.builtins importStackingEstimator
fromtpot.export_utils importset_param_recursive
# NOTE:Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv( 'PATH/TO/DATA/FILE', sep= 'COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop( 'target', axis= 1)
training_features, testing_features, training_target, testing_target =
train_test_split(features, tpot_data[ 'target'], random_state= 42)
# Average CV score on the training set was: 0.9799428471757372
exported_pipeline = make_pipeline(
PolynomialFeatures(degree= 2, include_bias= False, interaction_only= False),
StackingEstimator(estimator=LogisticRegression(C= 0.1, dual= False, penalty= "l1")),
RandomForestClassifier(bootstrap= True, criterion= 'entropy',
max_features= 0.35000000000000003,
min_samples_leaf= 20, min_samples_split= 19,
n_estimators= 100)
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
回歸
TPOT可以優(yōu)化管道以解決回歸問題。以下是使用波士頓房屋價(jià)格數(shù)據(jù)集的最小工作示例。
fromtpot importTPOTRegressor
fromsklearn.datasets importload_boston
fromsklearn.model_selection importtrain_test_split
housing = load_boston
X_train, X_test, y_train, y_test = train_test_split(
housing.data, housing.target,
train_size= 0.75, test_size= 0.25,
random_state= 42)
tpot = TPOTRegressor(generations= 5, population_size= 50,
verbosity= 2, random_state= 42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export( 'tpot_boston_pipeline.py')
這將導(dǎo)致流水線達(dá)到約12.77均方誤差(MSE),tpot_boston_pipeline.py中的Python代碼應(yīng)類似于:
importnumpy asnp
importpandas aspd
fromsklearn.ensemble importExtraTreesRegressor
fromsklearn.model_selection importtrain_test_split
fromsklearn.pipeline importmake_pipeline
fromsklearn.preprocessing importPolynomialFeatures
fromtpot.export_utils importset_param_recursive
# NOTE:Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv( 'PATH/TO/DATA/FILE',
sep= 'COLUMN_SEPARATOR',
dtype=np.float64)
features = tpot_data.drop( 'target', axis= 1)
training_features, testing_features, training_target, testing_target =
train_test_split(features, tpot_data[ 'target'], random_state= 42)
# Average CV score on the training set was: -10.812040755234403
exported_pipeline = make_pipeline(
PolynomialFeatures(degree= 2, include_bias= False, interaction_only= False),
ExtraTreesRegressor(bootstrap= False, max_features= 0.5,
min_samples_leaf= 2, min_samples_split= 3,
n_estimators= 100)
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
LightwoodGithub鏈接
https://github.com/EpistasisLab/tpot

一個(gè)基于Pytorch的框架,它將機(jī)器學(xué)習(xí)問題分解為較小的塊,可以與一個(gè)目標(biāo)無縫地粘合在一起:讓它變得如此簡(jiǎn)單,以至于您只需要一行代碼就可以構(gòu)建預(yù)測(cè)模型。
安裝
我們可以從pip安裝Lightwood:
pip3 install lightwood
注意:根據(jù)我們的環(huán)境,在上面的命令中我們可能必須使用pip而不是pip3。
鑒于簡(jiǎn)單的sensor_data.csv,我們可以預(yù)測(cè)sensor3的值。
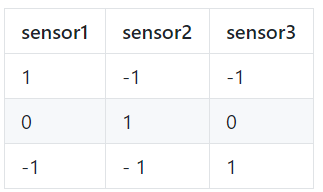
從Lightwood導(dǎo)入預(yù)測(cè)變量
fromlightwood importPredictor
訓(xùn)練模型。
importpanda
ssensor3_predictor = Predictor(output=[ 'sensor3']
).learn(from_data=pandas.read_csv( 'sensor_data.csv'))
現(xiàn)在我們可以預(yù)測(cè)sensor3的值。
prediction = sensor3_predictor.predict(when={ 'sensor1': 1, 'sensor2': -1})
MindsDB官方鏈接
https://github.com/mindsdb/lightwood
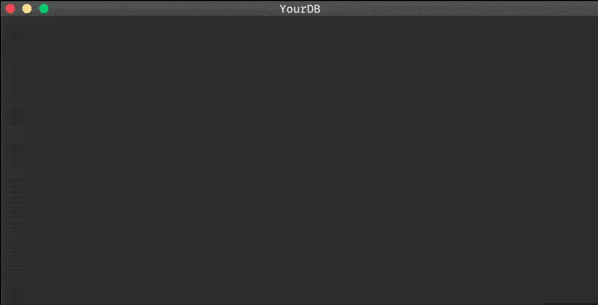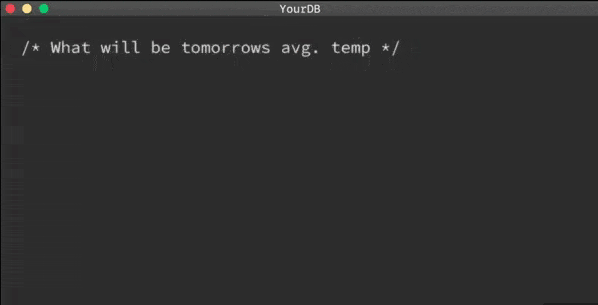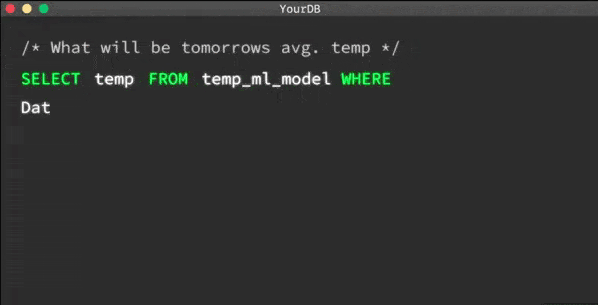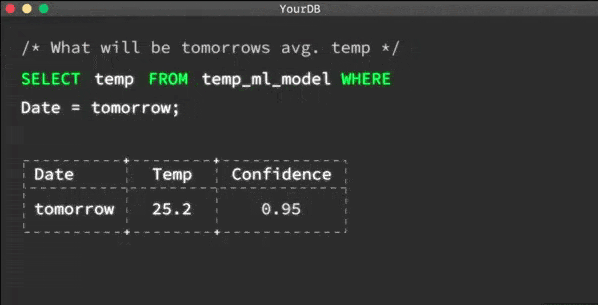
MindsDB是現(xiàn)有數(shù)據(jù)庫的開源AI層,可讓您輕松使用SQL查詢來開發(fā),訓(xùn)練和部署最新的機(jī)器學(xué)習(xí)模型。
官方鏈接
https://github.com/mindsdb/mindsdb
mljar-supervised
mljar-supervised是一個(gè)自動(dòng)化的機(jī)器學(xué)習(xí)Python軟件包,可用于表格數(shù)據(jù)。它旨在為數(shù)據(jù)科學(xué)家節(jié)省時(shí)間time。它抽象了預(yù)處理數(shù)據(jù),構(gòu)建機(jī)器學(xué)習(xí)模型以及執(zhí)行超參數(shù)調(diào)整以找到最佳模型common的通用方法。這不是黑盒子,因?yàn)槟梢源_切地看到ML管道的構(gòu)造方式(每個(gè)ML模型都有詳細(xì)的Markdown報(bào)告)。
在mljar-supervised中,將幫助您:
-
解釋和理解您的數(shù)據(jù),
-
嘗試許多不同的機(jī)器學(xué)習(xí)模型,
-
通過分析創(chuàng)建有關(guān)所有模型的詳細(xì)信息的Markdown報(bào)告,
-
保存,重新運(yùn)行和加載分析和ML模型。
它具有三種內(nèi)置的工作模式:
-
解釋模式,非常適合于解釋和理解數(shù)據(jù),其中包含許多數(shù)據(jù)解釋,例如決策樹可視化,線性模型系數(shù)顯示,排列重要性和數(shù)據(jù)的SHAP解釋,
-
執(zhí)行構(gòu)建用于生產(chǎn)的ML管道,
-
競(jìng)爭(zhēng)模式,用于訓(xùn)練具有集成和堆疊功能的高級(jí)ML模型,目的是用于ML競(jìng)賽中。
Auto-Keras官方鏈接
https://github.com/mljar/mljar-supervisedv
Auto-Keras是由DATA Lab開發(fā)的用于自動(dòng)機(jī)器學(xué)習(xí)(AutoML)的開源軟件庫。Auto-Keras建立在深度學(xué)習(xí)框架Keras之上,提供自動(dòng)搜索深度學(xué)習(xí)模型的體系結(jié)構(gòu)和超參數(shù)的功能。
Auto-Keras遵循經(jīng)典的Scikit-Learn API設(shè)計(jì),因此易于使用。當(dāng)前版本提供了在深度學(xué)習(xí)期間自動(dòng)搜索超參數(shù)的功能。
在Auto-Keras中,趨勢(shì)是通過使用自動(dòng)神經(jīng)體系結(jié)構(gòu)搜索(NAS)算法來簡(jiǎn)化ML。NAS基本上使用一組算法來自動(dòng)調(diào)整模型,以取代深度學(xué)習(xí)工程師/從業(yè)人員。
神經(jīng)網(wǎng)絡(luò)智能 NNI官方鏈接
https://github.com/keras-team/autokeras

用于神經(jīng)體系結(jié)構(gòu)搜索和超參數(shù)調(diào)整的開源AutoML工具包。NNI提供了CommandLine Tool以及用戶友好的WebUI來管理訓(xùn)練實(shí)驗(yàn)。使用可擴(kuò)展的API,您可以自定義自己的AutoML算法和培訓(xùn)服務(wù)。為了使新用戶容易使用,NNI還提供了一組內(nèi)置的最新AutoML算法,并為流行的培訓(xùn)平臺(tái)提供了開箱即用的支持。
Ludwig官方網(wǎng)站
https://nni.readthedocs.io/en/latest/

路德維希(Ludwig)是一個(gè)工具箱,可讓用戶無需編寫代碼即可訓(xùn)練和測(cè)試深度學(xué)習(xí)模型。它建立在TensorFlow之上,Ludwig基于可擴(kuò)展性原則構(gòu)建,并基于數(shù)據(jù)類型抽象,可以輕松添加對(duì)新數(shù)據(jù)類型和新模型架構(gòu)的支持,可供從業(yè)人員快速培訓(xùn)和測(cè)試深度學(xué)習(xí)模型以及由研究人員獲得的強(qiáng)基準(zhǔn)進(jìn)行比較,并具有實(shí)驗(yàn)設(shè)置,可通過執(zhí)行相同的數(shù)據(jù)處理和評(píng)估來確保可比性。
路德維希提供了一組模型體系結(jié)構(gòu),可以將它們組合在一起以為給定用例創(chuàng)建端到端模型。舉例來說,如果深度學(xué)習(xí)圖書館提供了建造建筑物的基礎(chǔ),路德維希提供了建造城市的建筑物,您可以在可用建筑物中進(jìn)行選擇,也可以將自己的建筑物添加到可用建筑物中。
-
無需編碼:不需要任何編碼技能即可訓(xùn)練模型并將其用于獲取預(yù)測(cè)。
-
通用性:新的基于數(shù)據(jù)類型的深度學(xué)習(xí)模型設(shè)計(jì)方法使該工具可在許多不同的用例中使用。
-
靈活性:經(jīng)驗(yàn)豐富的用戶對(duì)模型的建立和培訓(xùn)具有廣泛的控制權(quán),而新用戶則會(huì)發(fā)現(xiàn)它易于使用。
-
可擴(kuò)展性:易于添加新的模型架構(gòu)和新的特征數(shù)據(jù)類型。
-
可理解性:深度學(xué)習(xí)模型的內(nèi)部通常被認(rèn)為是黑匣子,但是路德維希(Ludwig)提供了標(biāo)準(zhǔn)的可視化效果來了解其性能并比較其預(yù)測(cè)。
-
開源:Apache License 2.0
Ad.NET官方鏈接
https://github.com/uber/ludwig

AdaNet是基于TensorFlow的輕量級(jí)框架,可在最少的專家干預(yù)下自動(dòng)學(xué)習(xí)高質(zhì)量的模型。AdaNet建立在AutoML最近的努力基礎(chǔ)上,以提供快速的,靈活的學(xué)習(xí)保證。重要的是,AdaNet提供了一個(gè)通用框架,不僅用于學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)體系結(jié)構(gòu),而且還用于學(xué)習(xí)集成以獲得更好的模型。
AdaNet具有以下目標(biāo):
-
易于使用:提供熟悉的API(例如Keras,Estimator)用于訓(xùn)練,評(píng)估和提供模型。
-
速度:可用計(jì)算進(jìn)行擴(kuò)展,并快速生成高質(zhì)量的模型。
-
靈活性:允許研究人員和從業(yè)人員將AdaNet擴(kuò)展到新穎的子網(wǎng)體系結(jié)構(gòu),搜索空間和任務(wù)。
-
學(xué)習(xí)保證:優(yōu)化提供理論學(xué)習(xí)保證的目標(biāo)。
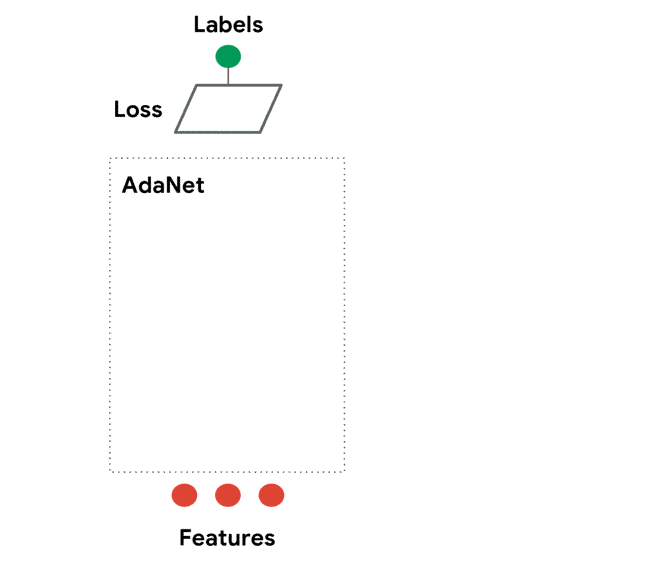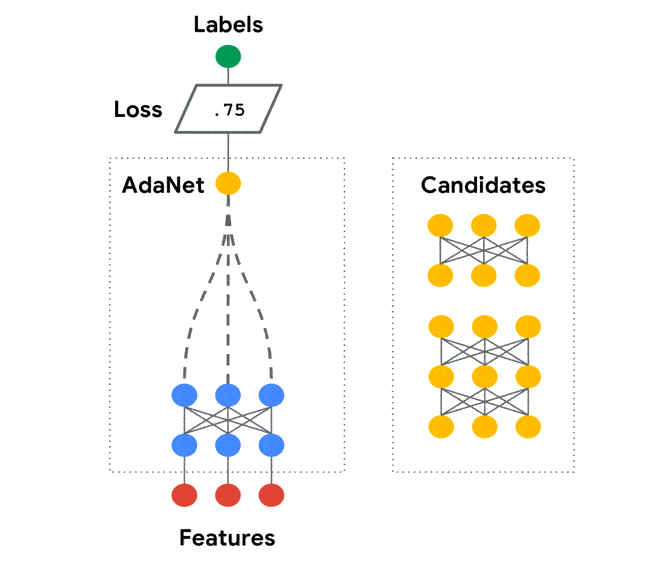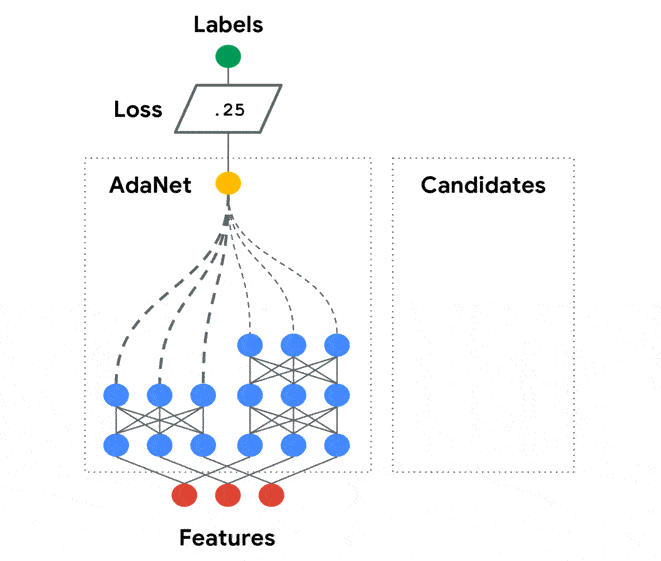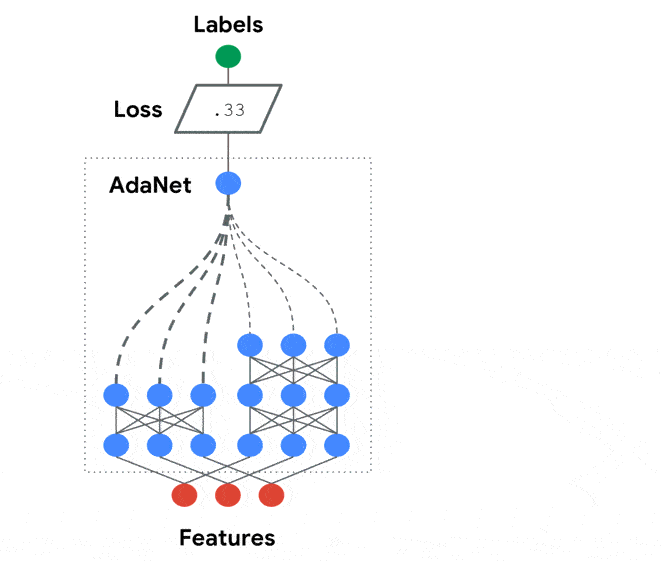
Darts官方鏈接
https://github.com/tensorflow/adanet
該算法基于架構(gòu)空間中的連續(xù)松弛和梯度下降。它能夠有效地設(shè)計(jì)用于圖像分類的高性能卷積體系結(jié)構(gòu)(在CIFAR-10和ImageNet上),以及用于語言建模的循環(huán)體系結(jié)構(gòu)(在Penn Treebank和WikiText-2上)。只需要一個(gè)GPU。
automl-gs官方鏈接
https://github.com/quark0/darts
提供一個(gè)輸入的CSV文件和一個(gè)您希望預(yù)測(cè)為automl-gs的目標(biāo)字段,并獲得訓(xùn)練有素的高性能機(jī)器學(xué)習(xí)或深度學(xué)習(xí)模型以及本機(jī)Python代碼管道,使您可以將該模型集成到任何預(yù)測(cè)工作流中。沒有黑匣子:您可以確切地看到如何處理數(shù)據(jù),如何構(gòu)建模型以及可以根據(jù)需要進(jìn)行調(diào)整。
automl-gs是一種AutoML工具,與Microsoft的NNI,Uber的Ludwig和TPOT不同,它提供了零代碼/模型定義界面,可在多個(gè)流行的ML / DL框架中以最少的Python依賴關(guān)系獲得優(yōu)化的模型和數(shù)據(jù)轉(zhuǎn)換管道。
以下是用R實(shí)現(xiàn) AutoKeras的R接口官方鏈接
https://github.com/minimaxir/automl-gs
AutoKeras是用于自動(dòng)機(jī)器學(xué)習(xí)(AutoML)的開源軟件庫。它是由德克薩斯農(nóng)工大學(xué)的DATA Lab和社區(qū)貢獻(xiàn)者開發(fā)的。AutoML的最終目標(biāo)是為數(shù)據(jù)科學(xué)或機(jī)器學(xué)習(xí)背景有限的領(lǐng)域?qū)<姨峁┮子谠L問的深度學(xué)習(xí)工具。AutoKeras提供了自動(dòng)搜索深度學(xué)習(xí)模型的體系結(jié)構(gòu)和超參數(shù)的功能。
在RStudio TensorFlow for R博客上查看AutoKeras博客文章。
以下是用Scala實(shí)現(xiàn) TransmogrifAI官方文檔
https://github.com/r-tensorflow/autokeras
TransmogrifAI(發(fā)音為tr?ns-m?g?r?-fī)是用Scala編寫的AutoML庫,它在Apache Spark之上運(yùn)行。它的開發(fā)重點(diǎn)是通過機(jī)器學(xué)習(xí)自動(dòng)化來提高機(jī)器學(xué)習(xí)開發(fā)人員的生產(chǎn)率,以及一個(gè)用于強(qiáng)制執(zhí)行編譯時(shí)類型安全,模塊化和重用的API。通過自動(dòng)化,它實(shí)現(xiàn)了接近手動(dòng)調(diào)整模型的精度,時(shí)間減少了近100倍。
如果您需要機(jī)器學(xué)習(xí)庫來執(zhí)行以下操作,請(qǐng)使用TransmogrifAI:
-
數(shù)小時(shí)而不是數(shù)月內(nèi)即可構(gòu)建生產(chǎn)就緒的機(jī)器學(xué)習(xí)應(yīng)用程序
-
在沒有博士學(xué)位的情況下建立機(jī)器學(xué)習(xí)模型在機(jī)器學(xué)習(xí)中
-
構(gòu)建模塊化,可重用,強(qiáng)類型的機(jī)器學(xué)習(xí)工作流程
以下是用JAVA實(shí)現(xiàn) Glaucus官方鏈接
https://github.com/salesforce/TransmogrifAI

Glaucus是基于數(shù)據(jù)流的機(jī)器學(xué)習(xí)套件,它結(jié)合了自動(dòng)機(jī)器學(xué)習(xí)管道,簡(jiǎn)化了機(jī)器學(xué)習(xí)算法的復(fù)雜過程,并應(yīng)用了出色的分布式數(shù)據(jù)處理引擎。對(duì)于跨領(lǐng)域的非數(shù)據(jù)科學(xué)專業(yè)人士,幫助他們以簡(jiǎn)單的方式獲得強(qiáng)大的機(jī)器學(xué)習(xí)工具的好處。
用戶只需要上傳數(shù)據(jù),簡(jiǎn)單配置,算法選擇,并通過自動(dòng)或手動(dòng)參數(shù)調(diào)整來訓(xùn)練算法。該平臺(tái)還為培訓(xùn)模型提供了豐富的評(píng)估指標(biāo),因此非專業(yè)人員可以最大限度地發(fā)揮機(jī)器學(xué)習(xí)在其領(lǐng)域中的作用。整個(gè)平臺(tái)結(jié)構(gòu)如下圖所示,主要功能是:
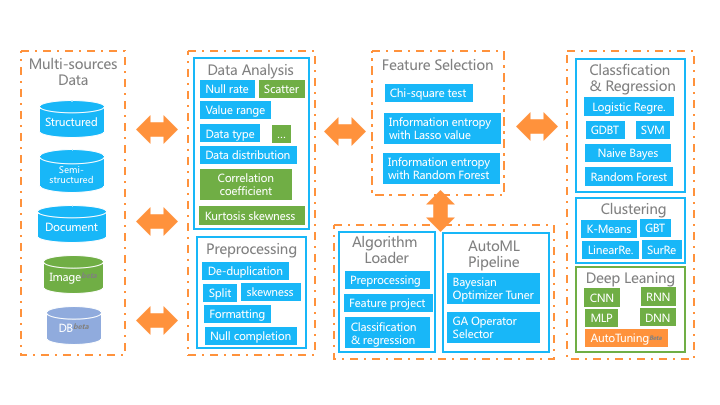
-
接收多源數(shù)據(jù)集,包括結(jié)構(gòu)化,文檔和圖像數(shù)據(jù);
-
提供豐富的數(shù)學(xué)統(tǒng)計(jì)功能,圖形界面使用戶輕松掌握數(shù)據(jù)情況;
-
在自動(dòng)模式下,我們實(shí)現(xiàn)了從預(yù)處理,特征工程到機(jī)器學(xué)習(xí)算法的全管道自動(dòng)化;
-
在手動(dòng)模式下,它極大地簡(jiǎn)化了機(jī)器學(xué)習(xí)流程,并提供了自動(dòng)數(shù)據(jù)清理,半自動(dòng)特征選擇和深度學(xué)習(xí)套件。
其他工具 H20 AutoML官方網(wǎng)站
https://github.com/ccnt-glaucus/glaucus

H2O AutoML界面設(shè)計(jì)為具有盡可能少的參數(shù),因此用戶所需要做的只是指向他們的數(shù)據(jù)集,標(biāo)識(shí)響應(yīng)列,并可選地指定時(shí)間限制或訓(xùn)練的總模型數(shù)量的限制。
在R和Python API中,AutoML與其他H2O算法使用相同的數(shù)據(jù)相關(guān)參數(shù)x,y,training_frame,validation_frame。大多數(shù)時(shí)候,您需要做的就是指定數(shù)據(jù)參數(shù)。然后,您可以為max_runtime_secs和/或max_models配置值,以在運(yùn)行時(shí)設(shè)置明確的時(shí)間或模型數(shù)量限制。
詳細(xì)原理與案例請(qǐng)見(點(diǎn)擊查看) 一文徹底搞懂自動(dòng)機(jī)器學(xué)習(xí)AutoML:H2O
PocketFlow官方鏈接
https://github.com//h2oai/h2o-3/blob/master/h2o-docs/src/product/automl.rst
PocketFlow旨在為開發(fā)人員提供一個(gè)易于使用的工具包,以提高推理效率而幾乎不降低性能或不降低性能。開發(fā)人員只需指定所需的壓縮和/或加速比,然后PocketFlow將自動(dòng)選擇適當(dāng)?shù)某瑓?shù)以生成用于部署的高效壓縮模型。
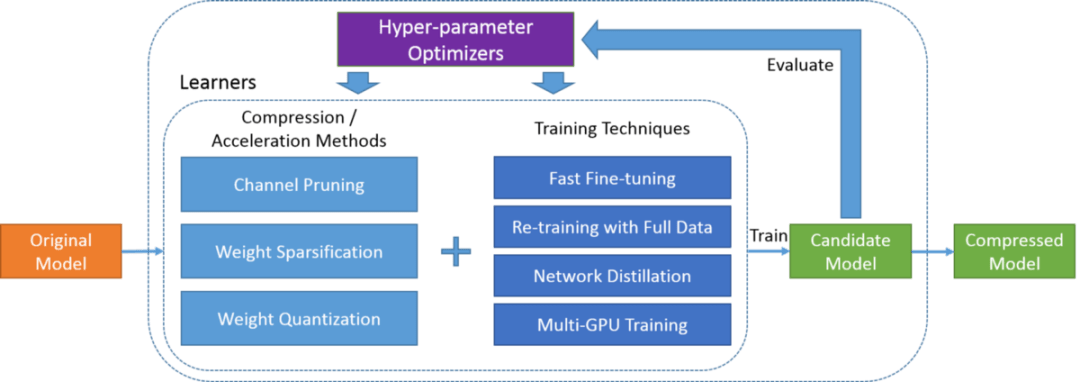
Ray官方鏈接
https://github.com/Tencent/PocketFlow

Ray提供了用于構(gòu)建分布式應(yīng)用程序的簡(jiǎn)單通用API。
Ray與以下庫打包在一起,以加快機(jī)器學(xué)習(xí)的工作量:
-
Tune:可伸縮超參數(shù)調(diào)整
-
RLlib:可擴(kuò)展的強(qiáng)化學(xué)習(xí)
-
RaySGD:分布式培訓(xùn)包裝器
-
Ray Serve:可擴(kuò)展和可編程服務(wù)
使用以下方式安裝Ray:pip install ray
Smac3官方鏈接
https://github.com/ray-project/ray
SMAC是用于算法配置的工具,可以跨一組實(shí)例優(yōu)化任意算法的參數(shù)。這還包括ML算法的超參數(shù)優(yōu)化。主要核心包括貝葉斯優(yōu)化和積極的競(jìng)速機(jī)制,可有效地確定兩種配置中哪一種的性能更好。
有關(guān)其主要思想的詳細(xì)說明,請(qǐng)參閱
Hutter, F. and Hoos, H. H. and Leyton-Brown, K.Sequential Model-Based Optimization for General Algorithm ConfigurationIn: Proceedings of the conference on Learning and Intelligent OptimizatioN (LION 5)
SMAC v3是用Python3編寫的,并經(jīng)過了Python3.6和python3.6的持續(xù)測(cè)試。它的隨機(jī)森林用C++編寫。
結(jié)論
autoML庫非常重要,因?yàn)樗鼈兛梢宰詣?dòng)執(zhí)行重復(fù)任務(wù),例如管道創(chuàng)建和超參數(shù)調(diào)整。它為數(shù)據(jù)科學(xué)家節(jié)省了時(shí)間,因此他們可以將更多的時(shí)間投入到業(yè)務(wù)問題上。AutoML還允許每個(gè)人代替一小部分人使用機(jī)器學(xué)習(xí)技術(shù)。數(shù)據(jù)科學(xué)家可以通過使用AutoML實(shí)施真正有效的機(jī)器學(xué)習(xí)來加速M(fèi)L開發(fā)。
讓我們看看AutoML的成功將取決于組織的使用情況和需求。時(shí)間將決定命運(yùn)。但是目前我可以說AutoML在機(jī)器學(xué)習(xí)領(lǐng)域中很重要。
轉(zhuǎn)自聞雞起舞,版權(quán)屬于原作者,僅用于學(xué)術(shù)分享





