

什么是全文搜索引擎?
常?的搜索?站,?如百度,?歌。

數據的分類
- 結構化數據:指具有固定格式或有限?度的數據,如數據庫,元數據等。
對于結構化數據,我們?般都是可以通過關系型數據庫(mysql,oracle等)的 table 的?式存儲和搜索,也可以建?索引。通過b-tree等數據結構快速搜索數據。
- ?結構化數據:全?數據,指不定?或?固定格式的數據,如郵件,word?檔等。
對于?結構化數據,也即對全?數據的搜索主要有兩種?法:順序掃描法,全?搜索法。
順序掃描
- 按字?意思,我們可以了解它的?概搜索?式,就是按照順序掃描的?式查找特定的關鍵字。?如讓你在?篇籃球新聞中,找出"科?"這個名字在哪些段落出現過。那你肯定需要從頭到尾把?章閱讀?遍,然后標記出關鍵字在哪些地?出現過。
- 這種?法毋庸置疑是最低效的,如果?章很?,有?萬字,等你閱讀完這篇新聞找到"科?"這個關鍵字,那得花多少時間。
全?搜索
- 對?結構化數據進?順序掃描很慢,我們是否可以進?優化?把我們的?結構化數據想辦法弄得有?定結構不就?了嗎?將?結構化數據中的?部分信息提取出來,重新組織,使其變得有?定結構,然后對這些有?定結構的數據進?搜索,從?達到搜索相對較快的?的。這種?式就構成了全?搜索的基本思路。這部分從?結構化數據中提取出的然后重新組織的信息,我們稱之索引。
- 我們以NBA中國?站為例,假設我們都是籃球愛好者,并且我們是科密,那如何快速找到有關科?的新聞呢?全?搜索的?式就是,將所有新聞中所有的關鍵字進?提取,?如"科?","詹姆斯","總冠軍","MVP"等關鍵字,然后對這些關鍵字建?索引,通過索引我們就可以找到對應的該關鍵詞出現的新聞了。
什么是全?搜索引擎
根據百度百科中的定義,全?搜索引擎是?前?泛應?的主流搜索引擎。它的?作原理是計算機索引程序通過掃描?章中的每?個詞,對每?個詞建??個索引,指明該詞在?章中出現的次數和位置,當?戶查詢時,檢索程序就根據事先建?的索引進?查找,并將查找的結果反饋給?戶的。
搜索引擎
- Lucene
- Solr
- Elastic search
為什么不?mysql做全?搜索
前?
- 有?可能會問,為什么?定要?搜索引擎呢?我們的所有數據不是都可以放在數據庫?嗎?
- ?且 Mysql,Oracle,SQL Server 等數據庫?不是也能提供查詢搜索功能,直接通過數據庫查詢不就可以了嗎?
- 確實,我們?部分的查詢功能都可以通過數據庫查詢獲得,如果查詢效率低下,還可以通過新建數據庫索引,優化SQL等?式進?提升效率,甚?通過引?緩存?如redis,memcache來加快數據的返回速度。如果數據量更?,還可以通過分庫分表來分擔查詢壓?。
- 那為什么還要全?搜索引擎呢?我們從?個?度來說
數據類型
全?索引搜索很好的?持?結構化數據的搜索,可以更好地快速搜索?量存在的任何單詞?結構化?本。例如 Google,百度類的?站搜索,它們都是根據??中的關鍵字?成索引,我們在搜索的時候輸?關鍵字,它們會將該關鍵字即索引匹配到的所有??返回;還有常?的項?中應??志的搜索等等。對于這些?結構化的數據?本,關系型數據庫搜索不是能很好的?持。
搜索性能
如果使?mysql做搜索,?如有個player表,這個表有user_name這個字段,我們要查找出user_name以james開頭的球員,和含有James的球員。我們?般怎么做?數據量達到千萬級別的時候怎么辦?
select * from player where user_name like 'james%';
select * from player where user_name like '%james%'; 靈活的搜索
- 如果我們想查出名字叫james的球員,但是?戶輸?了jame,我們想提示他?些關鍵字
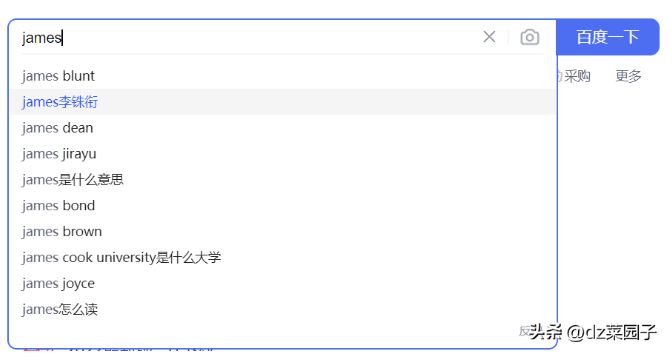
- 如果我們想查出帶有"冠軍"關鍵字的?章,但是?戶輸?了"總冠軍",我們也希望能查出來。
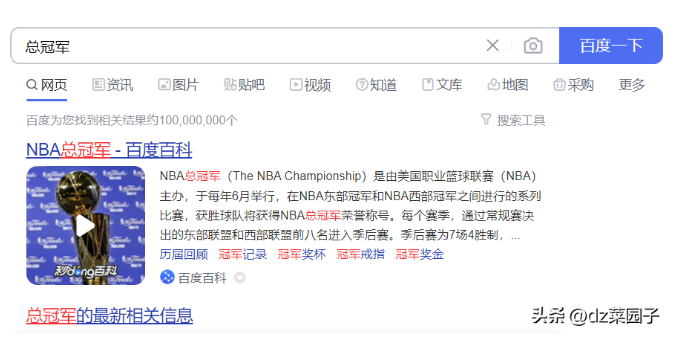
索引的維護
?般傳統數據庫,全?搜索都實現的很雞肋,因為?般也沒??數據庫存??本字段,因為進?全?搜索的時候需要掃描整個表,如果數據量?的話即使對SQL的語法進?優化,也是效果甚微。即使建?了索引,但是維護起來也很麻煩,對于 insert 和 update 操作都會重新構建索引。
適合全?索引引擎的場景
- 搜索的數據對象是?量的?結構化的?本數據。
- ?本數據量達到數?萬或數百萬級別,甚?更多。
- ?持?量基于交互式?本的查詢。
- 需求?常靈活的全?搜索查詢。
- 對安全事務,??本數據操作的需求相對較少的情況。
常?的搜索引擎
簡介:常?的搜索引擎,Lucene,Solr,Elasticsearch
Lucene
- Lucene是?個Java全?搜索引擎,完全?Java編寫。Lucene不是?個完整的應?程序,?是?個代碼庫和API,可以很容易地?于向應?程序添加搜索功能。
- 通過簡單的API提供強?的功能
可擴展的?性能索引
強?,準確,?效的搜索算法
跨平臺解決?案
- Apache軟件基?會
在Apache軟件基?會提供的開源軟件項?的Apache社區的?持。
但是Lucene只是?個框架,要充分利?它的功能,需要使?java,并且在程序中集成Lucene。需要很多的學習了解,才能明?它是如何運?的,熟練運?Lucene確實?常復雜。
Solr
- Solr是?個基于Lucene的Java庫構建的開源搜索平臺。它以?戶友好的?式提供ApacheLucene的搜索功能。它是?個成熟的產品,擁有強???泛的?戶社區。它能提供分布式索引,復制,負載均衡查詢以及?動故障轉移和恢復。如果它被正確部署然后管理得好,它就能夠成為?個?度可靠,可擴展且容錯的搜索引擎。很多互聯?巨頭,如Netflflix,eBay,Instagram和亞?遜都使?Solr,因為它能夠索引和搜索多個站點。
- 強?的功能
全?搜索
突出
分?搜索
實時索引
動態群集
數據庫集成
NoSQL功能和豐富的?檔處理
Elasticsearch
- Elasticsearch是?個開源,是?個基于Apache Lucene庫構建的Restful搜索引擎.
- Elasticsearch是在Solr之后?年推出的。它提供了?個分布式,多租戶能?的全?搜索引擎,具有HTTP Web界?(REST)和?架構JSON?檔。Elasticsearch的官?客戶端庫提供Java,Groovy,PHP,Ruby,Perl,Python,.NET和Javascript。
- 主要功能
分布式搜索
數據分析
分組和聚合
- 應?場景
維基百科
Stack Overflflow
GitHub
電商?站
?志數據分析
商品價格監控?站
BI系統
站內搜索
籃球論壇
參考個人博客:cyz






