
今天和大家分享下我近段時間get的新技能,用單線程、多線程和協程三種方式爬取并下載梨視頻的小視頻,話不多說,我們開始叭。沖鴨沖鴨!
目標
將梨視頻上的科技相關的視頻資源下載保存到電腦本地
工具
- Python/ target=_blank class=infotextkey>Python3.9
- Pycharm2020
需要用到的第三方庫
1) requests # 發送請求2) parsel # 解析數據(支持re, xpath, css)3) fake_useragent # 構建請求頭4) random # 生成隨機數5) os # 操作路徑/生成文件夾6) json # 處理json數據7) concurrent # 處理線程池8) asyncio, aiohttp, aiofiles # 處理協程
分析并使用單線程下載視頻
我們需要將梨視頻網站上的視頻資源下載到電腦本地,那必不可少的兩個元素必然是視頻名稱和視頻資源url。獲取視頻資源url后,針對視頻資源的url發起請求,得到響應,再將響應內容以視頻名稱為名保存到電腦本地即可。
起始頁:科技熱點資訊短視頻_科技熱點新聞-梨視頻官網-Pear Video
URL地址:
https://www.pearvideo.com/category_8
1.分析起始頁
F12對起始頁刷新抓包,拿到數據請求接口

梨視頻(科技)主頁
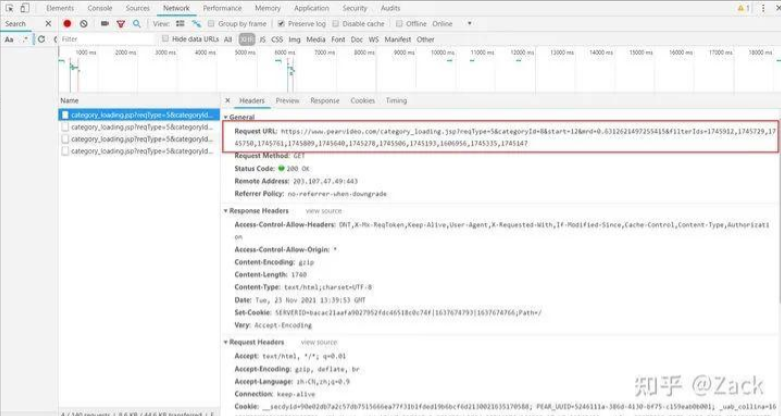
對比觀察抓包獲取到的url:
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=12&mrd=0.6312621497255415&filterIds=1745912,1745729,1745750,1745761,1745809,1745640,1745278,1745506,1745193,1606956,1745335,1745147
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=24&mrd=0.9021185727219558&filterIds=1745912,1745729,1745750,1745254,1745034,1744996,1744970,1744646,1744743,1744838,1744567,1744308,1744225,1744727,1744649
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=36&mrd=0.6598737970838424&filterIds=1745912,1745729,1745750,1744642,1744353,1744377,1744291,1744127,1744055,1744106,1744126,1744040,1743939,1743997,1744012
對比上方三個url可見,除了其中的start, mrd以及filterIds不同之外,其余部分均為https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=。其中start每次增長為12,即每次加載12段視頻;mrd為一個隨機數,filterIds即為視頻資源的cid號。
2. 發送起始頁請求
我們可以根據抓包獲取到的信息構建請求,獲取響應內容。全文將模仿scrapy框架的寫法,將代碼封裝在一個類之中,再定義不同的函數實現各個階段的功能。
# 導入需要用到的模塊
import requests
from parsel import Selector
from fake_useragent import UserAgent
import random
import json
import os
創建類并定義相關函數、屬性
class PearVideo:
def __init__(self, page):
self.headers = {
"User-Agent": UserAgent().chrome, # 構建谷歌請求頭
}
self.page = page # 設置要爬取的頁數
self.base_url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start="
def start_request(self):
for page in range(self.page):
start_url = self.base_url + str(page * 12) # 拼接起始頁url
res = requests.get(start_url, headers=self.headers)
if res.status_code == 200:
# 將獲取到的請求轉換成一個parsel.selector.Selector對象,之后方便解析文本;
# 類似scrapy框架中的response對象,可直接調用re(), xpath()和css()方法。
selector = Selector(res.text)
self.parse(selector)
獲取到響應之后就可以解析響應文本了,在響應文本中我們可以提取到視頻的詳情頁url及視頻名稱,代碼如下:
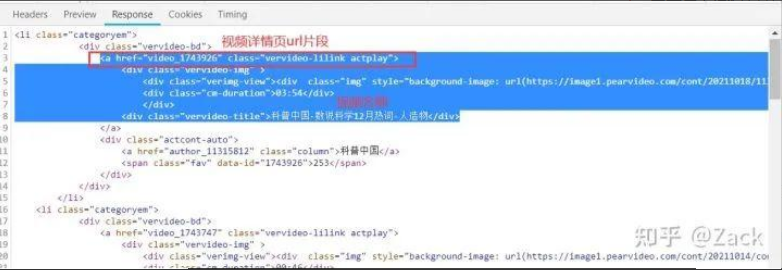
3. 解析起始頁響應獲取視頻名稱、視頻詳情頁url
def parse(self, response):
videos = response.xpath("//div[@class='vervideo-bd']")
for video in videos:
# 拼接視頻詳情頁url
detail_url = "https://www.pearvideo.com/" + video.xpath("./a/@href").get()
# 提取視頻名稱
video_name = video.xpath(".//div[@class='vervideo-title']/text()").get()
# 將視頻詳情頁url和視頻名稱傳遞給parse_detail方法,對詳情頁發送請求獲取響應。
self.parse_detail(detail_url, video_name)
在瀏覽器中打開視頻詳情頁,按F12觀察瀏覽器渲染之后的代碼可見視頻資源的url, 如下圖所示:
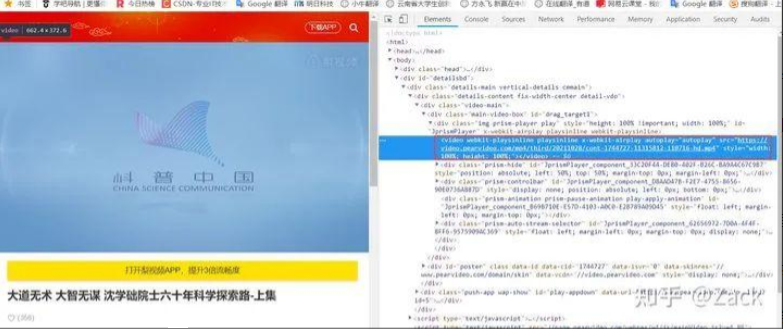
此處的視頻資源url為:
https://video.pearvideo.com/mp4/third/20211028/cont-1744727-11315812-110716-hd.mp4
但是實際獲取視頻詳情頁響應后,并沒有找到視頻資源的url,能找到的只有一張視頻圖片預覽的url,如下圖所示(可在瀏覽器視頻詳情頁,鼠標右鍵查看網頁源代碼獲取):

于是,我們再次針對視頻詳情頁抓包,找到視頻資源url的相關請求和響應內容,如下圖所示:
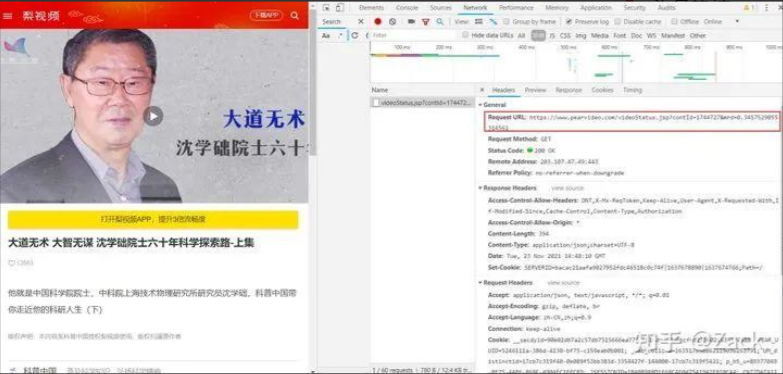

其中的contId即為詳情頁響應的data-cid屬性值(詳見下文),而mrd為一個隨機值,可通過random.random()生成,在發送請求的時候Referer必不可少,否則將無法獲取到正確的響應內容。
點擊preview,可以查看請求的響應結果,如下圖所示:
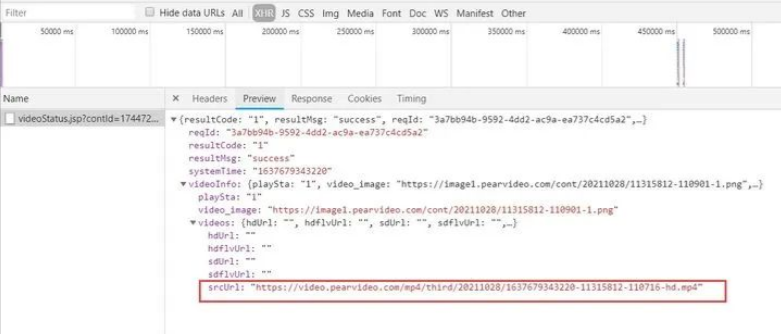
在圖中,我們可以得到一個后綴為mp4的srcUrl鏈接,這看起來像是我們需要的視頻資源url,但是如果直接使用這個鏈接發送請求,將會提示如下錯誤:
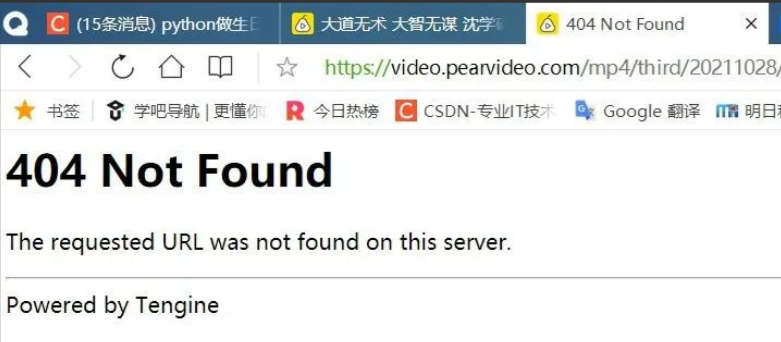
對比觀察瀏覽器渲染之后的視頻資源url和抓包獲取的視頻資源url:
瀏覽器渲染:
https://video.pearvideo.com/mp4/third/20211028/cont-1744727-11315812-110716-hd.mp4抓包獲取:
https://video.pearvideo.com/mp4/third/20211028/1637679343220-11315812-110716-hd.mp4
通過觀察可得出,除了上文加黑標粗的部分不同外,其余部分均相同;而其中的1744727即為視頻資源的data-cid屬性值。
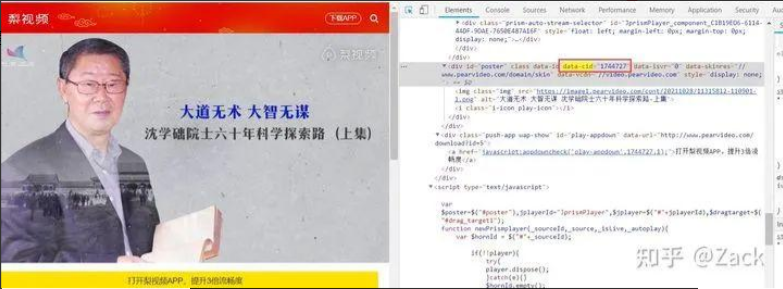
瀏覽器視頻詳情頁中獲取
于是我們可以將抓包所獲取到的假的視頻資源url中的1637679343220替換為cont-1744727(即視頻data-cid屬性值),即可獲取到真正的視頻資源url, 從而下載視頻資源!
經過漫長的分析之后,終于可以著手寫代碼啦!
4. 針對視頻詳情頁url發送請求,獲取響應
def parse_detail(self, detail_url, video_name):
detail_res = requests.get(detail_url, headers=self.headers)
detail_selector = Selector(detail_res.text)
init_cid = detail_selector.xpath("//div[@id='poster']/@data-cid").get() # 提取網頁中data-cid的屬性值(初始cid)
mrd = random.random() # 生成隨機數,構建mrd
ajax_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={init_cid}&mrd={mrd}"
global ajax_header # 將ajax_header設置為全局變量,以便在后續的函數中調用
ajax_header = {"Referer": f"https://www.pearvideo.com/video_{init_cid}"}
self.parse_ajax(ajax_url, init_cid, video_name)
5. 對視頻詳情頁抓包,獲取假的視頻資源url
def parse_ajax(self, ajax_url, init_cid, video_name):
ajax_res = requests.get(ajax_url, headers=ajax_header)
fake_video_url = json.loads(ajax_res.text)["videoInfo"]["videos"]["srcUrl"] # 獲取假的視頻資源url
fake_cid = fake_video_url.split("/")[-1].split("-")[0] # 從假的視頻資源url中抽取假的cid
real_cid = "cont-" + init_cid # 真的cid等于cont-加上初始的cid
# 將假的視頻資源url中假的cid(fake_cid)替換為真的cid(real_cid)即可得到真正的視頻資源url啦!!!
# 這段代碼,你品,你細品...
real_video_url = fake_video_url.replace(fake_cid, real_cid)
self.download_video(video_name, real_video_url)
6. 對視頻資源url發送請求,獲取響應
有了視頻名稱和視頻資源url,就可以下載視頻啦!!!
def download_video(self, video_name, video_url):
video_res = requests.get(video_url, headers=ajax_header)
video_path = os.path.join(os.getcwd(), "單線程視頻下載")
# 如果不存在則創建視頻文件夾存放視頻
if not os.path.exists(video_path):
os.mkdir(video_path)
with open(f"{video_path}/{video_name}.mp4", "wb") as video_file:
video_file.write(video_res.content)
print(f"{video_name}下載完畢")
最后,定義一個run()方法作為整個類的入口,調用最開始的start_request()函數即可!(套娃,一個函數套另一個函數)
def run(self):
self.start_request()
if __name__ == '__main__':
pear_video = PearVideo(3) # 先獲取它三頁的視頻資源
pear_video.run()
使用線程池下載視頻
線程池這部分的代碼總體和單線程類似,只是將其中的視頻名稱和視頻資源url單獨抽取出來,作為全局變量。獲取視頻名稱和視頻資源url這部分仍為單線程,僅在下載視頻資源這部分才用了線程池處理,可以同時針對多個視頻資源url發送請求獲取響應。
主要代碼如下:
class PearVideo:
def __init__(self, page):
self.headers = {
"User-Agent": UserAgent().chrome,
}
self.page = page
self.base_url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start="
self.video_list = [] # 新增了video_list為全局變量,用來保存視頻名稱和視頻資源url
1.獲取真正的視頻資源url代碼
def parse_ajax(self, ajax_url, init_cid, video_name):
ajax_res = requests.get(ajax_url, headers=ajax_header)
fake_video_url = json.loads(ajax_res.text)["videoInfo"]["videos"]["srcUrl"]
fake_cid = fake_video_url.split("/")[-1].split("-")[0]
real_cid = "cont-" + init_cid
real_video_url = fake_video_url.replace(fake_cid, real_cid)
# video_dict每次請求都會刷新,最終保存到video_list中
video_dict = {
"video_url": real_video_url,
"video_name": video_name
}
self.video_list.Append(video_dict)
2. 多線程下載視頻資源代碼
def download_video(self, video_dict): # 此處傳遞的是一個字典而非video_list這個列表
video_res = requests.get(video_dict["video_url"], headers=ajax_header)
video_path = os.path.join(os.getcwd(), "線程池視頻下載")
if not os.path.exists(video_path):
os.mkdir(video_path)
with open(f"{video_path}/{video_dict['video_name']}.mp4", "wb") as video_file:
video_file.write(video_res.content)
print(f"{video_dict['video_name']}下載完畢")
3. 啟動多線程
if __name__ == '__main__':
pear_video = PearVideo(2)
pear_video.run()
pool = ThreadPoolExecutor(4) # 此處的4表示每次只開啟4個線程下載視頻資源
# 此處的map方法和Python自帶的map(x,y)含義類似,即將可迭代對象y中的每一個元素執行函數x。
pool.map(pear_video.download_video, pear_video.video_list)
使用協程下載視頻
使用協程下載視頻資源中最為重要的三個庫為asyncio(創建協程對象),aiohttp(發送異步請求),aiofiles(異步保存文件)。
重點:
1)在函數前加上async關鍵字,函數即被創建為一個協程對象;2)協程對象中所有需要io耗時操作的部分均需使用await將任務掛起;3)協程對象不能直接運行,需要創建一個事件循環(類似無限循環),然后再運行協程對象。
注意:
1)不能使用requests發送異步請求,需要使用aiohttp或httpx;2)不能直接使用open()保存文件,需要使用aiofiles進行異步操作保存。
主要代碼如下
# 將視頻資源url和視頻名稱作為全局變量
self.video_urls = []
self.video_names = []
1.定義協程對象下載視頻
# 下載視頻信息
async def download_videos(self, session, video_url, video_name, video_path):
# 發送異步請求
async with session.get(video_url, headers=ajax_header) as res:
# 獲取異步響應,前面必須加上await,表示掛起
content = await res.content.read()
# 異步保存視頻資源到電腦本地
async with aiofiles.open(f"{video_path}/{video_name}.mp4", "wb") as file:
print(video_name + " 下載完畢...")
await file.write(content)
2. 創建main()運行協程對象
async def main(self):
video_path = os.path.join(os.getcwd(), "協程視頻下載")
if not os.path.exists(video_path):
os.mkdir(video_path)
async with aiohttp.ClientSession() as session: # 創建session,保持會話
# 創建協程任務,每一個視頻資源url即為一個協程任務
tasks = [
asyncio.create_task(self.download_videos(session, url, name, video_path))
for url, name in zip(self.video_urls, self.video_names)
]
# 等待所有的任務完成
done, pending = await asyncio.wait(tasks)
3. 調用整個類并運行協程對象
if __name__ == '__main__':
pear_video = PearVideo(3)
pear_video.run()
loop = asyncio.get_event_loop() # 創建事件循環
loop.run_until_complete(pear_video.main()) # 運行協程對象
在保存視頻的時候,如果視頻名稱中含有"", "/", "*", "?", "<", ">", "|"在內的非法字符,視頻將無法保存,程序將報錯,可用如下代碼過濾視頻名稱:
def rename(self, name):
stop = ["\", "/", "*", "?", "<", ">", "|"]
new_name = ""
for i in name:
if i not in stop:
new_name += i
return new_name
在使用多線程和協程下載視頻資源這部分代碼中都是使用單線程和線程池/協程結合,均是在獲取到視頻名稱和視頻資源url后再針對視頻資源發送請求,獲取響應,此部分代碼仍有待優化,如使用生產者/消費者模式一邊生產視頻資源url,一邊根據url下載視頻;而協程部分也可將其它需要發送網絡請求的部分修改為協程模式,從而提高下載速度。
總結
下載梨視頻的視頻資源難點在于破解真正的視頻資源url, 先后需要對視頻起始頁(主頁)發送請求,再對視頻詳情頁發送請求,然后再對視頻詳情頁抓包獲取真正的視頻資源url,最后再針對視頻資源url發送請求,下載視頻資源。其中線程池和協程的部分仍有待優化,以便更好地提高下載效率!





