
缺乏自主的關鍵技術是國產數據庫被詬病最多的痛點。
眾所周之,國產數據庫中,絕大多數是基于開源數據庫改造的,尤其是基MySQL或 PostgreSQL改造的居多,這本身無可厚非。
自研,并非只有從0開始完全自研一條路,基于開源數據庫做半自研,然后逐漸深入關鍵核心模塊,直至最終完全掌控開源數據庫,也是自研。但是,這絕不是在開源數據庫上穿個“衣”帶個“帽”。毫無疑問,在數據庫市場中,自研、內核創新、核心業務系統等詞被濫用了。
那么,基于開源數據庫的國產數據庫中,到底有沒有,具有自己的技術創新,甚至內核級創新的產品呢?答案,當然是有的。
今天,老魚就想來聊一聊openGauss的技術創新,為此,老魚采訪了openGauss 技術委員會主席李國良,openGauss開源數據庫首席架構師黃凱耀,聽他們說一說openGauss內核與架構技術創新的故事。
李國良,清華大學計算機系副主任、教授、博士生導師。在數據庫會議和期刊上發表論文150余篇,他引10000余次。獲得了VLDB 2017 Early Career Research Contributions Award(亞洲首位)、IEEE TCDE Early Career Award(亞洲首位)。SIGMOD 2021大會主席,VLDB 2021 Demo 主席,ICDE 2022 Industry Chair,獲國家科技進步二等獎、江蘇省科技進步一等獎。
黃凱耀,openGauss開源數據庫首席架構師,負責openGauss的技術規劃與產品設計工作,在數據庫高性能架構、高可用架構、OLTP性能優化、OLAP性能優化、一體化架構、軟硬協同等領域有豐富的理論、工程與實踐經驗。
什么是數據庫內核?學過數據庫的都知道,內核通常指數據庫最核心的部分,比如:優化器、解析器、執行器、存儲引擎等。
openGauss對內核如何界定?老魚找到一張官方圖:
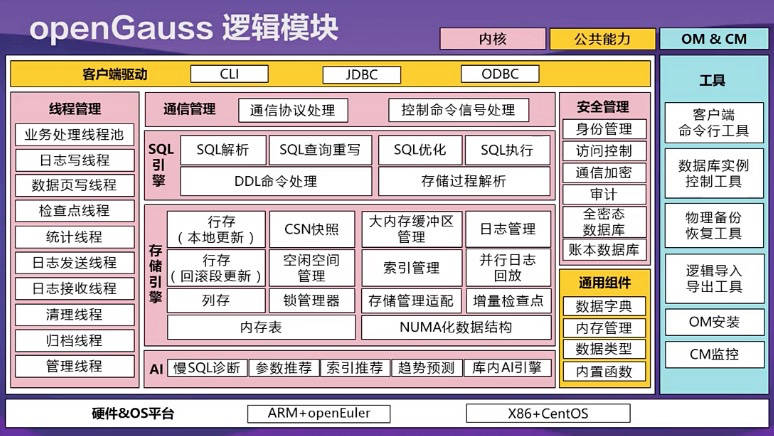
如上圖,粉色的部分就是openGauss界定的內核部分,包括線程管理、通信管理、SQL引擎、存儲引擎、安全管理、AI。那么,openGauss在內核上都有哪些創新?其實,上圖已經能看出一部分東西。
眾所周之,openGauss內核早期衍生自PostgreSQL-XC,但如今,openGauss與PostgreSQL-在架構和內核上,已經有了極大的差異。
如上圖,openGauss執行模型,采用線程池模型。而PostgreSQL是進程模型。這么改有什么好處?進程模型,數據庫進程通過共享內存實現通訊和數據共享,每個進程對應一個并發連接,這就存在高并發下,進程切換性能損耗,導致多核擴展性問題。而線程池技術的整體設計思想是線程資源池化、并且在不同連接之間復用,因此,高并發連接切換代價小,內存損耗小,執行效率高。
李國良說,openGauss尤其在核心的優化器、執行器、存儲引擎方面,做了很多的改進和優化,與傳統的關系型數據庫,有了本質區別。
存儲引擎方面,openGauss實現存儲引擎融合,即一套架構支持多種存儲模式。openGauss支持多引擎(行存儲引擎、列存儲引擎、內存引擎),而PostgreSQL僅支持行存儲引擎。看起來只是多支持了2個引擎,但其中涉及很多關鍵技術。比如:openGauss行存儲引擎采用原地更新(in-place update)設計(又名:Ustore存儲引擎),追加寫引擎(HEAP),支持MVCC(Multi-Version Concurrency Control,多版本并發控制),同時支持本地存儲和存儲、計算分離部署方式。
原地更新相比非原地更新有什么好處?李國良給老魚打了個比方,簡單的說,非原地更新是一張表一直往上加,有刪有增,維護這張表代價非常大。openGauss 內核此前的版本使用的行存儲引擎是Append Update(追加更新)模式,追加更新對于業務中的增、刪以及HOT(Heap Only Tuple) Update(即同一頁面內更新)有很好的表現,但對于跨數據頁面的非HOT UPDATE場景,垃圾回收不夠高效,因此,Ustore存儲引擎應運而生。
眾所周知,優化器的好壞會直接決定關系型數據庫的強弱,優化器一般分為RBO(Rule-Based Optimizer)基于規則的優化器和CBO(Cost-Based Optimizer)基于代價的優化器,PostgreSQL支持CBO,openGauss支持CBO,SQL by pass。
雖然都支持CBO,但對復雜場景的優化能力是完全不同的。李國良說,openGauss在優化器的CBO上做了很多技術創新。首先,openGauss添加了很多查詢重寫規則,查詢重寫優化;其次,openGauss做了很多CBO代價的調優模型,適應不同場景;最后,openGauss加了基于機器學習的代價估計方法和優化算法,使得優化器更智能,適用于更多、更全面的復雜場景。
Sql-bypass是openGauss針對OLTP場景開發的一個輕量化執行器,它解決的是什么問題?在典型的OLTP場景中,簡單SQL查詢占了很大部分比例。試想一下,如果一個簡單的SQL查詢因為復雜的CBO邏輯,而消耗不必要的CPU資源浪費執行時間,那肯定是不行的。SQL by pass就是為了加速這類查詢設計的,可以極大地縮短執行器通用框架處理邏輯,極大地提升執行的性能。
執行器方面,為了提高SQL的執行速度,解決傳統數據處理引擎條件邏輯冗余的問題,openGauss執行器引入了自適應實時編譯(Codegen)技術,其核心思想是為具體的查詢生成定制化的機器碼代替通用的函數實現,并盡可能地將數據存儲在CPU寄存器中。
總的來說,openGauss內核創新圍繞“四高”原則,即:高性能、高可用、高安全、高智能。比如:高性能,openGauss聚焦了很多新型技術,包括NUMA-Aware技術、智能優化技術、內核并行執行的技術,這些都是在內核創新方面引領的一些新型技術。
高智能,在數據庫內核方面涉及到很多優化技術,包括很多優化NP問題,以及代價估算技術。傳統方式都是基于一些獨立性假設、均勻分布假設,這導致估算結果非常不準確,而openGauss通過眾多智能技術(智能索引技術、智能數據化分析技術、智能優化內核技術)提升準確性、提升數據庫內核優化效率,提高可復制性。
 (密態數據庫總體架構)
(密態數據庫總體架構)
高安全,是openGauss非常重視的一個特性,openGauss引領了防篡改、全密態數據庫發展,也得到了一些POC的測試。此后,openGauss會持續構筑這些能力,打造安全、穩定的數據庫密態內核,達到商用產品化標準,保護用戶敏感、隱私數據的全生命周期的安全。
黃凱耀則給老魚分享了4個架構創新,工具創新的故事,分別是插件化架構、可觀測內核架構、資源池化架構、數據安全架構,而這四個架構創新是基于用戶場景驅動的,解決的是易遷移、易運維、易開發、易擴展的剛需問題。
篇幅所限,本文只解析插件化架構及可觀測內核架構。

黃凱耀告訴老魚,插件化架構的提出,是為了易遷移的目標,也就是為了實現方便簡單的把其它數據庫往openGauss遷移。為了達成這個目標,openGauss設計了數據庫的插件化架構。首先,在計算引擎這一層上面,定義了數據庫的擴展點。數據庫內核開發者可以基于這些擴展點,去實現其它數據庫語法的兼容插件。

同時,為了更方便支持應用開發者把原有的數據庫遷移到openGauss上,在內核層面,openGauss實現了SQL兼容性評估插件。基于應用提供的SQL語句,去調用相應的數據庫插件,基于該插件的能力,對SQL語句進行評估并得出可讀性很強的評估報告,為什么說可讀性很強?因為,它是從其它數據庫遷移到openGauss的遷移建議的中文提示,而非模糊化的英文提示。
第二個故事,是可觀測架構。可觀測與可運維是社區開發者對openGauss提出的另外一項重大訴求,并不亞于遷移方面的呼聲。黃凱耀說,解決的問題是怎樣對openGauss進行更加全面系統地性能監控和故障診斷。
搞過數據庫運維的人都知道一個棘手的場景,就是業務部門反饋系統慢,但DBA從有限的數據庫監控指標上卻看不出任何問題。因此,加強數據庫可觀測性是降低數據庫使用成本一個非常重要的手段。
相較而言,要實現全棧的可觀測、可跟蹤架構,技術難度很高。因為,這不僅涉及到數據庫內核,數據庫運維,還涉及操作系統內核等,黃凱耀說。

openGauss通過資源消耗鏈的角度,把整個系統的資源消耗分為三類:
存儲資源消耗鏈
網絡資源消耗鏈
CPU內存資源消耗鏈
在每一個資源消耗鏈上,可以通過上鉆下探的方法,去實現系統性能問題的優化或者故障問題的定位。通過這種全面系統的上鉆下探,就可以實現一個良好的可觀測架構。
而這背后,需要對數據庫內核代碼做更多的增強,并且僅數據庫內核增強還不夠,還需要借助操作系統最先進的eBPF技術,才可能提供更全面、更豐富的可觀測數據。而有了豐富的數據,診斷系統就可以基于這些數據做基于專家模型的推理或AI診斷。
通常,從一個業務指標,關聯到數據庫等待時間指標,再關聯到操作系統的資源消耗指標,是目前主流數據庫所提供的可觀測能力。但openGauss更進了一步,直接把數據庫內核中的熱點函數也追蹤起來,這樣,實現了在等待事件之下的進一步的觀測與診斷。
因此,openGauss可觀測架構實現了從觀測數據到診斷定位的全鏈條打通。
實際上,openGauss內核與架構技術創新的故事遠不止這些,本文也只是管中窺豹,無法一一列舉。比如:在Oracle 21c中才出現的區塊鏈表 ,在openGauss 2.0中就已經被實現 。當然,即便如此,openGauss依然還需要持續提升和完善,創新之路上還有很長的路要走。但本文想表達的是,無論是內核創新,還是架構創新,事實上,無論是那種架構的創新,最終都與內核息息相關,只有完全掌握消化內核并在此基礎上持續創新,才算是真正的自主可控。
數據庫發展了半個多世紀,在舊的數據庫技術上,中國與西方差距其實不大,大家都知道怎么去做。李國良說,但在軟件工程能力上,我們與國外是有差距的,這需要我們努力,而超越機會更大的是創新性,我們要去引領創新,而不是跟隨別人創新。
因為,你走別人的路,一直跟別人學,是永遠不可能成功的。





