
引言
在關(guān)于《Nginx》的文章中曾經(jīng)提到:單節(jié)點的Nginx在經(jīng)過調(diào)優(yōu)后,可承載5W左右的并發(fā)量,同時為確保Nginx的高可用,在文中也結(jié)合了Keepalived對其實現(xiàn)了程序宕機(jī)重啟、主機(jī)下線從機(jī)頂替等功能。
但就算實現(xiàn)了高可用的Nginx依舊存在一個致命問題:如果項目的QPS超出5W,那么很有可能會導(dǎo)致Nginx被流量打到宕機(jī),然后根據(jù)配置的高可用規(guī)則,Keepalived會對Nginx重啟,但重啟后的Nginx依舊無法承載業(yè)務(wù)帶來的并發(fā)壓力,結(jié)果同樣會宕機(jī).....
經(jīng)過如上分析后,明顯可看出,如果Nginx面對這種超高并發(fā)的情況,就會一直處于「在重啟、去重啟的路上」這個過程不斷徘徊,因此在此背景下,我們需要設(shè)計出一套能承載更大流量級別的接入層架構(gòu)。
不過相對來說,至少90%以上的項目用不上這套接入層架構(gòu),因為大部分項目上線后,能夠擁有的用戶數(shù)是很有限的,壓根無法產(chǎn)生太高的并發(fā)量,所以往往一個Nginx足以支撐系統(tǒng)的訪問壓力。
不過雖說大家不一定用得上,但不懂兩個字我們絕不能說出口,尤其是面試過程中,往往頻繁問到的:你是如何處理高并發(fā)的? 跟本文有很大的聯(lián)系,之后被問到時,千萬先別回答什么緩存、削峰填谷、熔斷限流、分庫分表.....等這類的,首先需要先把接入層說清楚,因為如果接入層都扛不住訪問壓力,流量都無法進(jìn)到系統(tǒng),后續(xù)這一系列處理手段自然沒有意義。
一、億級吞吐第一戰(zhàn)-DNS輪詢解析
對于單節(jié)點的Nginx而言,雖然利用Keepalived實現(xiàn)了高可用,但它更類似于一種主從關(guān)系,從機(jī)在主機(jī)正常的情況下,并不能為主機(jī)分擔(dān)訪問壓力,也就代表著作為主節(jié)點的機(jī)器,需要憑“一己之力”承載整個系統(tǒng)的所有流量。那么當(dāng)系統(tǒng)流量超出承載極限后,很容易導(dǎo)致Nginx宕機(jī),所以也需要對Nginx進(jìn)行橫向拓展,那又該如何實現(xiàn)呢?最簡單的方式:DNS輪詢解析方案。
DNS輪詢解析技術(shù)算一種較老的方案了,但在如今的大舞臺上依舊能夠看見它的身影,它源自于DNS的域名多記錄解析,在《HTTP/HTTPS》文章中曾聊到過,DNS域名系統(tǒng)本質(zhì)上是一個大型的分布式K-V數(shù)據(jù)庫,以域名作為Key,以物理服務(wù)器的公網(wǎng)IP作為Value,而大多數(shù)域名注冊商都支持為同一個域名配置多個對應(yīng)的IP,如下:
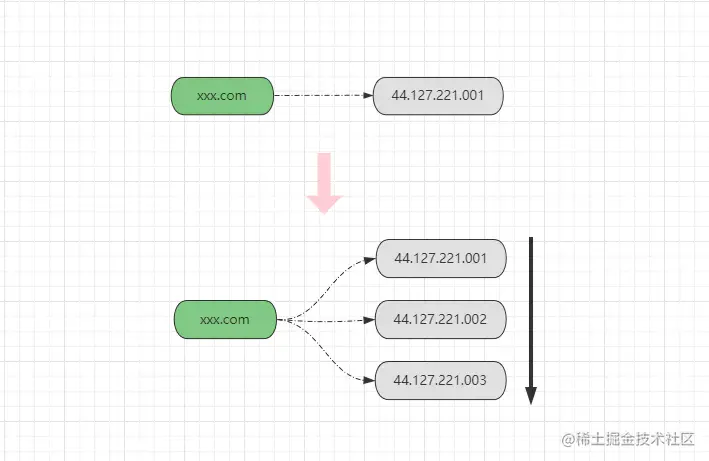
如上圖所示,為一個域名配置多個映射的IP后,DNS服務(wù)器在解析域名請求時,就會依據(jù)配置的IP順序,將請求逐一分配到不同的IP上,也就是《上文》所提及到的輪詢調(diào)度方式。
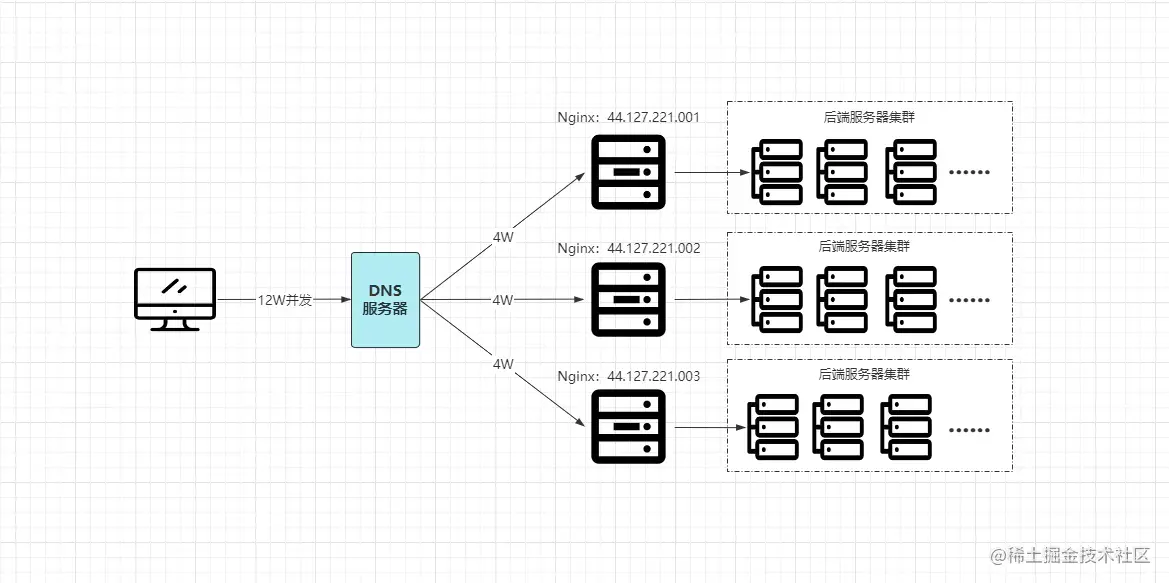
借助DNS的輪詢解析支持,對Nginx可以輕松實現(xiàn)橫向拓展,也就是同一個域名配置的多臺物理機(jī),分別都部署一個Nginx節(jié)點,每臺Nginx節(jié)點的配置信息都一樣。
好比目前每瞬12W的并發(fā)量,配置域名時,映射3臺真實Nginx服務(wù)器,最終經(jīng)過DNS輪詢解析后,12W的并發(fā)請求被均攤到每臺Nginx,每個節(jié)點分別承載4W的并發(fā)請求,通過這種方式就能夠完美的解決之前的:單節(jié)點Nginx無法承載超高并發(fā)量而宕機(jī)的問題,如下:
![Nginx水平集群]
同時DNS域名解析,也依舊可以配置調(diào)度算法,如Rate權(quán)重分配、最少連接數(shù)分配、甚至可以按照客戶端網(wǎng)絡(luò)的運營商、客戶端所在地區(qū)等方式進(jìn)行解析分配,但僅一小部分的DNS服務(wù)器支持。
淺談DNS域名輪詢解析的優(yōu)劣
這種方式帶來的優(yōu)勢極為明顯:
無需增加額外的成本即可實現(xiàn)多節(jié)點水平集群,利于系統(tǒng)拓展。
但也存在非常大的劣勢:
- ①與其他的負(fù)載均衡方案不同,其他的負(fù)載方案一般都會自帶健康監(jiān)測機(jī)制,但DNS則無法感知,也就是當(dāng)下游的某服務(wù)器宕機(jī),DNS服務(wù)器會依舊向其分發(fā)請求。
- ②無法根據(jù)服務(wù)器的硬件配置,合理的分配客戶端請求,大部分DNS服務(wù)器只支持最簡單的輪詢調(diào)度。
雖然DNS輪詢解析方案存在很大的劣勢,但這兩個劣勢對比其帶來的收益可以忽略不計,因為現(xiàn)在云計算技術(shù)的發(fā)展,多臺節(jié)點保持相同的配置已不再是難事。同時,由于Nginx本身就會利用Keepalived的VIP機(jī)制實現(xiàn)高可用,所以就算某個節(jié)點宕機(jī),從機(jī)也可頂替上線接管流量,中間只會有很短暫的切換時間。
而且如果DNS將客戶端請求分發(fā)到某個宕機(jī)節(jié)點時,客戶端看到的結(jié)果便是空白頁、超時無響應(yīng)或請求錯誤的信息,通常情況下,依據(jù)用戶的習(xí)性,都會再次重試,那么客戶端再次發(fā)出的請求會被輪詢解析到其他節(jié)點,而從機(jī)在這個時間間隔內(nèi)也能夠成功上線接管服務(wù)。
二、億級吞吐第二戰(zhàn)-CDN內(nèi)容分發(fā)
CDN(Content Delivery.NETwork)內(nèi)容分發(fā)網(wǎng)絡(luò)是一種構(gòu)建在現(xiàn)有網(wǎng)絡(luò)基礎(chǔ)上的智能虛擬網(wǎng)絡(luò),依靠部署在全球各地的節(jié)點,通過負(fù)載均衡、內(nèi)容分發(fā)、機(jī)器調(diào)度等功能,使用戶的請求能夠被分發(fā)到離自身最近的節(jié)點處理,就近獲取所需的資源,最終達(dá)到提升用戶訪問速度以及降低服務(wù)器訪問壓力等目的。
CDN出現(xiàn)的本質(zhì)是為了解決不同地區(qū)用戶訪問速度不一致問題,在之前的《TCP/IP》文中曾提到過,網(wǎng)絡(luò)上的數(shù)據(jù)傳輸本質(zhì)上最終都會依賴于物理層的傳輸介質(zhì),那么當(dāng)用戶和目標(biāo)服務(wù)器的“實際地理距離”越長,訪問的速度自然會越慢,而CDN的核心就在于:各地區(qū)都會部署子節(jié)點,當(dāng)用戶訪問時,會將其請求分發(fā)到距離最近的節(jié)點處理,就好比生活中的例子:
某個想吃北京烤鴨的人身在美國,最初僅北京有相應(yīng)的店鋪,因此想吃的時候必須得跑到北京去買,那么這一去一回的過程自然會需要很長時間,而CDN的思想就是在各地都開分店,好比美國也有北京烤鴨的分店,當(dāng)某個用戶想吃時,不再需要跑到北京去買,而是可以直接選擇就近的店鋪進(jìn)行購買,這樣速度自然會更快。
2.1、CDN分發(fā)的內(nèi)容
通常一個平臺的資源都會分為靜態(tài)與動態(tài)兩種類型,而CDN本質(zhì)上是一種類似于緩存的技術(shù),緩存必然會存在延遲性,對于會經(jīng)常發(fā)生變化的動態(tài)資源,使用CDN意義并不大,因為CDN無法確保數(shù)據(jù)的實時性。
由于靜態(tài)資源很少發(fā)生變更,所以CDN一般會用于靜態(tài)資源的分發(fā),如果你要使用CDN服務(wù),國內(nèi)有大量的CDN提供商提供這類服務(wù),當(dāng)購買CDN服務(wù)后,將靜態(tài)資源傳給CDN服務(wù),那么這些靜態(tài)資源將自動的被分發(fā)到提供商全球各地的CDN節(jié)點。
2.2、CDN實現(xiàn)原理
在系統(tǒng)接入CDN服務(wù)并將靜態(tài)資源傳遞給CDN后,那么當(dāng)用戶再訪問系統(tǒng)時,對應(yīng)的一些請求就會被分發(fā)到距離用戶最近的CDN節(jié)點處理,但這究竟是如何實現(xiàn)的呢?接下來簡單聊一聊。
一般用戶發(fā)送請求都是通過域名去進(jìn)行訪問的,域名最終會被解析成一個IP,那么如何解析出一個距離用戶最近的服務(wù)器IP,這是普通的DNS服務(wù)器做不到的,因此CDN為了實現(xiàn)這點,需要特殊的DNS服務(wù)器去解析域名請求,該DNS服務(wù)器需要解決兩個問題:
①需要得知用戶目前的所在位置。
②CDN所有節(jié)點中,哪個節(jié)點離用戶最近。
對于上述兩個問題,第一個問題可以直接從用戶的請求中提取客戶端IP,然后根據(jù)IP去判斷,可以將IP解析為上海電信、北京移動等,從而能夠確定用戶的大概位置。
第一個問題容易找到答案,但實現(xiàn)CDN請求分發(fā)的難點在于第二個問題:如何確定距離用戶最近的CDN節(jié)點。這時就需要用到DNS解析中的CNAME機(jī)制了,DNS域名解析主要會分為兩種:
- ①將一個域名解析為一個具體的IP,這種方式被稱為A記錄機(jī)制。
- ②將一個域名解析為另一個域名,這種方式就被稱為CNAME機(jī)制。
在CDN中,這個CNAME會被配置為CDN專用DNS服務(wù)器的域名地址。
某個用戶通過域名static.xxx.com請求靜態(tài)資源時,這個域名會映射著一個CNAME,例如cdn.xxx.com,當(dāng)普通的DNS服務(wù)器收到用戶的static.xxx.com域名請求后,經(jīng)過解析得到一個CNAME,該CNAME對應(yīng)的則是CDN專用的DNS服務(wù)器,那么會將域名解析工作轉(zhuǎn)交給該DNS服務(wù)器處理,CDN專用DNS服務(wù)器對cdn.xxx.com域名解析,根據(jù)服務(wù)器上記錄著的所有CDN節(jié)點信息,選出距離用戶最近的CDN服務(wù)器地址并返回給用戶,最后用戶就可通過該地址訪問距離自己最近的CDN節(jié)點。
上述這個過程也被稱為智能DNS解析技術(shù)。
2.3、CDN帶來的優(yōu)勢
大致聊了CDN分發(fā)原理后,再來思考思考CDN的引入能夠給系統(tǒng)帶來哪些好處呢?
- ①加快用戶的訪問速度,帶來更好的用戶體驗感。
- ②分擔(dān)系統(tǒng)50%以上的訪問流量,降低系統(tǒng)的負(fù)載壓力。
- ③節(jié)省系統(tǒng)源站的帶寬消耗,降低網(wǎng)絡(luò)帶寬的成本。
- ④進(jìn)一步提升系統(tǒng)安全性,大部分攻擊請求會被CDN節(jié)點阻擋。
從上看來,系統(tǒng)接入CDN服務(wù)后帶來的收益很大,就算原本的系統(tǒng)訪問速度很慢,在接入CDN后也能夠快速加載,對于用戶而言體驗感會進(jìn)一步提升,并且最關(guān)鍵的是:對于網(wǎng)站整體而言,幾乎90%以上的靜態(tài)請求會由CDN去響應(yīng),系統(tǒng)源站能夠減輕很大的訪問壓力,從而能夠確保系統(tǒng)本身擁有更大的“動態(tài)請求”吞吐能力。
三、億級吞吐第三戰(zhàn)-LVS負(fù)載均衡
在之前提到過,我們可以通過DNS的輪詢解析機(jī)制對Nginx實現(xiàn)水平拓展,從而使得接入層能夠承擔(dān)更高的并發(fā)訪問,但DNS由于其機(jī)制的不健全,所以一般并不會采用它去實現(xiàn)Nginx的集群,畢竟動態(tài)伸縮也不方便,更改配置后需要3~4小時才能生效。
如果要對Nginx實現(xiàn)集群,一般都會采用LVS去實現(xiàn),也包括淘寶、騰訊等大部分企業(yè),都使用了LVS技術(shù),那什么是LVS呢?

LVS是linux Virtual Server的簡稱,意為Linux虛擬服務(wù)器,本項目在1998年5月由章文嵩博士成立,在Linux2.6版本中被正式加入系統(tǒng)內(nèi)核,關(guān)于更多可參考:《LVS-百度百科》。
LVS一般被用作于負(fù)載調(diào)度器,它與Nginx的功能類似,但不同點在于:LVS工作在OSI七層網(wǎng)絡(luò)模型中的第四層-網(wǎng)絡(luò)層,而Nginx則是工作在第七層-應(yīng)用層,同時LVS并非是以進(jìn)程的方式運行在操作系統(tǒng)上的,而是直接位于Linux內(nèi)核中工作,因此LVS的性能一般是Nginx的十倍以上。
其實在很多大型互聯(lián)網(wǎng)企業(yè)中,都能看見LVS的身影,例如淘寶的接入層設(shè)計、阿里云中的SLB-CLB四層負(fù)載均衡服務(wù)等都是基于LVS實現(xiàn)的。
LVS相較于其他軟件負(fù)載均衡技術(shù)(Nginx、HaProxy)的特點:
- ①工作在網(wǎng)絡(luò)層,位于系統(tǒng)內(nèi)核,擁有更高的性能、可用性。
- ②能夠?qū)⒃S多低性能的服務(wù)器組合在一起形成一個高性能的超級服務(wù)器群。
- ③擁有四種工作模式以及十二種調(diào)度算法,適用于各類不同的業(yè)務(wù)場景。
- ④擁有健全的節(jié)點健康監(jiān)測機(jī)制,并且擁有很強(qiáng)的拓展性,支持動態(tài)伸縮。
同時在LVS中存在大量專業(yè)術(shù)語,如下:
- Director:負(fù)載均衡器,指LVS本身。
- Balancer:請求分發(fā)器,也指LVS本身。
- Real Server(RS):后端負(fù)責(zé)請求處理的服務(wù)器。
- Client IP(CIP):客戶端的IP地址。
- Virtural IP(VIP):虛擬IP地址。
- Director IP(DIP):LVS所在的服務(wù)器IP地址。
- Real Server IP(RIP):后端服務(wù)器的IP地址。
LVS基本工作原理
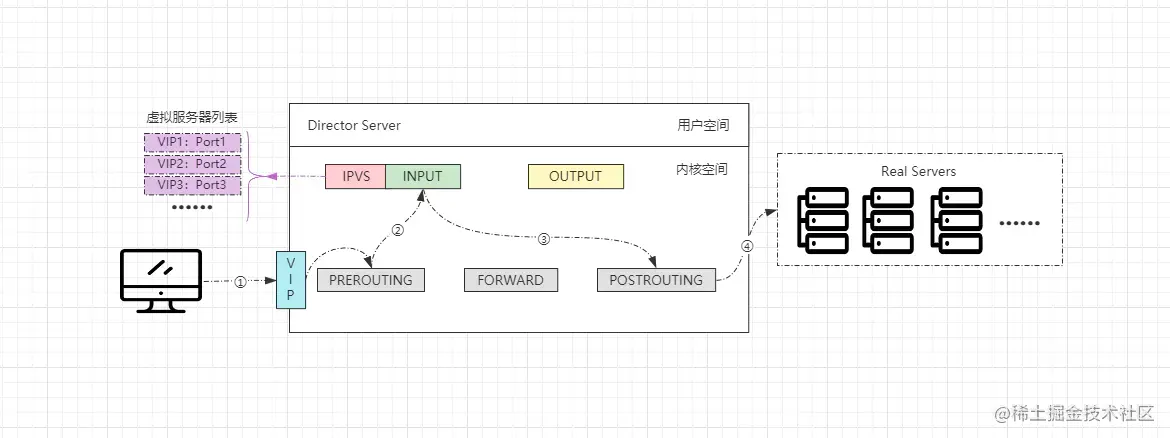
- ①客戶端通過訪問VIP發(fā)送請求報文,調(diào)度器收到后會將其發(fā)往內(nèi)核空間。
- ②內(nèi)核中的PREROUTING鏈會先收到請求,確認(rèn)是發(fā)往自己的請求后會轉(zhuǎn)給INPUT鏈。
- ③ip_vs是工作在INPUT鏈上的,IPVS會將用戶請求和VIP列表進(jìn)行匹配,匹配成功后會修改請求報文中的目的地址及端口,然后將新的報文發(fā)給POSTROUTING鏈。
- ④POSTROUTING鏈?zhǔn)盏綀笪暮螅l(fā)現(xiàn)更改后的報文中目標(biāo)地址正好是自己配置的后端服務(wù)器RS地址,那此時就會通過選路,最終將數(shù)據(jù)報文發(fā)送給后端服務(wù)器。
OK~,對于LVS有了一點基本認(rèn)識之后,接著來看看LVS中四種工作模式以及十二種調(diào)度算法。
3.1、LVS四種工作模式
在LVS中,為了適應(yīng)不同的應(yīng)用場景,因此也專門研發(fā)了多種不同的工作模式,每種工作模式都有各自的應(yīng)用場景,LVS中共計存在四種工作模式: NAT、DR、TUN、FULL-NAT,其中最為常用的是DR直接路由模式,接下來詳細(xì)剖析看看。
3.1.1、網(wǎng)絡(luò)地址轉(zhuǎn)換模式(NAT)
NAT模式與帶有防火墻的私有網(wǎng)絡(luò)結(jié)構(gòu)類似,LVS作為所有后端服務(wù)器節(jié)點的網(wǎng)關(guān)層,客戶端請求與后端服務(wù)器的響應(yīng)都會經(jīng)過LVS,LVS在整個接入層中作為客戶端的訪問入口,作為服務(wù)端的返回出口,后端服務(wù)器位于內(nèi)網(wǎng)環(huán)境,使用私有IP地址,與LVS位于同一物理網(wǎng)段,如下:
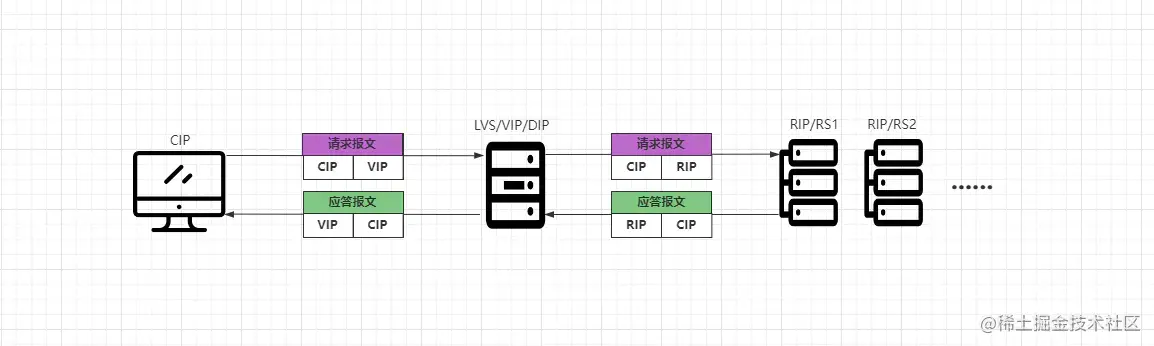
- ①客戶端CIP請求VIP,VIP即DIP,也就是LVS本身。
- ②LVS將客戶端請求報文中的目標(biāo)地址改為后端一臺具體的RIP地址。
- ③RS將請求處理完成后,會將響應(yīng)結(jié)果組裝成應(yīng)答報文返回給LVS。
- ④LVS收到后端的響應(yīng)數(shù)據(jù)后,會將響應(yīng)報文中的目標(biāo)地址改為自身的VIP。
在NAT模式中,由于請求/應(yīng)答的雙向流量都需要經(jīng)過LVS,因此對于LVS的性能、帶寬開銷比較大,同時需要注意:如果采用NAT模式,那么DIP、RIP必須要在同一個物理網(wǎng)絡(luò)中。
3.1.2、直接路由模式(DR)
DR模式中,是采用半開放式網(wǎng)絡(luò)結(jié)構(gòu)實現(xiàn)的,后端的各節(jié)點與LVS位于同一個物理網(wǎng)絡(luò),LVS在其中作為客戶端的訪問入口,但服務(wù)端返回響應(yīng)時則不需要經(jīng)過LVS,而是直接把數(shù)據(jù)響應(yīng)給客戶端,如下:
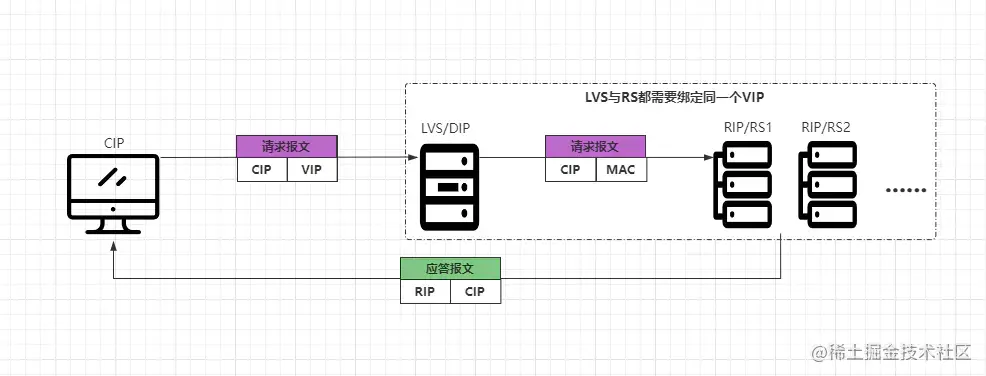
- ①客戶端CIP請求VIP,請求報文中CIP為源地址,VIP為目標(biāo)地址。
- ②請求會先到LVS上,LVS會將報文中的目標(biāo)mac地址改變?yōu)槟撑_RS的MAC地址。
- ③RS收到請求后發(fā)現(xiàn)是自己的MAC地址,并且也是自己的IP地址,則會處理請求。
- ④RS處理完成請求后,會根據(jù)請求報文中的源地址,直接將應(yīng)答報文返回給CIP。
在DR模式中,很明顯的可以看出,客戶端請求的流量會通過LVS作為入口,但服務(wù)端的應(yīng)答流量卻不用通過LVS作為出口。因為在DR模式中,LVS與后端的RS都會綁定同一個VIP,然后LVS會通過修改目標(biāo)MAC地址的方式實現(xiàn)請求分發(fā),當(dāng)RS收到請求后,發(fā)現(xiàn)目標(biāo)MAC、IP地址都是自己后,就會開始處理請求。
在這個過程中,由于客戶端請求的是VIP地址,而LVS、RS都綁定相同的VIP,所以LVS改掉目標(biāo)MAC地址,轉(zhuǎn)發(fā)請求后,在RS角度來看是無法感知的,畢竟自己的IP就是請求報文中的VIP,所以RS會認(rèn)為該請求就是客戶端直接請求自己的。
當(dāng)RS將客戶端的請求處理完成之后,會根據(jù)請求報文中的源IP地址,作為應(yīng)答報文的目標(biāo)IP地址,直接將響應(yīng)結(jié)果返回給客戶端,無需經(jīng)過LVS再次包裝,這樣能夠很好的解決之前NAT模式中存在的不足。
3.1.3、IP隧道模式(TUN)
TUN模式是采用開放式網(wǎng)絡(luò)結(jié)構(gòu),服務(wù)端的各節(jié)點可以不與LVS位于同一網(wǎng)絡(luò),也就是后端服務(wù)器可以分散在互聯(lián)網(wǎng)中的不同網(wǎng)絡(luò)中,但每個后端節(jié)點必須要有獨立的公網(wǎng)IP,因為LVS需要通過專用的IP隧道與后端節(jié)點相互通信。其中LVS主要作為客戶端的訪問入口,服務(wù)器響應(yīng)結(jié)果時,直接通過各自的Internet連接返回給客戶端,不需要經(jīng)過LVS,如下:
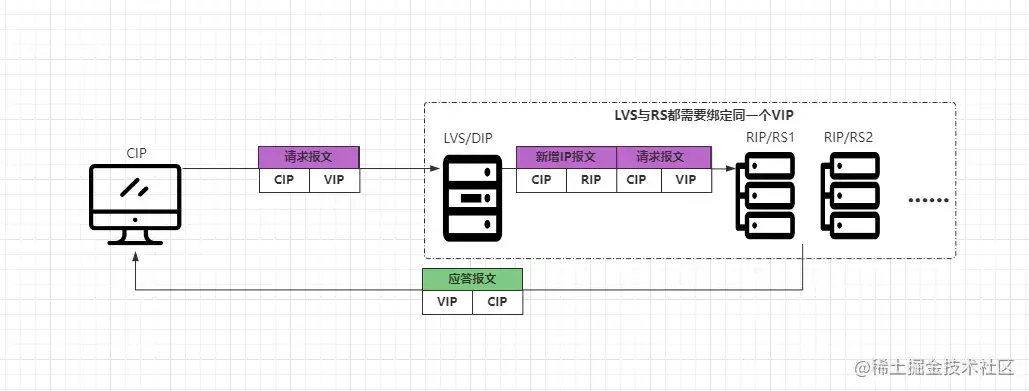
- ①客戶端發(fā)送請求報文到LVS服務(wù)器,報文源IP為CIP,目標(biāo)IP為VIP。
- ②LVS收到請求報文后,不會再修改報文內(nèi)容,而是在報文前面再添加一個IP報文頭。 新增的IP報文中源地址為CIP,目標(biāo)地址為一臺具體的RIP。
- ③RS收到新封裝的報文后,會解封數(shù)據(jù)報,然后處理客戶端請求。
- ④處理完成后會根據(jù)請求報文中的源IP:CIP,將應(yīng)答報文直接返回給客戶端。
從上述過程中會發(fā)現(xiàn),TUN模式似乎與之前的DR模式有些類似,但與DR模式不同的是:TUN模式是基于IP隧道技術(shù)實現(xiàn)的,并且整個LVS集群中的所有節(jié)點,都可以不在一個物理網(wǎng)絡(luò)中,也就是LVS、RS可以是分散在各地的服務(wù)器,但需要額外注意:VIP、DIP、RIP必須全部要為公網(wǎng)IP,不然無法使用IP隧道機(jī)制。
3.1.4、雙向網(wǎng)絡(luò)地址轉(zhuǎn)換模式(FULL-NAT)
FULL-NAT模式在之前的版本中是不存在的,這個模式是章文嵩博士去了阿里之后,專門針對于阿里的業(yè)務(wù)研發(fā)的一種新模式,它是NAT模式的升級版本,在NAT模式中只做兩次IP轉(zhuǎn)換,而FULL-NAT模式會做四次,如下:
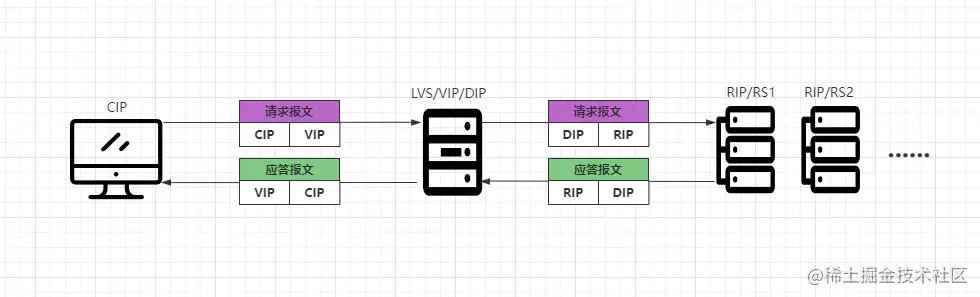
- ①客戶端會先發(fā)送請求報文到LVS,報文中源IP為CIP,目標(biāo)IP為VIP。
- ②LVS收到客戶端的報文后,會將源地址改為自身的DIP,并將目標(biāo)IP改為RIP。
- ③RS接收到請求后會進(jìn)行處理,處理完成之后會將應(yīng)答報文返回給LVS服務(wù)器。
- ④LVS會將應(yīng)答報文中的源IP改為VIP,目標(biāo)IP為CIP,從而將數(shù)據(jù)響應(yīng)給客戶端。
在FULL-NAT模式中,一共會做四次IP的轉(zhuǎn)換,那為何要這樣實現(xiàn)呢?因為之前的NAT模式中,DIP、VIP、RIP都必須要位于同一個VLAN物理網(wǎng)絡(luò)中,那么此時就會導(dǎo)致RS集群的主機(jī)數(shù)量受到限制。
在FULL-NAT模式中,LVS收到客戶端請求后,會將報文中的源地址改為自身的DIP,并將目標(biāo)IP改為RIP,這樣對于RS而言,DIP就成了客戶端,因此可以實現(xiàn)跨VLAN、跨機(jī)房、跨網(wǎng)絡(luò)進(jìn)行請求分發(fā)。
當(dāng)RS處理完對應(yīng)的請求后,會將數(shù)據(jù)返回到LVS,LVS又會將應(yīng)答報文中的源IP改為VIP,目標(biāo)IP為CIP,從而由LVS作為響應(yīng)者返回數(shù)據(jù)。
當(dāng)然,F(xiàn)ULL-NAT模式雖然能夠?qū)崿F(xiàn)跨網(wǎng)絡(luò)分發(fā),但由于其中進(jìn)行了多次IP轉(zhuǎn)換,因此對比普通的NAT模式而言,分發(fā)的效率要降低10%左右。
3.1.5、四種工作模式對比
|
對比項 |
NAT |
DR |
TUN |
FULL-NAT |
|
分發(fā)性能 |
NO.03 |
NO.01 |
NO.2 |
NO.4 |
|
網(wǎng)絡(luò)結(jié)構(gòu) |
封閉式網(wǎng)絡(luò) |
半開放式網(wǎng)絡(luò) |
開放式網(wǎng)絡(luò) |
半開放式網(wǎng)絡(luò) |
|
數(shù)據(jù)響應(yīng) |
LVS |
RS |
RS |
LVS |
|
轉(zhuǎn)發(fā)實現(xiàn) |
改目標(biāo)IP |
改目標(biāo)MAC |
新增IP數(shù)據(jù)報 |
重構(gòu)IP數(shù)據(jù)報 |
|
使用限制 |
局域網(wǎng)絡(luò) |
綁定同一VIP |
需支持Tunneling |
RS與LVS要能通信 |
|
模式特點 |
內(nèi)外網(wǎng)隔離 |
性能最佳 |
遠(yuǎn)距離分發(fā) |
可跨網(wǎng)絡(luò)分發(fā) |
在LVS的四種工作模式中,DR是性能最好的,也是正常情況下使用最為頻繁的工作模式,同時也是LVS默認(rèn)的工作模式。
3.2、LVS十二種調(diào)度算法
與其他的負(fù)載調(diào)度技術(shù)相同,在LVS中也提供了多種調(diào)度算法,主要也分為兩大類:靜態(tài)調(diào)度以及動態(tài)調(diào)度算法,兩類算法共計十二種,如下:
- 靜態(tài)調(diào)度算法: 輪詢算法(RR) 加權(quán)輪詢算法(WRR) 源地址哈希算法(SH) 目標(biāo)地址哈希算法(DH)
- 動態(tài)調(diào)度算法: 最小連接數(shù)算法(LC) 加權(quán)最小連接數(shù)算法(WLC) 最短延遲算法(SED) 最少隊列算法(NQ) 局部最少連接數(shù)算法(LBLC) 帶復(fù)制的局部最少連接數(shù)算法(LBLCR) 加權(quán)故障轉(zhuǎn)移算法(FO) 加權(quán)活動連接數(shù)算法(OVF)
其中動態(tài)算法對比靜態(tài)算法而言會更為智能化,但分發(fā)效率也會更低,接下來簡單看看LVS中提供的每種調(diào)度算法。
不會對每種算法進(jìn)行原理剖析,大致分析其過程和思想,如想要了解調(diào)度算法具體實現(xiàn)的小伙伴可參考上篇:《網(wǎng)絡(luò)編程之請求分發(fā)篇》。
3.2.1、輪詢算法(RR)
輪詢算法在LVS中也被稱為輪叫、輪調(diào)算法,但本質(zhì)上意思都是相同的,對于配置的多個服務(wù)端節(jié)點,依次分發(fā)請求處理。
在這種算法中,分發(fā)請求時講究雨露均沾,會對配置的所有節(jié)點無差別的依次調(diào)度。
具體實現(xiàn)可參考《請求分發(fā)篇-輪詢算法實現(xiàn)》。
3.2.2、加權(quán)輪詢算法(WRR)
這種算法屬于輪詢算法的升級版本,主要是為了照顧到集群中硬件配置不同的節(jié)點,根據(jù)服務(wù)器自身的硬件基礎(chǔ),為不同服務(wù)器配置不同的權(quán)重值,性能越好的服務(wù)器配置越高的權(quán)重值,LVS在分發(fā)請求時,會根據(jù)配置的權(quán)重值,分發(fā)對應(yīng)比例的請求數(shù)到每臺服務(wù)器。
這種算法相較于基本的輪詢調(diào)度而言,更加智能化一些,因為能夠根據(jù)節(jié)點的性能去配置對應(yīng)權(quán)重,能夠在最大程度上將每臺服務(wù)器的性能發(fā)揮到極致。
具體實現(xiàn)可參考《請求分發(fā)篇-平滑加權(quán)輪詢算法實現(xiàn)》。
3.2.3、源地址哈希算法(SH)
之前的兩種調(diào)度算法,都無法解決session不一致問題:
session不一致問題:好比最簡單的登錄功能,客戶端發(fā)送請求登錄成功,然后將其登錄的狀態(tài)保存在session中,結(jié)果客戶端的第二次請求被分發(fā)到了另外一臺機(jī)器,由于第二臺服務(wù)器session中沒有相關(guān)的登錄信息,因此會要求客戶端重新登錄。
而源地址哈希算法中,LVS會根據(jù)請求報文中的源IP地址進(jìn)行哈希計算,然后最終計算出一臺服務(wù)器的IP,并將該請求分發(fā)到對應(yīng)的節(jié)點處理,同時由于分發(fā)請求是基于哈希算法實現(xiàn)的,那么之后每當(dāng)相同的客戶端請求時,由于源IP地址是相同的,所以同一客戶端的請求都會被分發(fā)到同一臺服務(wù)器處理。
3.2.4、目標(biāo)地址哈希算法(DH)
與源地址哈希算法相同,目標(biāo)地址哈希算法也是一種基于哈希算法實現(xiàn)的,但該算法中是基于目標(biāo)地址作為哈希條件去進(jìn)行計算,從而計算出一臺的具體服務(wù)器地址,最后將對應(yīng)的請求轉(zhuǎn)發(fā)到對應(yīng)節(jié)點處理。
需要額外注意的是:這里的目標(biāo)地址并非指請求報文中的目標(biāo)IP地址,因為本質(zhì)上客戶端都是通過請求相同的VIP來訪問LVS的,所以請求報文中的目標(biāo)IP地址都是相同的,要是基于目標(biāo)IP地址去計算,那么會將所有請求都分發(fā)到一個節(jié)點上。
既然不是通過請求報文中的目標(biāo)IP地址進(jìn)行計算,那這里所謂的“目標(biāo)地址”究竟是什么呢?要搞清楚這個點之前,首先得理解DH算法的應(yīng)用場景,一般DH算法都是應(yīng)用在緩存場景中的,所以這里的“目標(biāo)地址”其實是緩存的目標(biāo)Key值,舉例:
請求①:put name '竹子'
請求②:get name
復(fù)制代碼
在上述案例中,請求①是寫入操作,其Key為name,DH算法會以該值作為哈希計算的條件,從而算出一臺服務(wù)器地址,并將其該Key值的緩存項寫入到該節(jié)點中。請求②則是一個讀取操作,由于讀取的目標(biāo)為name,與之前寫入操作的Key相同,那么DH算法計算之后,最終得到的服務(wù)器地址也是相同的,就會將這個讀取請求分發(fā)到之前寫入緩存的節(jié)點,確保能夠命中數(shù)據(jù)。
對于兩種哈希算法的具體實現(xiàn)可參考《請求分發(fā)篇-一致性哈希算法實現(xiàn)》。
3.2.5、最小連接數(shù)算法(LC)
最小連接數(shù)算法,也可以被稱為最小活躍數(shù)算法、最空閑節(jié)點算法等,該算法屬于動態(tài)算法的一種,相較于之前的四種靜態(tài)算法,該算法更為智能化,在這種算法中可以根據(jù)所有節(jié)點的負(fù)載情況,進(jìn)行“相對合理”的請求分發(fā),永遠(yuǎn)都會選取最為空閑的那臺服務(wù)器來處理請求。
如果存在多個連接數(shù)都為最小的節(jié)點,則是類似于輪詢的方式去依次調(diào)度。
這種算法中,能夠根據(jù)線上各服務(wù)器的實際運行情況分發(fā)請求,能夠?qū)⒓褐?ldquo;做事最少的節(jié)點揪出來”處理請求,從而做到“杜絕任何服務(wù)器出現(xiàn)摸魚情況”。
3.2.6、加權(quán)最小連接數(shù)算法(WLC)
LC、WLC算法的關(guān)系就類似于之前的輪詢和加權(quán)輪詢算法,加權(quán)最小連接數(shù)算法是最小連接數(shù)算法的升級版本,也就是說可以為每個節(jié)點配置權(quán)重,當(dāng)尋找連接數(shù)最小的節(jié)點時,如果集群中存在多個連接數(shù)都為最小的節(jié)點,那最終就會根據(jù)配置的權(quán)重值,來決定當(dāng)前請求具體交由誰處理。
在Dubbo的負(fù)載均衡-最小活躍數(shù)算法的實現(xiàn)中,實現(xiàn)的就是加權(quán)最小活躍數(shù)版本。
對于最小連接數(shù)算法的具體實現(xiàn)感興趣的小伙伴可參考《請求分發(fā)篇-最小活躍數(shù)算法實現(xiàn)》。
3.2.7、最短預(yù)期延遲算法(SED)
最短預(yù)期延遲算法是基于WLC算法實現(xiàn)的,WLC算法中,如果權(quán)重值和連接數(shù)都相同,那么會隨機(jī)調(diào)度一個節(jié)點處理請求,這顯然還并沒有那么那么“智能”,因此SED算法的出現(xiàn)就是為了解決該問題。
在WLC算法中衡量連接數(shù)標(biāo)準(zhǔn)是綜合考慮所有連接數(shù)的,而SED算法中則只考慮活動連接數(shù),也就是說SED算法只會選擇活動連接數(shù)最小的節(jié)點,這樣能夠確保選擇的節(jié)點將會是整個集群中,預(yù)期延遲最短的RS,因為活動連接數(shù)最小,所以也就代表著該節(jié)點實際負(fù)載最低,那么響應(yīng)速度也就最快。
3.2.8、最少隊列算法(NQ)
最少隊列算法也被稱為永不排隊算法,這種算法又是基于SED算法實現(xiàn)的,NQ算法在SED算法的基礎(chǔ)上,實現(xiàn)了一個活躍連接數(shù)為0的判斷,當(dāng)有節(jié)點的活躍連接數(shù)為0時,那么無需經(jīng)過SED運算,而是將請求直接分發(fā)過去,在沒有節(jié)點活躍數(shù)為0的情況下,正常使用SED算法分發(fā)請求,
LC、WLC、SED、NQ四種算法,本質(zhì)上都是遞進(jìn)的關(guān)系,后面的每種算法都基于之前的算法不足,然后優(yōu)化后并推出的,最終的目的則是:讓請求分發(fā)時更為智能,選擇出的節(jié)點永遠(yuǎn)都是性能最好的。
不過在上篇文章中,我們也提到了另外一種更為智能的最優(yōu)響應(yīng)算法,該算法在開始前,會對服務(wù)列表中的各節(jié)點發(fā)出一個探測請求,然后根據(jù)各節(jié)點的響應(yīng)時間來決定由哪臺服務(wù)器處理客戶端請求,該算法能更好根據(jù)節(jié)點列表中每臺機(jī)器的當(dāng)前運行狀態(tài)分發(fā)請求,具體實現(xiàn)可參考《請求分發(fā)篇-最優(yōu)響應(yīng)算法實現(xiàn)》。
3.2.9、局部最少連接數(shù)算法(LBLC)
局部最少連接數(shù)算法其實比較雞肋,屬于DH算法的動態(tài)版本,相對來說使用的也較少,在該算法中會基于請求的目標(biāo)地址進(jìn)行分發(fā),首先根據(jù)其目標(biāo)地址找出該目標(biāo)地址最近使用的服務(wù)器,如若對應(yīng)的服務(wù)器目前可用并沒有超載,就直接將該請求分發(fā)到這臺服務(wù)器處理。如若找出的服務(wù)器不可用或請求負(fù)載過高,則根據(jù)LC算法找出集群中連接數(shù)最小的節(jié)點,并將該請求分發(fā)過去。
3.2.10、帶復(fù)制的局部最少連接數(shù)算法(LBLCR)
LBLCR算法也就是基于LBLC算法的升級版本,與LBLC算法的不同點在于:該算法會維護(hù)一個目的地址與一組服務(wù)器的映射表,而LBLC算法中只會維護(hù)目的地址與一個服務(wù)器的映射關(guān)系。
在LBLCR算法中,會根據(jù)請求的目標(biāo)地址先找到映射的一組服務(wù)器,然后根據(jù)最少連接數(shù)算法從該組服務(wù)器中,選出一臺節(jié)點處理請求,如若選擇的節(jié)點不可用或負(fù)載過高,則會去RS集群中再根據(jù)LC算法選擇一個節(jié)點,然后加入映射的服務(wù)器組中,并將請求分發(fā)到該服務(wù)器。
同時,如果映射的服務(wù)器組很長一段時間內(nèi)都沒被修改過,那會自動將“最忙”的服務(wù)器移除。
DH、LBLC、LBLCR算法一般都是用于Cache集群環(huán)境中,但目前用的也比較少,因為一般的緩存中間件都有成熟的集群方案,除非需要自研緩存集群時,才會用到LVS這些算法作為緩存分發(fā)策略。
3.2.11、加權(quán)故障轉(zhuǎn)移算法(FO)
加權(quán)故障轉(zhuǎn)移算法中,首先會遍歷所有的RS節(jié)點列表,然后從中找到負(fù)載較低且權(quán)重值最高的服務(wù)器,并將請求分發(fā)到該服務(wù)器上處理。
對于負(fù)載過高的服務(wù)器,LVS會對其設(shè)置一個IP_VS_DEST_F_OVERLOAD標(biāo)識,這里說的“找到負(fù)載較低的服務(wù)器”,即代表著找到未設(shè)置IP_VS_DEST_F_OVERLOAD標(biāo)識的節(jié)點。
3.2.12、加權(quán)活動連接數(shù)算法(OVF)
加權(quán)活動連接數(shù)算法是基于服務(wù)器的活動連接數(shù)與權(quán)重值實現(xiàn)的,在該算法中會首先找到權(quán)重值最高的可用節(jié)點,可用節(jié)點要滿足以下條件:
- ①未設(shè)置IP_VS_DEST_F_OVERLOAD標(biāo)識,即負(fù)載較低。
- ②服務(wù)器當(dāng)前的活動連接數(shù)小于其權(quán)重值。
- ③服務(wù)器的權(quán)重值不能為0。
找到權(quán)重值最高的可用節(jié)點后,會將請求分發(fā)到權(quán)重值最高的服務(wù)器,直至其活動連接數(shù)超過權(quán)重值為止。
FO、OVF算法都是后面新增加的算法,只在內(nèi)核版本4.15及其以上的版本中才存在,如若你內(nèi)核的版本低于4.15,那么需要額外打補丁后才能使用。
3.2.13、分發(fā)調(diào)度算法小結(jié)
經(jīng)過上述分析后,不難得知的是:LVS前前后后共計提供了十二種調(diào)度算法,其中靜態(tài)算法四種,動態(tài)算法八種,越到后面的算法,其實現(xiàn)過程就越為復(fù)雜,但其分發(fā)請求也越為智能。所有算法中用的比較頻繁的是RR、WRR、SH、LC、WLC五種。
不過還是之前那句話,越智能的算法往往代表著開銷越大,在超高并發(fā)的情況下,將所有節(jié)點的硬件配置統(tǒng)一標(biāo)準(zhǔn),采用越普通、越簡單的算法才是最佳的選擇。
3.3、LVS的安裝與管理
LVS因本身是被加入到Linux內(nèi)核的,所以無需額外再安裝,在內(nèi)核中名為ip_vs。
①首先檢測一下內(nèi)核中是否有LVS模塊:
[root@localhost]# lsmod | grep -i ip_vs
ip_vs 141432 0
nf_conntrack 133053 1 ip_vs
libcrc32c 12644 4 xfs,sctp,ip_vs,nf_conntrack
復(fù)制代碼
②如果沒有上面的內(nèi)容,需要加載一下:
[root@localhost]# modprobe ip_vs
復(fù)制代碼
將ip_vs模塊加載到內(nèi)核后,即可安裝ipvsadm工具了,ipvsadm是LVS官方提供的管理工具,因為LVS本身就成為了內(nèi)核的一部分,所以我們使用LVS本質(zhì)上是通過工具對內(nèi)核的ip_vs模塊進(jìn)行調(diào)用。
3.3.1、安裝ipvsadm管理工具
①首先需要安裝一下ipvsadm工具,在線安裝方式:
[root@localhost]# yum install -y ipvsadm
復(fù)制代碼
離線方式安裝方式:
- 一、先創(chuàng)建存放離線包的目錄并進(jìn)入
- 二、通過wget命令從官網(wǎng)拉取源碼包
- 三、解壓拉取下來的源碼包并編譯
- 四、如若編譯報錯則需要安裝相關(guān)的依賴包
[root@localhost]# mkdir /soft/tools && mkdir /soft/tools/ipvsadm
[root@localhost]# cd /soft/tools/ipvsadm
[root@localhost]# wget https://kernel.org/pub/linux/utils/kernel/ipvsadm/ipvsadm-1.31.tar.gz
[root@localhost]# tar -xzvf ipvsadm-1.31.tar.gz
[root@localhost]# cd ipvsadm-1.31
[root@localhost]# make && make install
# 編譯報錯請執(zhí)行下述命令安裝依賴包
yum install -y popt-static kernel-devel make gcc openssl-devel lftplibnl* popt* openssl-devel lftplibnl* popt* libnl* libpopt* gcc*
復(fù)制代碼
②創(chuàng)建一個內(nèi)核的軟鏈接,提供給ipvsadm工具操作內(nèi)核中的ip_vs模塊:
[root@localhost]# ln -s /usr/src/kernels/3.10.0-862.el7.x86_64/ /usr/src/linux
復(fù)制代碼
如果你不清楚內(nèi)核的版本,可以通過uname -r查看,創(chuàng)建對應(yīng)內(nèi)核版本的軟鏈接。
③檢查ipvsadm是否安裝成功:
[root@localhost]# ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
.......
復(fù)制代碼
在任意位置輸入ipvsadm命令,如果出現(xiàn)如上提示代表安裝成功。
④ipvsadm安裝成功后,主體文件位置:
- 離線安裝的情況下,所有主體文件都會在解壓后的目錄中。
- 通過yum命令在線安裝的情況下,各主體文件的所在位置: 主程序:/usr/sbin/ipvsadm 規(guī)則保存工具:/usr/sbin/ipvsadm-save 規(guī)則重載工具:/usr/sbin/ipvsadm-restore 配置文件:/etc/sysconfig/ipvsadm-config ipvs調(diào)度規(guī)則文件:/etc/sysconfig/ipvsadm
3.3.2、ipvsadm指令大全
ipvsadm是LVS工作在用戶空間的管理工具,可以通過它管理工作在內(nèi)核空間的ip_vs,ipvsadm的所有操作指令大體可分為三類:
- 對于虛擬服務(wù)器VIP的增、刪、改指令。
- 對于真實服務(wù)器RS的增、刪、改指令。
- 對于LVS自身的操作與查看指令。
用法如下:
ipvsadm [option] [value] ....
ipvsadm的參數(shù)選項有很多,如下:
- -h(--help):查看命令的幫助信息,列出ipvsadm的所有指令與參數(shù)。
- -A(--add service):在VIP服務(wù)器列表中添加一條新的虛擬服務(wù)器記錄。
- -a(--add server):在RS服務(wù)器列表中添加一條新的真實服務(wù)器記錄。
- -t(--tcp-service):代表對外提供TCP服務(wù)。
- -u(--udp-service):代表對外提供UDP服務(wù)。
- -r(--real-server):表示真實服務(wù)器的IP地址。
- -s(--scheduler):代表目前服務(wù)器列表使用何種調(diào)度算法。
- -w(--weight):為每個RS節(jié)點配置權(quán)重值。
- -m(--masquerading):指定LVS的工作模式為NAT模式。
- -g(--gatewaying):指定LVS的工作模式為DR模式。
- -i(--ipip):指定LVS的工作模式為TUN模式。
- -6(--IPv6):指定LVS支持IPv6類型的IP訪問。
- -E(--edit-service):編輯VIP列表中的一條虛擬服務(wù)器記錄。
- -D(--delete-service):刪除VIP列表中一條虛擬服務(wù)器記錄。
- -C(--clear):清空VIP列表中的所有虛擬服務(wù)器記錄。
- -R(--restore):恢復(fù)VIP列表已配置的規(guī)則。
- -S(--save):將VIP列表中配置好的規(guī)則保存到指定文件中。
- -d(--delete-server):刪除一個VIP中的某條真實服務(wù)器記錄。
- -L|-l(--list):顯示VIP服務(wù)器列表。
- -n(--numberic):以數(shù)字形式輸出IP地址與端口。
- -stats:輸出LVS自身的流量統(tǒng)計信息。
- -rete:輸出LVS流量的出入速率信息。
- -Z(--zero):清空LVS統(tǒng)計的所有信息。
- .......
3.3.3、LVS-DR模式實操
①準(zhǔn)備工作,準(zhǔn)備三臺Linux,所有的服務(wù)器都需要關(guān)閉防火墻以及selinux。
- 192.168.12.129:作為director,部署LVS。
- 192.168.12.130:作為真實服務(wù)器RS1,部署后端服務(wù)。
- 192.168.12.131:作為真實服務(wù)器RS2,部署后端服務(wù)。
②在LVS所在的Linux網(wǎng)卡上綁定VIP(需要根據(jù)機(jī)器的網(wǎng)卡類型綁定):
[root@localhost]# ip addr add dev ens33 192.168.12.111/32
復(fù)制代碼
上述中,我的網(wǎng)卡為ens33,并綁定VIP:192.168.12.111/32。
③為了方便操作,我們把一些操作指令編寫成一個lvs-dr.sh腳本,如下:
[root@localhost]# vi /soft/scripts/lvs/lvs-dr.sh
#!/bin/sh
# 指定安裝后的ipvsadm主程序位置
adm=/soft/tools/ipvsadm/ipvsadm-1.31/ipvsadm
# 先清除LVS之前配置好的所有規(guī)則
$adm -C
# 在VIP列表中添加一條虛擬服務(wù)器記錄,調(diào)度算法會輪詢
$adm -A -t 192.168.12.111:80 -s rr
# 在前面添加的VIP記錄上新增兩條真實服務(wù)器記錄,工作模式為DR
$adm -a -t 192.168.12.111:80 -r 192.168.12.130 -g
$adm -a -t 192.168.12.111:80 -r 192.168.12.131 -g
# 將配置好的規(guī)則保存在文件中
$adm -S > /etc/sysconfig/ipvsadm
# 開啟路由轉(zhuǎn)發(fā)功能
echo 1 > /proc/sys/net/ipv4/ip_forward
復(fù)制代碼
④編寫的腳本文件需要更改編碼格式,并賦予執(zhí)行權(quán)限,否則可能執(zhí)行失敗:
[root@localhost]# vi /soft/scripts/lvs/lvs-dr.sh
:set fileformat=unix # 在vi命令里面執(zhí)行,修改編碼格式
:set ff # 查看修改后的編碼格式
[root@localhost]# chmod +x /soft/scripts/lvs/lvs-dr.sh
復(fù)制代碼
⑤執(zhí)行l(wèi)vs_dr.sh腳本并查看配置后的結(jié)果:
[root@localhost]# ./soft/scripts/lvs/lvs-dr.sh
[root@localhost]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.12.111:80 rr
-> 192.168.12.130:80 Route 1 0 0
-> 192.168.12.131:80 Route 1 0 0
復(fù)制代碼
從上面的結(jié)果中可以看出,我們添加了一條192.168.12.111:80的VIP記錄,采用的調(diào)度算法為RR輪詢算法,并且在該VIP記錄下還添加了兩條真實服務(wù)器RIP記錄。不過由于目前還未開始測試,因此后面LVS的統(tǒng)計信息都為0。
⑥配置第一臺RS真實服務(wù)器:192.168.12.130,首先可以在上面安裝Nginx:
可以通過yum install -y nginx在線安裝。
也可以參考之前文章《Nginx-環(huán)境搭建》中的離線安裝方式。
⑦為RS真實服務(wù)器綁定VIP(DR模式中的LVS、RS必須要求綁定同一個VIP),但需要注意的是:RS節(jié)點的VIP一定要綁在lo口上,不要綁在ens33、eth0等這類網(wǎng)卡上:
[root@localhost]# ip addr add dev lo 192.168.12.111/32
復(fù)制代碼
⑧將RS節(jié)點上需執(zhí)行的一些命令編寫成lvs-dr-rs.sh腳本:
[root@localhost]# vi /soft/scripts/lvs/lvs-dr_rs.sh
#!/bin/sh
# 改寫一下Nginx的默認(rèn)的index.html首頁內(nèi)容
echo "I is Real Server 001" > /soft/nginx/html/index.html
# 忽略ARP廣播,保持ARP靜默,確保請求VIP時,能夠首先落入到LVS上
echo 1 >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo 1 >/proc/sys/net/ipv4/conf/all/arp_ignore
# 開啟精確匹配IP回包機(jī)制,確保RS處理完請求后能夠直接響應(yīng)數(shù)據(jù)給客戶端
echo 2 >/proc/sys/net/ipv4/conf/lo/arp_announce
echo 2 >/proc/sys/net/ipv4/conf/all/arp_announce
# 啟動nginx(由于沒做反向代理,也未更改配置文件,直接啟動即可)
/soft/nginx/sbin/nginx
復(fù)制代碼
然后重復(fù)上述過程,配置第二臺RS節(jié)點,也可以直接克隆一次,但第二個RS節(jié)點上,稍微將上述腳本第一條指令中的I is Real Server 001改為I is Real Server 002,這樣做的好處在于:待會兒測試的時候方便觀察效果。
⑨為兩個RS節(jié)點的腳本文件開放執(zhí)行權(quán)限并執(zhí)行:
[root@localhost]# vi /soft/scripts/lvs/lvs-dr-rs.sh
:set fileformat=unix # 在vi命令里面執(zhí)行,修改編碼格式
:set ff # 查看修改后的編碼格式
[root@localhost]# chmod +x /soft/scripts/lvs/lvs-dr-rs.sh
[root@localhost]# ./soft/scripts/lvs/lvs-dr-rs.sh
復(fù)制代碼
⑩用一臺新的機(jī)器充當(dāng)客戶端,測試LVS-DR模式的分發(fā)效果,可以在windows瀏覽器訪問VIP測試,也可直接通過curl命令測試:
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
[root@localhost]# curl http://192.168.12.111
I is Real Server 002
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
[root@localhost]# curl http://192.168.12.111
I is Real Server 002
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
.......
復(fù)制代碼
觀察如上結(jié)果,很明顯可看出LVS在根據(jù)我們配置好的RR輪詢算法進(jìn)行請求分發(fā)。
整個LVS-DR模式實驗測試到此便告一段落了,但實際過程中一般很少用ipvsadm去操作LVS,因為這種方式步驟比較繁雜,并且沒有健康檢查機(jī)制,也就是說當(dāng)某個RS節(jié)點宕機(jī)后,LVS依舊會為其分發(fā)請求。
正是由于不方便管理以及沒有健康檢查機(jī)制,因此實際情況下都是采用Keepalived去管理LVS的,其實Keepalived最開始就是為LVS專門研發(fā)的,用于快捷管理、確保高可用以及健康檢查的工具。
3.4、結(jié)合Keepalived管理LVS
Keepalived在《Nginx-高可用》篇章中初次提到了它,我們使用它對Nginx實現(xiàn)了最基本的宕機(jī)重啟以及VIP漂移的高可用機(jī)制,因此對于Keepalived基本概念與環(huán)境構(gòu)建過程,在本文中則不再重復(fù)贅述,可直接參考之前的內(nèi)容,在這里重點講一下如何通過Keepalived管理LVS。
通過Keepalived管理LVS其實還是配置之前的keepalived.conf文件。
環(huán)境:四臺Linux,其中兩臺作為RS,一臺作為LVS主,另一臺作為LVS從。
首先根據(jù)之前說過的Keepalived安裝步驟,先在LVS主、從兩臺機(jī)器上安裝Keepalived,然后開始配置keepalived.conf文件。
LVS主節(jié)點上的keepalived.conf文件:
# -------全局配置---------
global_defs {
# 自帶的郵件提醒服務(wù),建議用獨立的監(jiān)控或第三方SMTP,也可選擇配置郵件發(fā)送。
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
# 高可用集群主機(jī)身份標(biāo)識(集群中主機(jī)身份標(biāo)識名稱不能重復(fù),建議配置成本機(jī)IP)
router_id 192.168.12.129
}
# -------Keepalived自身實例配置---------
# 定義虛擬路由,VI_1為虛擬路由的標(biāo)示符(可自定義名稱)
vrrp_instance VI_1 {
# 當(dāng)前節(jié)點的身份標(biāo)識:用來決定主從(MASTER為主機(jī),BACKUP為從機(jī))
state MASTER
# 綁定虛擬IP的網(wǎng)絡(luò)接口,根據(jù)自己的機(jī)器的網(wǎng)卡配置
interface ens33
# 虛擬路由的ID號,主從兩個節(jié)點設(shè)置必須一樣
virtual_router_id 121
# 填寫本機(jī)IP
mcast_src_ip 192.168.12.129
# 節(jié)點權(quán)重優(yōu)先級,主節(jié)點要比從節(jié)點優(yōu)先級高
priority 100
# 優(yōu)先級高的設(shè)置nopreempt,解決異常恢復(fù)后再次搶占造成的腦裂問題
nopreempt
# 組播信息發(fā)送間隔,兩個節(jié)點設(shè)置必須一樣,默認(rèn)1s(類似于心跳檢測)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# 虛擬IP(VIP),也可擴(kuò)展,可配置多個。
192.168.12.111/32
}
}
# -------LVS集群配置---------
# 配置一個虛擬服務(wù)器(VIP),可配置多個組成VIP集群
virtual_server 192.168.12.129 80 {
# 對每個RS健康檢查的時間間隔
delay_loop 6
# 當(dāng)前VIP所采用的分發(fā)調(diào)度算法:RR輪詢
lb_algo rr
# 當(dāng)前LVS采用的工作模式:DR直接路由
lb_kind DR
# 同一個客戶端的請求在多少秒內(nèi)都發(fā)往同一臺RS服務(wù)器
persistence_timeout 50
# 當(dāng)前LVS所采用的通信協(xié)議
protocol TCP
# 定義備用節(jié)點,當(dāng)所有RS都故障時,用sorry_server來響應(yīng)客戶端
sorry_server 127.0.0.1 80
# 配置第一臺RS真實服務(wù)器的信息
real_server 192.168.12.130 80 {
# 設(shè)定權(quán)重值,默認(rèn)為1
weight 1
# 配置TCP信息
TCP_CHECK {
# 連接的端口號
connect_port 80
# 連接超時時間
connect_timeout 3
# 請求失敗后的重試次數(shù)
nb_get_retry 3
# 重試的超時時間
delay_before_retry 3
}
}
# 配置第二臺RS真實服務(wù)器的信息
real_server 192.168.12.131 80 {
# 設(shè)定權(quán)重值,默認(rèn)為1
weight 1
# 配置TCP信息
TCP_CHECK {
# 連接的端口號
connect_port 80
# 連接超時時間
connect_timeout 3
# 請求失敗后的重試次數(shù)
nb_get_retry 3
# 重試的超時時間
delay_before_retry 3
}
}
}
復(fù)制代碼
觀察上述配置文件,其實與之前的并未有太大區(qū)別,僅僅只是多增加了一個virtual_server模塊,而后在內(nèi)配置了LVS的規(guī)則,以及兩個真實服務(wù)器節(jié)點real_server。當(dāng)然,LVS作為整個系統(tǒng)請求分發(fā)的“咽喉要塞”,自然也要確保其高可用的特性,因此可再為其配置一臺從機(jī),確保當(dāng)前機(jī)器發(fā)生意外不能正常工作時,依舊能夠確保整個系統(tǒng)的可用性。
LVS從節(jié)點上的keepalived.conf文件:
# -------Keepalived全局配置---------
global_defs {
# 自帶的郵件提醒服務(wù),建議用獨立的監(jiān)控或第三方SMTP,也可選擇配置郵件發(fā)送。
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
# 高可用集群主機(jī)身份標(biāo)識(集群中主機(jī)身份標(biāo)識名稱不能重復(fù),建議配置成本機(jī)IP)
router_id 192.168.12.132
}
# -------Keepalived自身實例配置---------
# 定義虛擬路由,VI_1為虛擬路由的標(biāo)示符(可自定義名稱)
vrrp_instance VI_1 {
# 當(dāng)前節(jié)點的身份標(biāo)識:用來決定主從(MASTER為主機(jī),BACKUP為從機(jī))
state BACKUP
# 綁定虛擬IP的網(wǎng)絡(luò)接口,根據(jù)自己的機(jī)器的網(wǎng)卡配置
interface ens33
# 虛擬路由的ID號,主從兩個節(jié)點設(shè)置必須一樣
virtual_router_id 121
# 填寫本機(jī)IP
mcast_src_ip 192.168.12.132
# 節(jié)點權(quán)重優(yōu)先級,主節(jié)點要比從節(jié)點優(yōu)先級高
priority 90
# 優(yōu)先級高的設(shè)置nopreempt,解決異常恢復(fù)后再次搶占造成的腦裂問題
nopreempt
# 組播信息發(fā)送間隔,兩個節(jié)點設(shè)置必須一樣,默認(rèn)1s(類似于心跳檢測)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# 虛擬IP(VIP),也可擴(kuò)展,可配置多個。
192.168.12.111/32
}
}
# -------LVS集群配置---------
# 配置一個虛擬服務(wù)器(VIP),可配置多個組成VIP集群
virtual_server 192.168.12.129 80 {
# 對每個RS健康檢查的時間間隔
delay_loop 6
# 當(dāng)前VIP所采用的分發(fā)調(diào)度算法:RR輪詢
lb_algo rr
# 當(dāng)前LVS采用的工作模式:DR直接路由
lb_kind DR
# 同一個客戶端的請求在多少秒內(nèi)都發(fā)往同一臺RS服務(wù)器
persistence_timeout 50
# 當(dāng)前LVS所采用的通信協(xié)議
protocol TCP
# 定義備用節(jié)點,當(dāng)所有RS都故障時,用sorry_server來響應(yīng)客戶端
sorry_server 127.0.0.1 80
# 配置第一臺RS真實服務(wù)器的信息
real_server 192.168.12.130 80 {
# 設(shè)定權(quán)重值,默認(rèn)為1
weight 1
# 配置TCP信息
TCP_CHECK {
# 連接的端口號
connect_port 80
# 連接超時時間
connect_timeout 3
# 請求失敗后的重試次數(shù)
nb_get_retry 3
# 重試的超時時間
delay_before_retry 3
}
}
# 配置第二臺RS真實服務(wù)器的信息
real_server 192.168.12.131 80 {
# 設(shè)定權(quán)重值,默認(rèn)為1
weight 1
# 配置TCP信息
TCP_CHECK {
# 連接的端口號
connect_port 80
# 連接超時時間
connect_timeout 3
# 請求失敗后的重試次數(shù)
nb_get_retry 3
# 重試的超時時間
delay_before_retry 3
}
}
}
復(fù)制代碼
兩個RS節(jié)點還是按照之前的方式配置,然后分別啟動LVS主、從機(jī)器上的keepalived服務(wù)以及RS節(jié)點上的Nginx服務(wù),接著來測試結(jié)果看看:
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
[root@localhost]# curl http://192.168.12.111
I is Real Server 002
[root@localhost]# curl http://192.168.12.111
I is Real Server 001
[root@localhost]# curl http://192.168.12.111
I is Real Server 002
.......
復(fù)制代碼
測試結(jié)果與之前通過ipvsadm工具管理的LVS相同,而通過keepalived之后,所有配置可以統(tǒng)一化管理,同時還能對每個VIP下的真實服務(wù)器節(jié)點進(jìn)行健康檢測,并且還能對LVS實現(xiàn)高可用,因此實際生產(chǎn)環(huán)境中,當(dāng)項目使用LVS時,一般都會采用keepalived管理。
當(dāng)然,對于LVS的高可用特性、RS節(jié)點的健康檢測機(jī)制,大家可以自行停掉對應(yīng)的機(jī)器,然后測試觀察結(jié)果(也包括其他的工作模式也可以自行測試,但一般最常用的就是DR模式)。
四、億級吞吐第四戰(zhàn)-Nginx與Gateway網(wǎng)關(guān)高可用
前面過程中簡單的對LVS-DR模式進(jìn)行了簡單實驗,其中我們通過Nginx作為WEB服務(wù),但實際系統(tǒng)中,Nginx是提供反向代理的作用,它并不處理客戶端的請求,最終的業(yè)務(wù)處理還是交由后端的Tomcat處理。
4.1、Nginx高可用設(shè)計
前面實驗中基于LVS對Nginx實現(xiàn)了水平集群拓展,因此讓整個系統(tǒng)擁有了更高的并發(fā)處理能力,而對于每個Nginx節(jié)點,也可以對其實現(xiàn)高可用,具體過程可參考:《全解Nginx篇-Keepalived實現(xiàn)Nginx高可用》。
相較而言,如果僅是為了容災(zāi),都為每臺Nginx配置一臺備機(jī),那么硬件成本會直線增高,因此通過Keepalived對Nginx實現(xiàn)宕機(jī)重啟就夠了,無需再為其實現(xiàn)VIP漂移,畢竟帶來的收益遠(yuǎn)小于硬件成本,但如若系統(tǒng)要保障更高程度上的高可用,那么可以再為每個Nginx節(jié)點配置從機(jī)。
如若要保證更高的可用性,那依舊可以為每個Nginx節(jié)點配置從節(jié)點容災(zāi)。
4.1.1、為Nginx配置從機(jī)后的接入層架構(gòu)
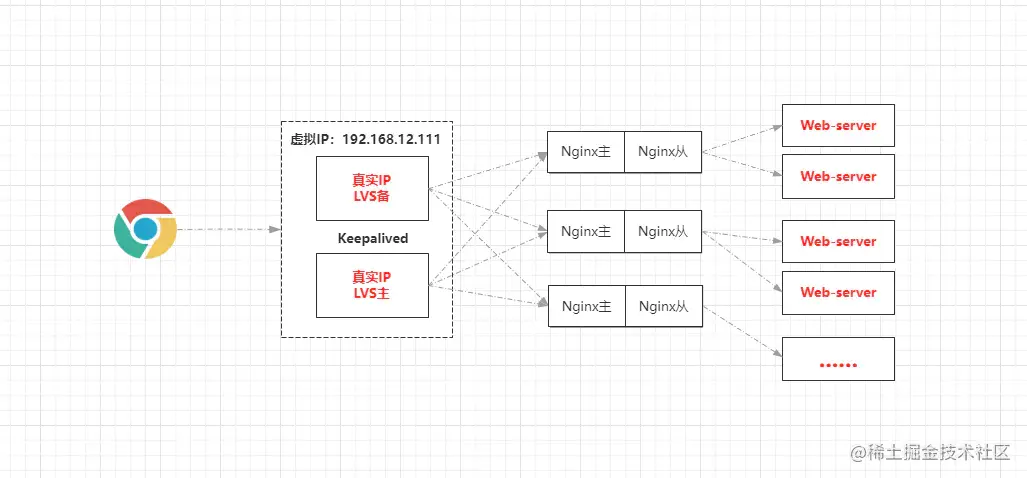
由于每個Nginx都配置了從機(jī),因此每個Nginx節(jié)點都具備容災(zāi)能力,因此可以讓每臺Nginx負(fù)責(zé)不同WEB服務(wù)器的請求分發(fā),這樣做的好處在于:能夠一定程度上提升些許性能。
4.1.2、不為Nginx配置從機(jī)的接入層架構(gòu)
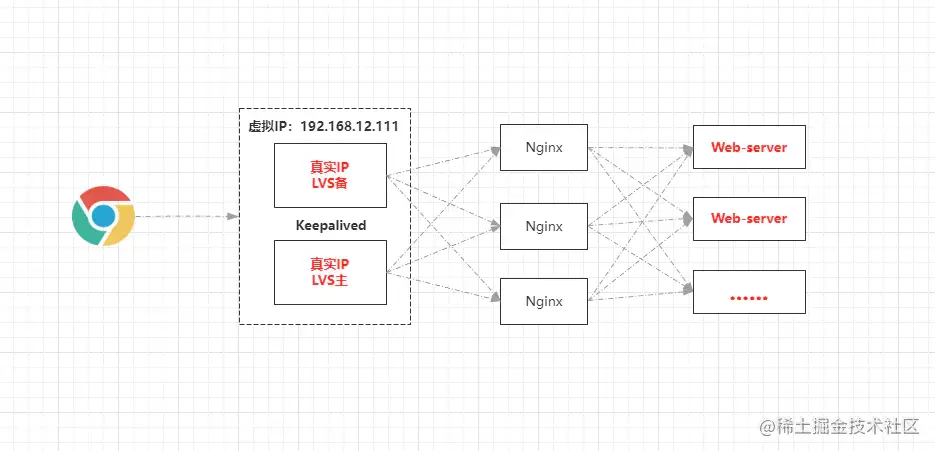
但如若不為Nginx配置從機(jī),那每個Nginx節(jié)點的不具備很強(qiáng)的容災(zāi)能力,再通過上述的那種方式配置反向代理,就會存在問題,因為如果一個節(jié)點宕機(jī),會導(dǎo)致該節(jié)點所代理的Web-server節(jié)點都不可用。
因此如果不給Nginx配置從機(jī),那么可以將每個Nginx的反向代理,都配置成所有Web-sever的列表,這樣就算一臺Nginx節(jié)點宕機(jī),也不會影響系統(tǒng)的正常運轉(zhuǎn)。
4.2、Gateway網(wǎng)關(guān)高可用集群
前面Nginx負(fù)責(zé)代理的是普通Web-server,但大型網(wǎng)站必然會做業(yè)務(wù)切割,對于分布式/微服務(wù)架構(gòu)而言,一般會劃分出多個子服務(wù),但服務(wù)太多不方便相互之間調(diào)用,并且也不方便對外提供,因此在微服務(wù)中都會存在一個服務(wù)網(wǎng)關(guān),由網(wǎng)關(guān)統(tǒng)一對外提供接口,目前微服務(wù)架構(gòu)中主流的網(wǎng)關(guān)技術(shù)是Gateway(在早期的SOA架構(gòu)中是服務(wù)總線)。
因此對于分布式/微服務(wù)系統(tǒng)而言,Nginx代理的實則為網(wǎng)關(guān)節(jié)點,由于網(wǎng)關(guān)作為整個后端系統(tǒng)的流量入口,因此必須要保證其高可用,也就是說會對其做集群部署,也就是在多臺服務(wù)器上部署網(wǎng)關(guān)(結(jié)構(gòu)完全相同),然后Nginx的配置中,將upstream配置成每個Gateway節(jié)點的IP+Port即可,最終整個接入層的架構(gòu)如下:
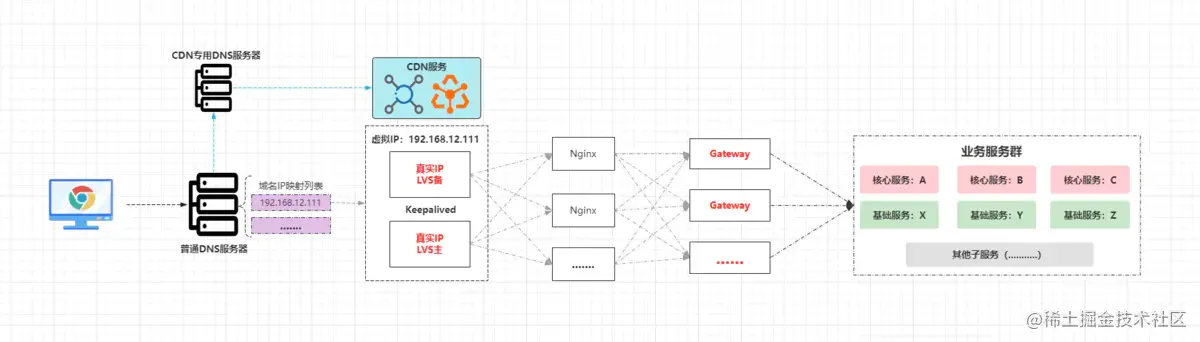
在這套架構(gòu)中,CDN至少能夠為系統(tǒng)分擔(dān)一半的流量,而LVS作為接入層的“首個守關(guān)將”,它的并發(fā)性是極強(qiáng)的,幾乎是Nginx的十倍以上,那假設(shè)此時LVS每秒的并發(fā)吞吐量為20W,為整個系統(tǒng)單日接入上億、十憶、百億流量都行。
五、千臺實例構(gòu)建日均百億流量架構(gòu)
這小節(jié)主要是為了拓展一下,類似于yy階段,說簡單一點就是讓諸位在吹牛逼的時候多點談資,不過在講述之前,首先需要搞懂幾個平臺常用的數(shù)據(jù)指標(biāo):
- PV:平臺頁面被瀏覽/點擊的總次數(shù),每次訪問或刷新都會計入一次PV。
- UV:一天內(nèi)訪問平臺的總用戶數(shù)(以客戶端cookie作為計算依據(jù))。
- IP:一天內(nèi)訪問平臺的獨立IP總數(shù)(以客戶端IP地址作為計算依據(jù))。
- QPS:平臺一秒內(nèi)接收到的請求總數(shù)。
- TPS:平臺一秒內(nèi)接收到的事務(wù)總數(shù)。
- RPS:平臺每秒能夠處理的請求總數(shù)(吞吐量)。
- RT:執(zhí)行一個請求從訪問到響應(yīng)的總體時間。
- 最大并發(fā)數(shù):平臺能夠在同一時刻同時處理的最大請求數(shù)。
- 單日流量:一天內(nèi)平臺收到的請求總數(shù)。
QPS、TPS的區(qū)別:TPS中的事務(wù)是指客戶端請求、服務(wù)端處理、服務(wù)端響應(yīng) 這個過程,一個事務(wù)是指客戶端訪問一次頁面,但QPS是每次對服務(wù)器發(fā)起請求都會計入一次,而訪問一個頁面往往會產(chǎn)生多個請求,因此一個TPS中往往會包含多個QPS。
OK~,對于上述的些許指標(biāo)有了簡單了解后,接著來聊聊百億架構(gòu)的事情,在思考該問題之前,首先需要計算出一個關(guān)鍵指標(biāo):峰值QPS,因為峰值QPS代表著系統(tǒng)將面臨的最高并發(fā),峰值QPS計算公式如下:
峰值QPS = (單日流量 * 80%) / (60 * 60 * 24 * 20%)
由于每天80%的訪問集中在20%的時間里,這20%時間叫做峰值時間,因此只需要用單日流量去計算出這20%中的QPS,那么就能的到單日峰值QPS。
在有些地方并非用單日流量作為計算條件,而是單日的PV總值,但在咱們這里就用現(xiàn)有的百億單日流量 作為計算的基礎(chǔ)條件,如下:
(10000000000*0.8)/(60*60*24*0.2)≈462963
通過如上公式計算,可以得知大概的峰值QPS在46.3W左右。的到峰值QPS后,就可以根據(jù)該值計算出每個層面的服務(wù)節(jié)點大概數(shù)量了,但首先要根據(jù)峰值QPS計算出每個節(jié)點的單機(jī)QPS上限,以及峰值QPS情況下會造成的最大并發(fā)數(shù):
①根據(jù)峰值QPS計算出系統(tǒng)流量的最大并發(fā)數(shù):
計算公式:QPS / (一秒 / 平均響應(yīng)時間)
假設(shè)此時系統(tǒng)中每個請求的平均響應(yīng)時間為500ms,那么根據(jù)公式計算出系統(tǒng)在同一時間會出現(xiàn)流量的最大并發(fā)數(shù):462963/(1/0.5)=231481.5。
②計算出每個層面單機(jī)QPS處理的上限值:
計算公式:節(jié)點最大并發(fā)數(shù) * (一秒 / 請求處理時間)
假設(shè)一個節(jié)點處理每個請求的平均時間為200ms,最大并發(fā)數(shù)為800,那么該節(jié)點的單機(jī)QPS上限為4000。
得到了流量的最大并發(fā)數(shù)以及單機(jī)QPS上限后,那么就可以根據(jù)這兩個值去計算每個層面需要的節(jié)點數(shù)量了,可以通過最大并發(fā)數(shù)計算,也可以通過單機(jī)的QPS上限計算:
- 通過最大并發(fā)數(shù)計算:節(jié)點數(shù)量 = 流量最大并發(fā)數(shù) / 節(jié)點最大并發(fā)數(shù)。
- 通過單機(jī)QPS上限計算:節(jié)點數(shù)量 = 峰值QPS / 單機(jī)QPS上限。
通過第二種方式計算出來的節(jié)點數(shù)量是最準(zhǔn)確的,畢竟每個層面處理請求的時間并不同,比如MySQL處理一個請求需要200ms,而redis可能只需10ms甚至更低,因但為了簡單,咱們就通過第一種方式去計算每個層面的節(jié)點數(shù)量(畢竟只是模擬):
- 接入層: LVS一主一備(LVS-DR的最大連接數(shù)上限大概在30-50W) 但為了容錯需要再搭建一個容災(zāi)集群,因此LVS共計四臺。 Nginx(單節(jié)點并發(fā)連接數(shù)5W左右,線上做反向代理實際3W左右) 231481.5/30000≈8,Nginx大概需要8臺。 Gateway網(wǎng)關(guān)由于不做具體的業(yè)務(wù)處理,默認(rèn)最大連接數(shù)在1W左右 231481.5/10000≈24,Gateway網(wǎng)關(guān)大概需要24臺左右。
- 系統(tǒng)服務(wù)層: SpringBoot內(nèi)嵌的Tomcat:默認(rèn)最大連接數(shù)也是1W,但由于要處理業(yè)務(wù)請求,因此線上能達(dá)到2000左右已算極致 231481.5/2000≈116,Tomcat大概需要116臺左右。 還要考慮到微服務(wù)的生態(tài)圈,服務(wù)不可能單獨部署,注冊中心、服務(wù)保護(hù)、系統(tǒng)監(jiān)控、定時調(diào)度、授權(quán)中心、CI/CD自動化等..... 因此系統(tǒng)服務(wù)層的完整構(gòu)建,至少需要大概180+臺左右的實例。
- 中間件層: 緩存中間件Redis,線上單機(jī)性能大概在5W左右的最大連接數(shù)。 231481.5/50000≈5,但由于緩存的特殊性,至少需部署20臺以上。 分庫分表中間件:8臺左右。 ELK分布式日志收集10臺左右。 Kafka、RabbitMQ消息中間件共計30臺左右。 ElasticSearch搜索中間件共計30臺左右。 ..........
- 存儲層: Mongodb大概需要30臺左右。 MySQL與Tomcat的數(shù)量大致對應(yīng),100臺左右(有些庫需要水平集群)。 大數(shù)據(jù)CDH全家桶50臺以上。 FastDFS分布式文件存儲共計20臺左右。
- .......
其中除開Redis外,其他實例都可采用“一物理機(jī)四實例”的方式部署,但想要構(gòu)建出整個完整的架構(gòu),估摸著需要幾千臺上萬實例,大幾百上千臺物理機(jī)器。當(dāng)然, 上述的節(jié)點數(shù)量并不作為生產(chǎn)環(huán)境下的的推薦,但計算方式是相同的,實際情況下可先計算出峰值QPS,然后再根據(jù)峰值QPS去與每個層面上的單機(jī)QPS上限做計算,從而得到準(zhǔn)確的節(jié)點數(shù)量。
但實際情況下,還需要參考物理服務(wù)器的內(nèi)存、CPU、磁盤的配置,還需要依據(jù)項目的業(yè)務(wù)類型、開發(fā)人員的技術(shù)水平去綜合性考慮具體要使用多少個節(jié)點,因為性能好的超級服務(wù)器再加一定程度上的性能調(diào)優(yōu),能夠極大程度上去節(jié)省服務(wù)器成本。





