
業務背景
跑批通常指代的是我們應用程序針對某一批數據進行特定的處理
在金融業務中一般跑批的場景有分戶日結、賬務計提、欠款批扣、不良資產處理等等
具體舉一個例子
客戶在我司進行借款,并約定每月 10 號碼還款,在客戶自主授權銀行卡簽約后
在每月 10 號(通常是凌晨)我們會在客戶簽約的銀行卡上進行扣款
然后可能會有一個客戶、兩個客戶、三個客戶、四個客戶、好多個客戶都需要進行扣款,所以這一“批” 所有數據,我們都要統一地進行扣款處理,即為我們“跑批”的意思
跑批任務是要通過定時地去處理這些數據,不能因為其中一條數據出現異常從而導致整批數據無法繼續進行操作,所以它必須是健壯的;并且針對于異常數據我們后續可以進行補償處理,所以它必須是可靠的;并且通常跑批任務要處理的數據量較大,我們不能讓它處理的時間過于久,所以我們必須考慮其性能處理;總結一下,我們跑批處理的應用程序需要做到的要求如下
- 健壯性
- 針對于異常數據,不可能導致程序崩潰
- 可靠性
- 針對于異常數據,我們后續可以跟蹤
- 大數據量
- 針對于大數據量,可在規定的時間內進行處理完畢
- 性能方面
- 必須在規定的時間內處理完從而避免干擾任何其他應用程序的正常運行
跑批風險
一些未接觸過跑批業務的同學,可能會犯一些錯誤·
- 「查詢跑批數據,未進行分片處理」
- 這種情況具體有兩種情況
- 一種是同學無意識進行分片處理,直接根據查詢條件將全量數據查出;
- 第二種情況呢,不單是在跑批的時候可能出現的情況,在平時的業務開發過程中也可能發現,針對于查詢條件未進行判空處理。比如 select id from t_user_account weher account_id = "12"; 然而在業務處理過程中,account_id 為空,卻直接進行查詢,數據量一旦上來,就容易導致 OOM 悲劇
- 「未對數據進行批量處理」
- 這種情況也是同學們容易犯的一個錯誤,通常我們跑批可能會涉及到數據準備的過程,那么有的同學就會直接梭哈,邊循環跑批數據邊去查找所需的數據,一方面for嵌套的循環處理,時間復雜度通常是隨著你的 for 個數上升的,在項目中一個同學在保費代扣的跑批任務中,進行了五次for 循環,這個時間復雜度就是O(n ^ 5)了,并且如果你的方法未進行事務管理的話,數據庫的連接釋放也是一個非常消耗資源的事情
- 上一個偽代碼可能會比較好理解
// 調用數據庫查詢需跑批數據
List<BizApplyDo> bizApplyDoList = this.listGetBizApply(businessDate);
// for 循環處理數據
for(BizApplyDo ba : bizApplyDoList) {
// 業務處理邏輯.. 省略
// 查詢賬戶數據
List<BizAccountDo> bizAccountDoList = this.listGetBizAccount(ba.getbizApplyId());
for (BizAccountDo bic : bizAccountDoList){
// 賬戶處理邏輯.. 省略
}
... // 后續還會嵌套 for 循環
}
- 「事務使用的力度不恰當」
我們知道 Spring 中間的事務可分為編程性事務和聲明式事務,具體二者的區別我們就不展開說明了
在開發過程中,就有可能同學不管三七二一,爽了就行,直接 @Trancational 覆蓋住我們整個方法
一旦方法處理時間過久,這個大事務就給我們的代碼埋下了雷
- 「未考慮下游接口的承受能力」
- 我們跑批任務除了在我們本系統進行的處理外,還有可能需要調用外部接口
- 比如代扣時,我們需要調用支付公司側的接口,那么我們是否有考慮下游接口的承受能力和響應時間(這里有一個坑,下一個 part 我們展開說一下)
- 「不同的跑批任務時間設置不合理」
- 在我們的項目中,有一個的業務玩法是,我們必須在保費扣完之后,才可進行本息的代扣
- 小張同學想當然,我的保費代扣定時任務從凌晨12點開始,一個小時定時任務總該結束了吧,那么我的本息代扣的定時任務從凌晨1點開始吧,可是這樣設置真的合適嗎?
優化思路
定時框架的選擇
常用的有 Spring 定時框架、Quartz、elastic-job、xxl-job 等,框架無謂好壞,適合自己業務的才是最佳的
可針對自己業務進行技術選型,我們常使用的技術為 xxl-job,針對于我們上文中所說到的不同的跑批任務設置的時間不合理,我們即可利用 xxljob 的子任務特性進行嵌套的任務處理,在保費代扣任務完成后緊接著進行本息代扣任務
防止OOM,切記分片處理
這一點其實沒有什么好展開的,在對跑批任務進行開發的時候,一定要記住分片處理
一次性加載所有數據到內存里,無疑是自掘墳墓
那么,如何優雅分片呢?
這時候小張同學舉手了:分片我會呀,比如像這種扣款的都是以時間維度來的,我直接 select * from t_repay_plan where repay_time <= "2022-04-10" limit 0,1000
那么,現在我們找個數據來看下這種深度分片的性能如何
我在數據庫中插入了大概兩百萬條數據,把制造數據的過程也分享給你們
// 1、創建表
CREATE TABLE `t_repay_plan` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`repay_time` datetime DEFAULT NULL COMMENT '還款時間',
`str1` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3099998 DEFAULT CHARSET=utf8mb4
// 2、創建存儲過程
delimiter $$
create procedure insert_repayPlan()
begin
declare n int default 1;
while n< 3000000
do
insert into t_repay_plan(repay_time,str1) values(concat( CONCAT(FLOOR(2015 + (RAND() * 1)),'-',LPAD(FLOOR(10 + (RAND() * 2)),2,0),'-',LPAD(FLOOR(1 + (RAND() * 25)),2,0))),n);
set n = n+1;
end while;
end
// 3、執行存儲過程
call insert_repayPlan();
隨著逐漸的數據偏移,數據耗時逐漸增加。因為這種深度分頁是將數據全部查詢出來,并且拋棄掉,效果自然不是那么盡如人意
其實我們分片還有一種方法,那就是利用到我們的 id 來進行分頁處理(當然是你的 id 是需要保證業務增長,并且結合具體的業務場景來進行分析)
我們同樣來試一下怎么利用 id ,進行分片的耗時情況

我們可以看到效果很明顯,利用 id 進行分片,效果是優于我們的這個還款時間字段的
當然關于跑批過程中 「覆蓋索引的使用、盡量不去 select * 等、批量進行插入」 等 sql 常見點不和大家一一展開說明了
針對所需數據進行 map 的構造
我們再寫一個簡單的反例
// 調用數據庫查詢需跑批數據
List<BizApplyDo> bizApplyDoList = this.listGetBizApply(businessDate);
// for 循環處理數據
for(BizApplyDo ba : bizApplyDoList) {
// 查詢賬戶數據
BizAccountDo bizAccountDo = this.getBizAccount(ba.getbizApplyId());
// 賬戶處理邏輯.. 省略
// 查詢扣款人數據
CustDo custDo = this.getCust(ba.getUserId);
// 扣款人處理邏輯.. 省略
}
我們可以這樣進行改造(偽代碼、忽略判空處理)
// 調用數據庫查詢需跑批數據
List<BizApplyDo> bizApplyDoList = this.listGetBizApply(businessDate);
// 構建業務申請編號集合
List<String> bizApplyIdList = bizApplyDoList.parallelStream().map(BizApplyDo::getbizApplyId()).collect(Collectors.toList());
// 批量進行賬戶查詢
List<BizAccountDo> bizAccountDoList = this.listGetBizAccount(bizApplyIdList);
// 構建賬戶 Map
Map<String, BizAccountDo> accountMap = bizAccountDoList.parallelStream().collect(Collectors.toMap(BizAccountDo::getBizApplyId(), Function.identity()))
// 扣款人數據同樣處理
for(BizApplyDo ba : bizApplyDoList) {
account = accountMap.get(ba.getbizApplyId())
// 賬戶處理邏輯.. 省略
}
盡可能減少 for 循環的嵌套,減少數據庫頻繁連接和銷毀
事務控制長點心
一旦我們使用了@Trancation進行管理事務,那么就要求組內開發人員在開發過程中需要瞪大眼睛去注意事務的控制范圍
因為 @Trancation 是在第一個 sql 方法執行的時候就開啟了事務,在方法未結束之前都不會進行提交,有些同學接手改造這個方法的時候,沒有注意到這個方法是被@Trancation覆蓋,那么在這個方法里加入一些RPC的遠程調用、消息發送、文件寫入、緩存更新等操作
1、這些操作自身是無法回滾的,這就會導致數據的不一致。可能RPC調用成功了,但是本地事務回滾了,可是PRC調用無法回滾了。
2、在事務中有遠程調用,就會拉長整個事務。那么久會導致本事務的數據庫連接一直被占用,那么如果類似操作過多,就會導致數據庫連接池耗盡或者單個鏈接超時
我曾經就見過一個方法,經過多人之手后,從而因為大事務導致數據庫連接被強行銷毀的悲劇
所以「我們可以有選擇性的去使用編程性事務去處理」我們的業務邏輯,讓接手的同學可以明確看到什么時候開啟了事務,什么時候提交了事務,也盡可能將我們的事務粒度的范圍縮小
下游接口 hold 住么
分享此條優化之前,先大致介紹一下我們的業務背景
保費代扣的跑批任務中,我們是會借助流程編排這個框架,去異步發起我們的代扣,你可以理解為一筆代扣申請就是一個異步線程,代扣的數據全部在流程編排中進行傳遞
在我們進行優化完畢的時候,準備在UAT環境進行優化測試的時候,發現僅20w條保費數據,處理時間就非常的不盡入人意
監控系統環境,發現系統頻頻在進行 GC,我的第一反應,不會是發生內存泄露了吧,在準備 dump 文件的時候
我意外的發現,大部分申請都是卡在了對外扣費的這個節點,經過日志觀察,發現下游接口給的響應時間過久,甚至部分出現了超時情況
那么這個GC就合理了,由于我們的代扣申請生成的速度非常快,并且是異步的線程調度,線程還未死亡,一直在嘗試對外請求扣費,就導致所有的數據都堆在內存里,就導致了頻繁GC
在和下游接口方進行核實之后,的確針對于該接口沒有進行限流處理(太坑了)
優化的思路也很簡單了,在業務可接受的情況,我們采取的是去發送 mq 請求后,就掛起流程編排(該線程會死亡),然后讓消費者進行處理調用成功后喚醒流程進行后續處理即可,當然使用固定的線程池直接調外也是可以的,目的都是防止過多的線程處于 RUNNING,從而導致內存一直的堆積
還有一種對外調用的萬金油處理方式,就是在業務可接受的情況下,采取一種 fast success 方式,舉個例子,在進行保費扣費的時候,我們調用支付公司的接口之前,直接將我們的扣費狀態更改為扣費中,然后直接掛起我們的業務,然后用定時任務去查證我們的扣費結果,收到扣費結果后,在繼續我們扣費后的操作
機器利用方面給我打滿
針對于生產上面的機器我們通常不會是單機部署,那么如何可以盡可能去壓榨我們服務器的資源呢
那就是利用xxl-job的 「分片廣播」 和 「動態分片」 功能
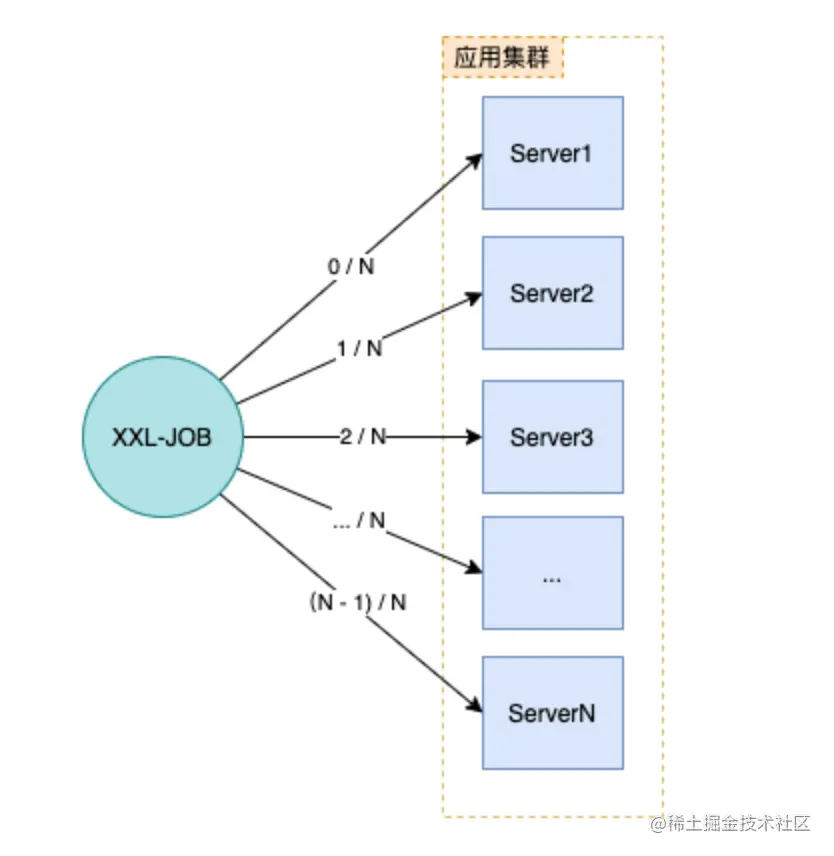
執行器集群部署時,任務路由策略選擇”分片廣播”情況下,一次任務調度將會廣播觸發對應集群中所有執行器執行一次任務,同時系統自動傳遞分片參數;可根據分片參數開發分片任務;
“分片廣播” 以執行器為維度進行分片,支持動態擴容執行器集群從而動態增加分片數量,協同進行業務處理;在進行大數據量業務操作時可顯著提升任務處理能力和速度。
“分片廣播” 和普通任務開發流程一致,不同之處在于可以獲取分片參數,獲取分片參數進行分片業務處理。
// 可參考Sample示例執行器中的示例任務"ShardingJobHandler"了解試用
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
具體舉個例子,比如我們做分戶日結的時候,可以根據商戶的編號對機器進行取模處理,然后每臺機器只執行某些特定商戶的數據
那么這邊留一個問題給大家:如果發生數據傾斜,你會如何處理,即某個商戶的數據量特別大, 導致這臺機器執行的任務非常的重,要是你,你會如何處理這種場景?
總結
今天針對于大數據量的跑批,在項目中實踐思考就到此結束了。
文章介紹了我們常見跑批任務中可能出現的風險和比較常用通用的一些優化思路進行了分享
關于線程池和緩存的運用我未在文章中提及,這兩點也對我們的高效跑批具有極大的幫助,小伙伴們可以加以利用
當然文章只是引起大家針對于跑批任務的思考,更多的優化還需結合任務具體情況和項目本身環境進行處理





