
背景
概述
最近團隊里我們在密集的討論 redis 緩存一致性相關的問題,電商核心的域如商品、營銷、庫存、訂單等實際上在緩存的選擇上各有特色,那么在這些差異的業務背后,我們有沒有一些最佳實踐可供參考呢?本文嘗試著來討論這個問題,并給出一些建議。
在討論之前,有兩個重點我們需要達成一致:
- 分布式場景下無法做到強一致:不同于 CPU 硬件緩存體系采用的 MESI 協議(參考資料)以及硬件的強時鐘控制,分布式場景下我們無法做到緩存與底層數據庫的強一致,即把緩存和數據庫的數據變更做成一個原子操作。硬件工程師設計了內存屏障(Memory Barrier)的概念,提供給軟件開發者不同的一致性選項在性能與一致性上進行權衡。
- 就算是達到最終一致性也很難:分布式場景下,要做到最終一致性,就要求緩存中存儲的是最新版本的數據(或者緩存為空),而且是在數據庫更新后很迅速的就要達到這個一致性的狀態,要做到是極其困難的。我們會面臨硬件、軟件、通信等等組件非常多的異常情況。
緩存的一致性問題
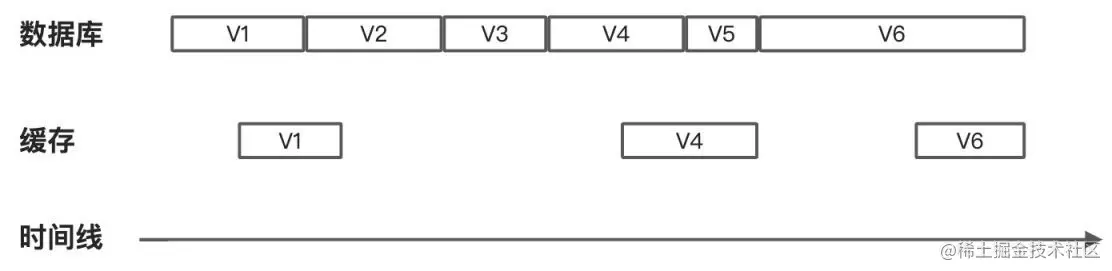
一般化來說,我們面臨的是這樣的一個問題,如下圖所示,數據庫的數據會有 5 次更新,產生 6 個版本,V1~V6,圖中每個方框的長度代表這個版本持續的時間。我們期望,在數據庫中的數據變化后,緩存層需要盡快的感知到并作出反應,如下圖所示,緩存層方框中的間隔代表這個時間段緩存數據不存在,V2、V3 以及 V5 版本在緩存中不存在并不會破壞我們的最終一致性要求,只要數據庫的最終版本和緩存的最終版本是相同的就可以了。
緩存是如何寫入的
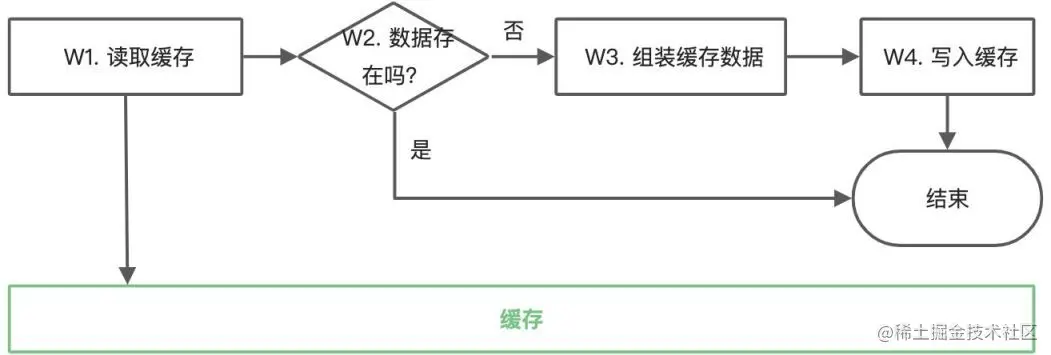
緩存寫入的代碼通常情況下都是和緩存使用的代碼放在一起的,包含 4 個步驟,如下圖所示:W1 讀取緩存,W2 判斷緩存是否存在,W3 組裝緩存數據(這通常需要向數據庫進行查詢),W4 寫入緩存。每一個步驟間可能會停頓多久是沒有辦法控制的,尤其是 W3、W4 之間的停頓最為要命,它很可能讓我們將舊版本的數據寫入到緩存中。
我們可能會想,W4 步的寫入,帶上 W2 的假設,即使用 WriteIfNotExists 語義,會不會有所改善?
考慮如下的情形,假設有 3 個緩存寫入的并發執行,由于短時間數據庫大量的更新,它們分別組裝的是 V1、V2、V3 版本的數據。使用 WriteIfNotExists 語義,其中必然有 2 個執行會失敗,哪一個會成功根本無法保證。我們無法簡單的做決策,需要再次將緩存讀取出來,然后判斷是否我們即將寫入的一樣,如果一樣那就很簡單;如果不一樣的話,我們有兩種選擇:
1)將緩存刪除,讓后續別的請求來處理寫入。
2)使用緩存提供的原子操作,僅在我們的數據是較新版本時寫入。
如何感知數據庫的變化
數據庫的數據發生變化后,我們如何感知到并進行有效的緩存管理呢?通常情況下有如下的 3 種做法:
使用代碼執行流
通常我們會在數據庫操作完成后,執行一些緩存操作的代碼。這種方式最大的問題是可靠性不高,應用重啟、機器意外當機等情況都會導致后續的代碼無法執行。
使用事務消息
作為如何感知數據庫的變化的改進,在數據庫操作完成后發出事務消息,然后在消息的消費邏輯里執行緩存的管理操作。可靠性的問題就解決了,只是業務側要為此增加事務消息的邏輯,以及運行成本。
使用數據變更日志
數據庫產品通常都支持在數據變更后產生變更日志,比如 MySQL 的 binlog。可以讓中間件團隊寫一款產品,在接收到變更后執行緩存的管理操作,比如阿里的精衛。可靠性有保證,同時還可以進行某個時間段變更日志的回放,功能就比較強大了。
最佳實踐一:數據庫變更后失效緩存
這是最常用和簡單的方式,應該被作為首選的方案,整體的執行邏輯如下圖所示:
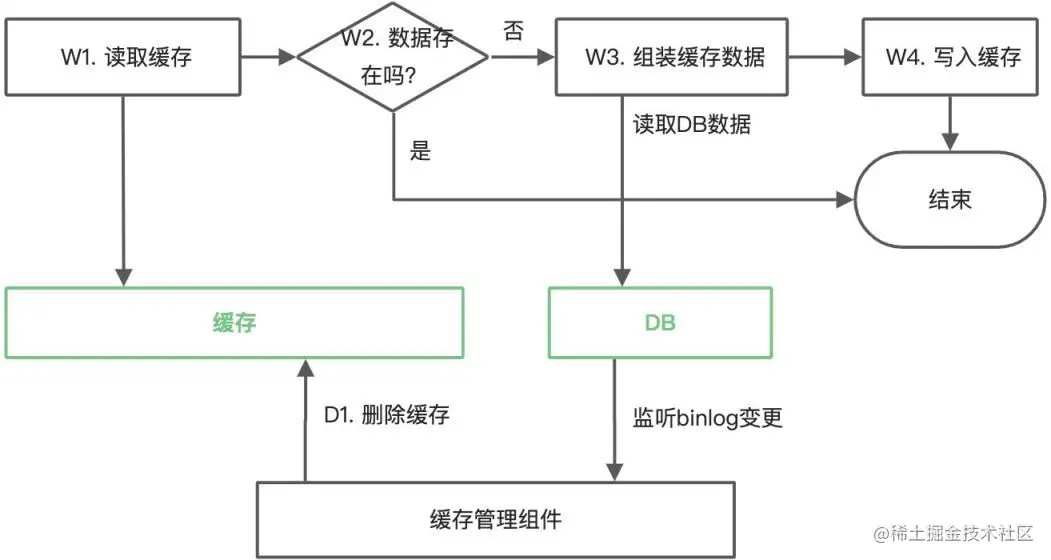
W4 步使用最基本的 put 語義,這里的假設是寫入較晚的請求往往也是攜帶的最新的數據,這在大多的情形下都是成立的。D1 步使用監聽 DB binlog 的方式來刪除緩存,即前述使用事務消息中介紹的方法。
這個方案的缺點是:在數據庫數據存在高并發更新且緩存讀取流量較大的情況下,會有小概率存在緩存中存儲的是舊版本數據的情況。
通常的解法有四種:
1)限制緩存有效時間:設定緩存的過期時間,比如 15 分鐘。即表示我們最多接受緩存在 15 分鐘的時間范圍內是舊的。
2)小概率緩存重加載:根據流量比設定一定比例的緩存重加載,以保證大流量情況下的緩存數據的一致性。比如 1%的比例,這同時還可以幫助數據庫得到充分的預熱。
3)結合業務特點:根據業務的特點做一些設計,比如:
針對營銷的場景:在商品詳情頁/確認訂單頁的優惠計算時使用緩存,而在下單時不使用緩存。這可以讓極端情況發生時,不產生過大的業務損失。
針對庫存的場景:讀取到舊版本的數據只是會在商品已售罄的情況下讓多余的流量進入到下單而已,下單時的庫存扣減是操作數據庫的,所以不會有業務上的損失。
4)兩次刪除:D1 步刪除緩存的操作執行兩次,且中間有一定的間隔,比如 30 秒。這兩次動作的觸發都是由“緩存管理組件”發起的,所以可以由它支持。
最佳實踐二:帶版本寫入
針對象商品信息緩存這種更新頻率低、數據一致性要求較高且緩存讀取流量很高的場景,通常會采用帶版本更新的方式,整體的執行邏輯如下圖如示:
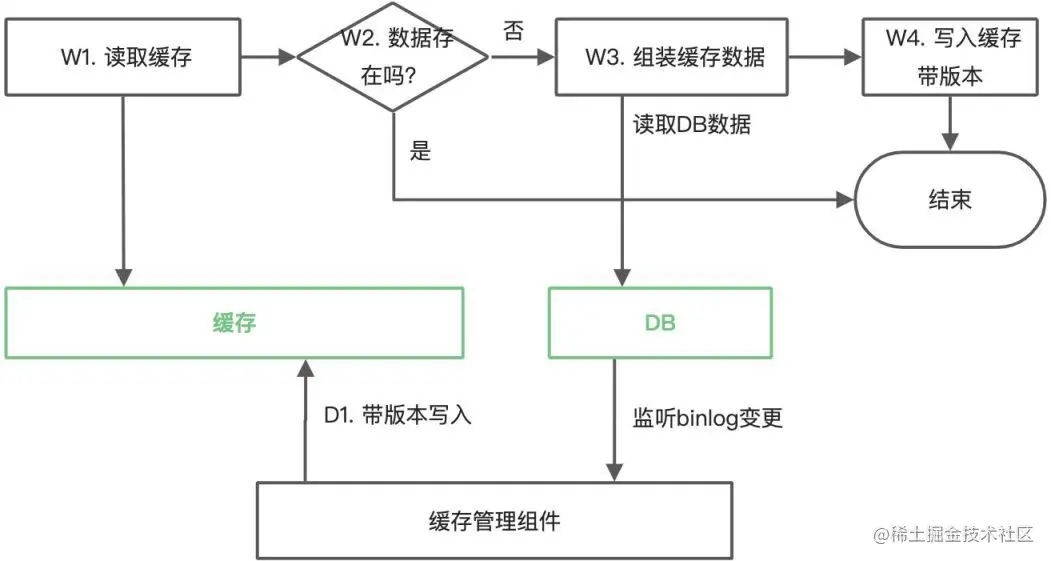
和“數據庫變更后失效緩存”方案最大的差異在 W4 步和 D1 步,需要緩存層提供帶版本寫入的 API,即僅當寫入數據版本較新時可以寫入成功,否則寫入失敗。這同時也要求我們在數據庫增加數據版本的信息。
這個方案的最終一致性效果比較好,僅在極端情況下(新版本寫入后數據丟失了,后續舊版本的寫入就會成功)存在緩存中存儲的是舊版本數據的可能。在 D1 步使用寫入而不是使用刪除可以極大程度的避免這個極端情況的出現,同時由于該方案適用于緩存讀取流量很高的場景,還可以避免緩存被刪除后 W3 步短時間大量請求穿透到 DB。
總結與展望
對于緩存與數據庫分離的場景,在結合了業界多家公司的實踐經驗以及 ROI 權衡之后,前述的兩個最佳實踐是被應用的最為廣泛的,尤其是最佳實踐一,應該作為我們日常應用的首選。同時,為了最大限度的避免每個最佳實踐背后可能發生的不一致性問題,我們還需要切合業務的特點,在關鍵的場景上做一些保障一致性的設計(比如前述的營銷在下單時使用數據庫讀而不是緩存讀),這也顯得尤為重要(畢竟如“背景”中所述,并不存在完美的技術方案)。
除了緩存與數據庫分離的方案,還有兩個業界已經應用的方案也值得我們借鑒:
阿里 XKV
簡單來講就是在數據庫上部署一個 Memcache 的 Server,它直接繞過數據庫層直接訪問存儲引擎層(如:InnoDB),同時使用 KV client 來進行數據的訪問。它的特點是數據實際上與數據庫是強一致的,性能可以比使用 SQL 訪問數據庫提升 5~10 倍。缺點也很明顯,只能通過主鍵或者唯一鍵來訪問數據(這只是相對 SQL 來說的,大多數緩存本來也就是 KV 訪問協議)。
騰訊 DCache
介紹資料。不用自行維護緩存與數據庫兩套存儲,給開發人員統一的一套數據視圖,由 DCache 在緩存更新后自行持久化數據。缺點是支持的數據結構有限( key-value,k-k-row,list,set,zset ),未來也很難支持形如數據庫表一樣復雜的數據結構。
作者:得物技術
鏈接:
https://juejin.cn/post/7051772135584301092





