
導讀:在大數據時代,對復雜數據結構中的各數據項進行有效的排序和查找的能力非常重要,因為很多現代算法都需要用到它。在為數據恰當選擇排序和查找策略時,需要根據數據的規模和類型進行判斷。盡管不同策略最終得到的結果完全相同,但使用恰當的排序和查找算法才能高效解決實際問題。
作者:伊姆蘭·艾哈邁德(Imran Ahmad)
來源:華章科技

本文介紹以下排序算法:
- 冒泡排序(bubble sort)
- 歸并排序(merge sort)
- 插入排序(insertion sort)
- 希爾排序(shell sort)
- 選擇排序(selection sort)
01 在Python中交換變量
在實現排序和查找算法時,需要交換兩個變量的值。在Python中,有一種簡單的方法可以交換兩個變量,如下所示:
var1 = 1
var2 = 2
var1,var2 = var2,var1
print(var1,var2)
我們看看交換的結果。
2 1
本文的所有排序算法中都使用這種簡單的方法來交換變量值。
下面我們從冒泡排序開始學習。
02 冒泡排序
冒泡排序是所有排序算法中最簡單且最慢的一種算法,其設計方式是:當算法迭代時使得列表中的最大值像氣泡一樣冒到列表的尾部。由于其最壞時間復雜度是O(N2),如前所述,它應該用于較小的數據集。
- 理解冒泡排序背后的邏輯
冒泡排序基于各種迭代(稱為遍歷)。對于大小為N的列表,冒泡排序將會進行N–1輪遍歷。我們著重討論第一次迭代,也就是第一輪遍歷。
第一輪遍歷的目標是將最大值移動到列表的尾部。第一輪遍歷完成時,我們將看到列表中的最大值冒到了尾部。
冒泡排序會比較兩個相鄰變量的值,如果較低位置的變量值大于較高位置的變量值,則交換這兩個值。這種迭代一直持續到我們到達列表的末尾,如圖3-2所示。
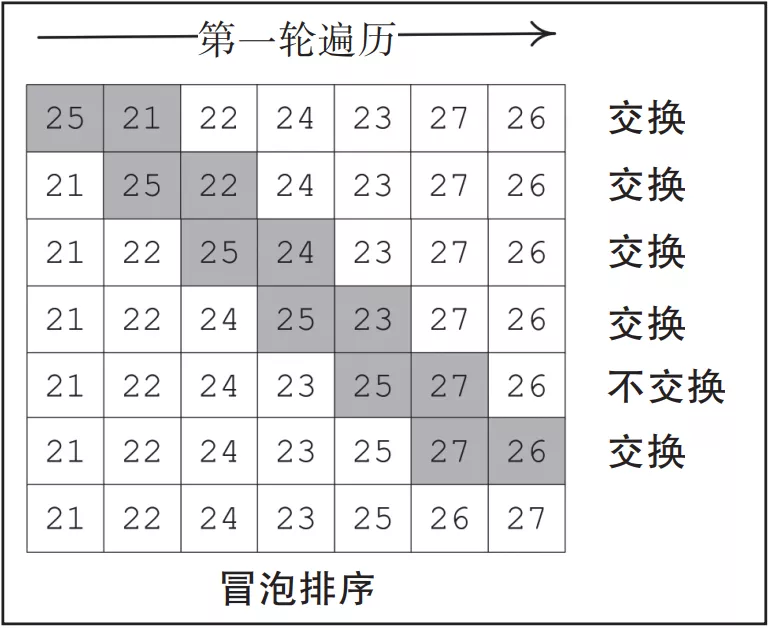
▲圖 3-2
現在,我們看看如何使用Python實現冒泡排序:
#Pass 1 of Bubble Sort
lastElementIndex = len(list)-1
print(0,list)
for idx in range(lastElementIndex):
if list[idx]>list[idx+1]:
list[idx],list[idx+1]=list[idx+1],list[idx]
print(idx+1,list)
在Python中實現冒泡排序的第一輪遍歷后,結果如圖3-3所示。
▲圖 3-3
一旦第一輪遍歷完成,最大值就已經位于列表的尾部。算法接下來將進行第二輪遍歷,第二輪遍歷的目標是將第二大的值移動到列表第二高的位置。為此,算法將再次比較相鄰變量的值,如果它們未按照大小排列則進行交換。第二輪遍歷將跳過列表頂部元素,因為該元素在第一輪遍歷后已經被放在了正確的位置上,因此不需要再移動。
完成第二輪遍歷后,算法將繼續執行第三輪遍歷,以此類推,直到列表中的所有數據都按照升序排列。該算法將需要N–1輪遍歷才能將大小為N的列表完全排序。Python中冒泡排序的完整實現如下所示。
def BubbleSort(list):
# Excahnge the elements to arrange in order
lastElementIndex = len(list)-1
for passNo in range(lastElementIndex,0,-1):
for idx in range(passNo):
if list[idx]>list[idx+1]:
list[idx],list[idx+1]=list[idx+1],list[idx]
return list
現在,我們看看冒泡排序算法的性能。
- 冒泡排序的性能
很容易就可以看出冒泡排序包含了兩層循環:
- 外層循環:外層循環稱為遍歷。例如,第一輪遍歷就是外層循環的第一次迭代。
- 內層循環:在每次內層循環的迭代過程中,對列表中剩余的未排序元素進行排序,直到最高值冒泡到右側為止。第一輪遍歷將進行N–1次比較,第二輪遍歷將進行N–2次比較,而每輪后續遍歷將減少一次比較操作。
由于存在兩層循環,最壞情況下的運行時復雜度是O(n2)。
03 插入排序
插入排序的基本思想是,在每次迭代中,都會從數據集中移除一個數據點,然后將其插入到正確的位置,這就是為什么將其稱為插入排序算法。
在第一次迭代中,我們選擇兩個數據點,并對它們進行排序,然后擴大選擇范圍,選擇第三個數據點,并根據其值找到正確的位置。該算法一直進行到所有的數據點都被移動到正確的位置。這個過程如圖3-5所示。
▲圖 3-5
插入排序算法的Python代碼如下所示:
def InsertionSort(list):
for i in range(1, len(list)):
j = i-1
element_next = list[i]
while (list[j] > element_next) and (j >= 0):
list[j+1] = list[j]
j=j-1
list[j+1] = element_next
return list
請注意,在主循環中,我們在整個列表中進行遍歷。在每次迭代中,兩個相鄰的元素分別是list[j](當前元素)和list[i](下一個元素)。
在list[j]>element_next且j>=0時,我們會將當前元素與下一個元素進行比較。
我們使用此代碼對數組進行排序。
list = [25,26,22,24,27,23,21]
InsertionSort(list)
print(list)
結果:
[21,22,23,24,25,26,27]
我們看一下插入排序算法的性能。
從算法的描述中可以明顯看出,如果數據集已經排好序,那么插入排序將執行得非常快。事實上,如果數據集已經排好序,則插入排序僅需線性運行時間,即O(n)。最糟糕的情況是,每次內層循環都要移動列表中的所有元素。如果內層循環由i定義,則插入排序算法的最壞時間復雜度由以下公式給出:
總的遍歷次數如圖3-7所示。
▲圖 3-7
一般來說,插入排序可以用在小型數據集上。對于較大的數據集,由于其平均性能為平方級,不建議使用插入排序。
04 歸并排序
到目前為止,我們已經介紹了兩種排序算法:冒泡排序和插入排序。如果數據是部分有序的,那么它們的性能都比較好。本文討論的第三種算法是歸并排序算法,它是由約翰·馮·諾依曼(John von Neumann)在20世紀40年代開發的。該算法的主要特點是,其性能不取決于輸入數據是否已排序。
同MapReduce和其他大數據算法一樣,歸并排序算法也是基于分治策略而設計的。在被稱為劃分的第一階段中,算法將數據遞歸地分成兩部分,直到數據的規模小于定義的閾值。在被稱為歸并的第二階段中,算法不斷地進行歸并和處理,直到得到最終的結果。該算法的邏輯如圖3-8所示。
▲圖 3-8
我們先來看看歸并排序算法的偽代碼:

可以看到,該算法有以下三個步驟:
- 它將列表劃分為兩個長度相等的部分。
- 它使用遞歸來進行劃分,直到每個列表的長度為1。
- 它將有序的部分歸并成一個有序的列表并返回。
歸并排序算法的實現代碼如下所示。
def MergeSort(list):
if len(list)>1:
mid = len(list)//2 #splits list in half
left = list[:mid]
right = list[mid:]
MergeSort(left) #repeats until length of each list is 1
MergeSort(right)
a = 0
b = 0
c = 0
while a < len(left) and b < len(right):
if left[a] < right[b]:
list[c]=left[a]
a = a + 1
else:
list[c]=right[b]
b = b + 1
c = c + 1
while a < len(left):
list[c]=left[a]
a = a + 1
c = c + 1
while b < len(right):
list[c]=right[b]
b = b + 1
c = c + 1
return list
運行前面的Python代碼時,會產生一個對應的輸出結果,如下所示。
list = [44,16,83,7,67,21,34,45,10]
MergeSort(list)
print(list)
[7, 10, 16, 21, 34, 44, 45, 67, 83]
可以看到,該代碼執行后的輸出結果是一個有序列表。
05 希爾排序
冒泡排序算法比較相鄰的元素,如果它們不符合順序,則進行交換。如果我們有一個部分有序的列表,則冒泡排序應該能夠給出比較合理的性能,因為一旦循環中不再發生元素交換,冒泡排序就會退出。
但是對于一個規模為N的完全無序的列表,冒泡排序必須經過N–1次完整的迭代才能得到完全排好序的列表。
丹諾德·希爾(Donald Shell)提出了希爾排序(以他的名字命名),該算法質疑了對選擇相鄰的元素進行比較和交換的必要性。
現在,我們來理解這個概念。
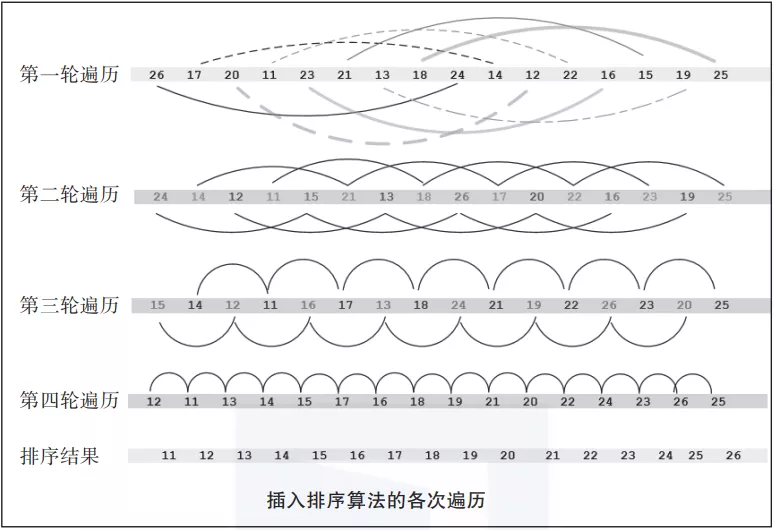
在第一輪遍歷中,我們不選擇相鄰的元素,而是選擇有固定間距的兩個元素,最終排序出由一對數據點組成的子列表,如圖3-11所示。在第二輪遍歷中,對包含四個數據點的子列表進行排序(見圖3-11)。

▲圖 3-11
在后續的遍歷中,每個子列表中的數據點數量不斷增加,子列表的數量不斷減少,直到只剩下一個包含所有數據點的子列表為止。此時,我們可以認為列表已經排好序了。
在Python中,用于實現希爾排序算法的代碼如下:
def ShellSort(list):
distance = len(list) // 2
while distance > 0:
for i in range(distance, len(list)):
temp = list[i]
j = i
# Sort the sub list for this distance
while j >= distance and list[j - distance] > temp:
list[j] = list[j - distance]
j = j-distance
list[j] = temp
# Reduce the distance for the next element
distance = distance//2
return list
用前面的代碼對列表進行排序,結果如下所示。
list = [26,17,20,11,23,21,13,18,24,14,12,22,16,15,19,25]
ShellSort(list)
print(list)
[11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26]
可以看到,調用ShellSort函數成功地對輸入數組進行了排序。
- 希爾排序的性能
希爾排序并不適用于大數據集,它用于中型數據集。粗略地講,它在一個最多有6000個元素的列表上有相當好的性能,如果數據的部分順序正確,則性能會更好。在最好的情況下,如果一個列表已經排好序,則它只需要遍歷一次N個元素來驗證順序,從而產生O(N)的最佳性能。
06 選擇排序
正如在本文前面所看到的,冒泡排序是最簡單的排序算法。選擇排序是對冒泡排序的改進,我們試圖使得算法所需的總交換次數最小化。
與冒泡排序算法的N–1輪遍歷過程相比,選擇排序在每輪遍歷中僅產生一次交換,在每輪遍歷中尋找最大值并將其直接移動到尾部,而不是像冒泡排序那樣,每輪遍歷都一步一步地將最大的值向尾部移動。因此,在第一輪遍歷后,最大值位于列表尾部。在第二輪遍歷后,第二大的值會緊鄰最大值。
隨著算法的進行,后面的值將根據它們的大小移動到正確的位置。最后一個值將在第N–1輪遍歷后移動。因此,選擇排序同樣需要N–1輪遍歷才能對N個數據項進行排序(如圖3-13所示)。
▲圖 3-13
這里展示了選擇排序在Python中的實現:
def SelectionSort(list):
for fill_slot in range(len(list) - 1, 0, -1):
max_index = 0
for location in range(1, fill_slot + 1):
if list[location] > list[max_index]:
max_index = location
list[fill_slot],list[max_index] = list[max_index],list[fill_slot]
return list
執行選擇排序算法時,將產生如下所示的輸出。
list = [70,15,25,19,34,44]
SelectionSort(list)
print(list)
[15,19,25,34,44,70]
可以看到,最后的輸出結果就是排好序的列表。
- 選擇排序的性能
選擇排序的最壞時間復雜度是O(N2)。請注意,其最壞性能近似于冒泡排序的性能,因此不應該用于對較大的數據集進行排序。不過,選擇排序仍是比冒泡排序設計更好的算法,由于交換次數減少,其平均復雜度比冒泡排序好。
小結:選擇一種排序算法
恰當地選擇排序算法既取決于當前輸入數據的規模,也取決于當前輸入數據的狀態。對于已經排好序的較小的輸入列表,使用高級算法會給代碼帶來不必要的復雜度,而性能的提升可以忽略不計。
例如,對于較小的數據集,我們不需要使用歸并排序,冒泡排序更容易理解和實現。如果數據已經被部分排好序了,則可以使用插入排序。對于較大的數據集,歸并排序算法是最好的選擇。
關于作者:伊姆蘭·艾哈邁德(Imran Ahmad) 是一名經過認證的谷歌講師,多年來一直在谷歌和學習樹(Learning Tree)任教,主要教授Python、機器學習、算法、大數據和深度學習。他在攻讀博士學位期間基于線性規劃方法提出了名為ATSRA的新算法,用于云計算環境中資源的優化分配。近4年來,他一直在加拿大聯邦政府的高級分析實驗室參與一個備受關注的機器學習項目。
本文摘編自《程序員必會的40種算法》,經出版方授權發布。





