擊這里在線咨詢客服")
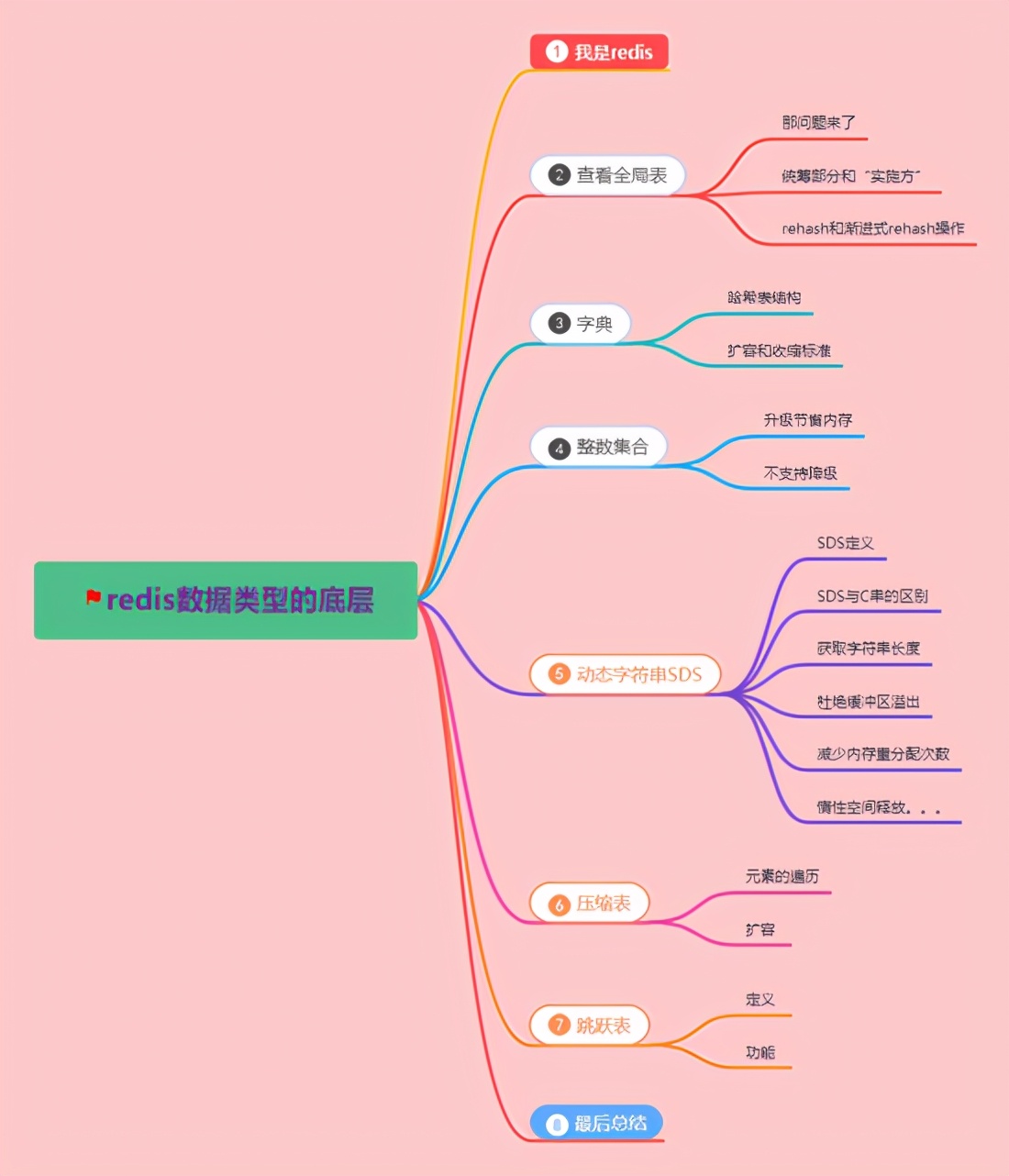
思維導(dǎo)圖:
我是redis
你好,我是 redis
一個(gè)叫Antirez的男人帶我來到這個(gè)充滿復(fù)雜的世界上。

聊到我的出生,那跟MySQL大哥脫不了關(guān)系呀,我是來幫助他的,所謂天降猛男redis就是我了,真想對(duì)他說:
“
我還沒有來到這個(gè)世界上的時(shí)候,剛開始挺好的,互聯(lián)網(wǎng)前期,咱們的用戶請(qǐng)求也不多,主要是一些靜態(tài)網(wǎng)站和小游戲,這 有啥難的 ,MYSQL大哥一個(gè)頂倆好吧。但天有不測(cè)風(fēng)云,歷史不會(huì)停止步伐的。用戶請(qǐng)求的數(shù)據(jù)也隨之暴漲,每天用戶的 每一次請(qǐng)求 都變成了對(duì)它的一個(gè)又一個(gè)的 讀寫操作 ,MYSQL直呼“快殺了我吧”,每年的“618”或者過年買票的時(shí)候,都是MYSQL受苦受累的日子啊!
”
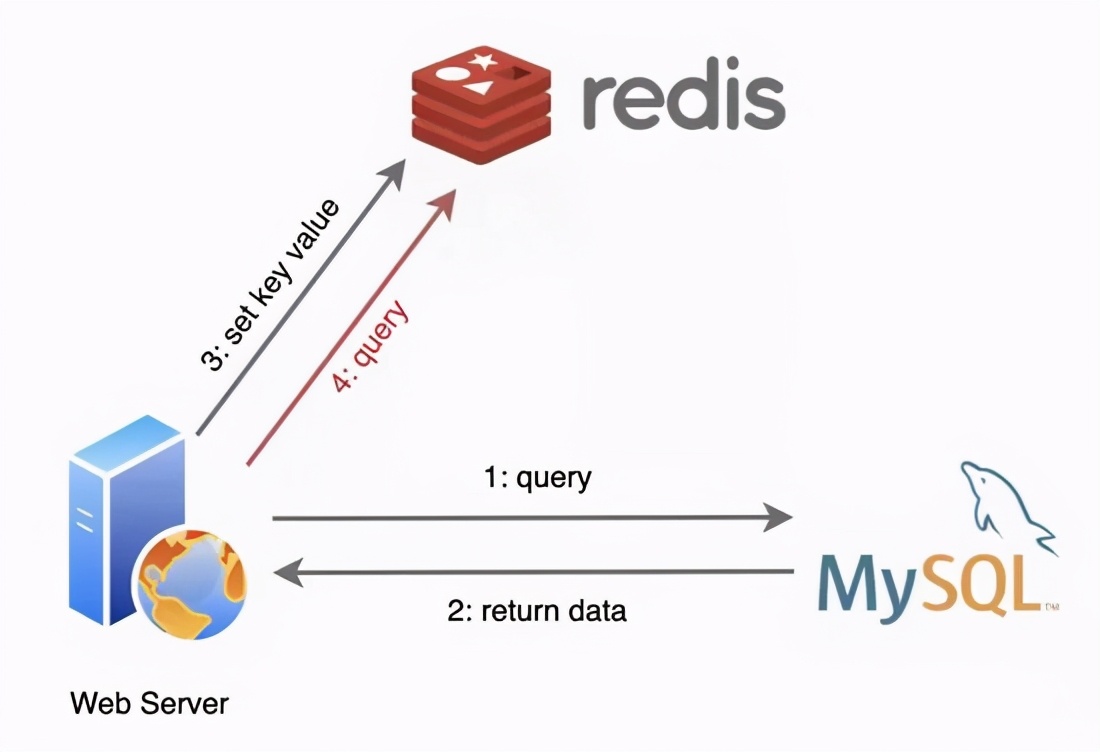
反思 問題 出現(xiàn)在哪里,MYSQL大哥開始頭頭分析起來,原來有一大半的用戶請(qǐng)求tm都是 讀操作 ,而且經(jīng)常又是查一個(gè)東西,簡(jiǎn)直浪費(fèi)我 磁盤IO 的時(shí)間。后來我的爸爸突發(fā)奇想,你看看別人 CPU的緩存 是很快的呀,給數(shù)據(jù)庫(kù)加個(gè)緩存就解決了唄,于是我就出生了!出生沒幾天,我就來給MYSQL大哥解決問題,效果也還不錯(cuò),我們也成為了 好基友 ,常常手拉手在后端服務(wù)器中配合,大致如圖:
為了方便與內(nèi)存對(duì)接,我支持好幾種數(shù)據(jù)結(jié)構(gòu)的存儲(chǔ):
“
String
Hash
List
Set
SortedSet
Bitmap
......
”
因?yàn)榘袽YSQL里 登記的數(shù)據(jù) 都放到我的內(nèi)存里來,就不去執(zhí)行慢如蝸牛的I/O操作,所以下次找我肯定比找MYSQL要 省去 不少的時(shí)間呢。
可別小瞧這一個(gè)微小的操作,可幫MYSQL大哥減輕了不小的負(fù)擔(dān)!我緩存的數(shù)據(jù)也逐漸增長(zhǎng),有
相當(dāng)部分
的時(shí)間都給他擋住了用戶請(qǐng)求,這下他可就清閑自在了!
“
那今天就給大家聊一聊,咱的看家本領(lǐng),內(nèi)存是如何 管 上面的數(shù)據(jù)類型的。說著,我拿筆給大家 畫 一張圖:
”
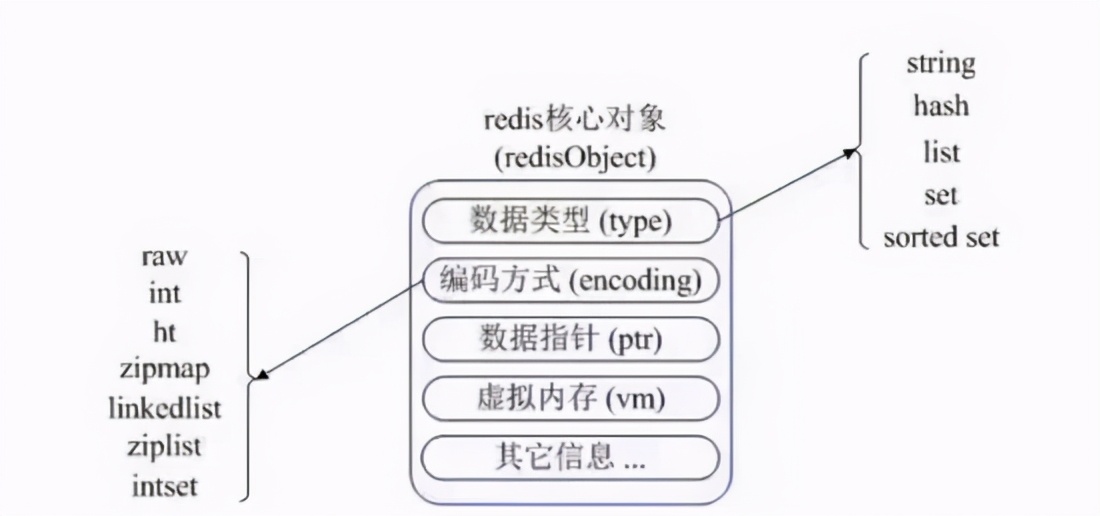
看看,我的肚子里用了一個(gè)redisObject對(duì)象來展示所有的 value和key 。type就是value對(duì)象是 那種 數(shù)據(jù)類型,第二個(gè)encoding就是不同的數(shù)據(jù)類型在Redis內(nèi)部是如何 放 的。
譬如: type=String 則表示value存儲(chǔ)的是一個(gè)普通字符串,那我推斷出 encoding 可以是raw或者是int。但是我稍加思索,哎,還要解釋下 底層數(shù)據(jù)結(jié)構(gòu) ,你知道嗎?底層的底層,你有了解過嗎?跟著我擺起來哈。
下面是各自對(duì)應(yīng)的數(shù)據(jù)結(jié)構(gòu);
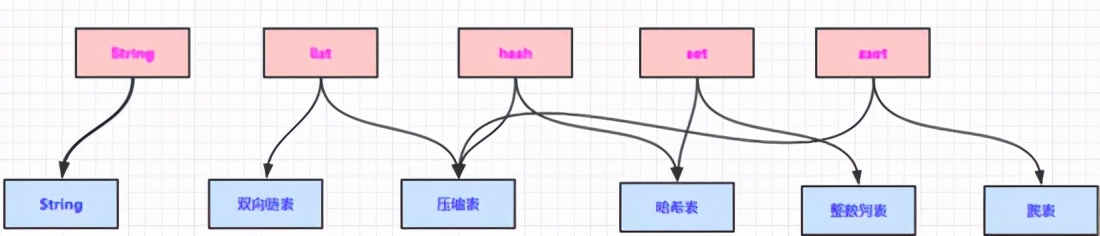
可以看出來,有很多類型都是使用 兩種結(jié)構(gòu) ,就像set在元素比較少的時(shí)候,且都是數(shù)字的情況下會(huì)用 整數(shù)列表 ,隨著數(shù)據(jù)增加就變成 哈希表 。但是我有一個(gè)比較大的疑問,這些類型都對(duì)應(yīng)不同的數(shù)據(jù)結(jié)構(gòu),想想redis 整體的結(jié)構(gòu)
是啥樣的呢?再舉個(gè)例子,現(xiàn)在有一個(gè)
key對(duì)應(yīng)的value
是我們的list類型的,那就對(duì)應(yīng)著上面的雙向鏈表啊?那咱第一步就要找到這個(gè)key,就可找到雙向鏈表了噻;
看看全局哈希表
其實(shí)啊,我這里是有一個(gè)大的哈希表的,在 你們的眼 里可能就是類似的長(zhǎng)數(shù)組,在它上面的每個(gè)空間,都可以看做一個(gè)哈希桶,長(zhǎng)這樣:

每一個(gè)key經(jīng)過我肚子里面的hash算法就會(huì)給你算出一個(gè)位置,怎么來算請(qǐng)看下面:
哈希算法:Redis計(jì)算哈希值和索引值方法如下:
//1、使用字典設(shè)置的哈希函數(shù),計(jì)算鍵 key 的哈希值
hash = dict->type->hashFunction(key);
//2、使用哈希表的sizemask屬性和第一步得到的哈希值,計(jì)算索引值
index = hash & dict->ht[x].sizemask;
那它就對(duì)應(yīng)一個(gè)哈希桶唄。 壯士請(qǐng)注意 ,這個(gè)過程是很快的哈。只有O(1)哦,這個(gè)過程咱就算出 內(nèi)存地址 ,那你就直接去找就行了。然后我們把這個(gè)key放到hash桶里面去。記住啊壯士,這個(gè)桶里面 保存的是引用 哈,不是你的 那個(gè)對(duì)象(狗頭) 。就好比哈希桶里面保存的是key家的門牌號(hào)一樣(實(shí)質(zhì)內(nèi)存地址),那我們就用了0(1)的復(fù)雜度就這樣找到這個(gè)key。,因?yàn)橛胟ey去查找value的時(shí)候,只需要在經(jīng)過依次hash能馬上找到哈希桶,就能定位到這個(gè) 鍵值對(duì) 的內(nèi)存地址了。
那問題來了
“
hash算法是不能保證 所有的key 經(jīng)過算法出來的值都一樣,那就是會(huì)有哈希沖突的存在,就是 兩個(gè)key放到了同一個(gè)桶 中,這可怎么辦呢?
”
我們就用 鏈表 來解決這個(gè)問題,就是兩個(gè)在一個(gè)桶中的元素,我們就用一個(gè)next指針把它們 連在一起 ,經(jīng)過hash算出來之后找到一個(gè)鍵值對(duì), 對(duì)比看著 如果不是,根據(jù)next指針再找下一個(gè)比就行。我們都知道鏈表是一種常用的數(shù)據(jù)結(jié)構(gòu),而C語(yǔ)言內(nèi)部是 沒有內(nèi)置 這種數(shù)據(jù)結(jié)構(gòu)的實(shí)現(xiàn),所以我redis會(huì)自己構(gòu)建了 鏈表 的實(shí)現(xiàn)。
其中每個(gè)
鏈表節(jié)點(diǎn)
使用一個(gè)listNode結(jié)構(gòu)表示:(下圖的右部分):
//鏈表節(jié)點(diǎn)
typedef struct listNode{
struct listNode * prev;
struct listNode * next;
void * value;
}
下圖是有兩部分,由list和listNode兩個(gè)數(shù)據(jù)結(jié)構(gòu)構(gòu)成。一部分是“ 統(tǒng)籌部分 ”是左邊,一部分是“ 具體實(shí)施 “:右邊;
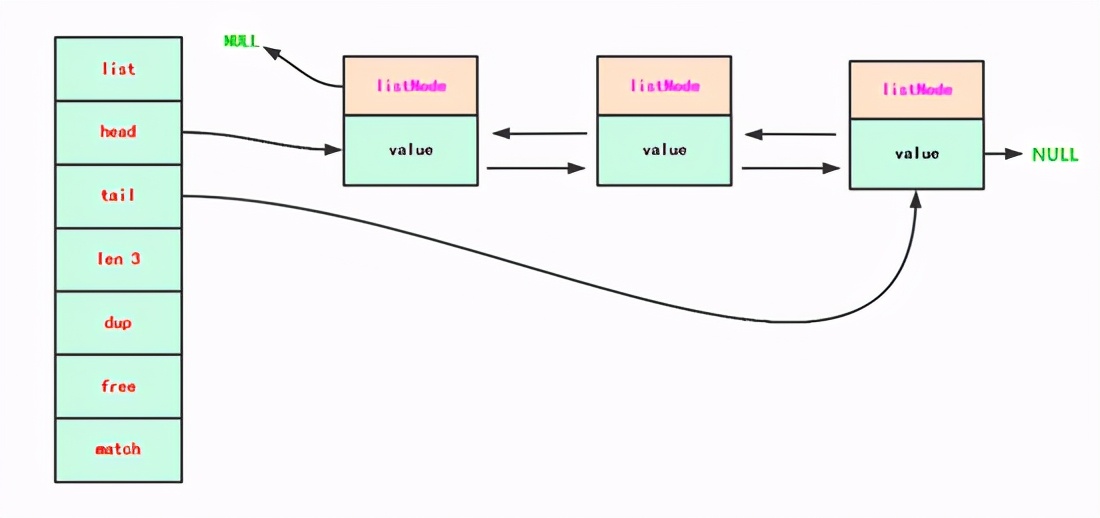
主體”統(tǒng)籌部分“:
head指向具體 雙向鏈表的頭
tail指向具體 雙向鏈表的尾
len雙向鏈表的
長(zhǎng)度
;
具體"實(shí)施方":
可以看出每個(gè)鏈表節(jié)點(diǎn)都有指向 前置節(jié)點(diǎn)prev 和 后置節(jié)點(diǎn)next 的指針,組成一個(gè)雙向鏈表。每個(gè)鏈表結(jié)構(gòu),有表頭表尾指針和鏈表長(zhǎng)度等信息。另外表頭節(jié)點(diǎn)和前置和表尾節(jié)點(diǎn)的 后置都是NULL ,所以是無環(huán)鏈表。
在總結(jié)下:
特點(diǎn):
- 雙端 :鏈表節(jié)點(diǎn)帶有prev和next指針,找到某個(gè)節(jié)點(diǎn)的前置節(jié)點(diǎn)和后置節(jié)點(diǎn)的 時(shí)間復(fù)雜度都是O(N)
- 無環(huán) :表頭節(jié)點(diǎn)的prev指針和表尾節(jié)點(diǎn)的next 都指向NULL,對(duì)立案表的訪問時(shí)以 NULL為截止
- 表頭與表尾 :因?yàn)殒湵韼в衕ead指針和tail指針,程序獲取鏈表頭結(jié)點(diǎn)和尾節(jié)點(diǎn)的時(shí)間復(fù)雜度為O(1)
- 長(zhǎng)度計(jì)數(shù)器 :鏈表中存有記錄鏈表 長(zhǎng)度 的屬性**len
- 多態(tài) :鏈表節(jié)點(diǎn)使用void* 指針來保存節(jié)點(diǎn)值,并且可以通過list結(jié)構(gòu)的dup 、free、match三個(gè)屬性是節(jié)點(diǎn)值設(shè)置類型特定函數(shù)。
這時(shí)我們可以通過直接操作list來操作鏈表會(huì)更加的方便:
typedef struct list {
//表頭節(jié)點(diǎn)
listNode * head;
//表尾節(jié)點(diǎn)
listNode * tail;
//鏈表長(zhǎng)度
unsigned long len;
//節(jié)點(diǎn)值復(fù)制函數(shù)
void *(*dup) (void *ptr);
//節(jié)點(diǎn)值釋放函數(shù)
void (*free) (void *ptr);
//節(jié)點(diǎn)值對(duì)比函數(shù)
int (*match)(void *ptr, void *key);
}
“
那么當(dāng)元素越來越多之后,一個(gè)哈希桶所 對(duì)應(yīng)的鏈表 就會(huì)越來越長(zhǎng),我們知道鏈表上的遍歷時(shí)間復(fù)雜度是O(n)的,那么會(huì)嚴(yán)重 影響性能 ,Redis這種追求快的數(shù)據(jù)庫(kù)看來是絕對(duì)不能夠 容忍 的,那么要怎么處理,就是rehash操作。
”
rehash和漸進(jìn)式rehash操作
redis會(huì)在 內(nèi)部再新建 一個(gè)長(zhǎng)度為原始長(zhǎng)度2倍的空哈希表,然后原哈希表上的元素 重新rehash 到新的哈希表中去,然后我們?cè)偈褂眯碌墓1砑纯伞?/p>
那么,這樣還是有個(gè)問題要解決呀!
要知道redis中存儲(chǔ)的數(shù)據(jù)可能是成百萬上千萬的,我們 重新rehash 一次未免太耗時(shí)了吧,因?yàn)閞edis中操作大部分是 單線程 的。
“
這個(gè)過程可能會(huì)阻斷其他操作很長(zhǎng)時(shí)間,這是不能忍受的,那要怎么處理呢?
”
首先redis是采用了 漸進(jìn)式rehash 的操作,就是會(huì)有一個(gè)變量,指向第一個(gè)哈希桶,然后redis每執(zhí)行一個(gè)添加key,刪除key的類似命令,就順便 copy一個(gè)哈希桶中的數(shù)據(jù) 到新的哈希表中去,這樣細(xì)水長(zhǎng)流的操作,是不會(huì)影響什么性能,就會(huì)所有的數(shù)據(jù)都被重新hash到新的哈希表中。
那么在這個(gè)過程中,當(dāng)然再有寫的操作,會(huì)直接把數(shù)據(jù)放到新的哈希表中,保證舊的肯定有 copy完 的時(shí)候,如果這段時(shí)間對(duì)數(shù)據(jù)庫(kù)的操作比較少,也沒有關(guān)系,redis 內(nèi)部也有定時(shí) 任務(wù),每隔一段時(shí)間也會(huì)copy一次。
動(dòng)態(tài)字符串SDS
SDS的全稱"simple dynamic string"。redis中所有場(chǎng)景中出現(xiàn)的字符串,基本都是由SDS來實(shí)現(xiàn)的。
所有 非數(shù)字的key 。例如 set msg "hello world" 中的key msg.
字符串?dāng)?shù)據(jù)類型的值 。例如 set msg "hello world"中的msg的值"hello wolrd"
最后是兩者結(jié)合:
非字符串?dāng)?shù)據(jù)類型中的“字符串值”
。例如 RPUSH fruits "Apple""banana""cherry"中的"apple" "banana" "cherry"都是;
上面的例子,我們可以很直觀地看到我們?cè)谄匠J褂胷edis的時(shí)候,創(chuàng)建的字符串到底是一個(gè)什么樣子的數(shù)據(jù)類型。除了用來保存字符串以外,SDS還被用作 緩沖區(qū) (buffer)AOF模塊中的 AOF緩沖區(qū) 。
SDS 的定義
動(dòng)態(tài)字符串的結(jié)構(gòu):
/*
* 保存字符串對(duì)象的結(jié)構(gòu)
*/
struct sdshdr {
// buf 中已占用空間的長(zhǎng)度
int len;
// buf 中剩余可用空間的長(zhǎng)度
int free;
// 數(shù)據(jù)空間
char buf[];
};
SDS長(zhǎng)這樣:
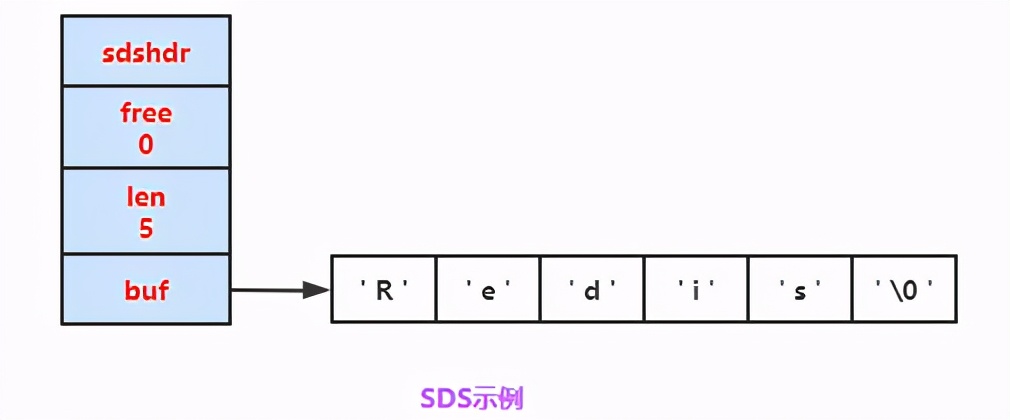
SDS示例
- len 變量,用于記錄buf 中已經(jīng) 使用的空間長(zhǎng)度 (這里指出Redis的長(zhǎng)度為5);
- free 變量,用于記錄buf修改后的還有 空余的空間 ,一般初次分配空間的時(shí)候,是沒有空余的,在對(duì)字符串修改的時(shí)候,就會(huì)有剩余空間出現(xiàn);
- buf 字符數(shù)組,用來記錄 我們的字符串 (記錄Redis)
SDS 與 C 字符串的區(qū)別
那么傳統(tǒng)的C字符串使用長(zhǎng)度為 N+1的字符串?dāng)?shù)組 來表示 長(zhǎng)度為N的字符串 ,所以為了獲取一個(gè)長(zhǎng)度為C字符串的長(zhǎng)度,必須遍歷整個(gè)字符串。
這樣做在獲取字符串長(zhǎng)度的時(shí)候,字符串?dāng)U展等操作的時(shí)候 效率比較低 。C語(yǔ)言用這種 簡(jiǎn)單 的字符串表示方式,但是并不能滿足Redis對(duì)字符串在安全性、效率以及功能方面的要求:
獲取字符串長(zhǎng)度(SDS O(1)/C 字符串 O(n))
“
和C 字符串不同,SDS的數(shù)據(jù)結(jié)構(gòu)中,有專門用于 保存字符串長(zhǎng)度 的變量,我們可以通過獲取len屬性的值,如下圖的,直接知道字符串長(zhǎng)度:
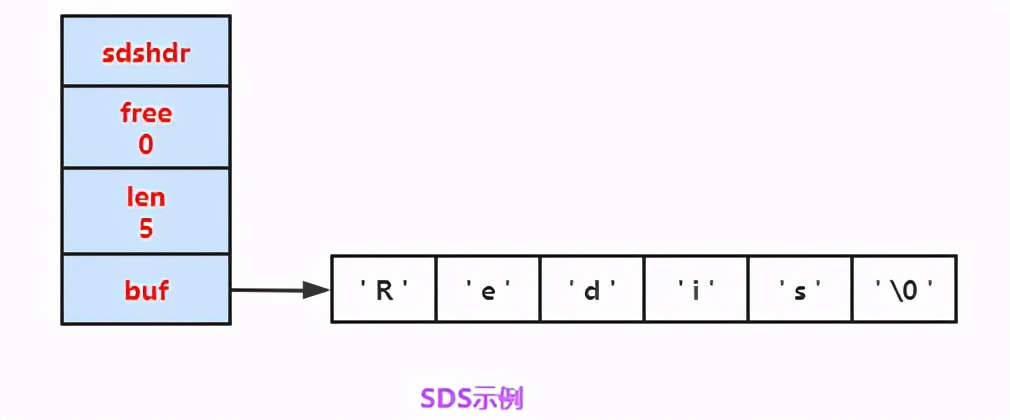
”
杜絕緩沖區(qū)溢出
C 字符串是不會(huì)記錄字符串長(zhǎng)度的,除了獲取的時(shí)候復(fù)雜度高以外,還容易導(dǎo)致緩沖區(qū)溢出。
我們現(xiàn)在假設(shè)程序中有兩個(gè)在內(nèi)存中 緊鄰著的字符串s1和s2 ,其中s1保存了字符串“ redis ”,而s2 則保存了字符串“ MongoDb ”:
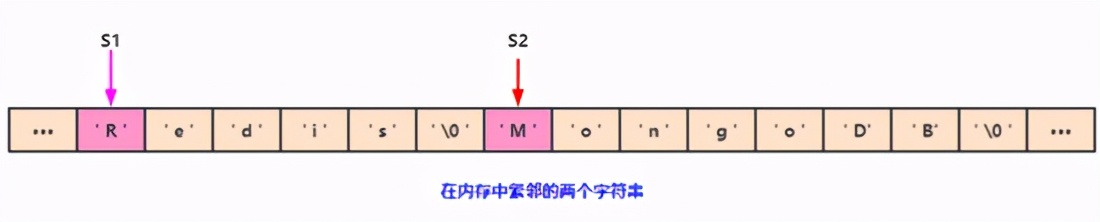
如果我們現(xiàn)在將s1的內(nèi)容修改為 redis cluster ,但是我又忘了重新為 s1分配足夠的空間 ,這時(shí)候就會(huì)出現(xiàn)以下問題:

我們可以看到,原本s2中的內(nèi)容已經(jīng) 被S1的給占領(lǐng) 了,s2現(xiàn)在是cluster,而不是“Mongodb”。Redis 中SDS 的 空間分配策略 完全 杜絕 了發(fā)生緩沖區(qū)溢出的可能性:
“
我們需要對(duì)一個(gè)SDS進(jìn)行修改的時(shí)候,redis會(huì)在執(zhí)行 拼接操作 之前,預(yù)先檢查給定SDS空間是否是足夠的,如果不夠,會(huì)先 拓展SDS 的空間 ,然后再執(zhí)行拼接操作;
”
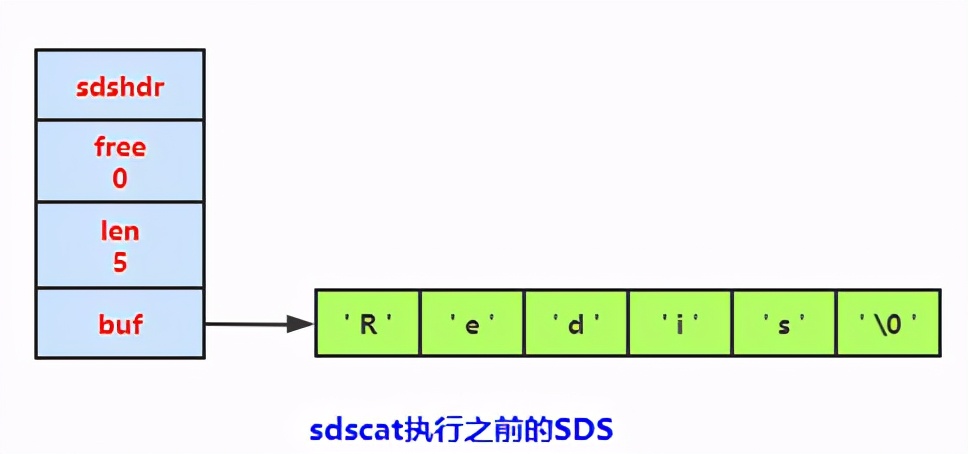
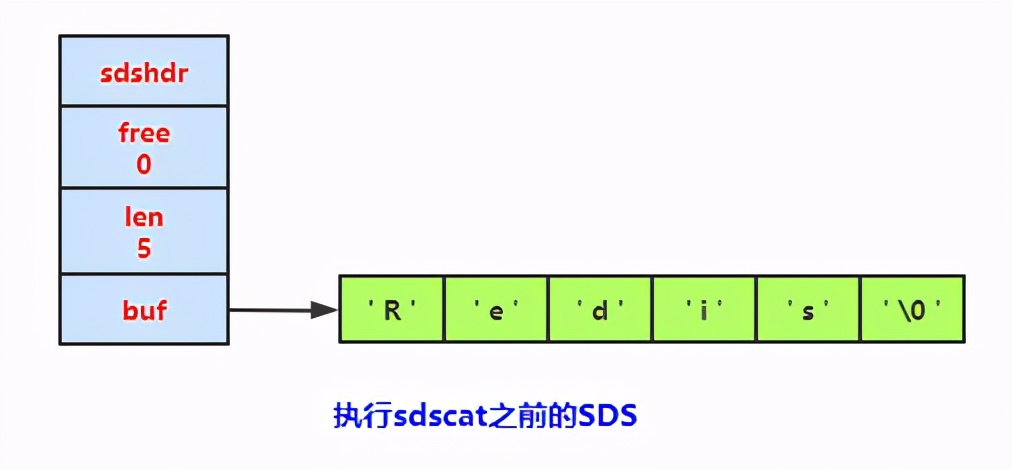
減少修改字符串時(shí)帶來的內(nèi)存重分配次數(shù)
C字符串在進(jìn)行字符串的擴(kuò)充和收縮的時(shí)候,都常常會(huì)面臨著 內(nèi)存空間 重新分配的問題。
- 字符串拼接會(huì)產(chǎn)生字符串的內(nèi)存空間的 擴(kuò)充 ,在拼接的過程中,原來的字符串的大小很可能 小于 拼接后的字符串的大小,那么這樣的話,就會(huì)導(dǎo)致一旦 忘記申請(qǐng) 分配空間,就會(huì)導(dǎo)致內(nèi)存的溢出。
- 字符串在進(jìn)行收縮的時(shí)候,內(nèi)存空間會(huì) 相應(yīng)的收縮 ,而如果在進(jìn)行字符串的切割的時(shí)候,沒有對(duì)內(nèi)存的空間進(jìn)行一個(gè)重新分配,那么這部分多出來的空間就成為了內(nèi)存泄露。*
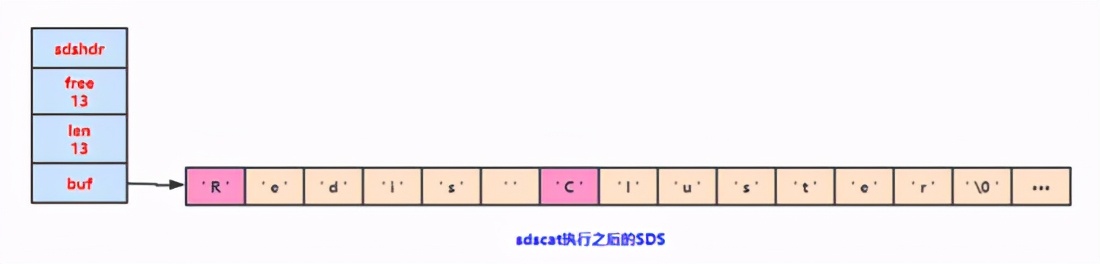
下面我們對(duì)SDS進(jìn)行拓展,那就需要進(jìn)行 空間的拓展 ,redis會(huì)將SDS的長(zhǎng)度修改為13字節(jié),并且將未使用空間同樣修改成1字節(jié);
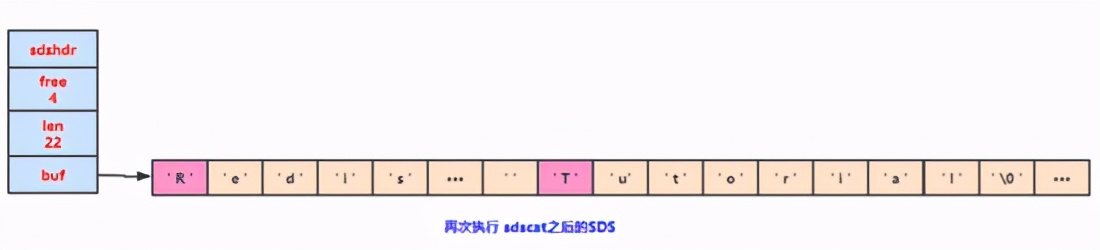
因?yàn)樵谏弦淮涡薷淖址臅r(shí)候已經(jīng)拓展了空間,再次進(jìn)行修改字符串的時(shí)候你會(huì)發(fā)現(xiàn)空間是足夠使用,因此就不要進(jìn)行空間拓展了。
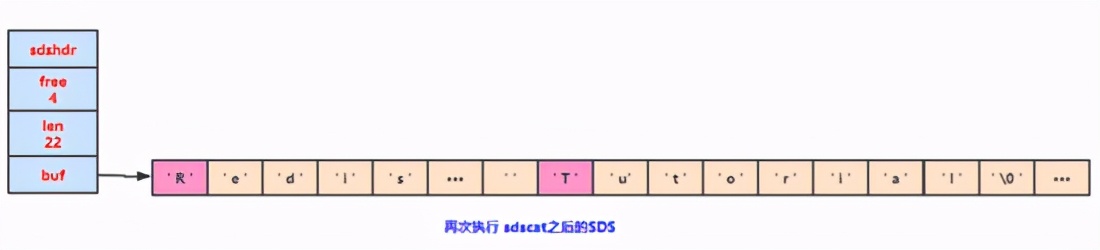
通過這種 預(yù)分配策略 ,SDS將連續(xù)增長(zhǎng)N次字符串所需的 內(nèi)存重分配次數(shù) 從必定N次會(huì)降低為最多N次
惰性空間釋放
我們?cè)谟^察SDS的結(jié)構(gòu)的時(shí)候,可以看到里面有free屬性,是用于 記錄空余空間 的。我們除了在拓展字符串的時(shí)候會(huì)使用到free來進(jìn)行記錄空余空間以外,在對(duì)字符串進(jìn)行收縮的時(shí)候,我們也可以使用free 屬性來進(jìn)行 記錄剩余空間 ,這樣做的好處就是避免下次對(duì)字符串進(jìn)行再次修改的時(shí)候,我們 再對(duì) 字符串的空間進(jìn)行拓展。
“
但是,我們并不是說不能釋放SDS中空余的空間,SDS 提供了相應(yīng)的API,讓我們可以在 有需要 的時(shí)候,會(huì) 自行釋放 SDS的空余空間;
”
通過惰性空間釋放,SDS避免了縮短字符串時(shí)所需的 內(nèi)存重分配 操作,并未將來可能有的增長(zhǎng)操作提供了優(yōu)化,嗯值得點(diǎn)贊!
二進(jìn)制安全
強(qiáng)調(diào) 的是C字符串中的字符必須符合某種 編碼 ,并且除了字符串的末尾之外,字符串里面不包含 空字符 ,否則最先被程序讀入的空字符將被誤認(rèn)為是字符串結(jié)尾,那就尷尬了,這些 限制 使得C字符串只能保存文本數(shù)據(jù),而不能保存想圖片,音頻,視頻,壓縮文件這樣的 二進(jìn)制 數(shù)據(jù)。
“
但是在Redis中,不是靠空字符來判斷字符串的結(jié)束的,而是通過 len 這個(gè)屬性。那么,即便是中間出現(xiàn)了空字符對(duì)于SDS來說,讀取該字符仍然是可以的。
”
如這樣:
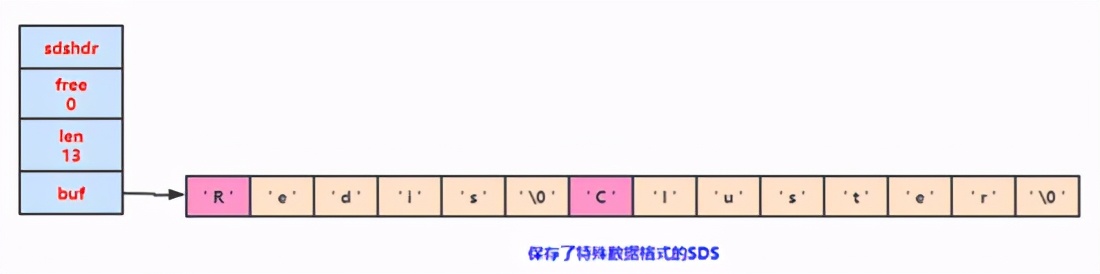
兼容部分C字符串函數(shù)
雖然SDS的API都是二進(jìn)制安全的,但他們同樣要遵循C字符串以 空字符串結(jié)尾 的慣例。
再次總結(jié)
|
C字符串 |
SDS |
|
獲取字符串長(zhǎng)度的復(fù)雜度為O(N) |
獲取字符串長(zhǎng)度的復(fù)雜度為O(1) |
|
API 是不安全的,可能會(huì)造成緩沖區(qū)溢出 |
API 是安全的,不會(huì)造成緩沖區(qū)溢出 |
|
修改字符串長(zhǎng)度N次必然需要執(zhí)行N次內(nèi)存重分配 |
修改字符串長(zhǎng)度N次最多執(zhí)行N次內(nèi)存重分配 |
|
只能保存文本數(shù)據(jù) |
可以保存二進(jìn)制數(shù)據(jù)和文本文數(shù)據(jù) |
|
可以使用所有<String.h>庫(kù)中的函數(shù) |
可以使用一部分<string.h>庫(kù)中的函數(shù) |
壓縮表
壓縮表是一種Redis用來 節(jié)省內(nèi)存 的一系列特殊編碼的 順序性連續(xù)存儲(chǔ) 的表結(jié)構(gòu),我們知道數(shù)組這種數(shù)據(jù)結(jié)構(gòu),每一個(gè)空間的大小都是一樣的,這樣我們存儲(chǔ)較小元素節(jié)點(diǎn)的時(shí)候就會(huì)造成 內(nèi)存的浪費(fèi) ,而壓縮鏈表可以做到每一個(gè)元素的節(jié)點(diǎn)的 大小都不一樣 。當(dāng)一個(gè)哈希鍵只含少量鍵值對(duì),并且每個(gè)鍵值對(duì)的鍵和值也是小整數(shù)值或者長(zhǎng)度比較短的字符串的時(shí)候,Redis就采用壓縮列表做底層實(shí)現(xiàn);
長(zhǎng)這樣:

圖里 entry 的結(jié)構(gòu)是這樣的:

previous_entry_length屬性以字節(jié)為單位,記錄了壓縮列表中 前一個(gè)節(jié)點(diǎn)的長(zhǎng)度 。該屬性的長(zhǎng)度可以是1字節(jié)或者是5字節(jié)。如果前一個(gè)節(jié)點(diǎn)的長(zhǎng)度 小于
254 字節(jié),那么該屬性長(zhǎng)度為1字節(jié),保存的是小于 254的值。那如果前一節(jié)點(diǎn)的長(zhǎng)度
大于等于
254字節(jié),那么長(zhǎng)度需要為5字節(jié),屬性的第一字節(jié)會(huì)被設(shè)置為0xFE (254)之后的4個(gè)字節(jié)保存其長(zhǎng)度。
參數(shù):
zlbytes :4 字節(jié)。記錄整個(gè)壓縮列表占用的內(nèi)存字節(jié)數(shù),在內(nèi)存重分配或者計(jì)算 zlend 的位置時(shí)使用。
zltail :4 字節(jié)。記錄壓縮列表表尾節(jié)點(diǎn)記錄壓縮列表的起始地址有多少個(gè)字節(jié),可以通過該屬性直接確定表尾節(jié)點(diǎn)的地址,無需遍歷。
zllen :2 字節(jié)。記錄了壓縮列表包含的節(jié)點(diǎn)數(shù)量,由于只有2字節(jié)大小,那么小于65535時(shí),表示節(jié)點(diǎn)數(shù)量。等于 65535 時(shí),需要遍歷得到總數(shù)。
entry :列表節(jié)點(diǎn),長(zhǎng)度不定,由內(nèi)容決定。
zlend
:1字節(jié),特殊值 0xFF ,來標(biāo)記壓縮列表的結(jié)束。
壓縮列表節(jié)點(diǎn)保存的是 一個(gè)字節(jié)數(shù)組 或者 一個(gè)整數(shù)值 :字節(jié)數(shù)組可以是下列值:
- 長(zhǎng)度小于等于 2^6-1 字節(jié)的字節(jié)數(shù)組
- 長(zhǎng)度小于等于 2^14-1 字節(jié)的字節(jié)數(shù)組
- 長(zhǎng)度小于等于 2^32-1 字節(jié)的字節(jié)數(shù)組整數(shù)可以是六種長(zhǎng)度;
- 4 位長(zhǎng),介于 0 到 12 之間的無符號(hào)整數(shù)
- 1 字節(jié)長(zhǎng)的有符號(hào)整數(shù)
- 3 字節(jié)長(zhǎng)的有符號(hào)整數(shù)
- int16_t 類型整數(shù)
- int32_t 類型整數(shù)
- int64_t 類型整數(shù)
元素的遍歷
先找到列表尾部元素:
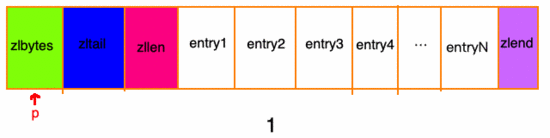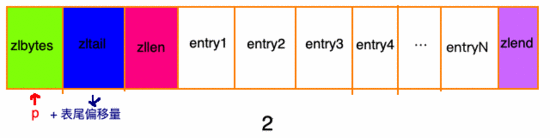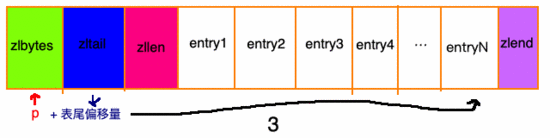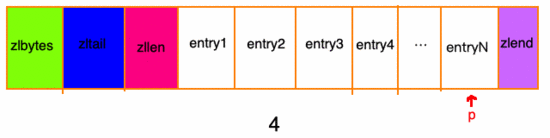
然后再根據(jù) ziplist 節(jié)點(diǎn)元素中的 previous_entry_length 屬性,來逐個(gè)來遍歷:
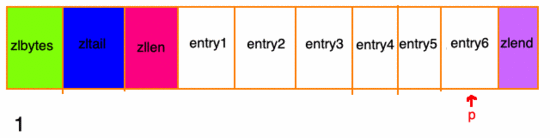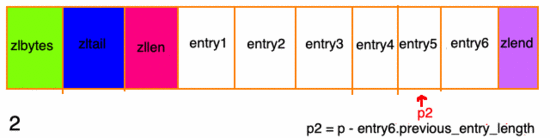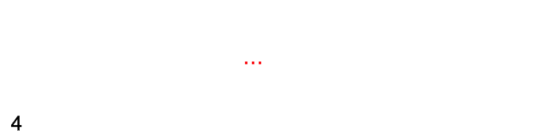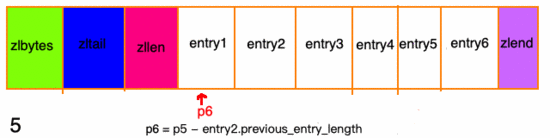
連鎖更新
再次看看 entry元素的結(jié)構(gòu),有一個(gè) previous_entry_length 字段,它的長(zhǎng)度要么都是1個(gè)字節(jié),要么都是5個(gè)字節(jié):
- 前一節(jié)點(diǎn)的長(zhǎng)度小于 254 字節(jié),則 previous_entry_length長(zhǎng)度為1字節(jié)
- 前一節(jié)點(diǎn)的長(zhǎng)度小于 254 字節(jié),則 previous_entry_length長(zhǎng)度為5字節(jié)假如現(xiàn)在有一組壓縮列表,長(zhǎng)度都在250字節(jié)至253字節(jié)之間,突然新增一新節(jié)點(diǎn) new, 長(zhǎng)度大于等于254字節(jié),會(huì)出現(xiàn):
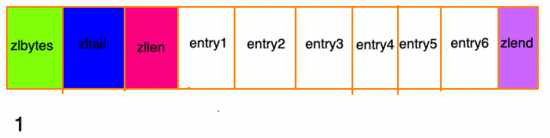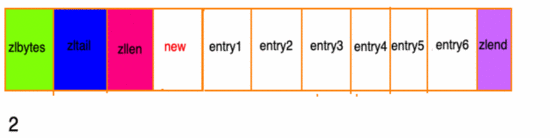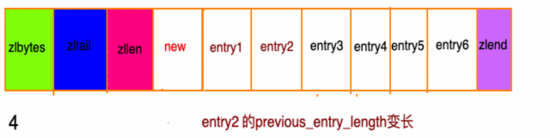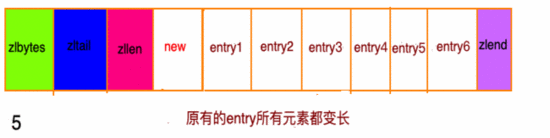
g3
程序需要 不斷 的對(duì)壓縮列表進(jìn)行 空間重分配 工作,直到結(jié)束。
除了增加操作,刪除操作也有可能帶來“連鎖更新”。請(qǐng)看下面這張圖, ziplist 中所有 entry 節(jié)點(diǎn)的長(zhǎng)度都在250字節(jié)至253字節(jié)之間,big節(jié)點(diǎn)長(zhǎng)度大于254字節(jié),small節(jié)點(diǎn)小于254字節(jié):
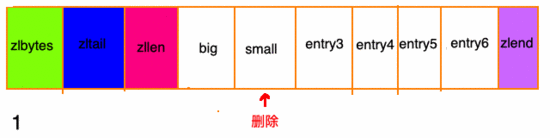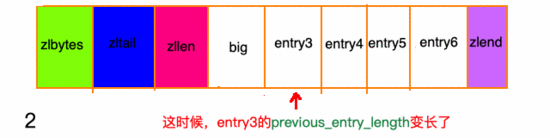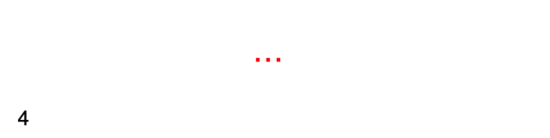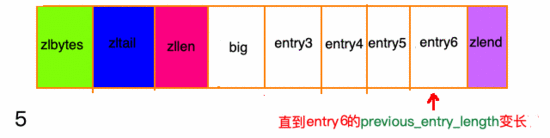
在我看來,壓縮列表實(shí)際上 類似于一個(gè)數(shù)組 ,數(shù)組中的每一個(gè)元素都對(duì)應(yīng)保存一個(gè)數(shù)據(jù)。和數(shù)組不同的是,壓縮列表在 表頭有三個(gè)字段 zlbytes、zltail 和 zllen,分別表示列表長(zhǎng)度、列表尾的偏移量和列表中的entry數(shù);壓縮列表在表尾還有一個(gè) zlend ,表示列表結(jié)束罷了。
字典
“
又叫 符號(hào)表 或者關(guān)聯(lián)數(shù)組、或映射(map),是一種用于 保存鍵值對(duì) 的抽象數(shù)據(jù)結(jié)構(gòu)。字典中的每一個(gè)鍵key都是唯一的,通過key可以對(duì)值來進(jìn)行 查找或修改 。C語(yǔ)言中沒有內(nèi)置這種數(shù)據(jù)結(jié)構(gòu)的實(shí)現(xiàn),所以字典依然是 Redis自己實(shí)現(xiàn)的;示例:
”
redis > SET msg "hello world"
OK
(“msg”,“hello world”)這個(gè)就是字典;
哈希表結(jié)構(gòu):
typedef struct dictht{
//哈希表數(shù)組
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩碼,用于計(jì)算索引值
//總是等于 size-1
unsigned long sizemask;
//該哈希表已有節(jié)點(diǎn)的數(shù)量
unsigned long used;
}dictht
哈希表是數(shù)組(表)table 組成,table里面每個(gè)元素都是指向 dict.h 或者 dictEntry 這個(gè)結(jié)構(gòu),dictEntry 結(jié)構(gòu):
typedef struct dictEntry{
//鍵
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一個(gè)哈希表節(jié)點(diǎn),形成鏈表
struct dictEntry *next;
}dictEntry
哈希表就略微有點(diǎn)復(fù)雜。哈希表的制作方法一般有兩種,一種是: 開放尋址法 ,一種是拉鏈法。redis的哈希表的制作使用的是 拉鏈法 。
整體結(jié)構(gòu)如圖:
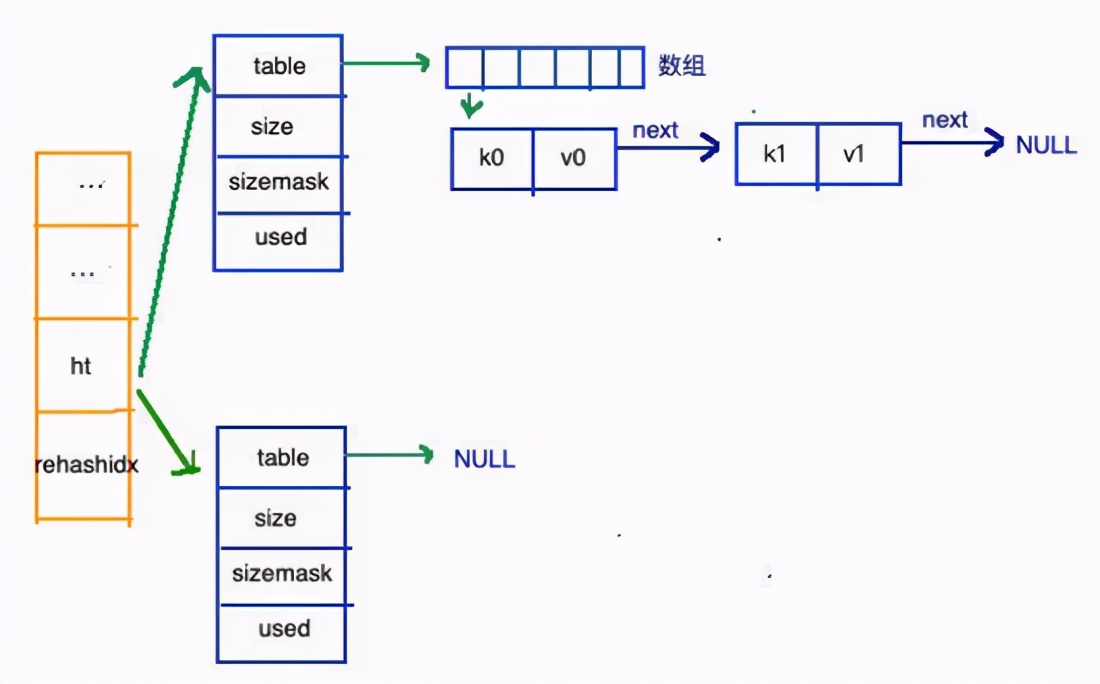
哈希1
“
也是分為兩部分:左邊橘黃色部分和右邊藍(lán)色部分,同樣,也是”統(tǒng)籌“和”實(shí)施“的關(guān)系。具體 哈希表的實(shí)現(xiàn) ,都是在 藍(lán)色部分 實(shí)現(xiàn)的,好!先來看看藍(lán)色部分:
”
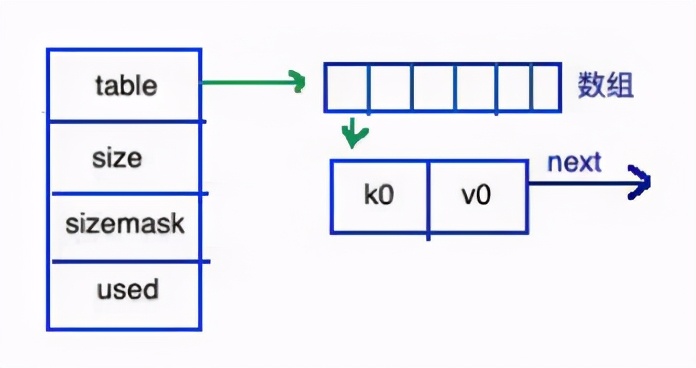
這也會(huì)分為左右兩邊“統(tǒng)籌”和“實(shí)施”的兩部分。
右邊部分很容易理解:就是通常用 拉鏈表實(shí)現(xiàn) 的哈希表的樣式;數(shù)組就是bucket,一般不同的key首先會(huì)定位到不同的bucket,若key重復(fù),就用鏈表把 沖突的key串 起來。
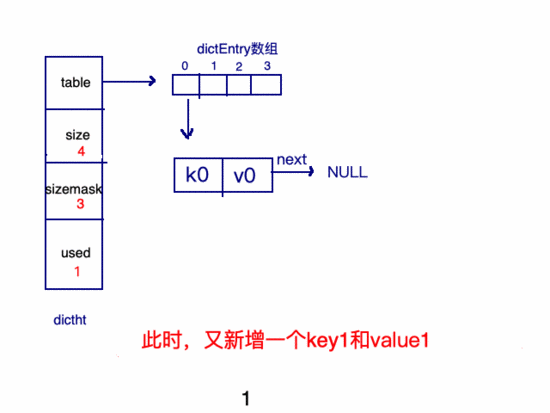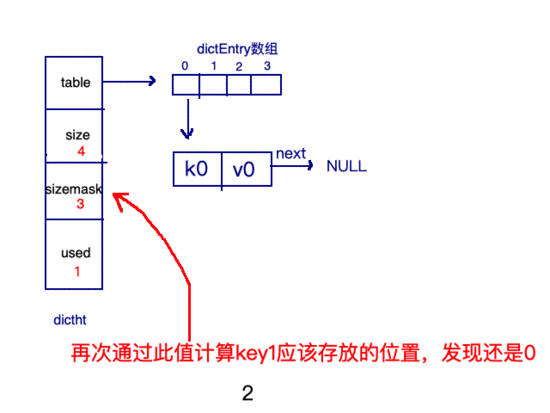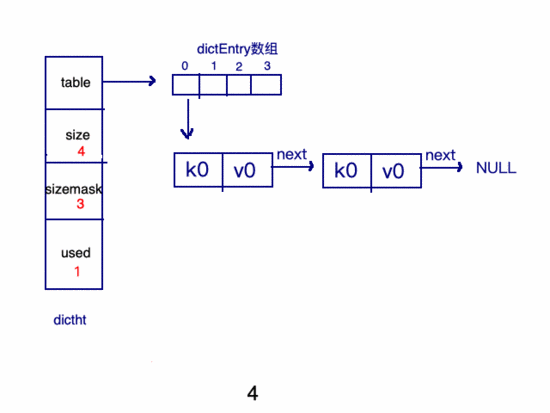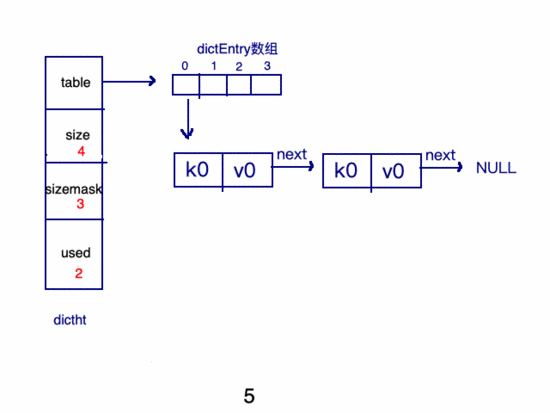
新建key的過程:
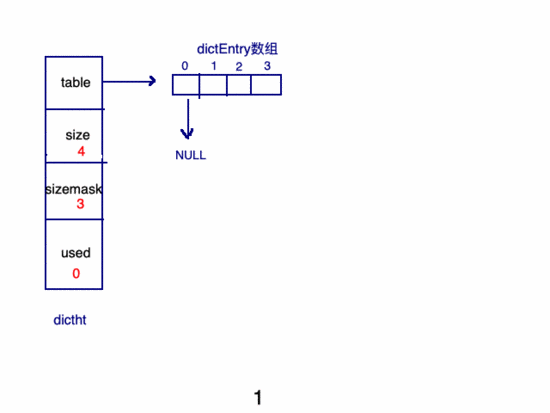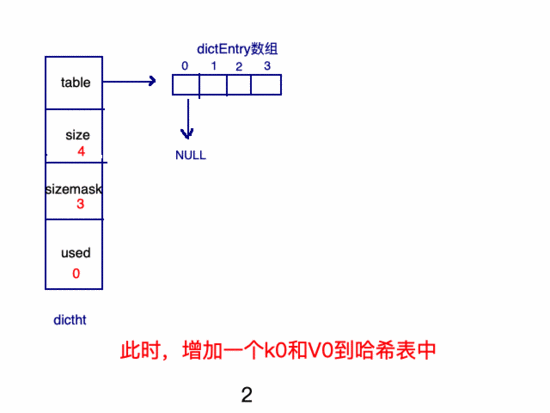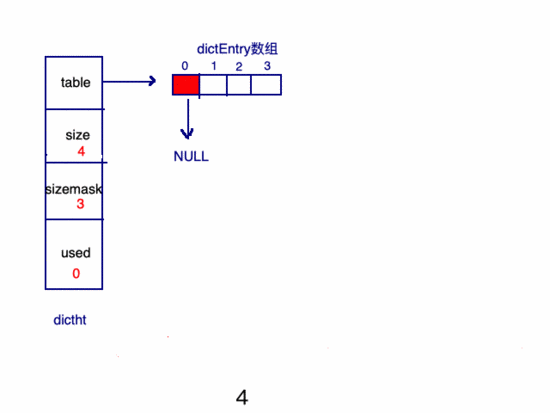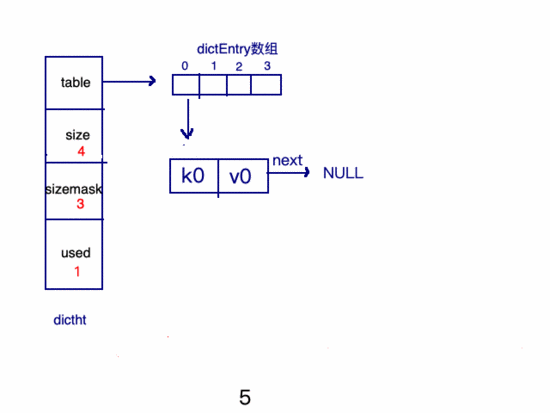
哈3
假如重復(fù)了:
哈4
rehash
“
再來看看哈希表總體圖中左邊橘黃色的“統(tǒng)籌”部分,其中有兩個(gè)關(guān)鍵的屬性:ht和 rehashidx。ht是一個(gè) 數(shù)組 ,有且只有倆元素ht[0]和ht[1];其中,ht[0]存放的是 redis中使用的哈希表 ,而ht[1]和rehashidx和哈希表是有 rehash 有關(guān)系的。
”
rehash指的是 重新計(jì)算 鍵的哈希值和索引值,然后將鍵值對(duì) 重排 的過程。
加載因子
(load factor)=ht[0].used/ht[0].size;
擴(kuò)容和收縮標(biāo)準(zhǔn)
擴(kuò)容:
- 沒有 執(zhí)行BGSAVE和BGREWRITEAOF指令的情況下,哈希表的加載因子大于 等于1。
- 正在執(zhí)行 BGSAVE和BGREWRITEAOF指令的情況下,哈希表的加載因子大于 等于5 。
收縮:
- 加載因子小于0.1時(shí),程序自動(dòng)開始對(duì)哈希表進(jìn)行收縮操作;
擴(kuò)容和收縮的數(shù)量;
擴(kuò)容:
第一個(gè)大于等于 ht[0].used*2的 2^n(2的n次方冪);
收縮:
第一個(gè)大于等于 ht[0].used的 2^n(2的n次方冪)。(以下部分屬于細(xì)節(jié)分析,可以跳過直接看擴(kuò)容步驟)
對(duì)于收縮,我當(dāng)時(shí)陷入了疑慮:收縮標(biāo)準(zhǔn)是加載因子 小于0.1 的時(shí)候,也就是說假如哈希表中有4個(gè)元素的話,哈希表的長(zhǎng)度只要大于40,就會(huì)進(jìn)行收縮,假如有一個(gè)長(zhǎng)度大于40,但是 存在的元素為4 即( ht[0].used為4)的哈希表,進(jìn)行收縮,那收縮后的值為多少?
我想了一下:按照前文所講的內(nèi)容,應(yīng)該是4。但是,假如是4, 存在和收縮后的長(zhǎng)度相等 ,是不是又該擴(kuò)容?
假如收縮后 長(zhǎng)度為4
,不僅不會(huì)收縮,甚至還會(huì)
報(bào)錯(cuò)
;
我們回過頭來再看看設(shè)定:題目可能成立嗎?哈希表的擴(kuò)容都是 2倍增長(zhǎng)的 ,最小是4, 4 ===》 8 ====》 16 =====》 32 ======》 64 ====》 128
“
也就是說:不存在長(zhǎng)度為 40多的情況,只能是64。但是如果是64的話,64 X 0.1(收縮界限)= 6.4 ,也就是說在減少到6的時(shí)候,哈希表就會(huì)收縮,會(huì)縮小到多少呢?是8。此時(shí),再繼續(xù)減少到4,也不會(huì)再收縮了。所以,根本不存在一個(gè)長(zhǎng)度大于40,但是存在的元素為4的哈希表的。
”
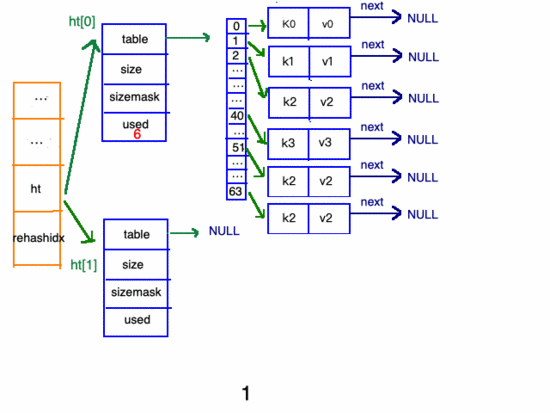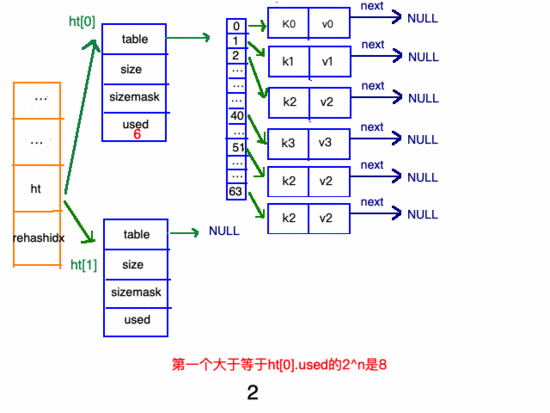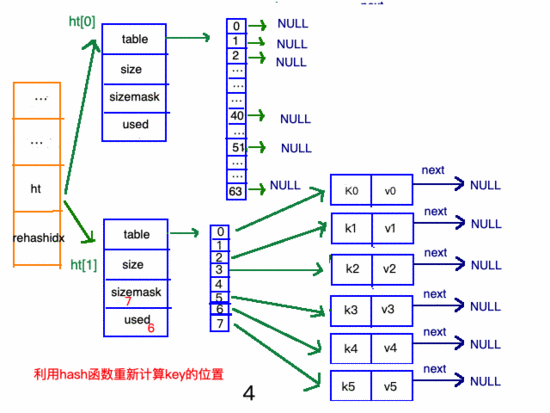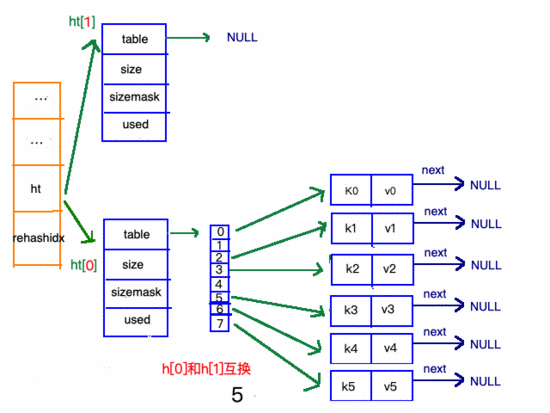
擴(kuò)容步驟
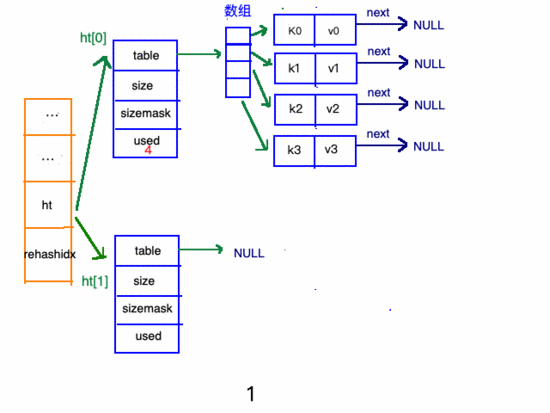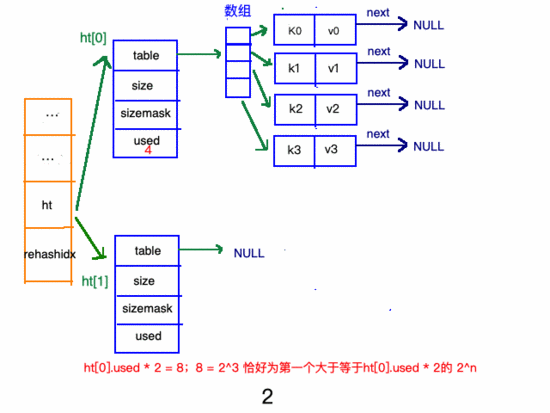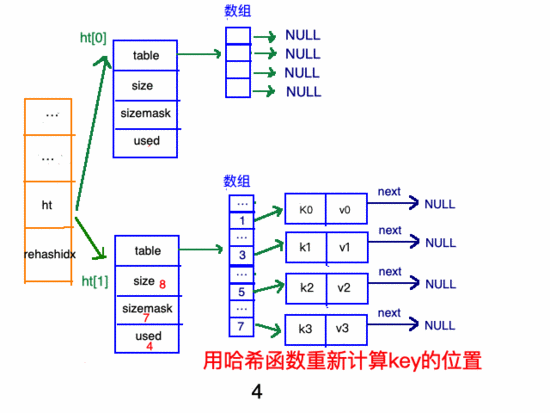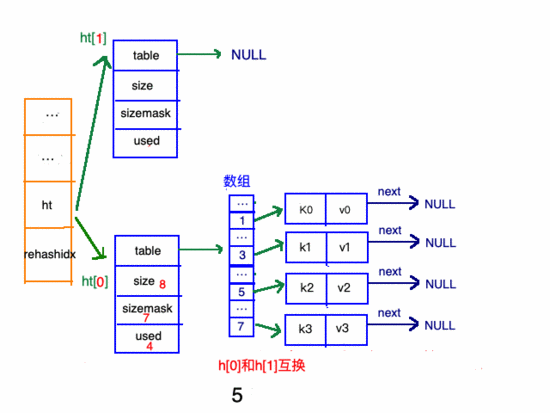
收縮步驟
漸進(jìn)式refresh
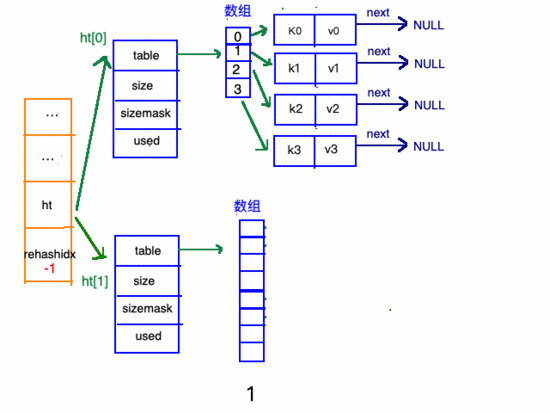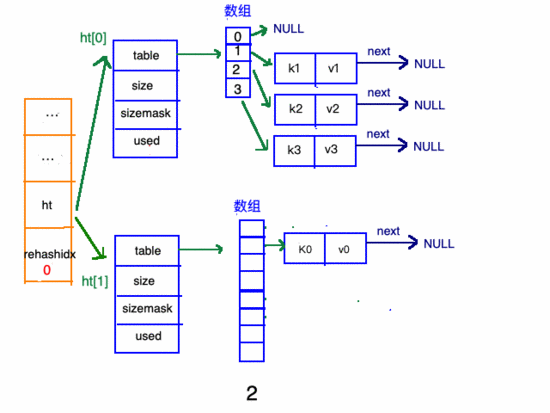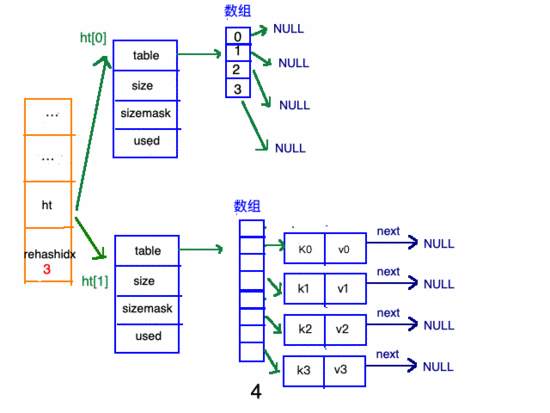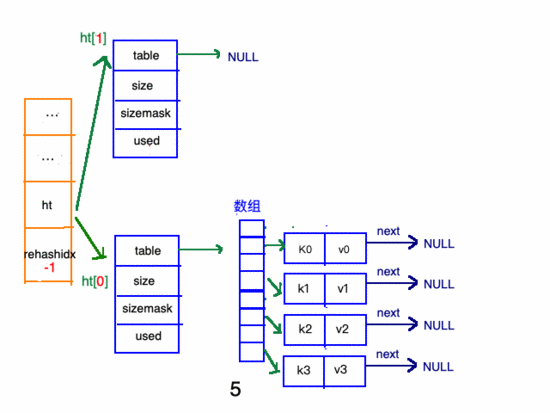
在"擴(kuò)容步驟"和"收縮步驟" 兩幅動(dòng)圖中每幅圖的 第四步驟 “將ht[0]中的數(shù)據(jù)利用哈希函數(shù) 重新計(jì)算 ,rehash到ht[1]”,并不是一步完成的,而是分成N多步,循序漸進(jìn)地完成的。因?yàn)閔ash中有可能存放幾千萬甚至上億個(gè)key,畢竟Redis中每個(gè) hash中可以存 2^32-1 鍵值對(duì) (40多億),假如一次性將這些鍵值rehash的話,可能會(huì)導(dǎo)致服務(wù)器在一段時(shí)間內(nèi)停止服務(wù),畢竟哈希函數(shù)就得 計(jì)算一陣子呢 (對(duì)吧(#^.^#))。
哈希表的refresh是分多次、漸進(jìn)式進(jìn)行的。
漸進(jìn)式refresh和下圖中左邊橘黃色的“統(tǒng)籌”部分中的rehashidx密切相關(guān):
- rehashidx 的數(shù)值就是現(xiàn)在rehash的 元素位置
- rehashidx 等于-1的時(shí)候說明沒有在進(jìn)行refresh
甚至在進(jìn)行期間,每次對(duì)哈希表的增刪改查操作,除了正常執(zhí)行之外,還會(huì)順帶將ht[0]哈希表相關(guān)鍵值對(duì) rehash 到ht[1]。
以擴(kuò)容步驟 舉例 :
intset
整數(shù)集合是 集合鍵 的底層實(shí)現(xiàn)方式之一。
跳表
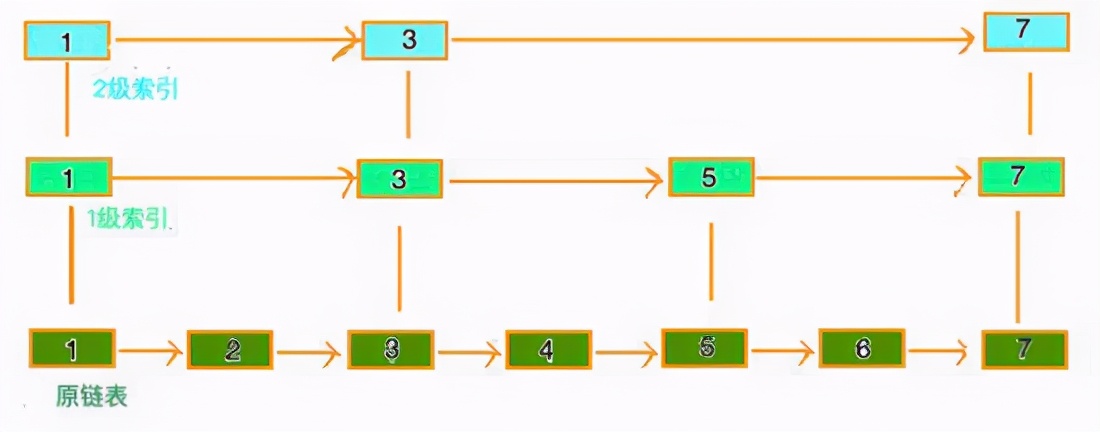
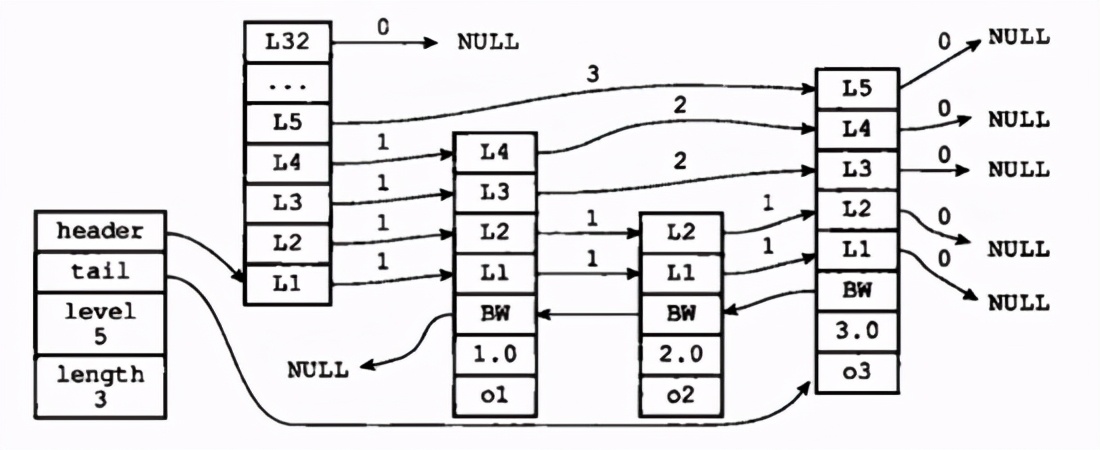
跳表這種數(shù)據(jù)結(jié)構(gòu)長(zhǎng)這樣:
redis中把跳表抽象成如下所示:
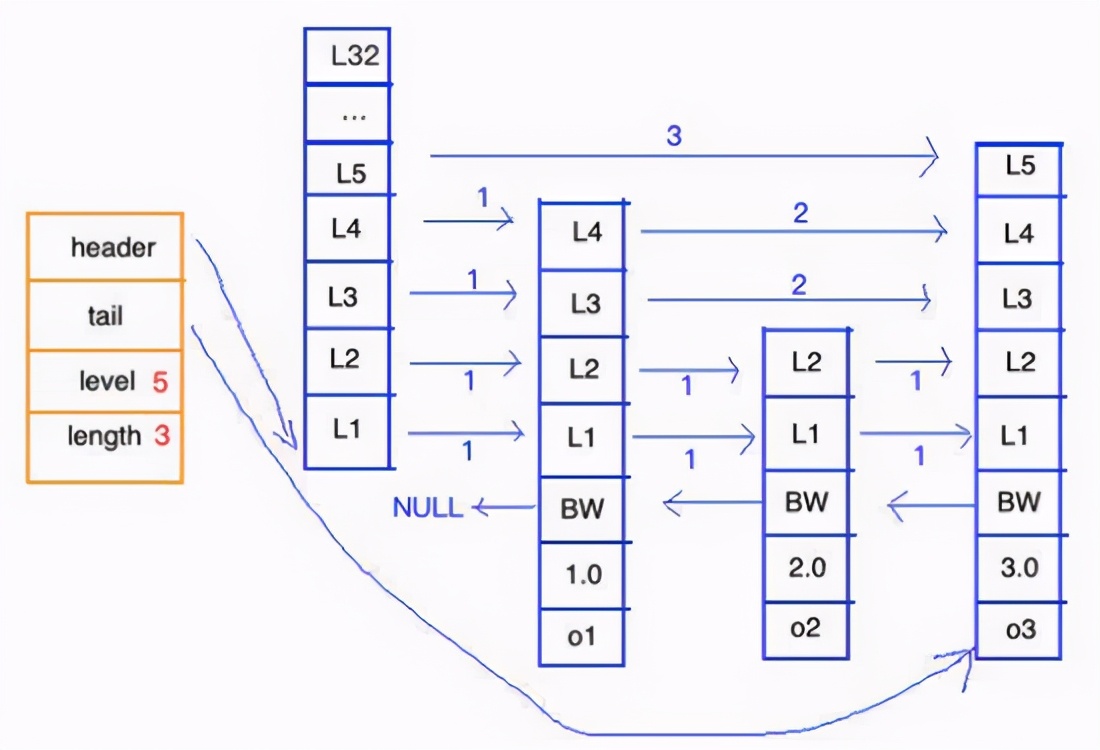
看這個(gè)圖,左邊“統(tǒng)籌”,右邊實(shí)現(xiàn)。
統(tǒng)籌部分 有幾點(diǎn)要說:
- header: 跳表表頭
- tail:跳表表尾
- level:層數(shù)最大的那個(gè)節(jié)點(diǎn)的層數(shù)
- length:跳表的長(zhǎng)度
實(shí)現(xiàn)部分有以下幾點(diǎn)說:
- 表頭:是鏈表的哨兵節(jié)點(diǎn),不記錄主體數(shù)據(jù)。是個(gè) 雙向鏈表分值 是有順序的
- o1、o2、o3是節(jié)點(diǎn)所保存的成員,是一個(gè)指針,可以指向一個(gè)SDS值。
- 層級(jí)高度最高是32。沒每次創(chuàng)建一個(gè)新的節(jié)點(diǎn)的時(shí)候,程序都會(huì) 隨機(jī)生成 一個(gè)介于1和32之間的值作為level 數(shù)組的大小 ,這個(gè)大小就是“高度”
redis五種數(shù)據(jù)結(jié)構(gòu)的實(shí)現(xiàn)
redis對(duì)象
redis中并沒有 直接使用 以上所說的那種數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn)鍵值數(shù)據(jù)庫(kù),而是基于一種對(duì)象,對(duì)象底層再 間接的引用 上文所說的 具體 的數(shù)據(jù)結(jié)構(gòu)。
就像這樣:

字符串
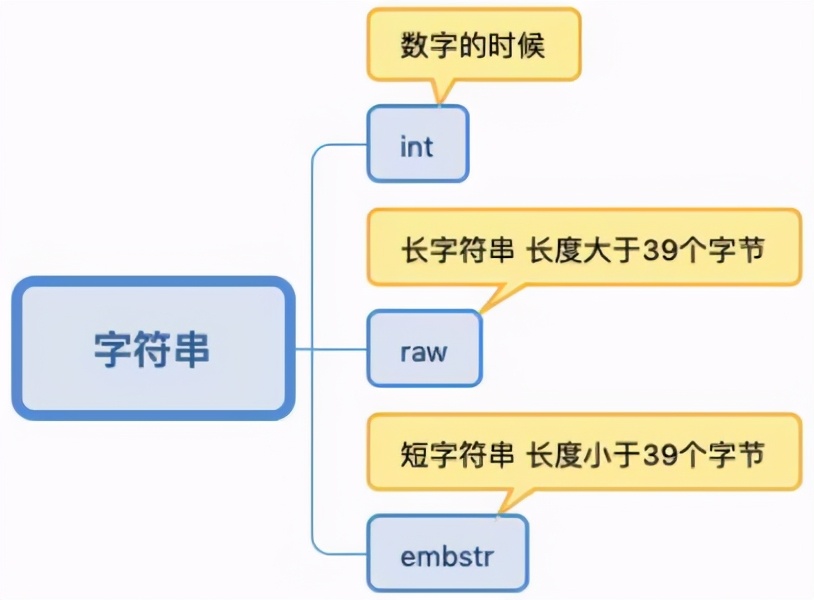
其中:embstr和raw都是由 SDS動(dòng)態(tài)字符串 構(gòu)成的。唯一區(qū)別是: raw 是分配內(nèi)存的時(shí)候,redis object和sds各分配一塊內(nèi)存,而embstr是redisobject和raw 在一塊兒內(nèi)存 中。
列表

列表
hash
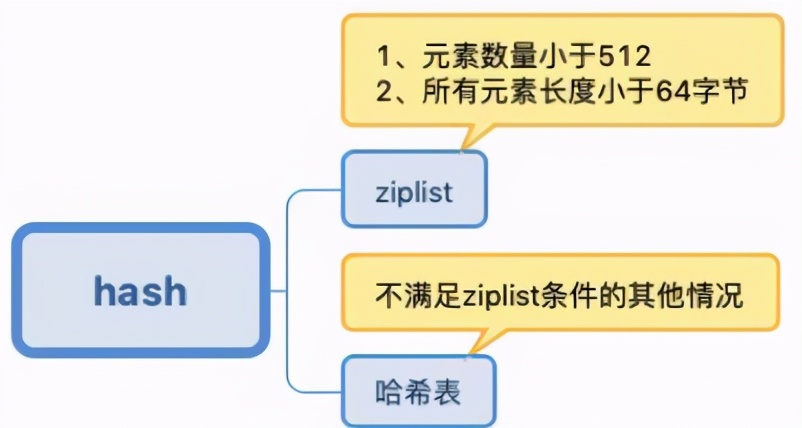
哈希
set
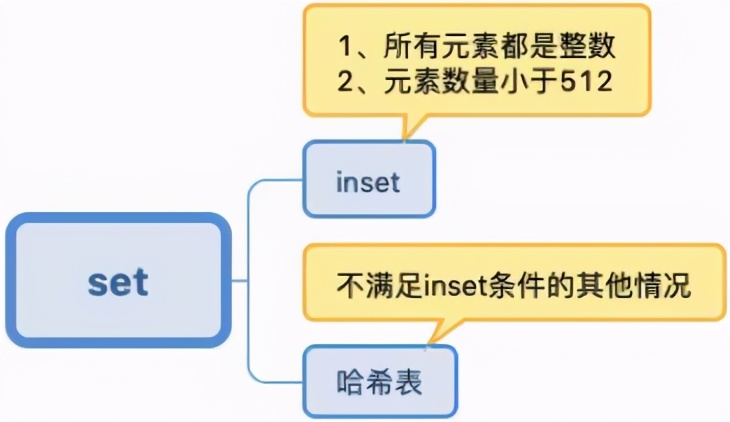
set
set
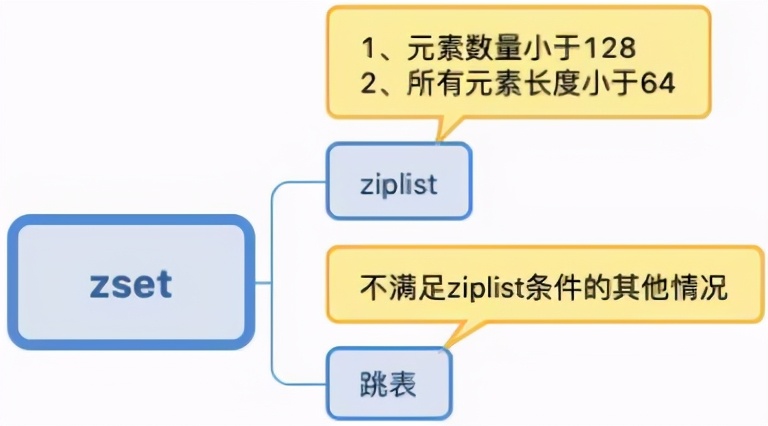
zset
跳躍表
是一種 有序 數(shù)據(jù)結(jié)構(gòu),它通過在 每個(gè)節(jié)點(diǎn) 中維持 多個(gè)指向其它節(jié)點(diǎn) 的指針,從而達(dá)到快速訪問節(jié)點(diǎn)的目的。具有如下 性質(zhì) :
1、由很多層結(jié)構(gòu)組成;
2、每一層都是一個(gè)有序的鏈表,排列順序?yàn)橛筛邔拥降讓樱抑辽侔瑑蓚€(gè)鏈表節(jié)點(diǎn),分別是前面的 head節(jié)點(diǎn) 和后面的 nil節(jié)點(diǎn) ;
3、最底層的鏈表包含了所有的元素;
4、如果一個(gè)元素出現(xiàn)在某一層的鏈表中,那么在 該層之下 的鏈表也全 都會(huì)出現(xiàn) (上一層的元素是當(dāng)前層的元素的子集);
5、鏈表中的每個(gè)節(jié)點(diǎn)都包含兩個(gè)指針,一個(gè)指向 同層的下一個(gè)鏈表節(jié)點(diǎn) ,另一個(gè)指向 下層的同一個(gè)鏈表節(jié)點(diǎn) ;
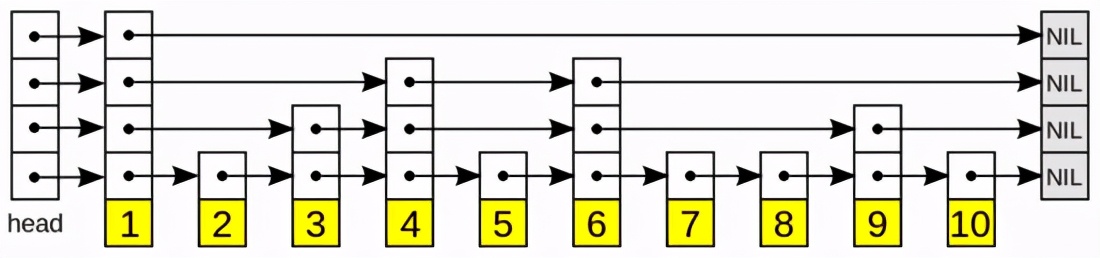
跳躍表節(jié)點(diǎn)定義如下:
typedef struct zskiplistNode {
//層
struct zskiplistLevel{
//前進(jìn)指針
struct zskiplistNode *forward;
//跨度
unsigned int span;
}level[];
//后退指針
struct zskiplistNode *backward;
//分值
double score;
//成員對(duì)象
robj *obj;
} zskiplistNode
多個(gè)跳躍表節(jié)點(diǎn)構(gòu)成一個(gè)跳躍表:
typedef struct zskiplist{
//表頭節(jié)點(diǎn)和表尾節(jié)點(diǎn)
structz skiplistNode *header, *tail;
//表中節(jié)點(diǎn)的數(shù)量
unsigned long length;
//表中層數(shù)最大的節(jié)點(diǎn)的層數(shù)
int level;
}zskiplist;
各個(gè)功能
“
①、搜索:從最高層的鏈表節(jié)點(diǎn)開始,如果比 當(dāng)前節(jié)點(diǎn)要大 和比當(dāng)前層的下一個(gè)節(jié)點(diǎn)要小,那么則往下找,也就是和當(dāng)前層的下一層的節(jié)點(diǎn)的下一個(gè)節(jié)點(diǎn)進(jìn)行比較,以此類推,一直找到 最底層的最后一個(gè)節(jié)點(diǎn) ,如果找到則返回,反之則返回空。
②、插入:首先確定 插入的層數(shù) ,有一種方法是假設(shè)拋一枚硬幣,如果是正面就累加,直到遇見反面為止,最后記錄正面的次數(shù)作為插入的層數(shù)。當(dāng)確定 插入的層數(shù)k 后,則需要將 新元素 插入到從底層到k層。
③、刪除:在各個(gè)層中找到包含 指定值的節(jié)點(diǎn)
,然后將節(jié)點(diǎn)從鏈表中刪除即可,如果刪除以后
只剩下
頭尾兩個(gè)節(jié)點(diǎn),則刪除這一層。
”
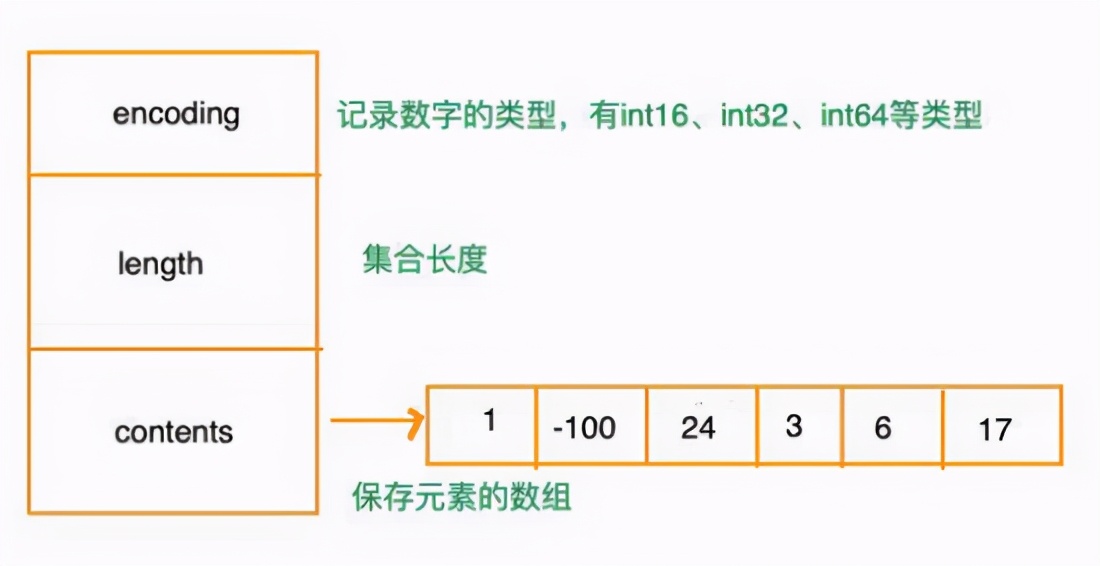
整數(shù)集合
用于保存 整數(shù)值 的集合抽象數(shù)據(jù)類型,它可以保存類型為int16_t、int32_t 或者int64_t 的整數(shù)值,并且保證集合中 不會(huì)出現(xiàn)重復(fù) 元素。定義如下:
typedef struct intset{
//編碼方式
uint32_t encoding;
//集合包含的元素?cái)?shù)量
uint32_t length;
//保存元素的數(shù)組
int8_t contents[];
}intset;
整數(shù)集合的每個(gè)元素都是 contents 數(shù)組 的一個(gè)數(shù)據(jù)項(xiàng),它們按照從小到大的 順序排列 ,并且不包含任何重復(fù)項(xiàng)。
length屬性記的是 contents數(shù)組的大小。
需要注意的是雖然 contents 數(shù)組聲明為 int8_t 類型,但是實(shí)際 上contents數(shù)組并不保存 任何 int8_t 類型的值 ,其真正類型有 encoding 來決定。
①、升級(jí)
當(dāng)我們新增的元素類型比原集合元素類型的長(zhǎng)度要大時(shí),需要對(duì) 整數(shù)集合 進(jìn)行升級(jí),才能將新元素放入整數(shù)集合中。具體步驟:
1、根據(jù)新元素類型,擴(kuò)展整數(shù)集合底層數(shù)組的大小,并為 新元素 分配空間。
2、將底層數(shù)組現(xiàn)有的所有元素都轉(zhuǎn)成與新元素相同類型的元素,并將 轉(zhuǎn)換后的元素 放到正確的位置,放置過程中,維持整個(gè)元素 順序 都是有序的。
3、將新元素添加到整數(shù)集合中是有序的呀!
升級(jí)能極大地節(jié)省內(nèi)存。
②、降級(jí)
整數(shù)集合不支持降級(jí)操作,一旦對(duì)數(shù)組進(jìn)行了升級(jí), 編碼 就會(huì)一直保持升級(jí)后的狀態(tài)
總結(jié)
“
大多數(shù)情況下,Redis使用 簡(jiǎn)單字符串SDS作為字符串 的表示,相對(duì)于C語(yǔ)言字符串,SDS具有常數(shù)復(fù)雜度獲取字符串長(zhǎng)度,杜絕了 緩存區(qū)的溢出 ,減少了修改字符串長(zhǎng)度時(shí)所需的 內(nèi)存重分配次數(shù) ,以及二進(jìn)制安全能存儲(chǔ)各種類型的文件,并且還兼容部分C函數(shù)。
”
通過為鏈表設(shè)置不同類型的特定函數(shù),Redis鏈表可以保存各種 不同類型的值 ,除了用作列表鍵,還在發(fā)布與訂閱、慢查詢、監(jiān)視器等方面發(fā)揮作用(后面會(huì)介紹)。
Redis的字典底層使用 哈希表實(shí)現(xiàn) ,每個(gè)字典通常有兩個(gè)哈希表,一個(gè)平時(shí)使用,另一個(gè)用于rehash時(shí)使用,使用 鏈地址法 解決哈希沖突。
跳躍表通常是有序集合的底層實(shí)現(xiàn)之一,表中的節(jié)點(diǎn)按照 分值大小 進(jìn)行排序。
整數(shù)集合是 集合鍵 的底層實(shí)現(xiàn)之一,底層由數(shù)組構(gòu)成, 升級(jí)特性 能盡可能的節(jié)省內(nèi)存。
壓縮列表是Redis為 節(jié)省內(nèi)存 而開發(fā)的順序型數(shù)據(jù)結(jié)構(gòu),經(jīng)常作為列表鍵和哈希鍵的底層實(shí)現(xiàn)。
原文鏈接:
https://mp.weixin.qq.com/s?__biz=MzAwMDg2OTAxNg==&mid=2652049856&idx=1&sn=05d77ad89bb84bf55cea9e17e6192a04&utm_source=tuicool&utm_medium=referral





