
1. pandas介紹
Pandas是一個強大的數據分析庫,它的Series和DataFrame數據結構,使得處理起二維表格數據變得非常簡單。
基于后面需要對Excel表格數據進行處理,有時候使用Pandas庫處理表格數據,會更容易、更簡單,因此我這里必須要講述。
Pandas庫是一個內容極其豐富的庫,這里并不會面面俱到。我這里主要講述的是如何利用Pandas庫完成 “表格讀取”、“表格取數” 和 “表格合并” 的任務。其實Pandas能實現的功能,遠遠不止這些,關于利用該庫如何實現數據清晰和圖表制作,不是本書的研究范圍,大家可以下去好好學習這個庫。
在使用這個庫之前,需要先導入這個庫。為了使用方便,習慣性給這個庫起一個別名pd,本書中只要是見到pd,指的都是Pandas。
2. Excel數據的讀取
Pandas支持讀取csv、excel、json、html、數據庫等各種形式的數據,非常強大。但是我們這里僅以讀取excel文件為例,講述如何使用Pandas庫讀取本地的excel文件。
在Pandas庫中,讀取excel文件使用的是pd.read_excel()函數,這個函數強大的原因是由于有很多參數供我們使用,是我們讀取excel文件更方便。在這里我們僅僅講述sheet_name、header、usecols和names四個常用參數。
① sheet_name參數詳解
我們知道一個excel文件是一個工作簿,一個工作簿有多個sheet表,每個sheet表中是一個表格數據。sheet_name參數就是幫助我們選擇要讀取的sheet表,具體用法如下。
sheet_name=正整數值,等于0表示讀取第一個sheet表,等于1表示讀取第二個sheet表,以此類推下去。
sheet_name=”sheet名稱”,我們可以利用每張sheet表的名稱,讀取到不同的sheet表,更方便靈活。
注意:如果不指定該參數,那么默認讀取的是第一個sheet表。
用法1:sheet_name=正整數值
df = pd.read_excel("readexcel.xlsx",sheet_name=1)
df
結果如下:
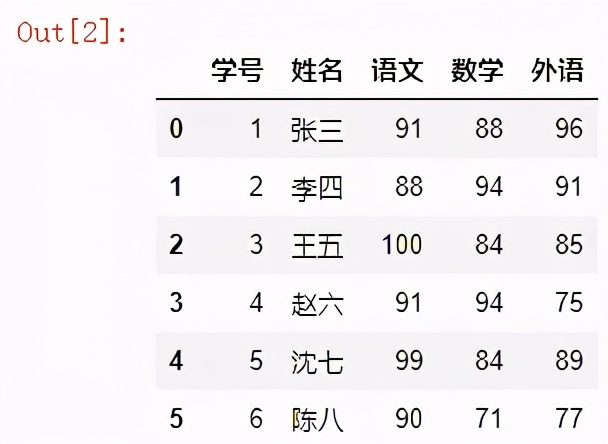
用法2:sheet_name=”sheet名稱”
df = pd.read_excel("readexcel.xlsx",sheet_name="考試成績表")
df
結果如下:

② header參數詳解
有時候待讀取的excel文件,可能有標題行,也有可能沒有標題行。但是默認都會將第一行讀取為標題行,這個對于沒有標題行的excel文件來說,顯得不太合適了,因此header參數可以很好的解決這個問題。
header=None,主要針對沒有標題行的excel文件,系統不會將第一行數據作為標題,而是默認取一個1,2,3…這樣的標題。
header=正整數值,指定哪一行作為標題行。
用法1:header=None
df = pd.read_excel("readexcel.xlsx",sheet_name="copy",header=None)
df
結果如下:

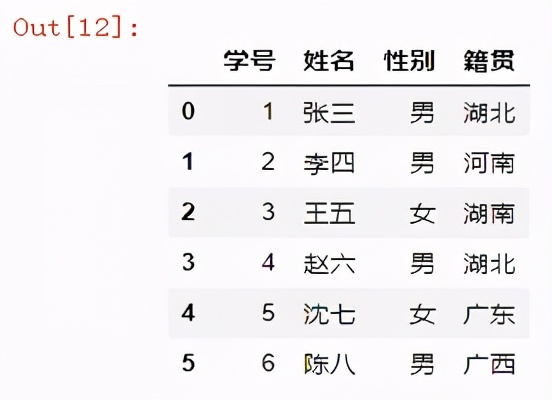
用法2:header=正整數值
df = pd.read_excel("readexcel.xlsx",sheet_name="基本信息表",header=1)
df
結果如下:
③ usecols參數詳解
當一張表有很多列的時候,如果你僅僅想讀取 這張表中的指定列,使用usecols參數是一個很好的選擇。
關于usecols參數,這里有多種用法,我們分別進行說明。
usecols=None,表示選擇一張表中的所有列,默認情況不指定該參數,也表示選擇表中的所有列。
usecols=[A,C],表示選擇A列(第一列)和C列(第三列)。而usecols=[A,C:E],表示選擇A列,C列、D列和E列。
usecols=[0,2],表示選擇第一列和第三列。
# 下面這兩行代碼,均表示獲取前2列的數據
df = pd.read_excel("readexcel.xlsx",sheet_name="考試成績表",usecols=[1,2])
df = pd.read_excel("readexcel.xlsx",sheet_name="考試成績表",usecols="A:B")
df
結果如下:

④ names參數詳解
如果一張表沒有標題行,我們就需要為其指定一個標題,使用names參數,可以在讀取數據的時候,為該表指定一個標題。
names=[“列名1”,”列名2”…]:傳入一個列表,指明每一列的列名。
name_list = ["學號","姓名","性別","籍貫"]
df = pd.read_excel("readexcel.xlsx",sheet_name="copy",header=None,names=name_list)
df
結果如下:

3. Excel數據的獲取
知道怎么讀取excel文件中的數據后,接下來我們就要學著如何靈活獲取到excel表中任意位置的數據了。
這里我一共提供了5種需要掌握的數據獲取方式,分別是 “訪問一列或多列” ,“訪問一行或多行” ,“訪問單元格中某個值” ,“訪問多行多列” 。
① 什么是“位置索引”和標簽索引

在講述如何取數之前,我們首先需要理解“位置索引”和“標簽索引”這兩個概念。
每個表的行索引就是一個“標簽索引”,而標識每一行位置的數字就是 “位置索引”,如圖所示。
在pandas中,標簽索引使用的是loc方法,位置索引用的是iloc方法。接下來就基于圖中這張表,來帶著大家來學習如何 “取數”。
首先,我們需要先讀取這張表中的數據。
df = pd.read_excel("readexcel.xlsx",sheet_name="地區")
df
結果如下:

② 訪問一列或多列
“訪問一列或多列”,相對來說比較容易,直接采用中括號“標簽數組”的方式,就可以獲取到一列或多列。
方法1:訪問一列
df["武漢"]
方法2:訪問多列
df[["武漢","廣水"]]
③ 訪問一行或多行
“訪問一行或多行”,方法就比較多了,因此特別容易出錯,因此需要特別注意。
方法1:訪問一行
# 位置索引
df.iloc[0]
# 標簽索引
df.loc["地區1"]
方法2:訪問多行
# 位置索引
df.iloc[[0,1,3]]
# 標簽索引
df.loc[["地區1","地區2","地區4"]]
④ 訪問單元格中某個值
“訪問單元格中某個值”,也有很多種方式,既可以使用“位置索引”,也可以使用“標簽索引”。
# 使用位置索引
df.iloc[2,1]
# 使用標簽索引
df.loc["地區3","天門"]
⑤ 訪問多行多列
“訪問多行多列”,方法就更多了。我一共為大家總結了5種方法。第一,iloc+切片;第二種,loc+標簽數組;第三種,iloc+切片+位置數組;第四種,loc+切片+標簽數組。
方法1:iloc+切片
# 選取前3行數據的所有列
df.iloc[:3,:]
方法2:loc+標簽數組
# 選取地區1和地區3這兩行的武漢、孝感、廣水列
df.loc[["地區1","地區3"],['武漢','孝感','廣水']]
方法3:iloc+切片+位置數組
# 選取所有行的第2和第5列數據
df.iloc[:,[1,4]]
方法4:loc+切片+標簽數組
# 選取地區1和地區2這兩行的武漢和廣水列
df.loc[:"地區2":,["武漢","廣水"]]
4. Excel數據的拼接
在進行多張表合并的時候,我們需要將多張表的數據,進行縱向(上下)拼接。在pandas中,直接使用pd.concat()函數,就可以完成表的縱向合并。
關于pd.concat()函數,用法其實很簡單,里面有一個參數ignore_index需要我們注意,ignore_index=True,表示會忽略原始索引,生成一組新的索引。
如果不使用ignore_index參數
df1 = pd.read_excel("concat.xlsx",sheet_name="Sheet1")
df2 = pd.read_excel("concat.xlsx",sheet_name="Sheet2")
pd.concat([df1,df2],ignore_index=True)
結果如下:
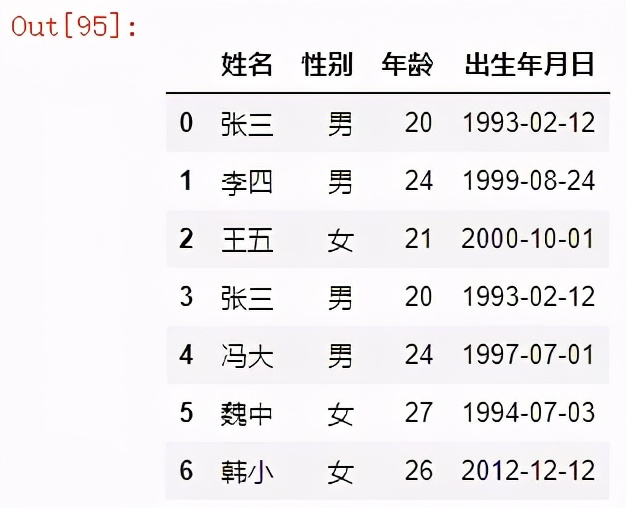
從上表可以看到,里面有兩條記錄是完全重復的,我們直接可以再調用drop_duplicates()函數,實現去重操作。
df1 = pd.read_excel("concat.xlsx",sheet_name="Sheet1")
df2 = pd.read_excel("concat.xlsx",sheet_name="Sheet2")
pd.concat([df1,df2],ignore_index=True).drop_duplicates()
結果如下:

5. Excel數據寫出
當我們將某個Excel文件中的表,進行讀取、數據整理等一系列操作后,就需要將處理好的數據,導出到本地。其實Pandas庫中可以導出的數據格式有很多種,我們同樣以導出xlsx文件為例,進行講述。
在Pandas庫中,將數據導出為xlsx格式,使用的是DataFrame對象的to_excle()方法,其中這里面有4個常用的參數,詳情如下。
- excel_writer:表示數據寫到哪里去,可以是一個路徑,也可以是一個ExcelWriter對象。
- sheet_name:設置導出到本地的Excel文件的Sheet名稱。
- index:新導出到本地的文件,默認是有一個從0開始的索引列,設置index=False可以去掉這個索引列。
- columns:選擇指定列導出,默認情況是導出所有列。
- encoding:有時候導出的文件會出現亂碼的格式,這個時候就需要使用該參數設置文件編碼格式。
df1 = pd.read_excel("concat.xlsx",sheet_name="Sheet1")
df2 = pd.read_excel("concat.xlsx",sheet_name="Sheet2")
df3 = pd.concat([df1,df2],ignore_index=True)
df3.to_excel(excel_writer="to_excel.xlsx",sheet_name="to_excel",index=None)
6. ExcelWriter的使用
有時候我們需要將多excel表寫入同一個工作簿,這個時候就需要借助Pandas中的pd.ExcelWriter()對象,默認對于xls使用xlwt引擎,對于xlsx使用openpyxl引擎。
這里面有兩個參數,一個是路徑參數Path,表示生成文件的存放路徑,一個是時間格式化參數datetime_format,可以將生成文件中的時間列,按照指定時間格式化輸出。
df1 = pd.read_excel("concat.xlsx",sheet_name="Sheet1")
df2 = pd.read_excel("concat.xlsx",sheet_name="Sheet2")
with pd.ExcelWriter("excel_writer.xlsx",datetime_format="YYYY-MM-DD") as writer:
df1.to_excel(excel_writer=writer,sheet_name="df1",index=None)
df2.to_excel(excel_writer=writer,sheet_name="df2",index=None)
上面第三行代碼,我們打開了一個ExcelWriter對象的同時,將所有設計到時間列的數據,進行格式化輸出為年-月-日。
接著第四行代碼,我們將df1中的數據寫到這個ExcelWriter對象中,將這個Sheet取名為df1。
最后第五行代碼,再將df2中的數據寫入到這個ExcelWriter對象中,同樣將Sheet取名為df1。





