
有時可以將機器學(xué)習(xí)算法視為一個黑匣子,那么我們?nèi)绾我愿庇^的方式來解釋它們呢?
在下圖中,給定藍(lán)點和紅點,我們可以看到有一個圖案。 作為人類,我們可以使用"直覺"將它們分開,并預(yù)測新點的顏色。
例如,我們大多數(shù)人可能會說圖中的黑點屬于藍(lán)點類別。 但是,如何用數(shù)學(xué)表達(dá)這種"直覺"呢? 您會發(fā)現(xiàn)不同的直覺導(dǎo)致了我們所知道的所有算法……

如果藍(lán)色圓點和紅色圓點可能對您來說很抽象,那么讓我們來看一些真實的例子。
· 腫瘤的診斷(B代表良性,M代表惡性),具有兩種不同的腫瘤特征。

· 垃圾郵件檢測:具有兩個變量,美元符號的頻率和單詞"刪除"的頻率。

您可能已經(jīng)知道一些可行的分類算法:邏輯回歸,kNN,LDA(線性判別分析),SVM,決策樹等。
但是了解它們是否直觀?
首先,為簡化問題,我們將在本文中考慮一維情況(我們將在另一篇文章中考慮二維情況)
如下圖所示,我們只有一個預(yù)測變量,即X,目標(biāo)變量是Y,具有兩個類別,紅點和藍(lán)點。
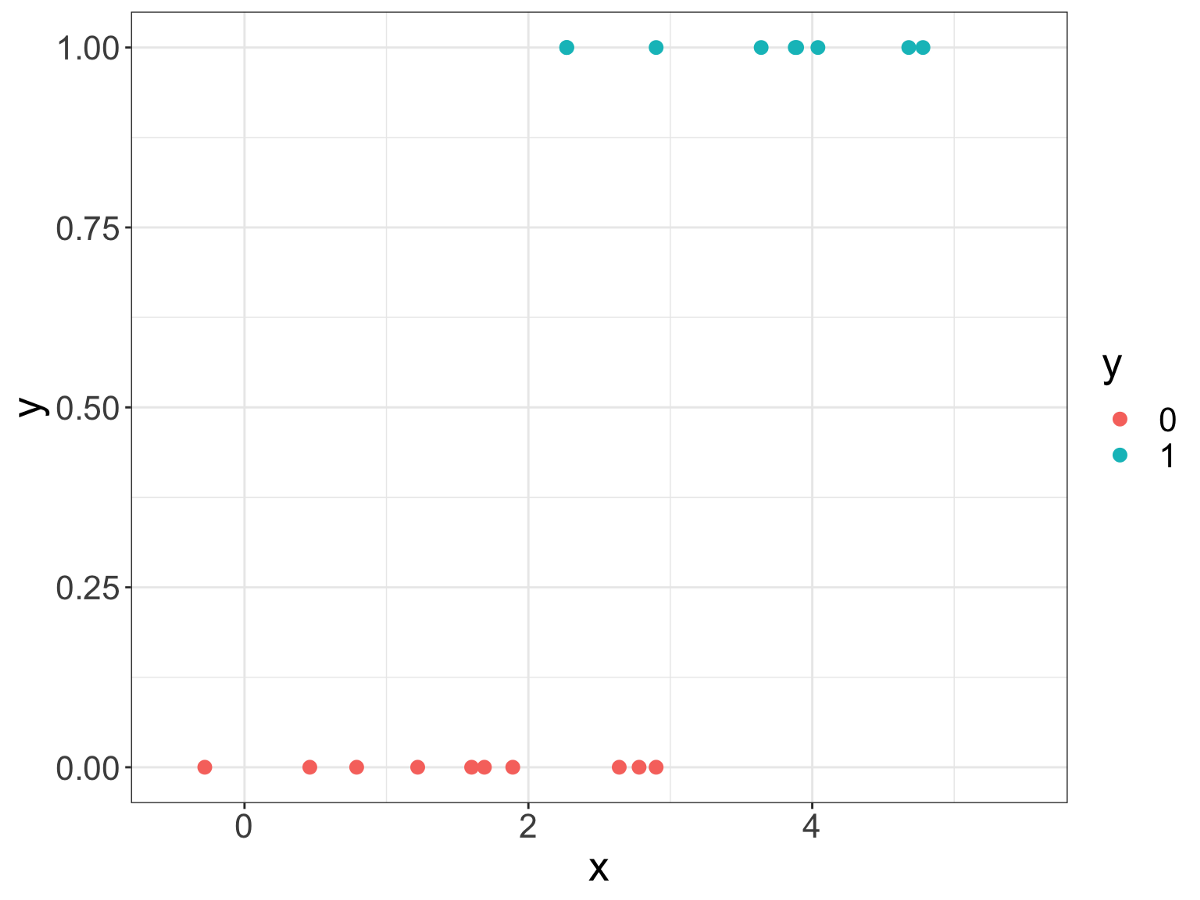
請注意,從數(shù)學(xué)上講,"紅色"或"藍(lán)色"沒有任何意義,因此我們將此變量轉(zhuǎn)換為二進制變量:" 1"代表"藍(lán)色"," 0"代表"紅色"。 這對應(yīng)于一個問題:點是藍(lán)色的嗎? 1表示True,0表示False。 當(dāng)然,這只是一個約定。
在真實的單詞示例中,"點是藍(lán)色的嗎?" 可以是:腫瘤是否惡變? 電子郵件是否是垃圾郵件?
第一原則:鄰居分析
對于給定的點,其想法是查看點的鄰居。
鄰居是什么? 最接近的?
"關(guān)閉"是什么意思? 最短的距離?
什么是距離? 在這里,它僅表示x的兩個值之間的差(x是實數(shù))。

現(xiàn)在,給定一個新點,我們可以計算出該點與所有其他點之間的距離。 我們可以選擇最接近的。
但是多少? 這種方法的主要問題是:我們選擇多少點?
首先,我們將其稱為k,并說k = 5。
現(xiàn)在我們可以檢查鄰居的階級。 如果您擁有一類的多數(shù),則可以通過多數(shù)類進行預(yù)測。 在我們的例子中,如果鄰居的多數(shù)類為1,則新點很可能屬于1類。
注意"多數(shù)"原則。 因此,如果我們選擇k = 4,那么將很難決定。 因此,如果k為奇數(shù),則有助于做出明確的決定。
現(xiàn)在可以計算出新點的概率了,下面的圖形如下:

對于K最近鄰,這個原理稱為kNN。
現(xiàn)在,此算法的特殊之處在于,由于您不知道要保留哪些點,因此必須為每次預(yù)測保留所有這些點。 這就是為什么我們說此算法不是基于模型的,而是基于實例的。
第二條原則:全球比例和正態(tài)分布
上面我們剛剛說過,選擇數(shù)字k很不方便,我們沒有對觀察結(jié)果建模。
那么,現(xiàn)在我們該怎么辦? 首先,讓我們考慮所有人口。 如果這樣做,則對于所有新點(多數(shù)類)的預(yù)測都將相同,而概率將是多數(shù)類的比例。
這可能有點簡單。 為了做得更好,我們可以考慮點的正態(tài)分布。 為什么呈正態(tài)分布? 好吧,它很簡單,并且簡化了所有計算。 這真的是一個很好的理由嗎? 好吧,這就是我們所謂的"建模"。
所有模型都是錯誤的,但有些是有用的。 —著名的統(tǒng)計學(xué)家喬治·博克斯(George Box)
現(xiàn)在,我們不用問鄰居,而是可以問一個更好的問題:我離藍(lán)點或紅點有多遠(yuǎn)。 換句話說:給定一個新點,該點是藍(lán)色或紅色的概率是多少?
· 新點與藍(lán)點之間的距離有多近? 我們考慮藍(lán)點的概率密度函數(shù)(記為PDF_b),而距離(或更確切地說,接近度)為PDF_b(x)
· 新點與紅點之間的距離有多近? 我們考慮紅點的概率密度函數(shù)(記為PDF_r),并且距離(或更接近)為PDF_r(x)

為了知道新點更接近哪種顏色,我們只需要比較兩個概率密度即可。 在下圖中,黑色曲線表示比率:PDF_b /(PDF_b + PDF_r)

現(xiàn)在,在建模方面令人驚奇的是:使用kNN,您必須保留所有點來做出決定,現(xiàn)在只需要使用幾個參數(shù)(例如均值和標(biāo)準(zhǔn)偏差)來定義 正態(tài)分布。
在先前的數(shù)據(jù)集中,我們有相同數(shù)量的藍(lán)點和紅點。 如果數(shù)量不同,我們可以按比例對兩個密度進行加權(quán)。

現(xiàn)在,該原理已被以下算法使用:線性判別分析,二次判別分析,樸素貝葉斯分類器。
它們之間有什么區(qū)別?
還記得我們必須計算法線密度嗎? 為了獲得正態(tài)分布,我們必須計算平均值和標(biāo)準(zhǔn)偏差。 對于這種方法,這很容易。 但是對于標(biāo)準(zhǔn)偏差,我們有兩種選擇。 我們可以計算每個類別的標(biāo)準(zhǔn)偏差,或者為簡化起見,我們可以考慮兩個類別的標(biāo)準(zhǔn)偏差相同。 為何如此 ? 我們可以使用兩個標(biāo)準(zhǔn)偏差的加權(quán)值。 現(xiàn)在為什么要"線性"還是"二次"? 為此,我們必須查看正態(tài)概率密度函數(shù),是的,公式,以及所有指數(shù),平方,pi等。所以讓我們再做一次。
那樸素的貝葉斯呢? 對于一維,LDA和樸素貝葉斯實際上是相同的。 他們又有什么不同呢? 在下一篇文章中,我們將討論二維情況。
第三原則:前沿領(lǐng)域分析
根據(jù)先前的原理,我們可以看到在對整個數(shù)據(jù)集建模之后,我們得出了一個決策邊界。
現(xiàn)在,我們想知道:如果目標(biāo)是尋找邊界,為什么我們不直接分析邊界區(qū)域?
可以用M(用于邊距)定義"邊界區(qū)域",M是我們選擇定義"邊界區(qū)域"的兩點之間的距離。 我們可以將紅色圓點的候選點標(biāo)記為A,將藍(lán)色圓點的候選點標(biāo)記為B。 用數(shù)學(xué)術(shù)語來說,我們有:
M = B-A
首先,讓我們考慮一下這兩個類是線性可分離的。 然后,我們可以計算出最大的紅點(我們得到A)和最小的藍(lán)點(我們有了B)。 (請注意,在一維情況下,最小值和最大值很容易定義。但是,當(dāng)維數(shù)較高時,最大值和最小值可能會更復(fù)雜。)
現(xiàn)在非常直觀地,我們可以選擇兩個值的平均值作為決策邊界。

但是,如果類0的一個值非常接近類1怎么辦? 然后,我們將具有如下圖所示的邊界:

現(xiàn)在我們有了這樣的直覺,第二種情況下定義的決策邊界并不是最佳的:邊界區(qū)域很小。 現(xiàn)在,如果我們保留先前的M,并讓異常指向,該怎么辦,如下所示:

并且我們可以為異常點添加一個懲罰項,可以是異常點與A之間的距離。

甚至更好的是,我們可以用系數(shù)對懲罰進行加權(quán),并將其稱為C。因此,最終決策標(biāo)準(zhǔn)是:
M-C×(紅色異常點-S_r)
(保證金減去加權(quán)罰款)
通常,如果存在多個異常點,我們可以對所有異常點求和:
M-C×(∑(紅色異常點-S_r)+ ∑(S_b-藍(lán)色異常點))
這樣,我們還解決了如下圖所示的點不可線性分離的情況的問題(請記住,我們說過,我們首先可以考慮點是線性可分離的,以便獲得直觀的"邊界 區(qū)域"。)

現(xiàn)在,此原理已用于SVM(支持向量機),為了獲得SVM的最終版本,我們必須進行一些小的調(diào)整(我們將在另一篇文章中進行討論)。 為什么將其稱為"支持"? 好吧,因為您使用了不同的點(稱為"支持向量")以最大化邊距(或更準(zhǔn)確地說是受罰邊距)。
原則四:尋找最優(yōu)曲線
為此,讓我們考慮將y建模為x的函數(shù)的直線。
y = a×x + b
為了簡化此問題的解決,我們可以考慮直線將通過每個類的平均值,如下圖所示。

現(xiàn)在,當(dāng)y = 0.5時可以考慮x的值,這可以作為決定y屬于0類還是1類的決策邊界。
但是對于這種模型,對于x的大值,您將得到y(tǒng)> 1,對于x的小值,y <0。 所以,我們能做些什么? 讓我們平滑一下。 像這樣 ?

來吧,我們可以做得更好,這樣嗎?

為了進行上圖中的平滑處理,我們可以使用例如以下功能
p(x)= 1 /(1 + exp(-(a×x + b)))
要了解為什么使用此函數(shù),您可以注意到我們找到了初始直線:y(x)= a×x + b,我們可以定義:sigma(y)= 1 /(1 + exp( -y)))
所以我們有:p(x)= sigma(y(x))= 1 /(1 + exp(-(a×x + b)))
為了可視化平滑效果,我們可以在下面看到sigma的圖形
· 當(dāng)x非常大時,輸出非常接近1
· 當(dāng)x很小時,輸出非常接近0

現(xiàn)在的任務(wù)是查找參數(shù):a和b。 為了實現(xiàn)這一目標(biāo),我們可以考慮對每個點進行正確分類的概率。
· 對于藍(lán)點,概率值為p(x);
· 對于紅點,概率值為1-p(x)。

準(zhǔn)則是總概率的最大化:我們將所有概率(對于0類和1類)相乘。 并且我們嘗試使結(jié)果最大化。
P_overall =乘積(類別1為p(x))×乘積(類別0為(1-p(x))
或更簡單的形式
P_overall =乘積(p(x)×y +(1-p(x))×(1-y))
然后,數(shù)學(xué)上的技巧是取對數(shù)并取導(dǎo)數(shù)等。但是事實證明,沒有一種簡單的方法(封閉式)可以找到參數(shù),而我們必須用數(shù)值方法求解。
下面我們可以看到a和b不同值的情況。 垂直線段代表每個點的概率。 所有這些概率的乘積應(yīng)最大化,以優(yōu)化a和b。

這就是邏輯回歸使用的原理,因為我們之前看到過sigma函數(shù)的名稱,稱為邏輯函數(shù)。
(如果您發(fā)現(xiàn)此解釋不夠直觀,則可以閱讀本文:直觀地講,我們?nèi)绾危ǜ茫├斫膺壿嫽貧w)
第五原則:避免錯誤
最終原則是關(guān)于選擇決策邊界時可能犯的錯誤。
現(xiàn)在有什么錯誤:
· 如果在該區(qū)域中有多數(shù)藍(lán)點,則紅點是錯誤;
· 如果紅色點占多數(shù),則藍(lán)色點就是錯誤。
找到?jīng)Q策邊界后,點將分為兩個區(qū)域。 想法是描述區(qū)域的"均勻性":錯誤越少,就越好。
現(xiàn)在,讓我們找到一個描述區(qū)域"同質(zhì)性"的函數(shù)。 例如,考慮p作為1類的比例。 并且我們得到(1-p)對于類別0的比例。
現(xiàn)在有了p和(1-p),我們能做什么? 讓我們從非常簡單的操作開始。
· 總和? 嗯,再想一想。
· 產(chǎn)品。 嗯,這是一張圖表。

因此該函數(shù)是對稱的,這是必需的特性,因為此函數(shù)應(yīng)適用于任何一個類。 此函數(shù)的輸出可以指示區(qū)域的"均勻性":越低越好
· 當(dāng)p接近1時,幾乎所有的點都是藍(lán)色的,該指示器非常低
· 當(dāng)p接近0時,幾乎所有點都被撕裂,則指示器也非常低
· 當(dāng)p為0.5時,我們有相同數(shù)量的紅點和藍(lán)點,這不是所需的狀態(tài)。 該指標(biāo)處于最高水平。
為了找到?jīng)Q策邊界,我們必須測試x的不同值。 對于x的每個值,將創(chuàng)建兩個區(qū)域:左側(cè)區(qū)域和右側(cè)區(qū)域。 對于每一側(cè),我們可以計算指標(biāo),然后用每個區(qū)域中點的比例對它們進行加權(quán),以獲得總體指標(biāo)。
現(xiàn)在我們可以測試所有點作為決策邊界,并查看指標(biāo)如何變化。

現(xiàn)在我們可以采用指標(biāo)的最低級別來找到x的最佳值。 請注意,由于我們具有階躍函數(shù),因此我們可以計算x的兩個值的均值,以定義指標(biāo)的最低水平。
現(xiàn)在,此原則的特別之處在于,您可以繼續(xù)在每個區(qū)域中找到其他決策邊界。 我們將在另一篇專門討論該原理的文章中看到,這樣做的好處是您可以輕松處理非線性情況。
因此,我們可以一步一步地找到最佳邊界。
在這里,我們有關(guān)于每個步驟不同決策邊界的決策樹。

現(xiàn)在的問題是:我們什么時候停止? 可能有不同的規(guī)則……
該原則也被認(rèn)為是"分而治之"。 它允許增長決策樹。 這些樹也是更復(fù)雜算法(例如,Random Forest或Gradient Boosting machines)的基礎(chǔ)。
當(dāng)我們談?wù)摍C器學(xué)習(xí)和人工智能時,我們總是談?wù)撋窠?jīng)網(wǎng)絡(luò),但是為什么我們在這里沒有提到它們呢? 好吧,實際上,我們確實看到了一個簡單的神經(jīng)網(wǎng)絡(luò)示例,即邏輯回歸…
對于機器學(xué)習(xí)從業(yè)者,您可能會注意到,我自愿不使用技術(shù)術(shù)語,也許您可以在適當(dāng)?shù)纳舷挛闹凶⑨尯头胖眉夹g(shù)術(shù)語:硬邊距,軟邊距,梯度下降,凸度,超平面,先驗概率,后驗概率 ,損失函數(shù),交叉熵,最大似然估計,過度擬合…
讓我們回顧一下:
· 原則1:檢查鄰居,我們得到KNN
· 原則2:考慮全球比例和正態(tài)分布,我們可以進行LDA,QDA或NB。
· 原則3:研究邊界區(qū)域,并嘗試使其"干凈"且大。 我們得到了SVM。
· 原則4:畫一條直線,使其平滑并嘗試調(diào)整。 我們得到邏輯回歸
· 原則5:分而治之。 我們得到?jīng)Q策樹。
請注意,我們并未完成五項原則的所有推理:
· 用kNN確定k in
· 決策樹中的停止規(guī)則
· 系數(shù)C的確定
· 確定邏輯回歸的a和b
(本文翻譯自Angela Shi的文章《Intuitively, How Can We Understand Different Classification Algorithms Principles》,參考:
https://towardsdatascience.com/intuitively-how-can-we-understand-different-classification-algorithms-principles-d45cf8ef54e3)





