擊這里在線咨詢客服")

阿里妹導(dǎo)讀:肉眼看計(jì)算機(jī)是由CPU、內(nèi)存、顯示器這些硬件設(shè)備組成,但大部分人從事的是軟件開(kāi)發(fā)工作。計(jì)算機(jī)底層原理就是連通硬件和軟件的橋梁,理解計(jì)算機(jī)底層原理才能在程序設(shè)計(jì)這條路上越走越快,越走越輕松。從操作系統(tǒng)層面去理解高級(jí)編程語(yǔ)言的執(zhí)行過(guò)程,會(huì)發(fā)現(xiàn)好多軟件設(shè)計(jì)都是同一種套路,很多語(yǔ)言特性都依賴于底層機(jī)制,今天董鵬為你一一揭秘。
結(jié)合 CPU 理解一行 JAVA 代碼是怎么執(zhí)行的
根據(jù)馮·諾依曼思想,計(jì)算機(jī)采用二進(jìn)制作為數(shù)制基礎(chǔ),必須包含:運(yùn)算器、控制器、存儲(chǔ)設(shè)備,以及輸入輸出設(shè)備,如下圖所示。

我們先來(lái)分析 CPU 的工作原理,現(xiàn)代 CPU 芯片中大都集成了,控制單元,運(yùn)算單元,存儲(chǔ)單元。控制單元是 CPU 的控制中心, CPU 需要通過(guò)它才知道下一步做什么,也就是執(zhí)行什么指令,控制單元又包含:指令寄存器(IR ),指令譯碼器( ID )和操作控制器( OC )。
當(dāng)程序被加載進(jìn)內(nèi)存后,指令就在內(nèi)存中了,這個(gè)時(shí)候說(shuō)的內(nèi)存是獨(dú)立于 CPU 外的主存設(shè)備,也就是 PC 機(jī)中的內(nèi)存條,指令指針寄存器IP 指向內(nèi)存中下一條待執(zhí)行指令的地址,控制單元根據(jù) IP寄存器的指向,將主存中的指令裝載到指令寄存器。
這個(gè)指令寄存器也是一個(gè)存儲(chǔ)設(shè)備,不過(guò)他集成在 CPU 內(nèi)部,指令從主存到達(dá) CPU 后只是一串 010101 的二進(jìn)制串,還需要通過(guò)譯碼器解碼,分析出操作碼是什么,操作數(shù)在哪,之后就是具體的運(yùn)算單元進(jìn)行算術(shù)運(yùn)算(加減乘除),邏輯運(yùn)算(比較,位移)。而 CPU 指令執(zhí)行過(guò)程大致為:取址(去主存獲取指令放到寄存器),譯碼(從主存獲取操作數(shù)放入高速緩存 L1 ),執(zhí)行(運(yùn)算)。

這里解釋下上圖中 CPU 內(nèi)部集成的存儲(chǔ)單元 SRAM ,正好和主存中的 DRAM 對(duì)應(yīng), RAM 是隨機(jī)訪問(wèn)內(nèi)存,就是給一個(gè)地址就能訪問(wèn)到數(shù)據(jù),而磁盤這種存儲(chǔ)媒介必須順序訪問(wèn),而 RAM 又分為動(dòng)態(tài)和靜態(tài)兩種,靜態(tài) RAM 由于集成度較低,一般容量小,速度快,而動(dòng)態(tài) RAM 集成度較高,主要通過(guò)給電容充電和放電實(shí)現(xiàn),速度沒(méi)有靜態(tài) RAM 快,所以一般將動(dòng)態(tài) RAM 做為主存,而靜態(tài) RAM 作為 CPU 和主存之間的高速緩存 (cache),用來(lái)屏蔽 CPU 和主存速度上的差異,也就是我們經(jīng)常看到的 L1 , L2 緩存。每一級(jí)別緩存速度變低,容量變大。
下圖展示了存儲(chǔ)器的層次化架構(gòu),以及 CPU 訪問(wèn)主存的過(guò)程,這里有兩個(gè)知識(shí)點(diǎn),一個(gè)是多級(jí)緩存之間為保證數(shù)據(jù)的一致性,而推出的緩存一致性協(xié)議,具體可以參考這篇文章,另外一個(gè)知識(shí)點(diǎn)是, cache 和主存的映射,首先要明確的是 cahce 緩存的單位是緩存行,對(duì)應(yīng)主存中的一個(gè)內(nèi)存塊,并不是一個(gè)變量,這個(gè)主要是因?yàn)?CPU 訪問(wèn)的空間局限性:被訪問(wèn)的某個(gè)存儲(chǔ)單元,在一個(gè)較短時(shí)間內(nèi),很有可能再次被訪問(wèn)到,以及空間局限性:被訪問(wèn)的某個(gè)存儲(chǔ)單元,在較短時(shí)間內(nèi),他的相鄰存儲(chǔ)單元也會(huì)被訪問(wèn)到。
而映射方式有很多種,類似于 cache 行號(hào) = 主存塊號(hào) mod cache總行數(shù) ,這樣每次獲取到一個(gè)主存地址,根據(jù)這個(gè)地址計(jì)算出在主存中的塊號(hào)就可以計(jì)算出在 cache 中的行號(hào)。

下面我們接著聊 CPU 的指令執(zhí)行。取址、譯碼、執(zhí)行,這是一個(gè)指令的執(zhí)行過(guò)程,所有指令都會(huì)嚴(yán)格按照這個(gè)順序執(zhí)行。但是多個(gè)指令之間其實(shí)是可以并行的,對(duì)于單核 CPU 來(lái)說(shuō),同一時(shí)刻只能有一條指令能夠占有執(zhí)行單元運(yùn)行。這里說(shuō)的執(zhí)行是 CPU 指令處理 (取指,譯碼,執(zhí)行) 三步驟中的第三步,也就是運(yùn)算單元的計(jì)算任務(wù)。
所以為了提升 CPU 的指令處理速度,所以需要保證運(yùn)算單元在執(zhí)行前的準(zhǔn)備工作都完成,這樣運(yùn)算單元就可以一直處于運(yùn)算中,而剛剛的串行流程中,取指,解碼的時(shí)候運(yùn)算單元是空閑的,而且取指和解碼如果沒(méi)有命中高速緩存還需要從主存取,而主存的速度和 CPU 不在一個(gè)級(jí)別上,所以指令流水線 可以大大提高 CPU 的處理速度,下圖是一個(gè)3級(jí)流水線的示例圖,而現(xiàn)在的奔騰 CPU 都是32級(jí)流水線,具體做法就是將上面三個(gè)流程拆分的更細(xì)。

除了指令流水線, CPU 還有分支預(yù)測(cè),亂序執(zhí)行等優(yōu)化速度的手段。好了,我們回到正題,一行 Java 代碼是怎么執(zhí)行的?
一行代碼能夠執(zhí)行,必須要有可以執(zhí)行的上下文環(huán)境,包括:指令寄存器、數(shù)據(jù)寄存器、棧空間等內(nèi)存資源,然后這行代碼必須作為一個(gè)執(zhí)行流能夠被操作系統(tǒng)的任務(wù)調(diào)度器識(shí)別,并給他分配 CPU 資源,當(dāng)然這行代碼所代表的指令必須是 CPU 可以解碼識(shí)別的,所以一行 Java 代碼必須被解釋成對(duì)應(yīng)的 CPU 指令才能執(zhí)行。下面我們看下System.out.println("Hello world")這行代碼的轉(zhuǎn)譯過(guò)程。
Java 是一門高級(jí)語(yǔ)言,這類語(yǔ)言不能直接運(yùn)行在硬件上,必須運(yùn)行在能夠識(shí)別 Java 語(yǔ)言特性的虛擬機(jī)上,而 Java 代碼必須通過(guò) Java 編譯器將其轉(zhuǎn)換成虛擬機(jī)所能識(shí)別的指令序列,也稱為 Java 字節(jié)碼,之所以稱為字節(jié)碼是因?yàn)?Java 字節(jié)碼的操作指令(OpCode)被固定為一個(gè)字節(jié),以下為 System.out.println("Hello world") 編譯后的字節(jié)碼:
0x00: b2 00 02 getstatic Java .lang.System.out 0x03: 12 03 ldc "Hello, World!" 0x05: b6 00 04 invokevirtual Java .io.PrintStream.println 0x08: b1 return
最左列是偏移;中間列是給虛擬機(jī)讀的字節(jié)碼;最右列是高級(jí)語(yǔ)言的代碼,下面是通過(guò)匯編語(yǔ)言轉(zhuǎn)換成的機(jī)器指令,中間是機(jī)器碼,第三列為對(duì)應(yīng)的機(jī)器指令,最后一列是對(duì)應(yīng)的匯編代碼:
0x00: 55 push rbp 0x01: 48 89 e5 mov rbp,rsp 0x04: 48 83 ec 10 sub rsp,0x10 0x08: 48 8d 3d 3b 00 00 00 lea rdi,[rip+0x3b] ; 加載 "Hello, World!n" 0x0f: c7 45 fc 00 00 00 00 mov Dword PTR [rbp-0x4],0x0 0x16: b0 00 mov al,0x0 0x18: e8 0d 00 00 00 call 0x12 ; 調(diào)用 printf 方法 0x1d: 31 c9 xor ecx,ecx 0x1f: 89 45 f8 mov DWORD PTR [rbp-0x8],eax 0x22: 89 c8 mov eax,ecx 0x24: 48 83 c4 10 add rsp,0x10 0x28: 5d pop rbp 0x29: c3 ret
JVM 通過(guò)類加載器加載 class 文件里的字節(jié)碼后,會(huì)通過(guò)解釋器解釋成匯編指令,最終再轉(zhuǎn)譯成 CPU 可以識(shí)別的機(jī)器指令,解釋器是軟件來(lái)實(shí)現(xiàn)的,主要是為了實(shí)現(xiàn)同一份 Java 字節(jié)碼可以在不同的硬件平臺(tái)上運(yùn)行,而將匯編指令轉(zhuǎn)換成機(jī)器指令由硬件直接實(shí)現(xiàn),這一步速度是很快的,當(dāng)然 JVM 為了提高運(yùn)行效率也可以將某些熱點(diǎn)代碼(一個(gè)方法內(nèi)的代碼)一次全部編譯成機(jī)器指令后然后在執(zhí)行,也就是和解釋執(zhí)行對(duì)應(yīng)的即時(shí)編譯(JIT), JVM 啟動(dòng)的時(shí)候可以通過(guò) -Xint 和 -Xcomp 來(lái)控制執(zhí)行模式。
從軟件層面上, class 文件被加載進(jìn)虛擬機(jī)后,類信息會(huì)存放在方法區(qū),在實(shí)際運(yùn)行的時(shí)候會(huì)執(zhí)行方法區(qū)中的代碼,在 JVM 中所有的線程共享堆內(nèi)存和方法區(qū),而每個(gè)線程有自己獨(dú)立的 Java 方法棧,本地方法棧(面向 native 方法),PC寄存器(存放線程執(zhí)行位置),當(dāng)調(diào)用一個(gè)方法的時(shí)候, Java 虛擬機(jī)會(huì)在當(dāng)前線程對(duì)應(yīng)的方法棧中壓入一個(gè)棧幀,用來(lái)存放 Java 字節(jié)碼操作數(shù)以及局部變量,這個(gè)方法執(zhí)行完會(huì)彈出棧幀,一個(gè)線程會(huì)連續(xù)執(zhí)行多個(gè)方法,對(duì)應(yīng)不同的棧幀的壓入和彈出,壓入棧幀后就是 JVM 解釋執(zhí)行的過(guò)程了。

中斷
剛剛說(shuō)到, CPU 只要一上電就像一個(gè)永動(dòng)機(jī), 不停的取指令,運(yùn)算,周而復(fù)始,而中斷便是操作系統(tǒng)的靈魂,故名思議,中斷就是打斷 CPU 的執(zhí)行過(guò)程,轉(zhuǎn)而去做點(diǎn)別的。
例如系統(tǒng)執(zhí)行期間發(fā)生了致命錯(cuò)誤,需要結(jié)束執(zhí)行,例如用戶程序調(diào)用了一個(gè)系統(tǒng)調(diào)用的方法,例如mmp等,就會(huì)通過(guò)中斷讓 CPU 切換上下文,轉(zhuǎn)到內(nèi)核空間,例如一個(gè)等待用戶輸入的程序正在阻塞,而當(dāng)用戶通過(guò)鍵盤完成輸入,內(nèi)核數(shù)據(jù)已經(jīng)準(zhǔn)備好后,就會(huì)發(fā)一個(gè)中斷信號(hào),喚醒用戶程序把數(shù)據(jù)從內(nèi)核取走,不然內(nèi)核可能會(huì)數(shù)據(jù)溢出,當(dāng)磁盤報(bào)了一個(gè)致命異常,也會(huì)通過(guò)中斷通知 CPU ,定時(shí)器完成時(shí)鐘滴答也會(huì)發(fā)時(shí)鐘中斷通知 CPU 。
中斷的種類,我們這里就不做細(xì)分了,中斷有點(diǎn)類似于我們經(jīng)常說(shuō)的事件驅(qū)動(dòng)編程,而這個(gè)事件通知機(jī)制是怎么實(shí)現(xiàn)的呢,硬件中斷的實(shí)現(xiàn)通過(guò)一個(gè)導(dǎo)線和 CPU 相連來(lái)傳輸中斷信號(hào),軟件上會(huì)有特定的指令,例如執(zhí)行系統(tǒng)調(diào)用創(chuàng)建線程的指令,而 CPU 每執(zhí)行完一個(gè)指令,就會(huì)檢查中斷寄存器中是否有中斷,如果有就取出然后執(zhí)行該中斷對(duì)應(yīng)的處理程序。
陷入內(nèi)核 : 我們?cè)谠O(shè)計(jì)軟件的時(shí)候,會(huì)考慮程序上下文切換的頻率,頻率太高肯定會(huì)影響程序執(zhí)行性能,而陷入內(nèi)核是針對(duì) CPU 而言的, CPU 的執(zhí)行從用戶態(tài)轉(zhuǎn)向內(nèi)核態(tài),以前是用戶程序在使用 CPU ,現(xiàn)在是內(nèi)核程序在使用 CPU ,這種切換是通過(guò)系統(tǒng)調(diào)用產(chǎn)生的。
系統(tǒng)調(diào)用是執(zhí)行操作系統(tǒng)底層的程序,linux的設(shè)計(jì)者,為了保護(hù)操作系統(tǒng),將進(jìn)程的執(zhí)行狀態(tài)用內(nèi)核態(tài)和用戶態(tài)分開(kāi),同一個(gè)進(jìn)程中,內(nèi)核和用戶共享同一個(gè)地址空間,一般 4G 的虛擬地址,其中 1G 給內(nèi)核態(tài), 3G 給用戶態(tài)。在程序設(shè)計(jì)的時(shí)候我們要盡量減少用戶態(tài)到內(nèi)核態(tài)的切換,例如創(chuàng)建線程是一個(gè)系統(tǒng)調(diào)用,所以我們有了線程池的實(shí)現(xiàn)。
從 Linux 內(nèi)存管理角度理解 JVM 內(nèi)存模型
進(jìn)程上下文
我們可以將程序理解為一段可執(zhí)行的指令集合,而這個(gè)程序啟動(dòng)后,操作系統(tǒng)就會(huì)為他分配 CPU ,內(nèi)存等資源,而這個(gè)正在運(yùn)行的程序就是我們說(shuō)的進(jìn)程,進(jìn)程是操作系統(tǒng)對(duì)處理器中運(yùn)行的程序的一種抽象。
而為進(jìn)程分配的內(nèi)存以及 CPU 資源就是這個(gè)進(jìn)程的上下文,保存了當(dāng)前執(zhí)行的指令,以及變量值,而 JVM 啟動(dòng)后也是linux上的一個(gè)普通進(jìn)程,進(jìn)程的物理實(shí)體和支持進(jìn)程運(yùn)行的環(huán)境合稱為上下文,而上下文切換就是將當(dāng)前正在運(yùn)行的進(jìn)程換下,換一個(gè)新的進(jìn)程到處理器運(yùn)行,以此來(lái)讓多個(gè)進(jìn)程并發(fā)的執(zhí)行,上下文切換可能來(lái)自操作系統(tǒng)調(diào)度,也有可能來(lái)自程序內(nèi)部,例如讀取IO的時(shí)候,會(huì)讓用戶代碼和操作系統(tǒng)代碼之間進(jìn)行切換。
虛擬存儲(chǔ)
當(dāng)我們同時(shí)啟動(dòng)多個(gè) JVM 執(zhí)行:System.out.println(new Object()); 將會(huì)打印這個(gè)對(duì)象的 hashcode ,hashcode 默認(rèn)為內(nèi)存地址,最后發(fā)現(xiàn)他們打印的都是 Java .lang.Object@4fca772d ,也就是多個(gè)進(jìn)程返回的內(nèi)存地址竟然是一樣的。
通過(guò)上面的例子我們可以證明,linux中每個(gè)進(jìn)程有單獨(dú)的地址空間,在此之前,我們先了解下 CPU 是如何訪問(wèn)內(nèi)存的?
假設(shè)我們現(xiàn)在還沒(méi)有虛擬地址,只有物理地址,編譯器在編譯程序的時(shí)候,需要將高級(jí)語(yǔ)言轉(zhuǎn)換成機(jī)器指令,那么 CPU 訪問(wèn)內(nèi)存的時(shí)候必須指定一個(gè)地址,這個(gè)地址如果是一個(gè)絕對(duì)的物理地址,那么程序就必須放在內(nèi)存中的一個(gè)固定的地方,而且這個(gè)地址需要在編譯的時(shí)候就要確認(rèn),大家應(yīng)該想到這樣有多坑了吧。
如果我要同時(shí)運(yùn)行兩個(gè) office word 程序,那么他們將操作同一塊內(nèi)存,那就亂套了,偉大的計(jì)算機(jī)前輩設(shè)計(jì)出,讓 CPU 采用 段基址 + 段內(nèi)偏移地址 的方式訪問(wèn)內(nèi)存,其中段基地址在程序啟動(dòng)的時(shí)候確認(rèn),盡管這個(gè)段基地址還是絕對(duì)的物理地址,但終究可以同時(shí)運(yùn)行多個(gè)程序了, CPU 采用這種方式訪問(wèn)內(nèi)存,就需要段基址寄存器和段內(nèi)偏移地址寄存器來(lái)存儲(chǔ)地址,最終將兩個(gè)地址相加送上地址總線。
而內(nèi)存分段,相當(dāng)于每個(gè)進(jìn)程都會(huì)分配一個(gè)內(nèi)存段,而且這個(gè)內(nèi)存段需要是一塊連續(xù)的空間,主存里維護(hù)著多個(gè)內(nèi)存段,當(dāng)某個(gè)進(jìn)程需要更多內(nèi)存,并且超出物理內(nèi)存的時(shí)候,就需要將某個(gè)不常用的內(nèi)存段換到硬盤上,等有充足內(nèi)存的時(shí)候在從硬盤加載進(jìn)來(lái),也就是 swap 。每次交換都需要操作整個(gè)段的數(shù)據(jù)。
首先連續(xù)的地址空間是很寶貴的,例如一個(gè) 50M 的內(nèi)存,在內(nèi)存段之間有空隙的情況下,將無(wú)法支持 5 個(gè)需要 10M 內(nèi)存才能運(yùn)行的程序,如何才能讓段內(nèi)地址不連續(xù)呢? 答案是內(nèi)存分頁(yè)。

在保護(hù)模式下,每一個(gè)進(jìn)程都有自己獨(dú)立的地址空間,所以段基地址是固定的,只需要給出段內(nèi)偏移地址就可以了,而這個(gè)偏移地址稱為線性地址,線性地址是連續(xù)的,而內(nèi)存分頁(yè)將連續(xù)的線性地址和和分頁(yè)后的物理地址相關(guān)聯(lián),這樣邏輯上的連續(xù)線性地址可以對(duì)應(yīng)不連續(xù)的物理地址。
物理地址空間可以被多個(gè)進(jìn)程共享,而這個(gè)映射關(guān)系將通過(guò)頁(yè)表( page table)進(jìn)行維護(hù)。 標(biāo)準(zhǔn)頁(yè)的尺寸一般為 4KB ,分頁(yè)后,物理內(nèi)存被分成若干個(gè) 4KB 的數(shù)據(jù)頁(yè),進(jìn)程申請(qǐng)內(nèi)存的時(shí)候,可以映射為多個(gè) 4KB 大小的物理內(nèi)存,而應(yīng)用程序讀取數(shù)據(jù)的時(shí)候會(huì)以頁(yè)為最小單位,當(dāng)需要和硬盤發(fā)生交換的時(shí)候也是以頁(yè)為單位。
現(xiàn)代計(jì)算機(jī)多采用虛擬存儲(chǔ)技術(shù),虛擬存儲(chǔ)讓每個(gè)進(jìn)程以為自己獨(dú)占整個(gè)內(nèi)存空間,其實(shí)這個(gè)虛擬空間是主存和磁盤的抽象,這樣的好處是,每個(gè)進(jìn)程擁有一致的虛擬地址空間,簡(jiǎn)化了內(nèi)存管理,進(jìn)程不需要和其他進(jìn)程競(jìng)爭(zhēng)內(nèi)存空間。
因?yàn)樗仟?dú)占的,也保護(hù)了各自進(jìn)程不被其他進(jìn)程破壞,另外,他把主存看成磁盤的一個(gè)緩存,主存中僅保存活動(dòng)的程序段和數(shù)據(jù)段,當(dāng)主存中不存在數(shù)據(jù)的時(shí)候發(fā)生缺頁(yè)中斷,然后從磁盤加載進(jìn)來(lái),當(dāng)物理內(nèi)存不足的時(shí)候會(huì)發(fā)生 swap 到磁盤。頁(yè)表保存了虛擬地址和物理地址的映射,頁(yè)表是一個(gè)數(shù)組,每個(gè)元素為一個(gè)頁(yè)的映射關(guān)系,這個(gè)映射關(guān)系可能是和主存地址,也可能和磁盤,頁(yè)表存儲(chǔ)在主存,我們將存儲(chǔ)在高速緩沖區(qū) cache 中的頁(yè)表稱為快表 TLAB 。
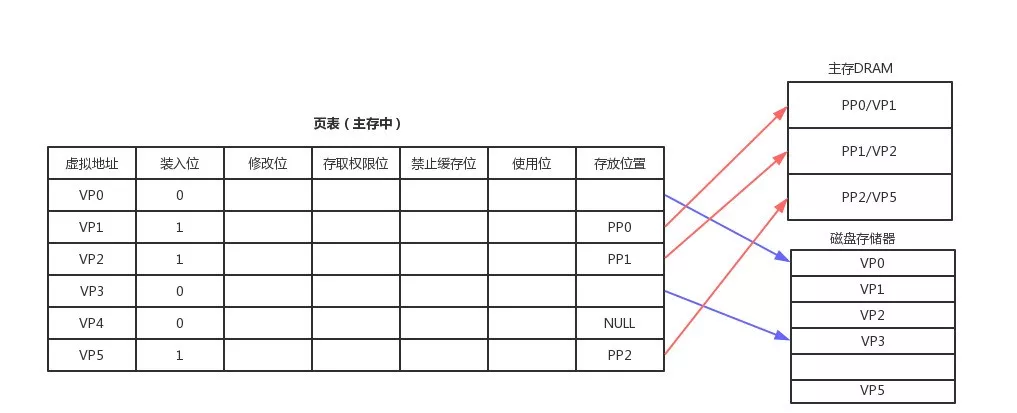
- 裝入位 表示對(duì)于頁(yè)是否在主存,如果地址頁(yè)每頁(yè)表示,數(shù)據(jù)還在磁盤
- 存放位置 建立虛擬頁(yè)和物理頁(yè)的映射,用于地址轉(zhuǎn)換,如果為null表示是一個(gè)未分配頁(yè)
- 修改位 用來(lái)存儲(chǔ)數(shù)據(jù)是否修改過(guò)
- 權(quán)限位 用來(lái)控制是否有讀寫權(quán)限
- 禁止緩存位 主要用來(lái)保證 cache 主存 磁盤的數(shù)據(jù)一致性
內(nèi)存映射
正常情況下,我們讀取文件的流程為,先通過(guò)系統(tǒng)調(diào)用從磁盤讀取數(shù)據(jù),存入操作系統(tǒng)的內(nèi)核緩沖區(qū),然后在從內(nèi)核緩沖區(qū)拷貝到用戶空間,而內(nèi)存映射,是將磁盤文件直接映射到用戶的虛擬存儲(chǔ)空間中,通過(guò)頁(yè)表維護(hù)虛擬地址到磁盤的映射,通過(guò)內(nèi)存映射的方式讀取文件的好處有,因?yàn)闇p少了從內(nèi)核緩沖區(qū)到用戶空間的拷貝,直接從磁盤讀取數(shù)據(jù)到內(nèi)存,減少了系統(tǒng)調(diào)用的開(kāi)銷,對(duì)用戶而言,仿佛直接操作的磁盤上的文件,另外由于使用了虛擬存儲(chǔ),所以不需要連續(xù)的主存空間來(lái)存儲(chǔ)數(shù)據(jù)。
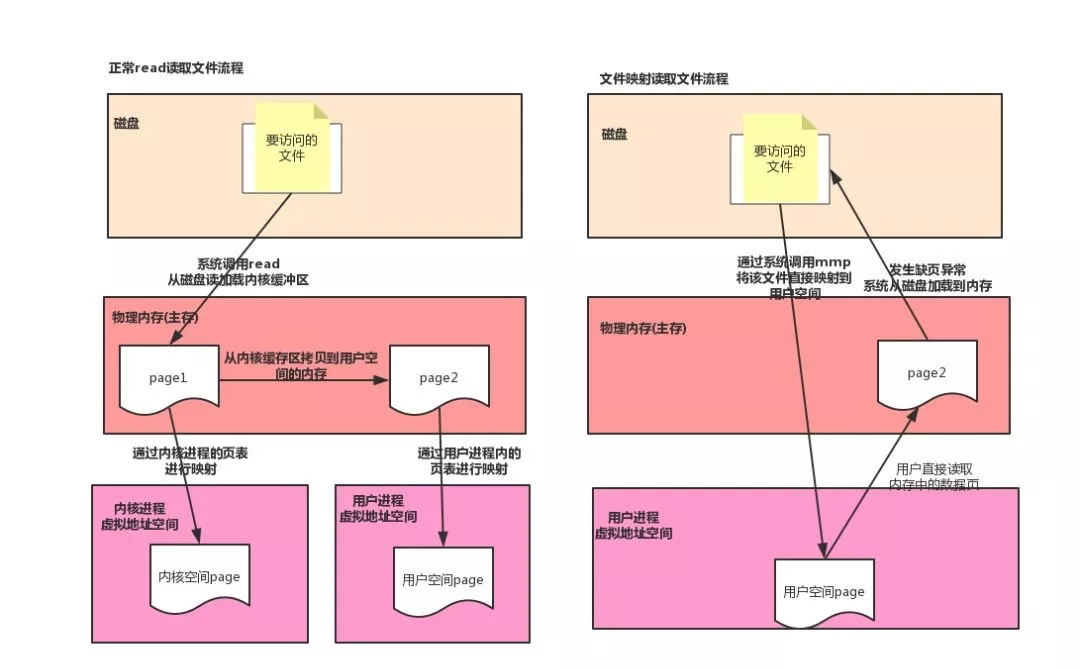
在 Java 中,我們使用 MAppedByteBuffer 來(lái)實(shí)現(xiàn)內(nèi)存映射,這是一個(gè)堆外內(nèi)存,在映射完之后,并沒(méi)有立即占有物理內(nèi)存,而是訪問(wèn)數(shù)據(jù)頁(yè)的時(shí)候,先查頁(yè)表,發(fā)現(xiàn)還沒(méi)加載,發(fā)起缺頁(yè)異常,然后在從磁盤將數(shù)據(jù)加載進(jìn)內(nèi)存,所以一些對(duì)實(shí)時(shí)性要求很高的中間件,例如rocketmq,消息存儲(chǔ)在一個(gè)大小為1G的文件中,為了加快讀寫速度,會(huì)將這個(gè)文件映射到內(nèi)存后,在每個(gè)頁(yè)寫一比特?cái)?shù)據(jù),這樣就可以把整個(gè)1G文件都加載進(jìn)內(nèi)存,在實(shí)際讀寫的時(shí)候就不會(huì)發(fā)生缺頁(yè)了,這個(gè)在rocketmq內(nèi)部叫做文件預(yù)熱。
下面我們貼一段 rocketmq 消息存儲(chǔ)模塊的代碼,位于 MappedFile 類中,這個(gè)類是 rocketMq 消息存儲(chǔ)的核心類感興趣的可以自行研究,下面兩個(gè)方法一個(gè)是創(chuàng)建文件映射,一個(gè)是預(yù)熱文件,每預(yù)熱 1000 個(gè)數(shù)據(jù)頁(yè),就讓出 CPU 權(quán)限。
private void init(final String fileName, final int fileSize) throws IOException {
this.fileName = fileName;
this.fileSize = fileSize;
this.file = new File(fileName);
this.fileFromOffset = Long.parseLong(this.file.getName());
boolean ok = false;
ensureDirOK(this.file.getParent());
try {
this.fileChannel = new RandomaccessFile(this.file, "rw").getChannel();
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
TOTAL_MAPPED_FILES.incrementAndGet();
ok = true;
} catch (FileNotFoundException e) {
log.error("create file channel " + this.fileName + " Failed. ", e);
throw e;
} catch (IOException e) {
log.error("map file " + this.fileName + " Failed. ", e);
throw e;
} finally {
if (!ok && this.fileChannel != null) {
this.fileChannel.close();
}
}
}
//文件預(yù)熱,OS_PAGE_SIZE = 4kb 相當(dāng)于每 4kb 就寫一個(gè) byte 0 ,將所有的頁(yè)都加載到內(nèi)存,真正使用的時(shí)候就不會(huì)發(fā)生缺頁(yè)異常了
public void warmMappedFile(FlushDiskType type, int pages) {
long beginTime = System.currentTimeMillis();
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
int flush = 0;
long time = System.currentTimeMillis();
for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) {
byteBuffer.put(i, (byte) 0);
// force flush when flush disk type is sync
if (type == FlushDiskType.SYNC_FLUSH) {
if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) {
flush = i;
mappedByteBuffer.force();
}
}
// prevent gc
if (j % 1000 == 0) {
log.info("j={}, costTime={}", j, System.currentTimeMillis() - time);
time = System.currentTimeMillis();
try {
// 這里sleep(0),讓線程讓出 CPU 權(quán)限,供其他更高優(yōu)先級(jí)的線程執(zhí)行,此線程從運(yùn)行中轉(zhuǎn)換為就緒
Thread.sleep(0);
} catch (InterruptedException e) {
log.error("Interrupted", e);
}
}
}
// force flush when prepare load finished
if (type == FlushDiskType.SYNC_FLUSH) {
log.info("mapped file warm-up done, force to disk, mappedFile={}, costTime={}",
this.getFileName(), System.currentTimeMillis() - beginTime);
mappedByteBuffer.force();
}
log.info("mapped file warm-up done. mappedFile={}, costTime={}", this.getFileName(),
System.currentTimeMillis() - beginTime);
this.mlock();
}
JVM 中對(duì)象的內(nèi)存布局
在linux中只要知道一個(gè)變量的起始地址就可以讀出這個(gè)變量的值,因?yàn)閺倪@個(gè)起始地址起前8位記錄了變量的大小,也就是可以定位到結(jié)束地址,在 Java 中我們可以通過(guò) Field.get(object) 的方式獲取變量的值,也就是反射,最終是通過(guò) UnSafe 類來(lái)實(shí)現(xiàn)的。我們可以分析下具體代碼。
Field 對(duì)象的 getInt方法 先安全檢查 ,然后調(diào)用 FieldAccessor
@CallerSensitive
public int getInt(Object obj)
throws IllegalArgumentException, IllegalAccessException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
return getFieldAccessor(obj).getInt(obj);
}
獲取field在所在對(duì)象中的地址的偏移量 fieldoffset
UnsafeFieldAccessorImpl(Field var1) {
this.field = var1;
if(Modifier.isStatic(var1.getModifiers())) {
this.fieldOffset = unsafe.staticFieldOffset(var1);
} else {
this.fieldOffset = unsafe.objectFieldOffset(var1);
}
this.isFinal = Modifier.isFinal(var1.getModifiers());
}
UnsafeStaticIntegerFieldAccessorImpl 調(diào)用unsafe中的方法
public int getInt(Object var1) throws IllegalArgumentException {
return unsafe.getInt(this.base, this.fieldOffset);
}
通過(guò)上面的代碼我們可以通過(guò)屬性相對(duì)對(duì)象起始地址的偏移量,來(lái)讀取和寫入屬性的值,這也是 Java 反射的原理,這種模式在jdk中很多場(chǎng)景都有用到,例如LockSupport.park中設(shè)置阻塞對(duì)象。 那么屬性的偏移量具體根據(jù)什么規(guī)則來(lái)確定的呢? 下面我們借此機(jī)會(huì)分析下 Java 對(duì)象的內(nèi)存布局。
在 Java 虛擬機(jī)中,每個(gè) Java 對(duì)象都有一個(gè)對(duì)象頭 (object header) ,由標(biāo)記字段和類型指針構(gòu)成,標(biāo)記字段用來(lái)存儲(chǔ)對(duì)象的哈希碼, GC 信息, 持有的鎖信息,而類型指針指向該對(duì)象的類 Class ,在 64 位操作系統(tǒng)中,標(biāo)記字段占有 64 位,而類型指針也占 64 位,也就是說(shuō)一個(gè) Java 對(duì)象在什么屬性都沒(méi)有的情況下要占有 16 字節(jié)的空間,當(dāng)前 JVM 中默認(rèn)開(kāi)啟了壓縮指針,這樣類型指針可以只占 32 位,所以對(duì)象頭占 12 字節(jié), 壓縮指針可以作用于對(duì)象頭,以及引用類型的字段。
JVM 為了內(nèi)存對(duì)齊,會(huì)對(duì)字段進(jìn)行重排序,這里的對(duì)齊主要指 Java 虛擬機(jī)堆中的對(duì)象的起始地址為 8 的倍數(shù),如果一個(gè)對(duì)象用不到 8N 個(gè)字節(jié),那么剩下的就會(huì)被填充,另外子類繼承的屬性的偏移量和父類一致,以 Long 為例,他只有一個(gè)非 static 屬性 value ,而盡管對(duì)象頭只占有 12 字節(jié),而屬性 value 的偏移量只能是 16, 其中 4 字節(jié)只能浪費(fèi)掉,所以字段重排就是為了避免內(nèi)存浪費(fèi), 所以我們很難在 Java 字節(jié)碼被加載之前分析出這個(gè) Java 對(duì)象占有的實(shí)際空間有多大,我們只能通過(guò)遞歸父類的所有屬性來(lái)預(yù)估對(duì)象大小,而真實(shí)占用的大小可以通過(guò) Java agent 中的 Instrumentation獲取。
當(dāng)然內(nèi)存對(duì)齊另外一個(gè)原因是為了讓字段只出現(xiàn)在同一個(gè) CPU 的緩存行中,如果字段不對(duì)齊,就有可能出現(xiàn)一個(gè)字段的一部分在緩存行 1 中,而剩下的一半在 緩存行 2 中,這樣該字段的讀取需要替換兩個(gè)緩存行,而字段的寫入會(huì)導(dǎo)致兩個(gè)緩存行上緩存的其他數(shù)據(jù)都無(wú)效,這樣會(huì)影響程序性能。
通過(guò)內(nèi)存對(duì)齊可以避免一個(gè)字段同時(shí)存在兩個(gè)緩存行里的情況,但還是無(wú)法完全規(guī)避緩存?zhèn)喂蚕淼膯?wèn)題,也就是一個(gè)緩存行中存了多個(gè)變量,而這幾個(gè)變量在多核 CPU 并行的時(shí)候,會(huì)導(dǎo)致競(jìng)爭(zhēng)緩存行的寫權(quán)限,當(dāng)其中一個(gè) CPU 寫入數(shù)據(jù)后,這個(gè)字段對(duì)應(yīng)的緩存行將失效,導(dǎo)致這個(gè)緩存行的其他字段也失效。

在 Disruptor 中,通過(guò)填充幾個(gè)無(wú)意義的字段,讓對(duì)象的大小剛好在 64 字節(jié),一個(gè)緩存行的大小為64字節(jié),這樣這個(gè)緩存行就只會(huì)給這一個(gè)變量使用,從而避免緩存行偽共享,但是在 jdk7 中,由于無(wú)效字段被清除導(dǎo)致該方法失效,只能通過(guò)繼承父類字段來(lái)避免填充字段被優(yōu)化,而 jdk8 提供了注解@Contended 來(lái)標(biāo)示這個(gè)變量或?qū)ο髮ⅹ?dú)享一個(gè)緩存行,使用這個(gè)注解必須在 JVM 啟動(dòng)的時(shí)候加上 -XX:-RestrictContended 參數(shù),其實(shí)也是用空間換取時(shí)間。
jdk6 --- 32 位系統(tǒng)下
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // 填充字段
}
jdk7 通過(guò)繼承
public class VolatileLongPadding {
public volatile long p1, p2, p3, p4, p5, p6; // 填充字段
}
public class VolatileLong extends VolatileLongPadding {
public volatile long value = 0L;
}
jdk8 通過(guò)注解
@Contended
public class VolatileLong {
public volatile long value = 0L;
}
NPTL和 Java 的線程模型
按照教科書(shū)的定義,進(jìn)程是資源管理的最小單位,而線程是 CPU 調(diào)度執(zhí)行的最小單位,線程的出現(xiàn)是為了減少進(jìn)程的上下文切換(線程的上下文切換比進(jìn)程小很多),以及更好適配多核心 CPU 環(huán)境,例如一個(gè)進(jìn)程下多個(gè)線程可以分別在不同的 CPU 上執(zhí)行,而多線程的支持,既可以放在Linux內(nèi)核實(shí)現(xiàn),也可以在核外實(shí)現(xiàn),如果放在核外,只需要完成運(yùn)行棧的切換,調(diào)度開(kāi)銷小,但是這種方式無(wú)法適應(yīng)多 CPU 環(huán)境,底層的進(jìn)程還是運(yùn)行在一個(gè) CPU 上,另外由于對(duì)用戶編程要求高,所以目前主流的操作系統(tǒng)都是在內(nèi)核支持線程,而在Linux中,線程是一個(gè)輕量級(jí)進(jìn)程,只是優(yōu)化了線程調(diào)度的開(kāi)銷。
而在 JVM 中的線程和內(nèi)核線程是一一對(duì)應(yīng)的,線程的調(diào)度完全交給了內(nèi)核,當(dāng)調(diào)用Thread.run 的時(shí)候,就會(huì)通過(guò)系統(tǒng)調(diào)用 fork() 創(chuàng)建一個(gè)內(nèi)核線程,這個(gè)方法會(huì)在用戶態(tài)和內(nèi)核態(tài)之間進(jìn)行切換,性能沒(méi)有在用戶態(tài)實(shí)現(xiàn)線程高,當(dāng)然由于直接使用內(nèi)核線程,所以能夠創(chuàng)建的最大線程數(shù)也受內(nèi)核控制。目前 Linux上 的線程模型為 NPTL ( Native POSIX Thread Library),他使用一對(duì)一模式,兼容 POSIX 標(biāo)準(zhǔn),沒(méi)有使用管理線程,可以更好地在多核 CPU 上運(yùn)行。
線程的狀態(tài)
對(duì)進(jìn)程而言,就三種狀態(tài),就緒,運(yùn)行,阻塞,而在 JVM 中,阻塞有四種類型,我們可以通過(guò) jstack 生成 dump 文件查看線程的狀態(tài)。
- BLOCKED (on object monitor) 通過(guò) synchronized(obj) 同步塊獲取鎖的時(shí)候,等待其他線程釋放對(duì)象鎖,dump 文件會(huì)顯示 waiting to lock <0x00000000e1c9f108>
- TIMED WAITING (on object monitor) 和 WAITING (on object monitor) 在獲取鎖后,調(diào)用了 object.wait() 等待其他線程調(diào)用 object.notify(),兩者區(qū)別是是否帶超時(shí)時(shí)間
- TIMED WAITING (sleeping) 程序調(diào)用了 thread.sleep(),這里如果 sleep(0) 不會(huì)進(jìn)入阻塞狀態(tài),會(huì)直接從運(yùn)行轉(zhuǎn)換為就緒
- TIMED WAITING (parking) 和 WAITING (parking) 程序調(diào)用了 Unsafe.park(),線程被掛起,等待某個(gè)條件發(fā)生,waiting on condition
而在 POSIX 標(biāo)準(zhǔn)中,thread_block 接受一個(gè)參數(shù) stat ,這個(gè)參數(shù)也有三種類型,TASK_BLOCKED, TASK_WAITING, TASK_HANGING,而調(diào)度器只會(huì)對(duì)線程狀態(tài)為 READY 的線程執(zhí)行調(diào)度,另外一點(diǎn)是線程的阻塞是線程自己操作的,相當(dāng)于是線程主動(dòng)讓出 CPU 時(shí)間片,所以等線程被喚醒后,他的剩余時(shí)間片不會(huì)變,該線程只能在剩下的時(shí)間片運(yùn)行,如果該時(shí)間片到期后線程還沒(méi)結(jié)束,該線程狀態(tài)會(huì)由 RUNNING 轉(zhuǎn)換為 READY ,等待調(diào)度器的下一次調(diào)度。
好了,關(guān)于線程就分析到這,關(guān)于 Java 并發(fā)包,核心都在 AQS 里,底層是通過(guò) UnSafe類的 cas 方法,以及 park 方法實(shí)現(xiàn),后面我們?cè)谡視r(shí)間單獨(dú)分析,現(xiàn)在我們?cè)诳纯?Linux 的進(jìn)程同步方案。
POSIX表示可移植操作系統(tǒng)接口(Portable Operating System Interface of UNIX,縮寫為 POSIX ),POSIX標(biāo)準(zhǔn)定義了操作系統(tǒng)應(yīng)該為應(yīng)用程序提供的接口標(biāo)準(zhǔn)。
CAS 操作需要 CPU 支持,將比較 和 交換 作為一條指令來(lái)執(zhí)行, CAS 一般有三個(gè)參數(shù),內(nèi)存位置,預(yù)期原值,新值 ,所以UnSafe 類中的 compareAndSwap 用屬性相對(duì)對(duì)象初始地址的偏移量,來(lái)定位內(nèi)存位置。

線程的同步
線程同步出現(xiàn)的根本原因是訪問(wèn)公共資源需要多個(gè)操作,而這多個(gè)操作的執(zhí)行過(guò)程不具備原子性,被任務(wù)調(diào)度器分開(kāi)了,而其他線程會(huì)破壞共享資源,所以需要在臨界區(qū)做線程的同步,這里我們先明確一個(gè)概念,就是臨界區(qū),他是指多個(gè)任務(wù)訪問(wèn)共享資源如內(nèi)存或文件時(shí)候的指令,他是指令并不是受訪問(wèn)的資源。
POSIX 定義了五種同步對(duì)象,互斥鎖,條件變量,自旋鎖,讀寫鎖,信號(hào)量,這些對(duì)象在 JVM 中也都有對(duì)應(yīng)的實(shí)現(xiàn),并沒(méi)有全部使用 POSIX 定義的 api,通過(guò) Java 實(shí)現(xiàn)靈活性更高,也避免了調(diào)用native方法的性能開(kāi)銷,當(dāng)然底層最終都依賴于 pthread 的 互斥鎖 mutex 來(lái)實(shí)現(xiàn),這是一個(gè)系統(tǒng)調(diào)用,開(kāi)銷很大,所以 JVM 對(duì)鎖做了自動(dòng)升降級(jí),基于AQS的實(shí)現(xiàn)以后在分析,這里主要說(shuō)一下關(guān)鍵字 synchronized 。
當(dāng)聲明 synchronized 的代碼塊時(shí),編譯而成的字節(jié)碼會(huì)包含一個(gè) monitorenter 和 多個(gè) monitorexit (多個(gè)退出路徑,正常和異常情況),當(dāng)執(zhí)行 monitorenter 的時(shí)候會(huì)檢查目標(biāo)鎖對(duì)象的計(jì)數(shù)器是否為0,如果為0則將鎖對(duì)象的持有線程設(shè)置為自己,然后計(jì)數(shù)器加1,獲取到鎖,如果不為0則檢查鎖對(duì)象的持有線程是不是自己,如果是自己就將計(jì)數(shù)器加1獲取鎖,如果不是則阻塞等待,退出的時(shí)候計(jì)數(shù)器減1,當(dāng)減為0的時(shí)候清楚鎖對(duì)象的持有線程標(biāo)記,可以看出 synchronized 是支持可重入的。
剛剛說(shuō)到線程的阻塞是一個(gè)系統(tǒng)調(diào)用,開(kāi)銷大,所以 JVM 設(shè)計(jì)了自適應(yīng)自旋鎖,就是當(dāng)沒(méi)有獲取到鎖的時(shí)候, CPU 回進(jìn)入自旋狀態(tài)等待其他線程釋放鎖,自旋的時(shí)間主要看上次等待多長(zhǎng)時(shí)間獲取的鎖,例如上次自旋5毫秒沒(méi)有獲取鎖,這次就6毫秒,自旋會(huì)導(dǎo)致 CPU 空跑,另一個(gè)副作用就是不公平的鎖機(jī)制,因?yàn)樵摼€程自旋獲取到鎖,而其他正在阻塞的線程還在等待。除了自旋鎖, JVM 還通過(guò) CAS 實(shí)現(xiàn)了輕量級(jí)鎖和偏向鎖來(lái)分別針對(duì)多個(gè)線程在不同時(shí)間訪問(wèn)鎖和鎖僅會(huì)被一個(gè)線程使用的情況。后兩種鎖相當(dāng)于并沒(méi)有調(diào)用底層的信號(hào)量實(shí)現(xiàn)(通過(guò)信號(hào)量來(lái)控制線程A釋放了鎖例如調(diào)用了 wait(),而線程B就可以獲取鎖,這個(gè)只有內(nèi)核才能實(shí)現(xiàn),后面兩種由于場(chǎng)景里沒(méi)有競(jìng)爭(zhēng)所以也就不需要通過(guò)底層信號(hào)量控制),只是自己在用戶空間維護(hù)了鎖的持有關(guān)系,所以更高效。

如上圖所示,如果線程進(jìn)入 monitorenter 會(huì)將自己放入該 objectmonitor 的 entryset 隊(duì)列,然后阻塞,如果當(dāng)前持有線程調(diào)用了 wait 方法,將會(huì)釋放鎖,然后將自己封裝成 objectwaiter 放入 objectmonitor 的 waitset 隊(duì)列,這時(shí)候 entryset 隊(duì)列里的某個(gè)線程將會(huì)競(jìng)爭(zhēng)到鎖,并進(jìn)入 active 狀態(tài),如果這個(gè)線程調(diào)用了 notify 方法,將會(huì)把 waitset 的第一個(gè) objectwaiter 拿出來(lái)放入 entryset (這個(gè)時(shí)候根據(jù)策略可能會(huì)先自旋),當(dāng)調(diào)用 notify 的那個(gè)線程執(zhí)行 moniterexit 釋放鎖的時(shí)候, entryset 里的線程就開(kāi)始競(jìng)爭(zhēng)鎖后進(jìn)入 active 狀態(tài)。
為了讓應(yīng)用程序免于數(shù)據(jù)競(jìng)爭(zhēng)的干擾, Java 內(nèi)存模型中定義了 happen-before 來(lái)描述兩個(gè)操作的內(nèi)存可見(jiàn)性,也就是 X 操作 happen-before 操作 Y , 那么 X 操作結(jié)果 對(duì) Y 可見(jiàn)。
JVM 中針對(duì) volatile 以及 鎖 的實(shí)現(xiàn)有 happen-before 規(guī)則, JVM 底層通過(guò)插入內(nèi)存屏障來(lái)限制編譯器的重排序,以 volatile 為例,內(nèi)存屏障將不允許 在 volatile 字段寫操作之前的語(yǔ)句被重排序到寫操作后面 , 也不允許讀取 volatile 字段之后的語(yǔ)句被重排序帶讀取語(yǔ)句之前。插入內(nèi)存屏障的指令,會(huì)根據(jù)指令類型不同有不同的效果,例如在 monitorexit 釋放鎖后會(huì)強(qiáng)制刷新緩存,而 volatile 對(duì)應(yīng)的內(nèi)存屏障會(huì)在每次寫入后強(qiáng)制刷新到主存,并且由于 volatile 字段的特性,編譯器無(wú)法將其分配到寄存器,所以每次都是從主存讀取,所以 volatile 適用于讀多寫少得場(chǎng)景,最好只有個(gè)線程寫多個(gè)線程讀,如果頻繁寫入導(dǎo)致不停刷新緩存會(huì)影響性能。
關(guān)于應(yīng)用程序中設(shè)置多少線程數(shù)合適的問(wèn)題,我們一般的做法是設(shè)置 CPU 最大核心數(shù) * 2 ,我們編碼的時(shí)候可能不確定運(yùn)行在什么樣的硬件環(huán)境中,可以通過(guò) Runtime.getRuntime().availableProcessors() 獲取 CPU 核心。
但是具體設(shè)置多少線程數(shù),主要和線程內(nèi)運(yùn)行的任務(wù)中的阻塞時(shí)間有關(guān)系,如果任務(wù)中全部是計(jì)算密集型,那么只需要設(shè)置 CPU 核心數(shù)的線程就可以達(dá)到 CPU 利用率最高,如果設(shè)置的太大,反而因?yàn)榫€程上下文切換影響性能,如果任務(wù)中有阻塞操作,而在阻塞的時(shí)間就可以讓 CPU 去執(zhí)行其他線程里的任務(wù),我們可以通過(guò) 線程數(shù)量=內(nèi)核數(shù)量 / (1 - 阻塞率)這個(gè)公式去計(jì)算最合適的線程數(shù),阻塞率我們可以通過(guò)計(jì)算任務(wù)總的執(zhí)行時(shí)間和阻塞的時(shí)間獲得。
目前微服務(wù)架構(gòu)下有大量的RPC調(diào)用,所以利用多線程可以大大提高執(zhí)行效率,我們可以借助分布式鏈路監(jiān)控來(lái)統(tǒng)計(jì)RPC調(diào)用所消耗的時(shí)間,而這部分時(shí)間就是任務(wù)中阻塞的時(shí)間,當(dāng)然為了做到極致的效率最大,我們需要設(shè)置不同的值然后進(jìn)行測(cè)試。

Java 中如何實(shí)現(xiàn)定時(shí)任務(wù)
定時(shí)器已經(jīng)是現(xiàn)代軟件中不可缺少的一部分,例如每隔5秒去查詢一下?tīng)顟B(tài),是否有新郵件,實(shí)現(xiàn)一個(gè)鬧鐘等, Java 中已經(jīng)有現(xiàn)成的 api 供使用,但是如果你想設(shè)計(jì)更高效,更精準(zhǔn)的定時(shí)器任務(wù),就需要了解底層的硬件知識(shí),比如實(shí)現(xiàn)一個(gè)分布式任務(wù)調(diào)度中間件,你可能要考慮到各個(gè)應(yīng)用間時(shí)鐘同步的問(wèn)題。
Java 中我們要實(shí)現(xiàn)定時(shí)任務(wù),有兩種方式,一種通過(guò) timer 類, 另外一種是 JUC 中的 ScheduledExecutorService ,不知道大家有沒(méi)有好奇 JVM 是如何實(shí)現(xiàn)定時(shí)任務(wù)的,難道一直輪詢時(shí)間,看是否時(shí)間到了,如果到了就調(diào)用對(duì)應(yīng)的處理任務(wù),但是這種一直輪詢不釋放 CPU 肯定是不可取的,要么就是線程阻塞,等到時(shí)間到了在來(lái)喚醒線程,那么 JVM 怎么知道時(shí)間到了,如何喚醒呢?
首先我們翻一下 JDK ,發(fā)現(xiàn)和時(shí)間相關(guān)的 API 大概有3處,而且這 3 處還都對(duì)時(shí)間的精度做了區(qū)分:
object.wait(long millisecond) 參數(shù)是毫秒,必須大于等于 0 ,如果等于 0 ,就一直阻塞直到其他線程來(lái)喚醒 ,timer 類就是通過(guò) wait() 方法來(lái)實(shí)現(xiàn),下面我們看一下wait的另外一個(gè)方法:
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos > 0) {
timeout++;
}
wait(timeout);
}
這個(gè)方法是想提供一個(gè)可以支持納秒級(jí)的超時(shí)時(shí)間,然而只是粗暴的加 1 毫秒。
Thread.sleep(long millisecond) 目前一般通過(guò)這種方式釋放 CPU ,如果參數(shù)為 0 ,表示釋放 CPU 給更高優(yōu)先級(jí)的線程,自己從運(yùn)行狀態(tài)轉(zhuǎn)換為可運(yùn)行態(tài)等待 CPU 調(diào)度,他也提供了一個(gè)可以支持納秒級(jí)的方法實(shí)現(xiàn),跟 wait 額區(qū)別是它通過(guò) 500000 來(lái)分隔是否要加 1 毫秒。
public static void sleep(long millis, int nanos)
throws InterruptedException {
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos >= 500000 || (nanos != 0 && millis == 0)) {
millis++;
}
sleep(millis);
}
LockSupport.park(long nans) Condition.await()調(diào)用的該方法, ScheduledExecutorService 用的 condition.await() 來(lái)實(shí)現(xiàn)阻塞一定的超時(shí)時(shí)間,其他帶超時(shí)參數(shù)的方法也都通過(guò)他來(lái)實(shí)現(xiàn),目前大多定時(shí)器都是通過(guò)這個(gè)方法來(lái)實(shí)現(xiàn)的,該方法也提供了一個(gè)布爾值來(lái)確定時(shí)間的精度。
System.currentTimeMillis() 以及 System.nanoTime() 這兩種方式都依賴于底層操作系統(tǒng),前者是毫秒級(jí),經(jīng)測(cè)試 windows 平臺(tái)的頻率可能超過(guò) 10ms ,而后者是納秒級(jí)別,頻率在 100ns 左右,所以如果要獲取更精準(zhǔn)的時(shí)間建議用后者好了,api 了解完了,我們來(lái)看下定時(shí)器的底層是怎么實(shí)現(xiàn)的,現(xiàn)代PC機(jī)中有三種硬件時(shí)鐘的實(shí)現(xiàn),他們都是通過(guò)晶體振動(dòng)產(chǎn)生的方波信號(hào)輸入來(lái)完成時(shí)鐘信號(hào)同步的。
- 實(shí)時(shí)時(shí)鐘 RTC ,用于長(zhǎng)時(shí)間存放系統(tǒng)時(shí)間的設(shè)備,即使關(guān)機(jī)也可以依靠主板中的電池繼續(xù)計(jì)時(shí)。Linux 啟動(dòng)的時(shí)候會(huì)從 RTC 中讀取時(shí)間和日期作為初始值,之后在運(yùn)行期間通過(guò)其他計(jì)時(shí)器去維護(hù)系統(tǒng)時(shí)間。
- 可編程間隔定時(shí)器 PIT ,該計(jì)數(shù)器會(huì)有一個(gè)初始值,每過(guò)一個(gè)時(shí)鐘周期,該初始值會(huì)減1,當(dāng)該初始值被減到0時(shí),就通過(guò)導(dǎo)線向 CPU 發(fā)送一個(gè)時(shí)鐘中斷, CPU 就可以執(zhí)行對(duì)應(yīng)的中斷程序,也就是回調(diào)對(duì)應(yīng)的任務(wù)
- 時(shí)間戳計(jì)數(shù)器 TSC , 所有的 Intel8086 CPU 中都包含一個(gè)時(shí)間戳計(jì)數(shù)器對(duì)應(yīng)的寄存器,該寄存器的值會(huì)在每次 CPU 收到一個(gè)時(shí)鐘周期的中斷信號(hào)后就會(huì)加 1 。他比 PIT 精度高,但是不能編程,只能讀取。
時(shí)鐘周期:硬件計(jì)時(shí)器在多長(zhǎng)時(shí)間內(nèi)產(chǎn)生時(shí)鐘脈沖,而時(shí)鐘周期頻率為1秒內(nèi)產(chǎn)生時(shí)鐘脈沖的個(gè)數(shù)。目前通常為1193180。
時(shí)鐘滴答:當(dāng)PIT中的初始值減到0的時(shí)候,就會(huì)產(chǎn)生一次時(shí)鐘中斷,這個(gè)初始值由編程的時(shí)候指定。

Linux啟動(dòng)的時(shí)候,先通過(guò) RTC 獲取初始時(shí)間,之后內(nèi)核通過(guò) PIT 中的定時(shí)器的時(shí)鐘滴答來(lái)維護(hù)日期,并且會(huì)定時(shí)將該日期寫入 RTC,而應(yīng)用程序的定時(shí)器主要是通過(guò)設(shè)置 PIT 的初始值設(shè)置的,當(dāng)初始值減到0的時(shí)候,就表示要執(zhí)行回調(diào)函數(shù)了,這里大家會(huì)不會(huì)有疑問(wèn),這樣同一時(shí)刻只能有一個(gè)定時(shí)器程序了,而我們?cè)趹?yīng)用程序中,以及多個(gè)應(yīng)用程序之間,肯定有好多定時(shí)器任務(wù),其實(shí)我們可以參考 ScheduledExecutorService 的實(shí)現(xiàn)。
只需要將這些定時(shí)任務(wù)按照時(shí)間做一個(gè)排序,越靠前待執(zhí)行的任務(wù)放在前面,第一個(gè)任務(wù)到了在設(shè)置第二個(gè)任務(wù)相對(duì)當(dāng)前時(shí)間的值,畢竟 CPU 同一時(shí)刻也只能運(yùn)行一個(gè)任務(wù),關(guān)于時(shí)間的精度問(wèn)題,我們無(wú)法在軟件層面做的完全精準(zhǔn),畢竟 CPU 的調(diào)度不完全受用戶程序控制,當(dāng)然更大的依賴是硬件的時(shí)鐘周期頻率,目前 TSC 可以提高更高的精度。
現(xiàn)在我們知道了,Java 中的超時(shí)時(shí)間,是通過(guò)可編程間隔定時(shí)器設(shè)置一個(gè)初始值然后等待中斷信號(hào)實(shí)現(xiàn)的,精度上受硬件時(shí)鐘周期的影響,一般為毫秒級(jí)別,畢竟1納秒光速也只有3米,所以 JDK 中帶納秒?yún)?shù)的實(shí)現(xiàn)都是粗暴做法,預(yù)留著等待精度更高的定時(shí)器出現(xiàn),而獲取當(dāng)前時(shí)間 System.currentTimeMillis() 效率會(huì)更高,但他是毫秒級(jí)精度,他讀取的 Linux 內(nèi)核維護(hù)的日期,而 System.nanoTime() 會(huì)優(yōu)先使用 TSC ,性能稍微低一點(diǎn),但他是納秒級(jí),Random 類為了防止沖突就用nanoTime生成種子。
Java 如何和外部設(shè)備通信
計(jì)算機(jī)的外部設(shè)備有鼠標(biāo)、鍵盤、打印機(jī)、網(wǎng)卡等,通常我們將外部設(shè)備和和主存之間的信息傳遞稱為 I/O 操作 , 按操作特性可以分為,輸出型設(shè)備,輸入型設(shè)備,存儲(chǔ)設(shè)備。現(xiàn)代設(shè)備都采用通道方式和主存進(jìn)行交互,通道是一個(gè)專門用來(lái)處理IO任務(wù)的設(shè)備, CPU 在處理主程序時(shí)遇到I/O請(qǐng)求,啟動(dòng)指定通道上選址的設(shè)備,一旦啟動(dòng)成功,通道開(kāi)始控制設(shè)備進(jìn)行操作,而 CPU 可以繼續(xù)執(zhí)行其他任務(wù),I/O 操作完成后,通道發(fā)出 I/O 操作結(jié)束的中斷,處理器轉(zhuǎn)而處理 IO 結(jié)束后的事件。其他處理 IO 的方式,例如輪詢、中斷、DMA,在性能上都不見(jiàn)通道,這里就不介紹了。當(dāng)然 Java 程序和外部設(shè)備通信也是通過(guò)系統(tǒng)調(diào)用完成,這里也不在繼續(xù)深入了。





