

今天準備談下ESB總線平臺建設項目中的服務運行統計分析,服務心跳監測,服務監控預警方面的設計和實現。可以看到,在一個ESB服務總線平臺上線后,SOA治理管控就變得相當重要,而這些運行監控分析本身也是提升ESB總線平臺高可用性的關鍵。
對于ESB總線本身的高可用性建設,我在前面寫過一篇文章可以參考。
大型集團ESB服務總線平臺建設項目高可用性實踐總結
今天主要分享下對于這類大型ESB總線平臺建設項目在服務運行統計分析,服務心跳監測,服務監控,服務預警等配合高可用性能力方面的一些實踐總結。
對接口服務運行統計分析的思考
對于ESB服務運行監控,從SOA服務管控和治理層面來看,經常會涉及到的KPI性能指標并不多,主要還是體現在運行次數,運行時間等關鍵的維度,如果考慮到指標本身之間的關聯關系方便分析,那么還需要增加服務運行的并發數(分鐘級),服務調用的數據量等關鍵指標。
舉例來說,當我們發現服務調用變慢了,即服務運行時間明顯增加了,那么我們需要分析是否是該服務本身的并發量是否增加了,還是說服務本身調用的數據量增加了,還是說其它服務調用的并發量和數據量增加了導致該服務的資源被占用等。這些都是可能需要涉及到關聯分析的地方。
首先我們來看下單次服務運行能夠采集和記錄的關鍵數據
- 服務運行時間(服務請求開始 to 服務請求結束)
- 服務運行是否成功(True or False)
- 服務傳輸的消息報文大小
- 服務名稱
- 服務提供的系統,包括服務提供系統歸屬的組織類別等
- 服務消費方系統
- 正常調用還是非法調用

接著再來看某個時間周期的情況,比如1個小時,1天,1周或1個月的統計時間周期
- 運行次數,對運行次數進行求和
- 最大分鐘級并發數,取并發數的Max值
- 異常數,對異常數按時間點進行求和
- 告警數,對告警數按時間點進行求和
- 服務最大運行時間,最小運行時間,平均運行時間
- 服務消息報文最大報文,最小報文,平均報文容量
對于時間周期只我們我們統計的一個維度,而對服務進行分析的時候還需要考慮如下維度
- 按服務目錄-》按服務
- 按企業-》子公司-》子組織
- 按應用域-》按應用系統-》按模塊
- 按服務類型-》服務子類型
- 按服務提供系統,服務消費系統
經過以上分析,我們看到一個最底層的服務運行日志信息,就有了按時間維度,按組織,服務類型,系統等多個維度進行維度分析和統計的可能。而這些恰好又是我們進行自定義報表和維度分析的基礎。所有的統計分析基本都會基于以上基礎運行信息展開進行。
基于以上思考,我們整合了一個面向組織和業務系統的服務運行統計分析報表,可以按系統的維度詳細的查看到自己提供和消費的接口服務的運行情況,異常情況,并發量和數據量,異常和告警等各種關鍵信息。如下參考:
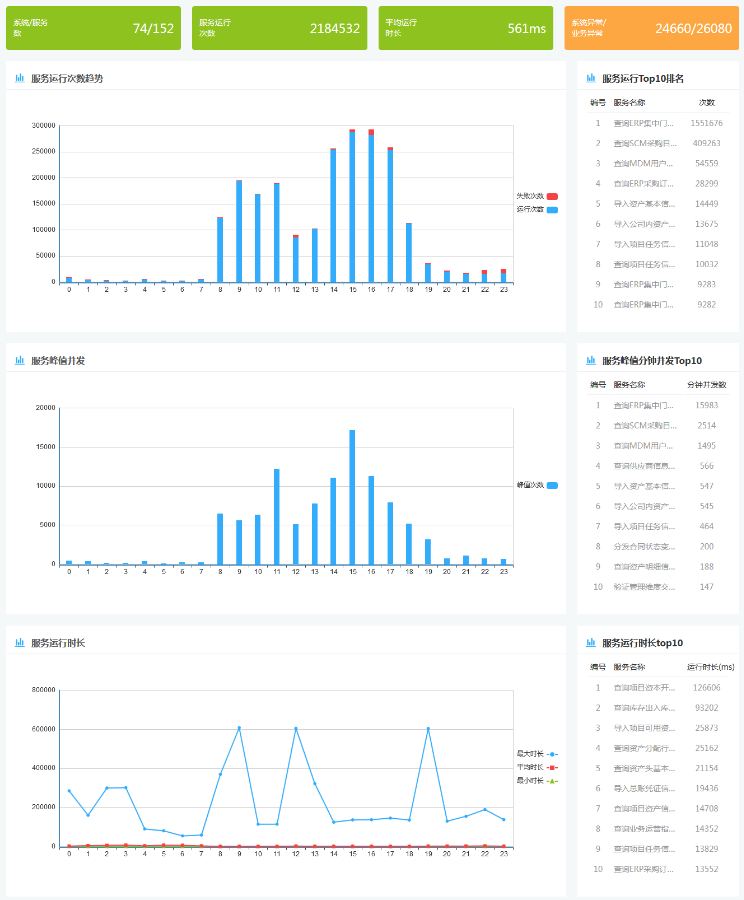
為了做完整的服務運行和性能分析,我們最好還需要對中間件資源池(應用服務器和數據庫服務器)的CPU,內存利用率,存儲使用量等關鍵指標進行實時的性能分析和監控。在實際的性能分析和監控中往往也是首先會從CPU和內存告警上第一時間反應出服務當前運行出現異常(如大并發,超大數據傳輸等),然后我們在通過實際的日志監控分析功能快速的查看當前服務運行的并發情況,傳遞的數據量情況等。
當我們發現如果一個服務經常運行大并發,大數據量的異常調用的時候,則需要對服務單獨啟用流量控制策略等。比如:
- 對服務傳輸的數據量及報文大小進行流控。
- 對服務本身的并發量進行流控。
- 對某個服務最大能夠使用的資源量進行流控,防止單服務占滿所有資源。
服務運行指標勾稽關系分析
服務運行指標相關之間的關聯分析是我們進行服務運行問題排查,異常告警問題根源分析的基礎。在前面談SOA治理管控平臺中,我們曾經畫過一個圖來說明,服務運行過程中的基礎物理資源,數據庫和應用服務器中間件資源,服務運行KPI和SLA設置之間的關聯關系,如下:

基于上圖,我們進一步做下擴展分析,先做下基本的關聯關系判別:
JVM內存持續增加不釋放,一個是服務并發量增加同時服務調用時間增長,其次是出現大數據量,長執行時間的服務調用,導致服務連接和內存無法快速回收。CPU使用率高升,但是內存利用率一般,一般為出現大并發量的服務調用,其次對于服務調用過程中有過多的數據映射,轉換等處理導致CPU利用率增加。
服務調用運行時間長,首先要分析是否是原始服務本身調用時間就變長,如果不是,則一般是在ESB服務調用上出現大量長周期服務調用,但是連接不能快速是否,線程池滿一直排隊的情況。
如果JVM內存溢出,首先要通過Jstat工具監控下內存GC回收的情況,究竟是新時代,老生代,還是PermSize出現溢出。如果是PermSize需要進一步分析是否是程序本身有問題。
如果沒有做流量控制,單個服務本身的大并發,大數據量調用往往會侵占所有資源,對整個ESB上其它運行的服務都造成性能影響。
對于ESB總線本身的等待線程數增加一定會涉及到內存持續增加,涉及到服務調用響應周期增加。如果是服務調用超時,則需要分析具體是在哪段引起的超時,是原始服務本身超時,還是在ESB中間件上進行服務處理的時候超時。
對于服務告警和預警,前面也講到過,再強調下具體場景包括
- 服務單位時間運行次數明顯增加,我們可以設置一個閾值,只要超過了就進行報警。
- 服務運行時間明顯增加,我們可以設置一個閾值,只要超過了就進行報警。
- 服務單位時間數據量明顯增加,我們可以設置一個閾值,只要超過了就進行報警。
注意對于服務告警策略可以是針對所有服務,也可以是針對某個具體的服務,對于閾值可以是一個百分比數,也可以是一個絕對值。接下來我們再看下服務運行各個指標本身之間的一些關聯關系:
- 服務傳遞數據量大,一定帶來內存增加
- 服務運行時長增加,同時更加容易引起服務調用超時。
- 服務調用并發量增加,服務調用時長一般也會增加,如果時長增加明顯,則一定導致內存持續增加。單個服務本身的并發量增加,會引起ESB上線程排隊增加,導致直接影響到其它服務調用性能。
- 單個服務調用本身的數據量增加,容易引起JVM內存持續增加,導致JVM內存溢出。
- 如果是后端服務本身性能下降,最明顯的就是占有連接,資源不釋放,導致ESB本身性能下降。
而對于整個ESB中間件的性能監控和分析,從最底層的IT基礎設施,存儲和服務器,到ESB中間件資源池,再到具體運行的服務運行包,相互之間存在密切的關聯,需要達到的效果往往是第一時間反饋出預警。并且通過預警去采取后續的行動措施和SLA策略設置等。
1. 從資源池監控發現的CPU和內存異常第一時間找到非法調用服務?

如果有CPU和內存利用率出現異常,同時某個服務或某幾個服務出現運行性能告警,那么我們就有了分析的依據究竟是哪個服務導致的。并快速定位到具體的服務。在定位到具體的服務后,可以再詳細查看服務調用的并發數,數據量等信息,然后有針對性的對服務展開流量控制策略。
2. 如果JVM內存持續上升而沒有釋放,如何快速定位到服務?
這個也是經常遇到的問題,當JVM內存持續增加,或者連接數不斷的增加而不釋放的時候,如果我們不進行及時的處理往往就導致整個JVM內存溢出而影響到所有ESB服務的運行。因此在這種場景下我們需要盡快的發現導致問題的服務,并對服務采取相應的措施。
3. 從服務運行告警到自動熔斷
為了不因為一個具體服務的異常非法調用而影響到所有服務的運行,對于單個服務在出現持續性的告警后,應該有策略直接對該服務進行熔斷處理。比如直接對服務進行禁用處理。
增加實時的心跳檢查
在前面部分已經詳細分析了服務本身的運行并發,次數和數據量與JVM內存,與CPU和內存利用率等各個關鍵指標之間的勾稽關系。
這些指標之間本身相互影響和作用,我們對指標的監控本身應該是風險驅動的,即在系統出現宕機或內存溢出等故障問題前快速的發現問題并進行處理。
因此,我們就需要對各種關鍵指標進行心跳監控和實時預警。
對JVM內存利用率進行監控
在前面我們已經談到了,實際上出現JVM溢出的時候,往往會由于請求漂移影響到整個集群大量節點內存溢出而導致集群不可用。
因此需要時刻監控JVM內存利用率的情況,如果發現JVM內存持續在某個高位,無法通過Gc操作將內存回收下來的時候就應該實時進行預警。
在預警后我們既可以進行人工處理,也可以設置策略直接對問題節點進行重啟操作。
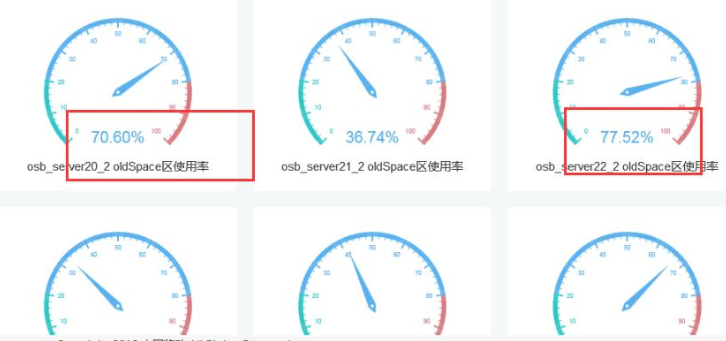
如上,我們對所有集群節點的JVM內存利用率進行實時監控,當發現利用率持續大于70%的時候就進行相應的預警操作,如果超過80%就推送嚴重警告信息。
對后端業務系統和服務本身可用性監控
其次,ESB服務總線如果出現服務調用異常,除了ESB總線本身的異常故障外,更大的可能性是后端業務系統不可用,或者說后端業務系統提供的業務服務不可用導致。
對于ESB總線本身,我們可以實時心跳檢查ESB總線暴露的服務可用性,如下:

如果是后端系統本身不可用,那么往往會快速的返回connection timeout異常信息,這樣不會影響到整個ESB總線平臺穩定性。但是如果是后端業務系統服務假死或處于長時間無響應的狀態,那么就會導致大量的連接無法釋放,最終導致資源被消耗完。
因此對后端系統和后端服務進行實時心跳監控也是有必要的。
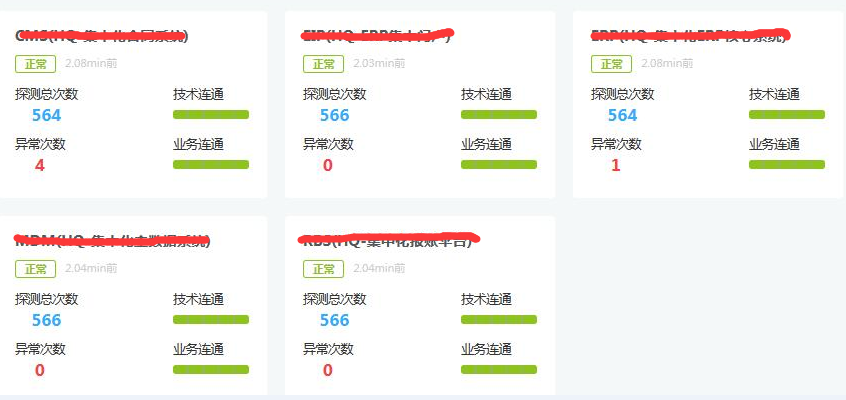
不論是對于ESB集群還是后端業務系統的監控,實際上都包括兩個方面的監控,一個我們叫技術聯通性監控,一個叫業務聯通性監控。
技術連通性即是否出現conneciton timeout訪問超時,是就返回異常。而對于業務聯通性,則是調用真實的某個業務服務接口,如果出現read time out則返回業務連通失敗錯誤。
對服務運行進行實時心跳監控
其次,我們還需要對服務運行進行實時心跳監控,即時刻監控服務運行的并發量,數據量,運行時長等幾個關鍵數據指標。
在前面已經談到過以上幾個指標本身存在勾稽關系,比如發現服務運行平均時長增加,那么很可能是服務并發量增加或調用數據量增加導致。其次,如果發現服務調用的消息報文數據量猛增,那么很可能導致服務運行時長增加。
因此需要對以上幾個關鍵指標進行實時監控,時刻監控是否發生了峰值突變情況。
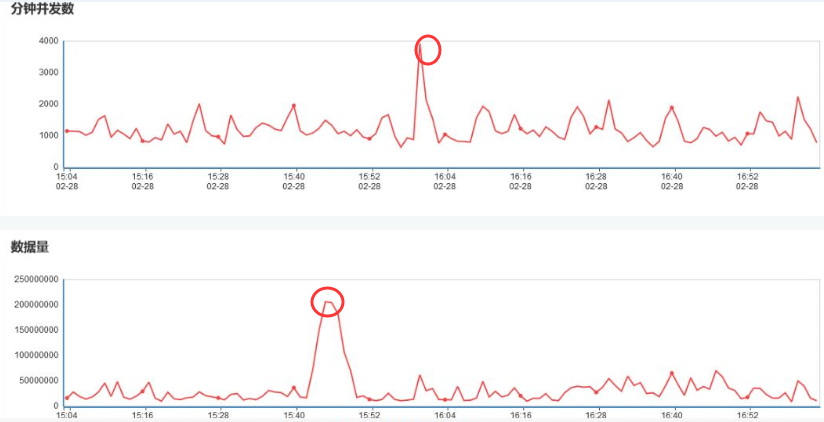
當發現了峰值或突變的時候,我們就需要進行預警,并分析發生大并發或大數據量調用的原因并及時采取相應的流量管控措施,以確保整個ESB平臺的穩定性。
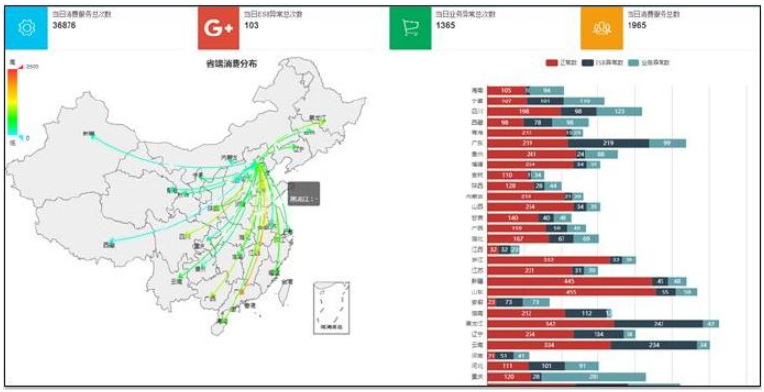
通過監控大屏可視化實時監控

監控大屏更多的是展示基于服務集成層面的總覽數據,同時對關鍵的異常告警信息,關鍵指標心跳,關鍵指標排名信息進行展示。這些都應該在Level1級層面的視圖或報表。
我們舉一個簡單場景,一個企業實施了ESB總線后,集成了20個業務系統,上100個服務接口,每天大概產生100萬條服務調用示例記錄,高峰時期的分鐘級并發在1萬次左右。
總線實際上和硬件類網關很類似,當所有的服務調用全部都有經過總線的時候,我們就更加關心總線上實際的實時并發量,數據流量大小數據。而且這兩個數據最好是要實現準實時的監控。以分鐘級為例,我們需要監控分鐘級的服務調用次數,分鐘級的服務調用傳輸數據量。
監控著兩個指標是否出現突然的峰值調用,如果沒有一般來說總線運行本身也不好出現問題。如果出現了各種異常大并發,大數據量調用,則一定會體現到我們的監控時序圖上面。這兩個數據實際上是適合在大屏上面實時心跳檢測并顯示的。
對于大屏可視化展示,我們可以理解為總覽,即更多的是當前ESB總線服務,集成的業務系統的總體健康情況。因此在大屏上我們可以考慮對當天的一些統計數據進行統計展示。
這些統計數據包括了服務調用總次數,平均時長,總數據量,平均數據量,分鐘級最大并發,接入總系統數,接入總服務數,總異常數,總告警次數等。對于異常告警往往是一個比較重要的展示內容,特別是異常信息本身還分為了系統級的異常和業務級的異常,對于告警本身又分為嚴重,一般,輕微等各種級別的告警。這些都需要在大屏進行一個統計的展示。
如果是做集團到省兩級ESB總線實施,在大屏上我們就可以考慮來實現結合地圖的可視化效果展示。這個前面有文章說過,可以通過連線,端點節點大小,顏色等來體現服務調用流量,狀態等信息。
即使是單級ESB總線,在大屏展示的時候我們也需要考慮是否能夠展示一個集成架構視圖,能夠展示出當前總線集成的多個業務系統,類似Bus總線的展示方式,可以通過該圖將集成的關鍵系統全部標注出來。同時對于集成的系統上本身可以顯示更多的關鍵信息。
如果集成的業務系統用一個方框進行展示,那么在方框里面可以考慮展示。
- 方框的顏色用于展示當前提供服務的本身的異常和告警情況
- 方框內可以顯示提供服務數和消費服務數
- 方框內可以顯示服務當天的服務提供總次數,峰值并發量
最后,大屏本身也可以展示一些列表數據,但是從大屏可視化效果來說,列表數據不適合展示太多。可以考慮的列表數據展示主要包括了服務運行次數,服務調用異常,服務調用耗時或數據量的Top10排名信息顯示等。





