
在分布式系統,尤其是微服務系統中,一次外部請求往往需要內部多個模塊,多個中間件,多臺機器的相互調用才能完成。在這一系列的調用中,可能有些是串行的,而有些是并行的。在這種情況下,我們如何才能確定這整個請求調用了哪些應用?哪些模塊?哪些節點?以及它們的先后順序和各部分的性能如何呢?
這就是涉及到鏈路追蹤。
什么是鏈路追蹤?
鏈路追蹤是分布式系統下的一個概念,它的目的就是要解決上面所提出的問題,也就是將一次分布式請求還原成調用鏈路,將一次分布式請求的調用情況集中展示,比如,各個服務節點上的耗時、請求具體到達哪臺機器上、每個服務節點的請求狀態等等。
鏈路追蹤的原理
衡量一個接口,我們一般會看三個指標:
- 接口的 RT(Route-Target)你怎么知道?
- 接口是否有異常響應?
- 接口請求慢在哪里?
1、單體架構時代
在創業初期,我們的系統一般是單體架構,如下:

對于單體架構,我們可以使用 AOP(切面編程)來統計這三個指標,如下:
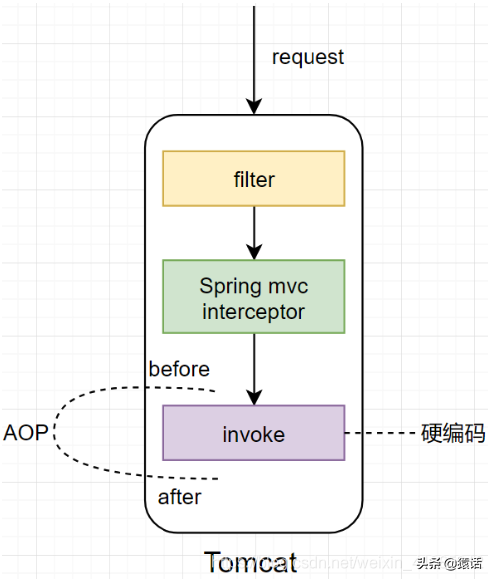
使用 AOP(切面編程),對原本的邏輯代碼侵入更少,我們只需要在調用具體的業務邏輯前后分別打印一下時間即可計算出整體的調用時間。另外,使用 AOP(切面編程)來捕獲異常也可知道是哪里的調用導致的異常。
2、微服務架構
隨著業務的快速發展,單體架構越來越不能滿足需要,我們的系統慢慢會朝微服務架構發展,如下:

一個稍微復雜的微服務架構
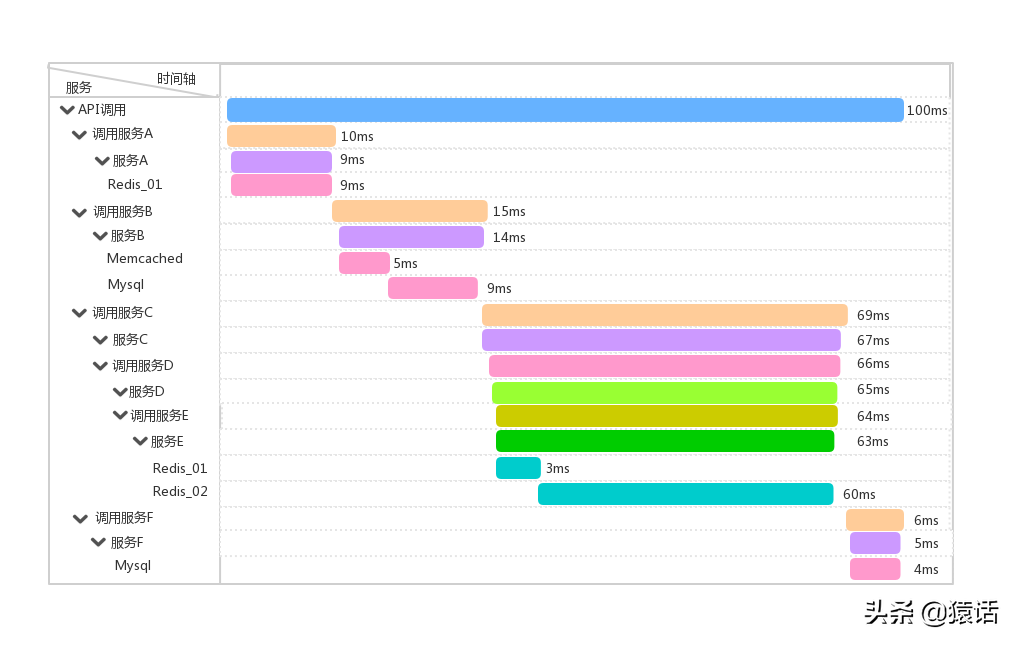
在微服務價格下,當有用戶反饋某個頁面很慢時,雖然我們知道這個請求可能的調用鏈是 A -----> C -----> B -----> D,但服務這么多,而且每個服務都有好幾臺機器,怎么知道問題具體出在哪個服務?哪臺機器呢?

這也是微服務這種架構下的幾個痛點:
- 排查問題難度大,周期長
- 特定場景難復現
- 系統性能瓶頸分析較難
分布式調用鏈就是為了解決以上幾個問題而生,它主要的作用如下:
- 自動采取數據
- 分析數據,產生完整調用鏈:有了請求的完整調用鏈,問題有很大概率可復現
- 數據可視化:每個組件的性能可視化,能幫助我們很好地定位系統的瓶頸,及時找出問題所在
通過分布式追蹤系統,我們能很好地定位請求的每條具體請求鏈路,從而輕易地實現請求鏈路追蹤,進而定位和分析每個模塊的性能瓶頸。

3、分布式調用鏈標準(OpenTracing)
OpenTracing 是一個輕量級的標準化層,它位于應用程序/類庫和追蹤或日志分析程序之間。它的出現是為了解決不同的分布式追蹤系統 API 不兼容的問題。
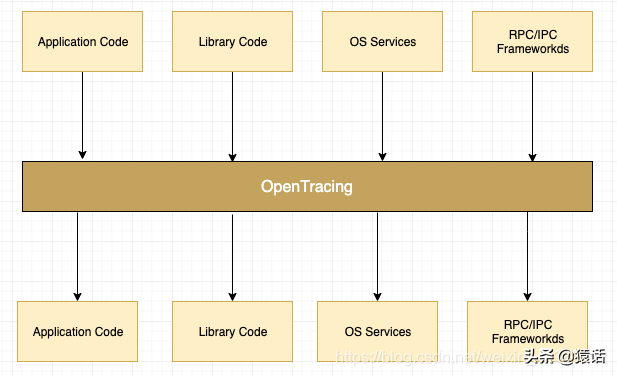
OpenTracing 通過提供與平臺和廠商無關的 API,使得開發人員能夠方便地添加追蹤系統,就像單體架構下的AOP(切面編程)一樣。
說到這里,大家是否想過 JAVA 中類似的實現?還記得 JDBC 吧?JDBC 就是通過提供一套標準的接口讓各個廠商去實現,程序員即可面對接口編程,不用關心具體的實現。這里的接口其實就是標準。所以,制定一套標準非常重要,可以實現組件的可插拔。

OpenTracing 的數據模型,主要有以下三個:
- Trace:一個完整請求鏈路
- Span:一次調用過程(需要有開始時間和結束時間)
- SpanContext:Trace 的全局上下文信息,如里面有traceId
為了讓大家更好地理解這三個概念,我特意畫了一張圖:

如圖所示,一次下單的完整請求就是一個 Trace。TraceId是這個請求的全局標識。內部的每一次調用就稱為一個 Span,每個 Span 都要帶上全局的 TraceId,這樣才可把全局 TraceId 與每個調用關聯起來。這個 TraceId 是通過 SpanContext 傳輸的,既然要傳輸,顯然都要遵循協議來調用。如圖所示,如果我們把傳輸協議比作車,把 SpanContext 比作貨,把 Span 比作路應該會更好理解一些。
理解了這三個概念,接下來我們就看看分布式追蹤系統是如何采集圖中的微服務調用鏈。
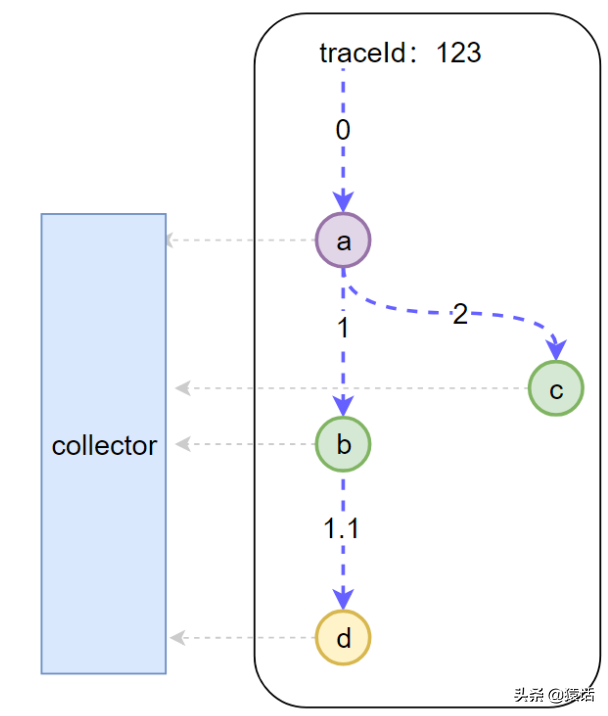
我們可以看到底層有一個 Collector 一直在默默無聞地收集數據,那么每一次調用 Collector 會收集哪些信息呢。
- 全局 trace_id:這是顯然的,這樣才能把每一個子調用與最初的請求關聯起來
- span_id: 圖中的 0,1,1.1,2,這樣就能標識是哪一個調用
- parent_span_id:比如 b 調用 d 的 span_id 是 1.1,那么它的 parent_span_id 即為 a 調用 b 的 span_id 即 1,這樣才能把兩個緊鄰的調用關聯起來。
有了這些信息,Collector 收集的每次調用的信息如下:

根據這些圖表信息顯然可以據此來畫出調用鏈的可視化視圖如下:

于是一個完整的分布式追蹤系統就實現了。
以上實現看起來確實簡單,但有以下幾個問題需要我們仔細思考一下:
- 怎么自動采集 span 數據:自動采集,對業務代碼無侵入
- 如何跨進程傳遞 context
- traceId 如何保證全局唯一
- 請求量這么多采集會不會影響性能
接下來,我們來看看鏈路追蹤系統 SkyWalking 是如何解決以上四個問題的。
鏈路追蹤系統SkyWalking的原理
1、怎么自動采集 span 數據
SkyWalking 采用了插件化 + javaagent 的形式來實現了 span 數據的自動采集,這樣可以做到對代碼的無侵入性。插件化意味著可插拔,擴展性好。如下圖所示:

2、如何跨進程傳遞 context
我們知道數據一般分為 header 和 body,就像 http 有 header 和 body,RocketMQ 也有 MessageHeader,Message Body。body 一般放著業務數據,所以不宜在 body 中傳遞 context,應該在 header 中傳遞 context,如圖所示:
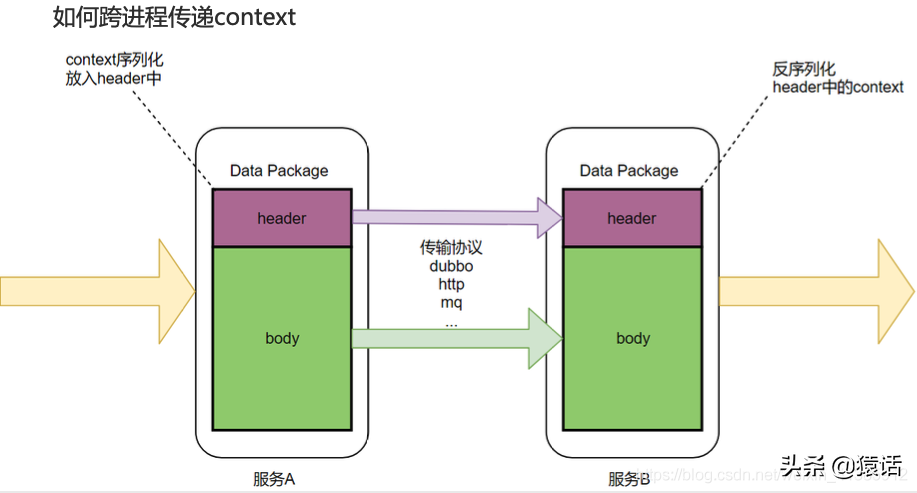
dubbo 中的 attachment 就相當于 header,所以我們把 context 放在 attachment 中,這樣就解決了 context 的傳遞問題。

3、traceId 如何保證全局唯一
要保證全局唯一 ,我們可以采用分布式或者本地生成的 ID。使用分布式的話,需要有一個發號器,每次請求都要先請求一下發號器,會有一次網絡調用的開銷。所以 SkyWalking 最終采用了本地生成 ID 的方式,它采用了大名鼎鼎的 snowflow 算法,性能很高。

snowflake 算法生成的 id
不過 snowflake 算法有一個眾所周知的問題:時間回撥,這個問題可能會導致生成的 id 重復。那么 SkyWalking 是如何解決時間回撥問題的呢。

每生成一個 id,都會記錄一下生成 id 的時間(lastTimestamp),如果發現當前時間比上一次生成 id 的時間(lastTimestamp)還小,那說明發生了時間回撥,此時會生成一個隨機數來作為 traceId。這里可能就有同學要較真了,可能會覺得生成的這個隨機數也會和已生成的全局 id 重復,是否再加一層校驗會好點。
這里要說一下系統設計上的方案取舍問題了,首先如果針對產生的這個隨機數作唯一性校驗無疑會多一層調用,會有一定的性能損耗,但其實時間回撥發生的概率很小(發生之后由于機器時間紊亂,業務會受到很大影響,所以機器時間的調整必然要慎之又慎),再加上生成的隨機數重合的概率也很小,綜合考慮這里確實沒有必要再加一層全局唯一性校驗。對于技術方案的選型,一定要避免過度設計,過猶不及。
4、請求量這么多,全部采集會不會影響性能?
如果對每個請求調用都采集,那毫無疑問數據量會非常大,但反過來想一下,是否真的有必要對每個請求都采集呢?其實沒有必要,我們可以設置采樣頻率,只采樣部分數據,SkyWalking 默認設置了 3 秒采樣 3 次,其余請求不采樣,如圖所示:
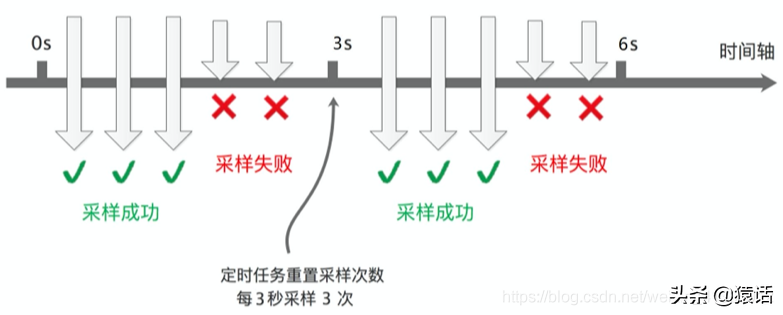
這樣的采樣頻率其實足夠我們分析組件的性能了,按 3 秒采樣 3 次,這樣的頻率來采樣數據會有啥問題呢。理想情況下,每個服務調用都在同一個時間點,這樣的話每次都在同一時間點采樣確實沒問題。如下圖所示:
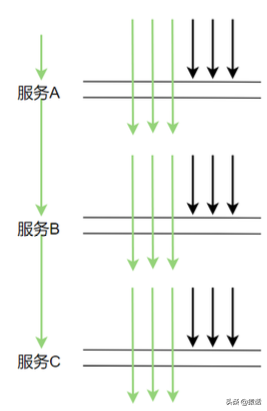
但在生產上,每次服務調用基本不可能都在同一時間點調用,因為期間有網絡調用延時等,實際調用情況很可能是下圖這樣:

這樣的話就會導致某些調用在服務 A 上被采樣了,在服務 B,C 上不被采樣,也就沒法分析調用鏈的性能。
那么 SkyWalking 是如何解決的呢?
它是這樣解決的:如果上游有攜帶 Context 過來(說明上游采樣了),則下游將強制采集數據,這樣可以保證鏈路完整。
SkyWalking 的基礎架構
SkyWalking 的基礎如下架構,可以說幾乎所有的的分布式調用都是由以下幾個組件組成的。
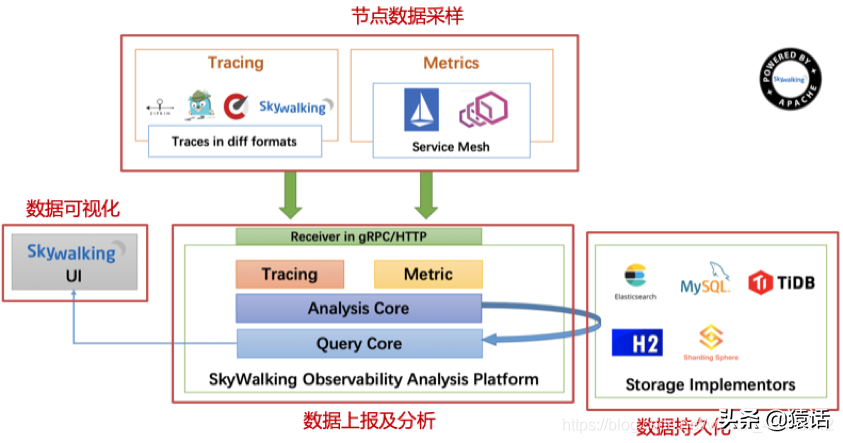
首先當然是節點數據的定時采樣,采樣后將數據定時上報,將其存儲到 ES, MySQL 等持久化層,有了數據自然而然可根據數據做可視化分析。
SkyWalking 的性能如何
如下是官方的測評數據:

圖中藍色代表未使用 SkyWalking 的表現,橙色代表使用了 SkyWalking 的表現,以上是在 TPS 為 5000 的情況下測出的數據,可以看出,不論是 CPU,內存,還是響應時間,使用 SkyWalking 帶來的性能損耗幾乎可以忽略不計。
接下來我們再來看 SkyWalking 與另一款業界比較知名的分布式追蹤工具 Zipkin、Pinpoint 的對比(在采樣率為 1 秒 1 個,線程數 500,請求總數為 5000 的情況下做的對比)。
可以看到在關鍵的響應時間上, Zipkin(117ms),PinPoint(201ms)遠遜于 SkyWalking(22ms)!從性能損耗這個指標上看,SkyWalking 完勝!

再看下另一個指標:對代碼的侵入性如何。
ZipKin 是需要在應用程序中埋點的,對代碼的侵入強,而 SkyWalking 采用 javaagent + 插件化這種修改字節碼的方式可以做到對代碼無任何侵入。除了性能和對代碼的侵入性上 SkyWaking 表現不錯外,它還有以下優勢幾個優勢:
- 對多語言的支持,組件豐富:目前其支持 Java、 .Net Core、php、NodeJS、Golang、LUA 語言,組件上也支持dubbo, mysql 等常見組件,大部分能滿足我們的需求。
- 擴展性:對于不滿足的插件,我們按照 SkyWalking 的規則手動寫一個即可,新實現的插件對代碼無入侵。
以上雖然主要以SkyWalking為例來介紹鏈路追蹤系統,但是并不是說其他鏈路追蹤系統一點不適用。具體選擇什么樣的,大家可按實際場景靈活選擇。





