
專注Python/ target=_blank class=infotextkey>Python、AI、大數據,請關注公眾號七步編程!
在不同公司的許多人可能出于各種原因需要從Inte.NET收集外部數據:分析競爭,匯總新聞摘要、跟蹤特定市場的趨勢,或者收集每日股票價格以建立預測模型……
無論你是數據科學家還是業務分析師,都可能時不時遇到這種情況,并問自己一個永恒的問題:我如何才能提取該網站的數據以進行市場分析?
提取網站數據及其結構的一種可能的免費方法是爬蟲。
在本文中,你將了解如何通過Python輕松的完成數據爬蟲任務。

什么是爬蟲?
廣義上講,數據爬蟲是指以編程方式提取網站數據并根據其需求進行結構化的過程。
許多公司正在使用數據爬蟲來收集外部數據并支持其業務運營:這是當前在多個領域中普遍的做法。
我需要了解什么才能學習python中的數據抓取?
很簡單,但是需要首先具備一些Python和html知識。
另外,需要了解兩個非常有效的框架,例如,Scrapy或Selenium。
詳細介紹
接下來,讓我們學習如何將網站變成結構化數據!
為此,首先需要安裝以下庫:
- requests:模擬HTTP請求(例如GET和POST), 我們將主要使用它來訪問任何給定網站的源代碼
- BeautifulSoup:輕松解析HTML和XML數據
- lxml:提高XML文件的解析速度
- pandas:將數據構造為Dataframes并以您選擇的格式(JSON,Excel,CSV等)導出
如果你使用的是Anaconda,配置起來會非常簡單,這些軟件包都已預先安裝。
如果不是使用Anaconda,需要通過如下命令安裝工具包:
pip install requests
pip install beautifulsoup4
pip install lxml
pip install pandas
我們要抓取哪些網站和數據?
這是爬蟲過程中首先需要回答的問題。
本文就以爬取Premium Beauty News為例進行演示。
該以優質美容新聞為主,它發布了美容市場的最新趨勢。
查看首頁,你會看到我們要抓取的文章以網格形式組織。

多頁面的組織如下:

當然,我們僅要提取出現在這些頁面上的每篇文章的標題,我們將深入每個帖子并獲取我們需要的詳細內容,例如:
- 標題
- 日期
- 摘要
- 全文

編碼實踐
前面,已經介紹了基本的內容以及需要用到的工具包。
接下來,就是正式編碼實踐的步驟。
首先,需要導入基礎工具包:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm_notebook
我通常定義一個函數來解析給定URL的每個頁面的內容。
該函數將被多次調用,這里將他命名為parse_url:
def parse_url(url):
response = requests.get(url)
content = response.content
parsed_response = BeautifulSoup(content, "lxml")
return parsed_response
提取每個帖子數據和元數據
首先,我將定義一個函數,該函數提取給定URL的每個帖子的數據(標題,日期,摘要等)。
然后,我們將遍歷所有頁面的for循環內調用此函數。
要構建我們的爬蟲工具,我們首先必須了解頁面的基本HTML邏輯和結構。以提取帖子的標題為例,講解一下。
通過在Chrome檢查器中檢查此元素:

我們注意到標題出現在 article-title類的h1內。
使用BeautifulSoup提取頁面內容后,可以使用find方法提取標題。
title = soup_post.find("h1", {"class": "article-title"}).text
接下來,看一下日期:

該日期顯示在一個span內,該范圍本身顯示在row sub-header類的標題內。
使用BeautifulSoup將其轉換為代碼非常容易:
datetime = soup_post.find("header", {"class": "row sub- header"}).find("span")["datetime"]
下一步就是摘要:

它在article-intro的h2標簽下:
abstract = soup_post.find("h2", {"class": "article-intro"}).text
現在,需要爬取帖子的全文內容。如果已經理解了前面的內容,那么這部分會非常容易。
該內容在article-text類的div內的多個段落(p標簽)中。

BeautifulSoup可以通過以下一種方式提取完整的文本。而不是遍歷每個每個p標簽、提取文本、然后將所有文本連接在一起。
content = soup_post.find("div", {"class": "article-text"}).text
下面,讓我們把它們放在同一個函數內看一下:
def extract_post_data(post_url):
soup_post = parse_url(post_url)
title = soup_post.find("h1", {"class": "article-title"}).text
datetime = soup_post.find("header", {"class": "row sub-header"}).find("span")["datetime"]
abstract = soup_post.find("h2", {"class": "article-intro"}).text
content = soup_post.find("div", {"class": "article-text"}).text
data = {
"title": title,
"datetime": datetime,
"abstract": abstract,
"content": content,
"url": post_url
}
return data
提取多個頁面上的帖子URL
如果我們檢查主頁的源代碼,會看到每個頁面文章的標題:

可以看到,每10篇文章出現在1個post-style1 col-md-6標簽下:
下面,提取每個頁面的文章就很容易了:
url = "https://www.premiumbeautynews.com/fr/marches-tendances/"
soup = parse_url(url)
section = soup.find("section", {"class": "content"})
posts = section.findAll("div", {"class": "post-style1 col-md-6"})
然后,對于每個單獨的帖子,我們可以提取URL,該URL出現在h4標簽內部。
我們將使用此URL調用我們先前定義的函數extract_post_data。
uri = post.find("h4").find("a")["href"]
分頁
在給定頁面上提取帖子后,需要轉到下一頁并重復相同的操作。
如果查看分頁,需要點擊“下一個”按鈕:

到達最后一頁后,此按鈕變為無效。
換句話說,當下一個按鈕處于有效狀態時,就需要執行爬蟲操作,移至下一頁并重復該操作。當按鈕變為無效狀態時,該過程應停止。
總結此邏輯,這將轉換為以下代碼:
next_button = ""
posts_data = []
count = 1
base_url = 'https://www.premiumbeautynews.com/'
while next_button isnotNone:
print(f"page number : {count}")
soup = parse_url(url)
section = soup.find("section", {"class": "content"})
posts = section.findAll("div", {"class": "post-style1 col-md-6"})
for post in tqdm_notebook(posts, leave=False):
uri = post.find("h4").find("a")["href"]
post_url = base_url + uri
data = extract_post_data(post_url)
posts_data.Append(data)
next_button = soup.find("p", {"class": "pagination"}).find("span", {"class": "next"})
if next_button isnotNone:
url = base_url + next_button.find("a")["href"]
count += 1
此循環完成后,將所有數據保存在posts_data中,可以將其轉換為漂亮的DataFrames并導出為CSV或Excel文件。
df = pd.DataFrame(posts_data)
df.head()
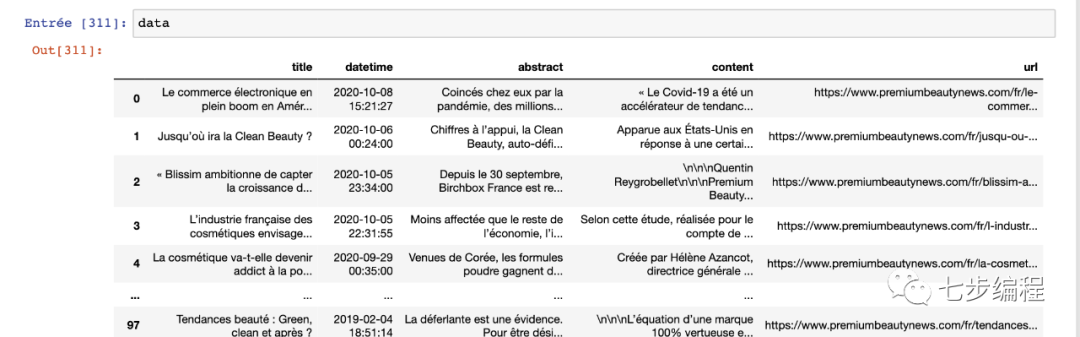
到這里,就把一個非結構化的網頁轉化成結構化的數據了!





