
最近定位了在一個多線程服務器程序(OceanBase MergeServer)中,一個線程非法篡改另一個線程的內存而導致程序core掉的問題。定位這個問題歷經曲折,嘗試了各種內存調試的辦法。往往感覺就要柳暗花明了,卻發現又進入了另一個死胡同。最后,使用強大的mprotect+backtrace+libsigsegv等工具成功定位了問題。整個定位過程遇到的問題和解決辦法對于多線程內存越界問題都很典型,簡單總結一下和大家分享。
現象
core是在系統集成測試過程中發現的。服務器程序MergeServer有一個50個工作線程組成的線程池,當使用8個線程的測試程序通過MergeServer讀取數據時,后者偶爾會core掉。用gdb查看core文件,發現core的原因是一個指針的地址非法,當進程訪問指針指向的地址時引起了段錯誤(segment fault)。見下圖。

發生越界的指針ptr_位于一個叫做cname_的對象中,而這個對象是一個動態數組field_columns_的第10個元素的成員。如下圖。

復現問題
之后,花了2天的時間,終于找到了重現問題的方法。重現多次,可以觀察到如下一些現象:
1. 隨著客戶端并發數的加大(從8個線程到16個線程),出core的概率加大;
2. 減少服務器端線程池中的線程數(從50個到2個),就不能復現core了。
3. 被篡改的那個指針,總是有一半(高4字節)被改為了0,而另一半看起來似乎是正確的。
4. 請看前一節,重現多次,每次出core,都是因為field_columns_這個動態數組的第10個元素data_[9]的cname_成員的ptr_成員被篡改。這是一個不好解釋的奇怪現象。
5. 在代碼中插入檢查點,從field_columns_中內容最初產生到讀取導致越界的這段代碼序列中“埋點”,既使用二分查找法定位篡改cname_的代碼位置。結果發現,程序有時core到檢查點前,有時又core到檢查點后。
綜合以上現象,初步判斷這是一個多線程程序中內存越界的問題。
使用glibc的MALLOC_CHECK_
因為是一個內存問題,考慮使用一些內存調試工具來定位問題。因為OB內部對于內存塊有自己的緩存,需要去除它的影響。修改OB內存分配器,讓它每次都直接調用c庫的malloc和free等,不做緩存。然后,可以使用glibc內置的內存塊完整性檢查功能。
使用這一特性,程序無需重新編譯,只需要在運行的時候設置環境變量MALLOC_CHECK_(注意結尾的下劃線)。每當在程序運行過程free內存給glibc時,glibc會檢查其隱藏的元數據的完整性,如果發現錯誤就會立即abort。用類似下面的命令行啟動server程序:
export MALLOC_CHECK_=2
bin/mergeserver -z 45447 -r 10.232.36.183:45401 -p45441
使用MALLOC_CHECK_以后,程序core到了不同的位置,是在調用free時,glibc檢查內存塊前面的校驗頭錯誤而abort掉了。如下圖。

但這個core能帶給我們想信息也很少。我們只是找到了另外一種稍高效地重現問題的方法而已。或許最初看到的core的現象是延后顯現而已,其實“更早”的時刻內存就被破壞掉了。
valgrind
glibc提供的MALLOC_CHECK_功能太簡單了,有沒有更高級點的工具不光能夠報告錯誤,還能分析出問題原因來?我們自然想到了大名鼎鼎的valgrind。用valgrind來檢查內存問題,程序也不需要重新編譯,只需要使用valgrind來啟動:
nohup valgrind --error-limit=no --suppressions=suppress bin/mergeserver -z 45447 -r 10.232.36.183:45401 -p45441 >nohup.out &
默認情況下,當valgrind發現了1000中不同的錯誤,或者總數超過1000萬次錯誤后,會停止報告錯誤。加了--error-limit=no以后可以禁止這一特性。--suppressions用來屏蔽掉一些不關心的誤報的問題。經過一翻折騰,用valgrind復現不了core的問題。valgrind報出的錯誤也都是一些與問題無關的誤報。大概是因為valgrind運行程序大約會使程序性能慢10倍以上,這會影響多線程程序運行時的時序,導致core不能復現。此路不通。
需要C/C++ linux高級服務器架構師學習資料后臺私信“資料”(包括C/C++,Linux,golang技術,Nginx,ZeroMQ,MySQL,redis,fastdfs,MongoDB,ZK,流媒體,CDN,P2P,K8S,Docker,TCP/IP,協程,DPDK,ffmpeg等)
magic number
既然MALLOC_CHECK_可以檢測到程序的內存問題,我們其實想知道的是誰(哪段代碼)越了界。此時,我們想到了使用magic number填充來標示數據結構的方法。如果我們在被越界的內存中看到了某個magic number,就知道是哪段代碼的問題了。
首先,修改對于malloc的封裝函數,把返回給用戶的內存塊填充為特殊的值(這里為0xEF),并且在開始和結束部分各多申請24字節,也填充為特殊值(起始0xBA,結尾0xDC)。另外,我們把預留內存塊頭部的第二個8字節用來存儲當前線程的ID,這樣一旦觀察到被越界,我們可以據此判定是哪個線程越的界。代碼示例如下。
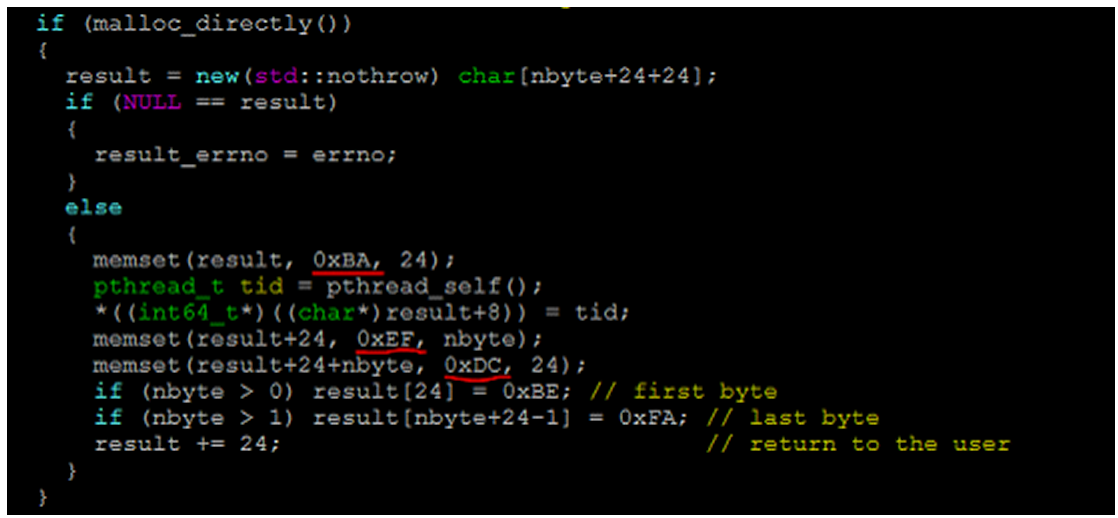
然后,在用戶程序通過我們的free入口釋放內存時,對我們填充到邊界的magic number進行檢查。同時調用mprobe強制glibc對內存塊進行完整性檢查。

最后,給程序中所有被懷疑的關鍵數據結構加上magic number,以便在調試器中檢查內存時能識別出來。例如

好了,都加好了。用MALLOC_CHECK_的方式重新運行。程序如我們所愿又core掉了,檢查被越界位置的內存:

如上圖,紅色部分是我們自己填充的越界檢查頭部,可以看到它沒有被破壞。其中第二行存儲的線程號經過確認確實等于我們當前線程的線程號。
藍色部分為前一個動態內存分配的結尾,也是完整的(24個字節0xdc)。0x44afb60和0x44afb68兩行所示的內存為glibc malloc存儲自身元數據的地方,程序core掉的原因是它檢查這兩行內容的完整性時發現了錯誤。由此推斷,被非法篡改的內容小于16個字節。仔細觀察這16字節的內容,我們沒有看到熟悉的magic number,也就無法推知有bug的代碼是哪塊。這和我們最初發現的core的現象相互印證,很可能被非法修改的內容僅為4個字節(int32_t大小)。
另外,雖然我們加寬了檢查邊界,程序還是會core到glibc malloc的元數據處,而不是我們添加的邊界里。而且,我們總可以觀察到前一塊內存(圖中藍色所示)的結尾時完整的,沒被破壞。這說明,這不是簡單的內存訪問超出邊界導致的越界。我們可以大膽的做一下猜測:要么是一塊已經釋放的內存被非法重用了;要么這是通過野指針“空投”過來的一次內存修改。
如果我們的猜測是正確的,那么我們用這種添加內存邊界的方式檢查內存問題的方法幾乎必然是無效的。
打怪利器electric-fence
至此,我們知道某個時間段內某個變量的內存被其他線程非法修改了,但是卻無法定位到是哪個線程哪段代碼。這就好比你明明知道未來某個時間段在某個地點會發生兇案,卻沒辦法看到兇手。無比郁悶。
有沒有辦法能檢測到一個內存地址被非法寫入呢?有。又一個大名鼎鼎的內存調試庫electric-fence(簡稱efence)就華麗登場了。
使用MALLOC_CHECK_或者magic number的方式檢測的最大問題是,這種檢查是“事后”的。在多線程的復雜環境中,如果不能發生破壞的第一時間檢查現場,往往已經不能發現罪魁禍首的蛛絲馬跡了。
electric-fence利用底層硬件(CPU提供的虛擬內存管理)提供的機制,對內存區域進行保護。實際上它就是使用了下一節我們要自己編碼使用的mprotect系統調用。當被保護的內存被修改時,程序會立即core掉,通過檢查core文件的backtrace,就容易定位到問題代碼。
這個庫的版本有點混亂,容易弄錯。搜索和下載這個庫時,我才發現,electric-fence的作者也是大名鼎鼎的busybox的作者,牛人一枚。但是,這個版本在linux上編譯連接到我的程序的時候會報WARNING,而且后面執行的時候也會出錯。后來,找到了debian提供的一個更高版本的庫,估計是社區針對linux做了改進。
使用efence需要重新編譯程序。efence編譯后提供了一個靜態庫libefence.a,它包含了能夠替代glibc的malloc, free等庫函數的一組實現。編譯時需要一些技巧。首先,要把-lefence放到編譯命令行其他庫之前;其次,用-umalloc強制g++從libefence中查找malloc等本來在glibc中包含的庫函數:
g++ -umalloc –lefence …
用strings來檢查產生的程序是否真的使用了efence:

和很多工具類似,efence也通過設置環境變量來修改它運行時的行為。通常,efence在每個內存塊的結尾放置一個不可訪問的頁,當程序越界訪問內存塊后面的內存時,就會被檢測到。如果設置EF_PROTECT_BELOW=1,則是在內存塊前插入一個不可訪問的頁。通常情況下,efence只檢測被分配出去的內存塊,一個塊被分配出去后free以后會緩存下來,直到一下次分配出去才會再次被檢測。而如果設置了EF_PROTECT_FREE=1,所有被free的內存都不會被再次分配出去,efence會檢測這些被釋放的內存是否被非法使用(這正是我們目前懷疑的地方)。但因為不重用內存,內存可能會膨脹地很厲害。
我使用上面2個標記的4種組合運行我們的程序,遺憾的是,問題無法復現,efence沒有報錯。另外,當EF_PROTECT_FREE=1時,運行一段時間后,MergeServer的虛擬內存很快膨脹到140多G,導致無法繼續測試下去。又進入了一個死胡同。
終極神器mprotect + backtrace + libsigsegv
electric-fence的神奇能力實際上是使用系統調用mprotect實現的。mprotect的原型很簡單,
int mprotect(const void *addr, size_t len, int prot);
mprotect可以使得[addr,addr+len-1]這段內存變成不可讀寫,只讀,可讀寫等模式,如果發生了非法訪問,程序會收到段錯誤信號SIGSEGV。
但mprotect有一個很強的限制,要求addr是頁對齊的,否則系統調用返回錯誤EINVAL。這個限制和操作系統內核的頁管理機制相關。
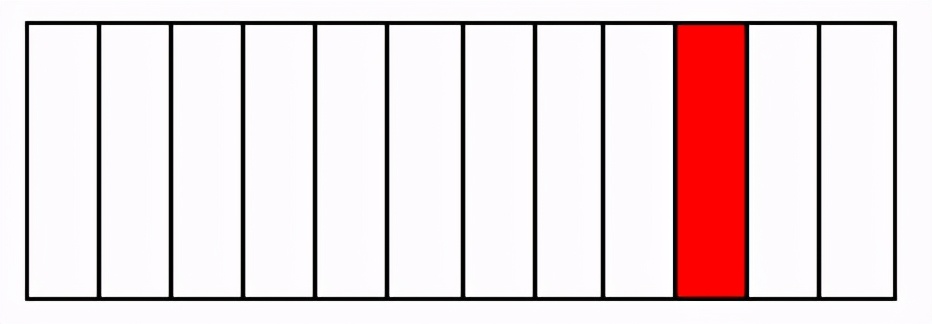
如圖,我們已經知道這個動態數組的第10個元素會被非法越界修改。review了代碼,發現從這個數組內容初始化完畢以后,到使用這個數組內容這段時間,不應該再有修改操作。那么,我們就可以在數組內容被初始化之后,立即調用mprotect對其進行只讀保護。
嘗試一
因為mprotect要求輸入的內存地址頁對齊,所以我修改了動態數組的實現,每次申請內存塊的時候多分配一個頁大小,然后取頁對齊的地址為第一個元素的起始位置。

如上圖,淺藍色部分為為了對齊內存地址而做的padding。代碼見下

動態數組申請的最小內存塊的大小為64KB。這里,動態數組中每個元素的大小為80字節,我們只需要從第1個元素開始保護一個頁的大小即可:

既然這個保護區域是程序中自動插入的,需要在內存釋放給系統前回復它為可讀寫,否則必然會因mprotect產生段錯誤。

好了,編譯、重啟、運行重現腳本。悲劇了。程序運行了很久都不再出core了,無法復現問題。我們在分配動態數組內存時,為了對齊在內存塊前添加的padding導致程序運行時的內存分布和原來產生core的運行環境不同了。這可能是無法復現的原因。要想復現,我們不能破壞原來的內存分配方式。
嘗試二
不改變動態數組的內存塊申請方式,又要滿足mprotect保護的地址必須頁對齊的要求,怎么做呢?我們換一個思路,從第10個元素向前,找到包含它且離它最近的頁對齊的內存地址。如下圖

但這樣會造成一個問題。圖中淺藍色部分本不是這個動態數組對象所擁有的內存,它可能被其他任何線程的任何數據結構在使用。我們使用這種方式保護紅色區域,會有很多無關的落入藍色區域的修改操作導致mprotect產生段錯誤。
實驗了一下,果然,程序跑起來不久就在其他無關的代碼處產生了段錯誤。這種保護方式的代碼如下:

成功
在上一節的保護方式下,我們因為保護了無關內存區域,會導致程序過早產生SIGSEGV而退出。我們能否截獲信號,不讓程序在非法訪問mprotect保護區域后仍然能繼續執行呢?當然。我們可以定制一個SIGSEGV段錯誤信號的處理函數。在這個處理函數中,如果能打印段錯誤時候的當前調用棧,就可以找到罪魁禍首了。

代碼如上圖。注意,處理SIGSEGV的handler函數有一些小技巧(坑很多):
1. SIGSEGV一般是內核處理的(page fault)。使用庫libsigsegv可以簡化用戶空間撰寫處理函數的難度。
2. 處理函數中,不能調用任何可能再分配內存的函數,否則會引起double fault。例如,在這段處理函數中,使用open系統調用打開文件,不能使用fopen;buff是從棧上分配的,不能從heap上申請;不能使用backtrace_symbols,它會向glibc動態申請內存,而要使用安全的backtrace_symbols_fd把backtrace直接寫入文件。
3. 最重要的,在SIGSEGV的處理函數中,我們需要恢復引起段錯誤的內存塊為可讀寫的。這樣,當處理函數返回被中斷的代碼繼續執行時,才不能再次引起段錯誤。重新編譯代碼,運行重現腳本。查看記錄了backtrace的文件sigsegv.bt,我們看到了熟悉的被篡改的指針地址(一半為0):

這個段錯誤會最終導致程序core掉,因為這個SIGSEGV信號不是由我們使用mprotect的保護而產生的。查看core文件,可以查到被越界的內存(即ptr_)的地址。從sigsegv.bt文件中查找,果然找到了那一次非法訪問:

使用addr2line檢查上面這個調用棧中的地址,我們終于找到了它。又經過一番代碼review和驗證,才總算確定了錯誤原因。有一個動態new出來的對象的指針在兩個有關聯的線程中共享,在某種極端情況下,其中一個delete了對象之后,另一個線程又修改了這個對象。
小結
小結一下,遇到棘手的內存越界問題,可以使用下面順序逐個嘗試:
1. code review分析代碼。
2. valgrind用起來最簡單,幾乎是傻瓜式的。能用盡量用。
3. glibc的MALLOC_CHECK_使用起來和很簡單,不需要重現編譯代碼。可以用來發現問題,但是其本身無法定位問題。和magic number結合起來,可以用來定位一類內存越界的問題。
4. 和electric-fence齊名的還有一個內存調試庫叫做dmalloc。雖然在本次解決問題的過程中沒有用到,這個庫對于檢測內存泄露等其他問題很有用。推薦大家學習一下,放到自己的工具庫中。
5. electric-fence是定位一類“野指針”訪問問題的利器,強烈推薦使用。
6. 如果上述所有工具都幫不了你,那么只好在熟悉代碼邏輯的基礎上,使用終極武器了。
7. code review。通過嘗試代碼庫中不同版本編譯出來的程序復現bug,用二分法定位引入bug的最早的一次代碼提交。





