
DataPipeline Head of AI 王睿在51CTO大咖來了公開課上作了題為《業務異常實時自動化檢測 — 基于人工智能的系統實戰》的分享,本文根據分享內容整理而成。

圖片來自 Pexels
王睿,之前在 Facebook/Instagram 擔任 AI 技術負責人,現在 DataPipeline 任 Head of AI,負責研發企業級業務異常檢測產品,旨在幫助企業一站式解決業務自動化監控和異常檢測問題。
分享主要從以下四方面跟大家分享構建該產品的思路和實戰:
- 為什么需要人工智能業務異常檢測系統
- 搭建該系統的挑戰和設計理念
- DataPipeline 的算法實現思路
- DataPipeline 的系統架構
為什么需要人工智能業務異常檢測系統
企業會因為業務異常無法得到及時解決而遭受較大的損失,比如某知名互聯網企業,將原價為 50 元的優惠券以 18 元賣出,導致用戶在短時間內大量瘋搶,損失慘重。
同樣,在金融、零售、電商領域因為 IT 系統的 Bug 或人工原因導致的業務異常也給企業造成了不可估量的經濟損失。
然而,在業務異常出現時,企業往往在幾天甚至幾個星期之后才會發現。以某公司為例,其主營業務為線上借貸,有次放款率突然增加,此時距離出現問題已經過去十幾個小時。
后果是將錢款借給了許多不具備借貸資質的人,導致回款率和營收大幅下降。

為此,隨著企業業務的持續高速增長以及信息化的全面普及,業務人員需要對業務變化有一個全面實時地掌控。
這時,IT 運維人員會關心服務器和網絡的運行;產品負責人會關心用戶訪問,點擊率和用戶體驗等;業務負責人則關心業務的核心 KPI,如銷售額。
這些指標猶如一個人的心跳、血壓、體溫,反映企業業務的健康狀況。
如何能快速準確地從業務指標中識別異常,發現問題根因,并及時解決對企業而言就顯得尤為重要。
目前針對這塊,不同企業采取的方法各異。傳統的業務監控方法往往是手工生成報表每天查看,對于比較重要且實時性要求較高的指標,會人工設定閾值,當指標跨過閾值時報警。
對于已知周期性的指標一般會用類似同比環比的方法。隨著企業業務量和業務種類的不斷提升,人工的監控也隨之增多。
而這種基于人工的方法則會顯示出幾大不足:
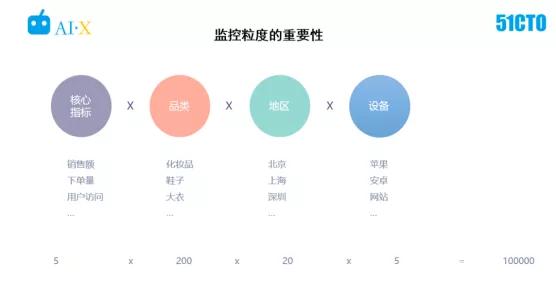
①大量業務指標沒有被實時監控。以電商為例,若只監控總銷售額,采用人工方法很容易實現。
但是,一旦某些地區或品類的銷售額出現異常,只看總銷售額指標則很難發現問題。
例如某零售企業,其酸奶的銷售額在某地區較之前有所下降,原因是酸奶的庫存出現了周轉問題。
由于一直售賣過期酸奶,導致接到大量用戶舉報。針對該情況,若只監控總銷售額很難發現問題,這時需要監控品類和地區兩個維度更細粒度的指標。
而監控多個維度的指標,指標監控的數量會成倍增長,顯然是人工無法勝任的。
②告警洪流。當業務出現問題時,往往報警的接收人員會收到大量告警,使得他們被告警洪流淹沒,很難精準定位問題根因。
除了告警的準確率低以外,還由于業務指標之間具有很強的相關性,主要體現在兩個方面:
首先是指標之間的鏈路關系。比如在電商零售領域,當服務器錯誤增高時導致用戶訪問下降,從而導致下游的訂單減少。
另外是指標的多維度特性,例如當訂單下降時,往往多個產品線,多個地區訂單量同時下降。
因此當業務出現問題時,往往是多個相關的指標一起告警,形成告警洪流。
③誤報漏報。作為業務負責人,既不想在業務出現問題的最后一刻才知道,也不想在凌晨三點被一個假警報叫醒。
而多次的誤報會導致“狼來了”的效應,當真正的問題出現時,告警卻往往容易被接收人員忽略掉。
④人工維護成本。隨著業務的不斷變化,大量的告警閾值和規則需要人工調整,而這顯然跟不上業務的變化速度和監控指標不斷增多的節奏。
因此我們需要一套自動化的智能業務監控和異常檢測系統,通過對指標變化規律的學習,自動掌握指標數據正常和異常的表現模式,從而全面,實時地監控企業業務不同層面,不同維度的各項指標。
這就是為什么我們需要搭建基于人工智能算法的業務異常檢測系統的原因。
搭建該系統的挑戰和設計理念
人工智能算法在異常檢測領域已經被研究了幾十年,但是搭建這樣的系統卻并非易事。主要的挑戰有以下幾點:
第一,對于異常的定義較為模糊且各種數據指標的表現形式千差萬別。
比如 IT 的 CPU 異常與銷售額異常不同,因此試圖用一種通用的算法檢測不同類型指標的異常往往準確率很低。
因為某一類數據的異常表現形式放在另一類數據指標中可能就不會被認為是異常。另外,在未來發生的異常很多時候是過去并未見過的。
這直接導致了第二個難點,即很難獲取標注數據。
不僅很難標注一個數據的變化是否是異常,且異常出現的頻率較低,很難像傳統機器學習問題那樣獲得很多正負樣本。
第三,對該算法和系統的實時性和可擴展性要求很高。
如果不能實時監控大量指標,發現異常并告警,這個系統將失去其意義。
為解決上述痛點,同時考慮到種種挑戰,DataPipeline 在設計該系統前確定了幾點設計原則:
①無(半)監督機器學習算法為主
雖然目標是將數據分類為正常或異常,但由于異常的定義模糊,很難獲取標注數據,我們主要采取無監督的機器學習算法。
當然,對于給用戶發送的告警,系統需要可以收集用戶的反饋,然后用在提升算法的準確性上。綜合來講,這是一種半監督學習的方法。
②算法跟業務解耦
人工智能算法的優勢在于解放人工,做到自動化,因此算法需要跟業務盡可能解耦。
算法可以通過對于指標歷史數據本身模式(如周期性)的學習來建模。而不同業務指標數據的表現形式各異,總體上時序數據的表現類型是有限的,因此我們需要算法具備根據不同表現形式選擇不同模型的能力。
③異常相關性學習和根因分析
上面講到的一個很大的痛點是告警洪流。當業務出現問題時,業務人員往往被淹沒在大量告警中,很難快速準確地定位問題。
因此我們需要學習監控指標之間的相關性,當業務出現問題時給用戶一個匯總的告警,這樣不僅能避免告警洪流,還能讓用戶一目了然地看到反映問題的相關指標,從而更快找到問題根因。
從產品角度而言,這也是一個成熟的業務異常檢測系統中很重要的組成部分,即根因分析。
我們不僅希望及時地反應業務問題,也希望能縮小發現問題到解決問題的時間和成本。
④算法的擴展性和實時性
算法和整個系統需要做到對億級數據指標的秒級實時響應。因此我們主要考慮應用輕量級并且支持線上學習(Online Learning)的算法模型。
近些年深度學習在異常檢測領域的應用逐漸成熟,其相較于傳統的統計模型算法具有更強的泛化能力。
但這些算法的訓練成本較大,因此需要對實時性要求更高的指標系統進行取舍。
DataPipeline 的算法實現思路
基于以上設計原則,DataPipeline 提出了解決問題的幾個步驟:
①接入數據
首先利用 DataPipeline 自身的數據集成能力,從不同數據源中接入實時的數據流或批式的數據集并進行預處理,形成多個指標的時序數據。
②正常表現的建模
進而對每個單一的指標時序數據學習其正常表現模式,擬合模型,并自動生成置信區間。
如下圖,深藍色部分為數據本身,淺藍色部分為自動生成的置信區間,紅色部分為異常。

③異常的檢測和過濾
對于新的數據點,一旦其跨過置信區間系統便認定為異常。接著對于每個識別出的異常進行打分和過濾。
④關聯多個異常并自動報警
對檢測出的多個異常,算法自動進行相關性學習,將其關聯起來。最后生成一個匯總的告警,發送給用戶。
下面重點解釋對單一數據的正常表現建模,異常檢測和關聯多個指標異常的具體技術實現。
單一數據的正常表現建模
在過去數十年里,許多不同類型的算法被研究和開發來嘗試解決這一問題。
其中有較為傳統的基于統計模型的算法,也有許多基于時序數據的分析方法,而近年來大熱的深度學習模型也被證明在時序數據預測和異常檢測上有較高的準確性。
這些算法一般遵循這樣一個步驟:先對歷史數據進行建模,學習數據正常表現的規律。
對新來的數據點,根據數據點偏離正常表現模型的程度來判定是否為異常。

比如最簡單的算法模型是高斯分布,假設該指標數據符合高斯分布,就可以通過歷史數據點估計出高斯分布的 mea n和期望(均數)μ 和標準差 σ,進而對新的數據點判定。
如果偏離期望多于三個標準差則該數據點不能被模型解釋的概率為 99.7%,我們就可以判定其為異常。
然而實際情況是,大部分數據都無法簡單地表現為高斯分布。因此,首先我們需要根據數據本身來自動選擇最適合的算法模型。
這也是很多開源的異常檢測算法直接被拿來使用往往得不到滿意效果的一個原因。
因為他們一般假設數據的底層表現是平穩的(Stationary),并且數據是規則取樣的(Regular Sampling),若使用不適合的算法模型對數據建模會得到非常不好的效果,甚至完全無法使用。
因此 DataPipeline 開發了一個算法,可以自動根據數據的表現形式選擇最合適的算法進行擬合。最常用的算法可以分為基于統計模型的算法和深度學習的算法。
統計模型算法:除了上面提到的高斯分布,比較常用的模型有基于指數平滑(Exponential Smoothing)的模型,實際是對過去的數據進行平均來預測未來的數據,只是給時間上更靠近當下的數據點更大的權重。
比較經典的有 Holt-Winters,ARIMA 等,這些還可以將周期性的規律考慮進去。
深度學習算法:對于不符合規則取樣和不表現為 Staionary 的數據,深度學習算法的效果更好。
LSTM(Long Short-Term Memory)是最常用的算法,而當下許多最新的算法都是基于 LSTM 上的變種。
然而深度學習算法很難做到實時訓練,即模型隨新的數據點實時更新,而且當監控數據量大的時候非常耗費 CPU。
算法自動選擇出最合適的模型后,系統便可根據歷史數據擬合模型,估計出模型參數,進而針對每個數據點給出預測。
對于實際數據點和預測數據點的差異(error)我們可以用高斯分布來模擬,利用高斯模型計算出一個置信區間,當新數據的 error 偏離置信區間過大時將其判斷為異常。
周期性學習
許多指標數據都表現出明顯的周期性,而周期性學習對異常檢測的準確性至關重要。
最常見的自動學習周期性方法是自相關學習(Autocorrelation)。簡言之,該算法是將數據向過去平移一個時間差(Lag),然后計算平移后的數據和原來數據的統計相關性。
如果某一個 Lag 平移后的數據和原數據相關性很大,則認為該 Lag 就是數據的周期性。此算法的主要問題是計算量較大,因為要對多個 Lag 進行計算。
鑒于上面提到的實時性和可擴展要求,DataPipeline 對該算法用 Subsampling 的方法進行優化,降低了計算復雜度。
相關性學習
之前提到為解決告警洪流問題,我們需要一個算法可以自動化計算指標間的相關性,在多個異常同時出現時,可以將反映同個業務問題的異常關聯在一起,給用戶一個匯總的告警。
針對這類問題,一般傳統的方法是采取多變量分析(Multivariate Analysis),即將所有時序數據當成互相有關聯的多變量一起建模,然后在整體層面檢測異常。
該方法的主要問題是很難規模化,且當出現異常時檢測結果的解釋性較差。

因此,在 DataPipeline,我們采用單變量分析對每個指標進行異常檢測,然后利用大規模聚類算法將相關度較高的指標進行聚類(如上圖)。
這樣每個指標的機器學習和相關性學習兩部分可以各自規模化,使得整個系統計算效率更高。
而聚類算法通過幾類特征來進行計算:
異常表現的相似度:簡言之,如果兩個指標多次、同時出現異常,則認為兩者更相關。
我們可以生成一個異常表現的特征向量,若在某個時間點該指標表現正常便設置為 0,若表現異常則設置為異常的打分(算法根據異常的嚴重程度自動打分)。
統計模型的相似度:即指標的數值是否有相似的模式。其中計算兩個時序數據數值相似度最常見的算法是 Pearson Correlation Coefficient。
元數據相似度和人工反饋:DataPipeline 還根據元數據的拓撲關系來判斷相關性。
比如同一個指標的多個維度生成的多個子指標會被認為更相關。此外,用戶也可自己輸入一些信息告訴系統哪些指標更相關。
DataPipeline 的系統架構
若構建一套企業級業務監控和異常檢測系統應該具備哪些組成部分?下面為 DataPipeline 的一些思路。

①產品功能組成
從產品功能角度而言,該系統可以接入企業的各種業務系統(左邊),包括核心業務系統和各種已有系統,諸如數據分析,監控系統等。
挑戰是如何將多源異構的數據以一致的方式接入,且同時可以處理流式和批式數據。
DataPipeline 已有的數據融合產品可以很好地實現這點。如果企業自己搭建,則需要根據具體情況確定實現方式。
另外,針對中間的系統內核,我們將其設計成了一個跟業務完全解耦的黑盒。
右邊則是用戶交互 UI,包括兩部分:
- 告警系統,可根據企業的報警需要接到企業交流 App 如釘釘、郵件,電話等。
- 監控看板,可以看到監控的指標數據,搜索不同指標和多維度展示。
另外,還可看到指標異常的匯總展示,根因展示等。從看板上用戶可以根據展示出的異常進行反饋,表明這是正確的異常還是誤報,另外還可調整指標異常檢測的敏感度。這些反饋和調整會返回到系統中。
②核心系統架構
核心系統主要分為線上處理和線下模型訓練兩部分。線上部分處理實時的數據指標最新數據流,從模型存儲數據庫中讀入模型并存于內存中,對數據流中每一個數據指標進行實時的閾值計算、異常檢測和打分。
之后多個數據指標的異常檢測結果會被匯總到一個關聯性處理器,進行異常的關聯,最后將關聯好的異常指標組匯總,生成并觸發告警。
在處理實時指標數據時,處理器會將最新的指標數據和檢測出的異常分別寫入數據庫為線下訓練做準備。
線下部分會定時從數據指標的歷史數據庫中讀取數據并進行線下的模型訓練,這其中便包括上面提到的算法自動選擇,周期性學習等。也會定期利用用戶返回的反饋對模型進行評估,計算出誤報漏報率等。
總結
業務異常的不及時解決會給企業帶來巨大的經濟損失。
相對于傳統的人工生成報表和人工閾值的監控方法,基于人工智能的業務異常檢測系統可以更自動化,更全面地監控業務各項指標并給出準確率更高,更有幫助性的報警和業務洞見。
而搭建這樣一套系統面臨業務數據表現形式多樣,告警過多準確率低下等挑戰。
伴隨著企業級人工智能業務異常檢測系統的出現,企業可以更高效、及時全面的掌控業務,從而實現業務和經濟效益的提升。





