

交叉驗證(也稱為"過采樣"技術)是數據科學項目的基本要素。 它是一種重采樣過程,用于評估機器學習模型并訪問該模型對獨立測試數據集的性能。
在本文中,您可以閱讀以下大約8種不同的交叉驗證技術,各有其優缺點:
1. Leave p out cross-validation
1. Leave one out cross-validation
1. Holdout cross-validation
1. Repeated random subsampling validation
1. k-fold cross-validation
1. Stratified k-fold cross-validation
1. Time Series cross-validation
1. Nested cross-validation
在介紹交叉驗證技術之前,讓我們知道為什么在數據科學項目中應使用交叉驗證。
為什么交叉驗證很重要?
我們經常將數據集隨機分為訓練數據和測試數據,以開發機器學習模型。 訓練數據用于訓練ML模型,同一模型在獨立的測試數據上進行測試以評估模型的性能。
隨著分裂隨機狀態的變化,模型的準確性也會發生變化,因此我們無法為模型獲得固定的準確性。 測試數據應與訓練數據無關,以免發生數據泄漏。 在使用訓練數據開發ML模型的過程中,需要評估模型的性能。 這就是交叉驗證數據的重要性。
數據需要分為:
· 訓練數據:用于模型開發
· 驗證數據:用于驗證相同模型的性能

簡單來說,交叉驗證使我們可以更好地利用我們的數據。
1.Leave p-out cross-validation
LpOCV是一種詳盡的交叉驗證技術,涉及使用p觀測作為驗證數據,而其余數據則用于訓練模型。 以所有方式重復此步驟,以在p個觀察值的驗證集和一個訓練集上切割原始樣本。
已推薦使用p = 2的LpOCV變體(稱為休假配對交叉驗證)作為估計二進制分類器ROC曲線下面積的幾乎無偏的方法。
2. Leave-one-out cross-validation
留一法交叉驗證(LOOCV)是一種詳盡的窮盡驗證技術。 在p = 1的情況下,它是LpOCV的類別。

對于具有n行的數據集,選擇第1行進行驗證,其余(n-1)行用于訓練模型。對于下一個迭代,選擇第2行進行驗證,然后重置來訓練模型。類似地,這個過程重復進行,直到n步或達到所需的操作次數。
以上兩種交叉驗證技術都是詳盡交叉驗證的類型。窮盡性交叉驗證方法是交叉驗證方法,以所有可能的方式學習和測試。他們有相同的優點和缺點討論如下:
優點: 簡單,易于理解和實施
缺點: 該模型可能會導致較低的偏差、所需的計算時間長
3.Holdout cross-validation
保留技術是一種詳盡的交叉驗證方法,該方法根據數據分析將數據集隨機分為訓練數據和測試數據。

在保留交叉驗證的情況下,數據集被隨機分為訓練和驗證數據。 通常,訓練數據的分割不僅僅是測試數據。 訓練數據用于推導模型,而驗證數據用于評估模型的性能。
用于訓練模型的數據越多,模型越好。 對于保留交叉驗證方法,需要從訓練中隔離大量數據。
優點:和以前一樣,簡單,易于理解和實施
缺點: 不適合不平衡數據集、許多數據與訓練模型隔離
4. k-fold cross-validation
在k折交叉驗證中,原始數據集被平均分為k個子部分或折疊。 從k折或組中,對于每次迭代,選擇一組作為驗證數據,其余(k-1)個組選擇為訓練數據。

該過程重復k次,直到將每個組視為驗證并保留為訓練數據為止。

模型的最終精度是通過獲取k模型驗證數據的平均精度來計算的。

LOOCV是k折交叉驗證的變體,其中k = n。
優點:
· 該模型偏差低
· 時間復雜度低
· 整個數據集可用于訓練和驗證
缺點:不適合不平衡數據集。
5. Repeated random subsampling validation
重復的隨機子采樣驗證(也稱為蒙特卡洛交叉驗證)將數據集隨機分為訓練和驗證。 數據集的k倍交叉驗證不太可能分成幾類,而不是成組或成對,而是在這種情況下隨機地成組。
迭代次數不是固定的,而是由分析決定的。 然后將結果平均化。

重復隨機二次抽樣驗證
優點: 訓練和驗證拆分的比例不取決于迭代或分區的數量
缺點: 某些樣本可能無法選擇用于訓練或驗證、不適合不平衡數據集
6. Stratified k-fold cross-validation
對于上面討論的所有交叉驗證技術,它們可能不適用于不平衡的數據集。 分層k折交叉驗證解決了數據集不平衡的問題。
在分層k倍交叉驗證中,數據集被劃分為k個組或折疊,以使驗證數據具有相等數量的目標類標簽實例。 這樣可以確保在驗證或訓練數據中不會出現一個特定的類,尤其是在數據集不平衡時。
分層k折交叉驗證,每折具有相等的目標類實例
最終分數是通過取各折分數的平均值來計算的
優點: 對于不平衡的數據集,效果很好。
缺點: 現在適合時間序列數據集。
7. Time Series cross-validation
數據的順序對于與時間序列相關的問題非常重要。 對于與時間相關的數據集,將數據隨機拆分或k折拆分為訓練和驗證可能不會產生良好的結果。
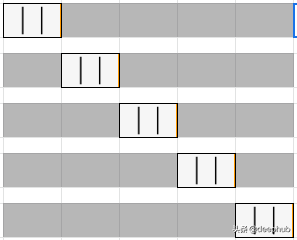
對于時間序列數據集,根據時間將數據分為訓練和驗證,也稱為前向鏈接方法或滾動交叉驗證。 對于特定的迭代,可以將訓練數據的下一個實例視為驗證數據。

如上圖所述,對于第一個迭代,第一個3行被視為訓練數據,下一個實例T4是驗證數據。 選擇訓練和驗證數據的機會將被進一步迭代。
8. Nested cross-validation
在進行k折和分層k折交叉驗證的情況下,我們對訓練和測試數據中的錯誤估計差。 超參數調整是在較早的方法中單獨完成的。 當交叉驗證同時用于調整超參數和泛化誤差估計時,需要嵌套交叉驗證。
嵌套交叉驗證可同時應用于k折和分層k折變體。
結論
交叉驗證用于比較和評估ML模型的性能。 在本文中,我們介紹了8種交叉驗證技術及其優缺點。 k折和分層k折交叉驗證是最常用的技術。 時間序列交叉驗證最適合與時間序列相關的問題。
這些交叉驗證的實現可以在sklearn包中找到。 有興趣的讀者可以閱讀sklearn文檔以獲取更多詳細信息。
https://scikit-learn.org/stable/modules/cross_validation.html
作者:Satyam Kumar
deephub翻譯組





