
歷史經驗告訴我們:好的工具事半功倍,不好的工具處處添堵。
當AI如火如荼的落地各種場景,很多人蠢蠢欲動的想要學習如何入場這個“風口”,給自己的企業也加點buff,也算是添磚加瓦了。而已經“站在風里”的人們,卻仍有不少人躊躇不前——技術是懂,但應用真的難做。究其原因,得到答案無外乎:手慢資源少,復雜投入高。

AI開發,特別是推動AI進入工業大生產階段的深度學習技術,的確復雜,燒錢,耗時間,那該怎么辦呢?這時,你需要工具,一個高效節省開發時間、支持大規模數據訓練、方便你多端多硬件靈活部署的好工具。它要開源開放、成熟完備,并足以支持產業級應用。市面上的深度學習框架已不少,讓我們來選選適合你的那一個。
首先,它要自主自研。經驗告訴我們,國際形式眼花繚亂、千變萬化,一切將底層技術的控制權留給他國的選擇都是悲劇,被“釜底抽薪”卡脖子的事兒絕對是每個人,每個企業的痛中之痛。其次,實踐出真知。歸根結底AI是一種“要在實踐中磨煉,最終服務于實踐”的科學商業的綜合體。因此,就深度學習框架這樣的工具來講,成熟完備、易學易用很重要。而決定了框架“成熟可用”的最基礎要素就是“場景”——框架好用,場景先行。推出框架的公司有場景嗎?場景豐富嗎?場景數據量大嗎?等等這些因素都是選擇框架時需要考慮的事情。

最后要看部署。如果說商業的本質是創造價值,那么AI開發的本質就是間接創造價值。一切AI開發的目的最終要回歸價值,也就是落地執行,即部署。所以找一個方便適配各類硬件的開發工具,在最后一步能省不少事兒。
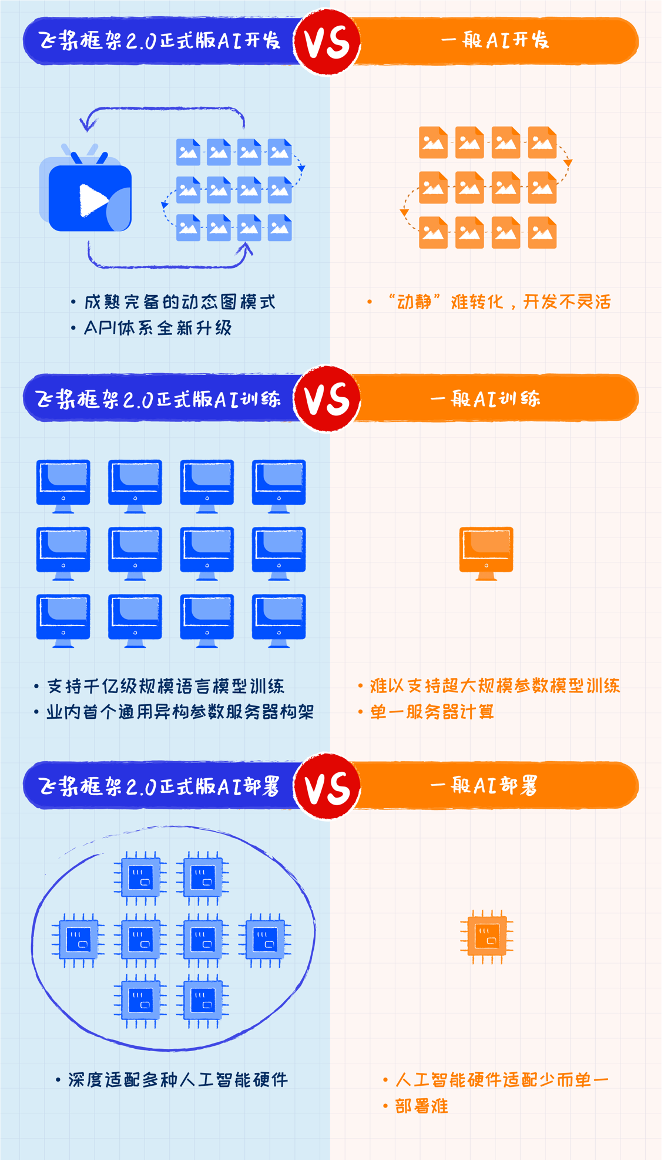
(一圖看懂:用飛槳框架2.0做AI開發是什么體驗)
就拿被稱作國貨之光的飛槳框架來說,首先它滿足自主自研,沒有“包裹外國的框架內核實際做本地漢化”的行為。其次,在開發上,剛剛升級為2.0正式版的飛槳框架可支持用戶使用動態圖完成深度學習相關領域全類別的模型算法開發,這標志著飛槳的動態圖功能已經成熟完備,是不是很強大!
另外,從官方發布的信息來看,目前飛槳官方算法模型庫已達到了270+,涵蓋計算機視覺、自然語言處理、語音、推薦等多個領域,基本上已經覆蓋了所有產業向主流應用需求。
在訓練層面上,飛槳框架2.0在支持萬億規模稀疏參數基礎上,也已實現支持千億規模稠密參數模型訓練。簡單的來說就是它可以實現超大規模數據和模型的訓練,而在針對這種“超大規模”訓練時,一臺機器效率多低呀而且根本難以“裝得下”,那可是千億萬億級數據量和超大模型。所以為了高效高質量地實現如“絲般順滑”的訓練體驗,飛槳可以支持將參數切分到多張 GPU 卡上訓練,從而真正支持不同場景下的千億規模稠密參數模型訓練。
經歷了開發,訓練,在最后的部署環節上,就相當于視頻剪好準備發布。在發布時,橫屏還是豎屏,清晰度有怎樣要求,大小有怎樣的限制等等都跟其載體有關。AI模型部署也一樣,不同硬件的適配要求對模型有著諸多限制。當前包括英特爾、英偉達、ARM等諸多芯片廠商紛紛開展對飛槳的支持。飛槳還跟飛騰、海光、鯤鵬、龍芯、申威等CPU進行深入適配,并結合麒麟、統信、普華操作系統,以及百度昆侖、海光DCU、寒武紀、比特大陸、瑞芯微、高通、英偉達等AI芯片深度融合,與浪潮、中科曙光等服務器廠商合作形成軟硬一體的全棧AI基礎設施。截止目前,飛槳已經適配和正在適配的芯片或IP型號達到29種,處于業界領先地位。
全套加速,整得明明白白。當然每個人也要看自己的開發習慣,但通用情況來看,飛槳兼顧易用和性能的模型生產能力還是非常強大的。對于想轉行AI,進入這個風口之地的開發者來說,搞定語言后直接用飛槳嘗試實操也不失為一個好選擇。
感興趣的朋友可以開始你們的嘗試了!





