
1、引言
在中大型IM系統(tǒng)中,聊天消息的唯一ID生成策略是個很重要的技術(shù)點。不夸張的說,聊天消息ID貫穿了整個聊天生命周期的幾乎每一個算法、邏輯和過程,ID生成策略的好壞有可能直接決定系統(tǒng)在某些技術(shù)點上的設(shè)計難易度。
有中小型IM場景下,消息ID可以簡單處理,反正只要唯一就行,而中大型場景下,因為要考慮到分布式的性能、一致性等,所以要考慮的問題點又是另一回事。
總之就是,IM的消息ID生成這件事,可深可淺,看似簡單但實際可探索的邊界可以很大,這也是為什么即時通訊網(wǎng)為此專門整理了《IM消息ID技術(shù)專題》系列文章的原因。做技術(shù)所謂厚積薄發(fā),了解的越多,你的技術(shù)可操作空間也就越大,希望隨著這個系列文章的閱讀,可以為你在ID生成這一塊的技術(shù)選型帶來更多有益的啟發(fā)。
另外,因為即時通訊網(wǎng)主要關(guān)注的是即時通訊方面的系統(tǒng)開發(fā),但并不意味著這個系統(tǒng)文章只適用于IM或消息推送等實時通信系統(tǒng),它同樣適用于其它需要唯一ID的應(yīng)用中。
本文將要分享的是滴滴開源的分布式ID生成器Tinyid的技術(shù)原理、使用方法等等,希望能進一步為你打開這方面的技術(shù)視野。
學(xué)習(xí)交流:
- 移動端IM開發(fā)入門文章:《新手入門一篇就夠:從零開發(fā)移動端IM》
- 開源IM框架源碼:https://github.com/JackJiang2011/MobileIMSDK
(本文同步發(fā)布于:http://www.52im.net/thread-3129-1-1.html)
2、專題目錄
本文是“IM消息ID技術(shù)專題”系列文章的第6篇,專題總目錄如下:
《IM消息ID技術(shù)專題(一):微信的海量IM聊天消息序列號生成實踐(算法原理篇)》
《IM消息ID技術(shù)專題(二):微信的海量IM聊天消息序列號生成實踐(容災(zāi)方案篇)》
《IM消息ID技術(shù)專題(三):解密融云IM產(chǎn)品的聊天消息ID生成策略》
《IM消息ID技術(shù)專題(四):深度解密美團的分布式ID生成算法》
《IM消息ID技術(shù)專題(五):開源分布式ID生成器UidGenerator的技術(shù)實現(xiàn)》
《IM消息ID技術(shù)專題(六):深度解密滴滴的高性能ID生成器(Tinyid)》(* 本文)
3、什么是Tinyid?
Tinyid是滴滴用JAVA開發(fā)的一款分布式id生成系統(tǒng),基于數(shù)據(jù)庫號段算法實現(xiàn)。
Tinyid是在美團的ID生成算法Leaf的基礎(chǔ)上擴展而來,支持數(shù)據(jù)庫多主節(jié)點模式,它提供了REST API和Java客戶端兩種獲取方式,相對來說使用更方便。不過,和美團的Leaf算法不同的是,Tinyid只支持號段一種模式(并不支持Snowflake模式)。(有關(guān)美團的Leaf算法,可以詳讀《IM消息ID技術(shù)專題(四):深度解密美團的分布式ID生成算法》)
Tinyid目前在滴滴客服部門使用,且通過tinyid-client方式接入,每天生成的是億級別的id。性能上,據(jù)稱單實例能達到1千萬QPS。
它的開源地址是:
主地址:https://github.com/didi/tinyid
備地址:https://github.com/52im/tinyid
PS:滴滴在Tinyid工程頁面寫了一句話,“tinyid,并不是滴滴官方產(chǎn)品,只是滴滴擁有的代碼”,我語文不好,這句該怎么理解呢?
4、Tinyid的主要技術(shù)特性
主要特性總結(jié)一下就是:
1)全局唯一的long型ID:即id極限數(shù)量是2的64次方;
2)趨勢遞增的id:趨勢遞增的意思是,id是遞增但不一定是連續(xù)的(這跟微信的ID生成策略類似);
3)提供 http 和 java-client 方式接入;
4)支持批量獲取ID;
5)支持生成1,3,5,7,9…序列的ID;
6)支持多個db的配置。
適用的場景:只關(guān)心ID是數(shù)字,趨勢遞增的系統(tǒng),可以容忍ID不連續(xù),可以容忍ID的浪費。
不適用場景:像類似于訂單ID的業(yè)務(wù),因生成的ID大部分是連續(xù)的,容易被掃庫、或者推算出訂單量等信息。
另外:微信的聊天消息ID生成算法也是基于號段、趨勢遞增這種邏輯,如果有興趣,可以詳見:《IM消息ID技術(shù)專題(一):微信的海量IM聊天消息序列號生成實踐(算法原理篇)》。
5、Tinyid的技術(shù)優(yōu)勢
性能方面:
1)http方式:訪問性能取決于http server的能力,網(wǎng)絡(luò)傳輸速度;
2)java-client方式:id為本地生成,號段長度(step)越長,qps越大,如果將號段設(shè)置足夠大,則qps可達1000w+。
可用性方面:
1)當(dāng)db不可用時,因為server有緩存,所以還可以使用一段時間;
2)如果配置了多個db,則只要有1個db存活,則服務(wù)可用;
3)使用tiny-client時,只要server有一臺存活,則理論上server全掛,因為client有緩存,也可以繼續(xù)使用一段時間。
6、Tinyid的技術(shù)原理詳解
6.1 ID生成系統(tǒng)的技術(shù)要點
在簡單系統(tǒng)中,我們常常使用db的id自增方式來標(biāo)識和保存數(shù)據(jù),隨著系統(tǒng)的復(fù)雜,數(shù)據(jù)的增多,分庫分表成為了常見的方案,db自增已無法滿足要求。
這時候全局唯一的id生成系統(tǒng)就派上了用場,當(dāng)然這只是id生成其中的一種應(yīng)用場景。
那么,一個成熟的id生成系統(tǒng)應(yīng)該具備哪些能力呢?
1)唯一性:無論怎樣都不能重復(fù),id全局唯一是最基本的要求;
2)高性能:基礎(chǔ)服務(wù)盡可能耗時少,如果能夠本地生成最好;
3)高可用:雖說很難實現(xiàn)100%的可用性,但是也要無限接近于100%的可用性;
4)易用性:能夠拿來即用,接入方便,同時在系統(tǒng)設(shè)計和實現(xiàn)上要盡可能的簡單。
6.2 Tinyid的實現(xiàn)原理
我們先來看一下最常見的id生成方式,db的auto_increment,相信大家都非常熟悉。
我也見過一些同學(xué)在實戰(zhàn)中使用這種方案來獲取一個id,這個方案的優(yōu)點是簡單,缺點是每次只能向db獲取一個id,性能比較差,對db訪問比較頻繁,db的壓力會比較大。
那么,是不是可以對這種方案優(yōu)化一下呢?可否一次向db獲取一批id呢?答案當(dāng)然是可以的。
一批id,我們可以看成是一個id范圍,例如(1000,2000],這個1000到2000也可以稱為一個“號段”,我們一次向db申請一個號段,加載到內(nèi)存中,然后采用自增的方式來生成id,這個號段用完后,再次向db申請一個新的號段,這樣對db的壓力就減輕了很多,同時內(nèi)存中直接生成id,性能則提高了很多。
PS:簡單解釋一下什么是號段模式:
號段模式就是從數(shù)據(jù)庫批量的獲取自增ID,每次從數(shù)據(jù)庫取出一個號段范圍,例如 (1,1000] 代表1000個ID,業(yè)務(wù)服務(wù)將號段在本地生成1~1000的自增ID并加載到內(nèi)存。
那么保存db號段的表該怎設(shè)計呢?我們繼續(xù)往下看。
6.3 DB號段算法描述

如上表,我們很容易想到的是db直接存儲一個范圍(start_id,end_id],當(dāng)這批id使用完畢后,我們做一次update操作,update start_id=2000(end_id), end_id=3000(end_id+1000),update成功了,則說明獲取到了下一個id范圍。仔細想想,實際上start_id并沒有起什么作用,新的號段總是(end_id,end_id+1000]。
所以這里我們更改一下,db設(shè)計應(yīng)該是這樣的:

如上表所示:
1)我們增加了biz_type,這個代表業(yè)務(wù)類型,不同的業(yè)務(wù)的id隔離;
2)max_id則是上面的end_id了,代表當(dāng)前最大的可用id;
3)step代表號段的長度,可以根據(jù)每個業(yè)務(wù)的qps來設(shè)置一個合理的長度;
4)version是一個樂觀鎖,每次更新都加上version,能夠保證并發(fā)更新的正確性 。
那么我們可以通過如下幾個步驟來獲取一個可用的號段:
A、查詢當(dāng)前的max_id信息:select id, biz_type, max_id, step, version from tiny_id_info where biz_type='test';
B、計算新的max_id: new_max_id = max_id + step;
C、更新DB中的max_id:update tiny_id_info set max_id=#{new_max_id} , verison=version+1 where id=#{id} and max_id=#{max_id} and version=#{version};
D、如果更新成功,則可用號段獲取成功,新的可用號段為(max_id, new_max_id];
E、如果更新失敗,則號段可能被其他線程獲取,回到步驟A,進行重試。
6.4 號段生成方案的簡單架構(gòu)
如上述內(nèi)容,我們已經(jīng)完成了號段生成邏輯。
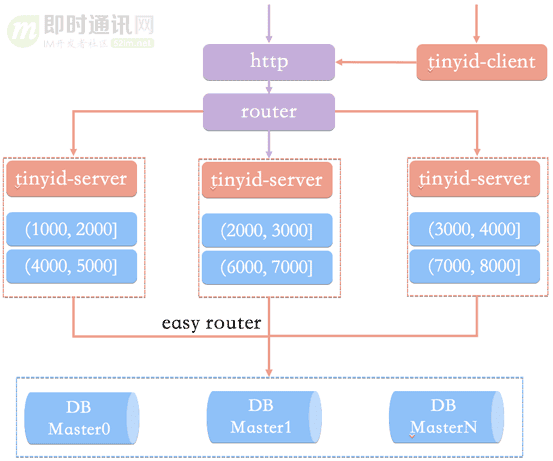
那么我們的id生成服務(wù)架構(gòu)可能是這樣的:

如上圖,id生成系統(tǒng)向外提供http服務(wù),請求經(jīng)過我們的負載均衡router,到達其中一臺tinyid-server,從事先加載好的號段中獲取一個id。
如果號段還沒有加載,或者已經(jīng)用完,則向db再申請一個新的可用號段,多臺server之間因為號段生成算法的原子性,而保證每臺server上的可用號段不重,從而使id生成不重。
可以看到:
1)如果tinyid-server如果重啟了,那么號段就作廢了,會浪費一部分id;
2)同時id也不會連續(xù);
3)每次請求可能會打到不同的機器上,id也不是單調(diào)遞增的,而是趨勢遞增的(不過這對于大部分業(yè)務(wù)都是可接受的)。
6.5 簡單架構(gòu)的問題
到此一個簡單的id生成系統(tǒng)就完成了,那么是否還存在問題呢?
回想一下我們最開始的id生成系統(tǒng)要求:高性能、高可用、簡單易用。
在上面這套架構(gòu)里,至少還存在以下問題:
1)當(dāng)id用完時需要訪問db加載新的號段,db更新也可能存在version沖突,此時id生成耗時明顯增加;
2)db是一個單點,雖然db可以建設(shè)主從等高可用架構(gòu),但始終是一個單點;
3)使用http方式獲取一個id,存在網(wǎng)絡(luò)開銷,性能和可用性都不太好。
6.6 優(yōu)化辦法及最終架構(gòu)
1)雙號段緩存:
對于號段用完需要訪問db,我們很容易想到在號段用到一定程度的時候,就去異步加載下一個號段,保證內(nèi)存中始終有可用號段,則可避免性能波動。
2)增加多db支持:
db只有一個master時,如果db不可用(down掉或者主從延遲比較大),則獲取號段不可用。實際上我們可以支持多個db,比如2個db,A和B,我們獲取號段可以隨機從其中一臺上獲取。那么如果A,B都獲取到了同一號段,我們怎么保證生成的id不重呢?tinyid是這么做的,讓A只生成偶數(shù)id,B只生產(chǎn)奇數(shù)id,對應(yīng)的db設(shè)計增加了兩個字段,如下所示

delta代表id每次的增量,remainder代表余數(shù),例如可以將A,B都delta都設(shè)置2,remainder分別設(shè)置為0,1則,A的號段只生成偶數(shù)號段,B是奇數(shù)號段。通過delta和remainder兩個字段我們可以根據(jù)使用方的需求靈活設(shè)計db個數(shù),同時也可以為使用方提供只生產(chǎn)類似奇數(shù)的id序列。
3)增加tinyid-client:
使用http獲取一個id,存在網(wǎng)絡(luò)開銷,是否可以本地生成id?
為此我們提供了tinyid-client,我們可以向tinyid-server發(fā)送請求來獲取可用號段,之后在本地構(gòu)建雙號段、id生成,如此id生成則變成純本地操作,性能大大提升,因為本地有雙號段緩存,則可以容忍tinyid-server一段時間的down掉,可用性也有了比較大的提升。
4)tinyid最終架構(gòu):
最終我們的架構(gòu)可能是這樣的:
下面是更具體的代碼調(diào)用邏輯:
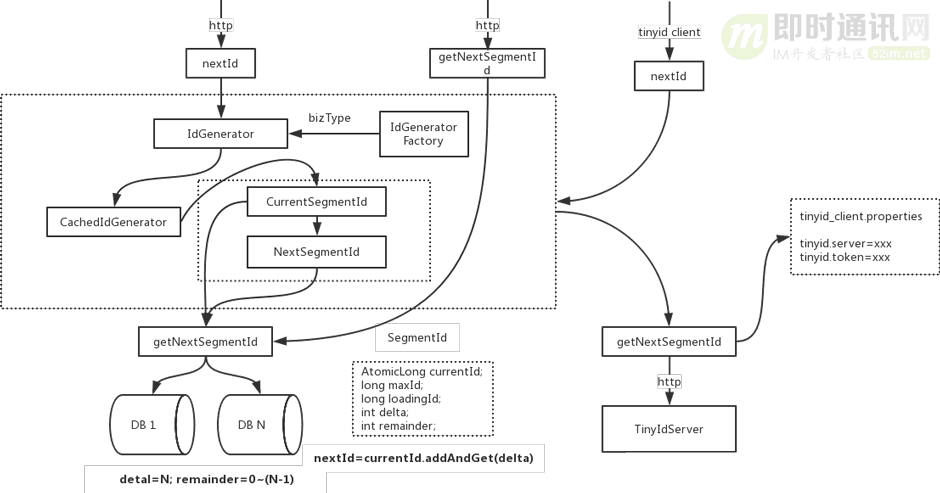
如上圖所示,下面是關(guān)于這個代碼調(diào)用邏輯圖的說明:
1)nextId和getNextSegmentId是tinyid-server對外提供的兩個http接口;
2)nextId是獲取下一個id,當(dāng)調(diào)用nextId時,會傳入bizType,每個bizType的id數(shù)據(jù)是隔離的,生成id會使用該bizType類型生成的IdGenerator;
3)getNextSegmentId是獲取下一個可用號段,tinyid-client會通過此接口來獲取可用號段;
4)IdGenerator是id生成的接口;
5)IdGeneratorFactory是生產(chǎn)具體IdGenerator的工廠,每個biz_type生成一個IdGenerator實例。通過工廠,我們可以隨時在db中新增biz_type,而不用重啟服務(wù);
6)IdGeneratorFactory實際上有兩個子類IdGeneratorFactoryServer和IdGeneratorFactoryClient,區(qū)別在于,getNextSegmentId的不同,一個是DbGet,一個是HttpGet;
7)CachedIdGenerator則是具體的id生成器對象,持有currentSegmentId和nextSegmentId對象,負責(zé)nextId的核心流程。nextId最終通過AtomicLong.andAndGet(delta)方法產(chǎn)生。
具體的代碼實現(xiàn),有興趣可以直接閱讀源碼:
主地址:https://github.com/didi/tinyid
備地址:https://github.com/52im/tinyid
7、Tinyid的最佳實踐
1)tinyid-server推薦部署到多個機房的多臺機器:
多機房部署可用性更高,http方式訪問需使用方考慮延遲問題。
2)推薦使用tinyid-client來獲取id,好處如下:
a、id為本地生成(調(diào)用AtomicLong.addAndGet方法),性能大大增加;
b、client對server訪問變的低頻,減輕了server的壓力;
c、因為低頻,即便client使用方和server不在一個機房,也無須擔(dān)心延遲;
d、即便所有server掛掉,因為client預(yù)加載了號段,依然可以繼續(xù)使用一段時間
注:使用tinyid-client方式,如果client機器較多頻繁重啟,可能會浪費較多的id,這時可以考慮使用http方式。
3)推薦db配置兩個或更多:
db配置多個時,只要有1個db存活,則服務(wù)可用 多db配置,如配置了兩個db,則每次新增業(yè)務(wù)需在兩個db中都寫入相關(guān)數(shù)據(jù)。
8、Tinyid該怎么調(diào)用?
關(guān)于怎么調(diào)用。鑒于篇幅原因,就不再具體去寫了,有興趣的話,可以讀一下這篇《Tinyid:滴滴開源千萬級并發(fā)的分布式ID生成器》。
9、參考資料
[1] 面試總被問分布式ID怎么辦? 滴滴(Tinyid)甩給他
[2] Tinyid:滴滴開源千萬級并發(fā)的分布式ID生成器
[3] tinyid工程中文readme
[4] 滴滴開源的Tinyid如何每天生成億級別的ID?





