

引用
Ding G, Guo Y, Zhou J. Collective matrix factorization hashing for multimodal data[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 2075-2082.
摘要
在計算機視覺和信息檢索領域,基于哈希的最近鄰搜索方法在有效和高效的大規模相似性搜索中備受矚目。以多模態數據為中心,本文研究了學習哈希函數進行跨視角的相似性搜索的問題。我們提出了一種新型的哈希方法,稱為協同矩陣分解的哈希(CMFH)。CMFH 通過協同矩陣分解與潛因子模型從一個實例的不同模態中學習統一的哈希碼,不僅可以支持跨視圖的搜索,而且可以通過合并多個視圖的信息源,提高搜索精度。我們還證明了 CMFH 作為一種保留相似性的哈希學習方法,具有閾值。通過大量的實驗,我們在三個不同的數據集上驗證了 CMFH 相較于幾種最先進的方法的顯著優越性。
1 介紹
最近鄰搜索在許多重要的應用中發揮著基礎性的作用,如信息檢索、數據挖掘和計算機視覺等領域。基于散列的最近鄰搜索是將高維數據嵌入到緊湊的二進制碼字中,因其近年來在海量數據中的巨大效率提升而引起了研究人員們的極大興趣。其中,基于哈希的模型中最值得借鑒的是位置敏感哈希(LSH),其基本思想是將原始數據映射到漢明空間,同時保留它們的相似性。LSH 可以很有效地處理相似性搜索,因為在計算二進制碼之間的漢明距離時,應用了位運算。在標準 LSH 的基礎上, 也可以采用一些機器學習的方法來設計有效的緊湊哈希。
隨著相似性搜索在不同視圖中的應用,上述的單視圖方法已趨向于多視圖場景。最近, 一些跨視圖哈希函數學習的核心問題是:如何處理來自不同概率分布的多模態數據。
一般來說,跨視角哈希方法可以分為兩類:特定視圖哈希方法和綜合哈希方法。以特定視圖的散列方法為實例的每個視圖,首先會學習獨立的散列碼,然后將多個特定視圖的二進制碼進行串聯,得到綜合散列碼。跨模態相似性搜索散列(CMSSH)是通過將不可知數據嵌入到一個共同的度量空間中來解決的。Kumar 等人將頻譜哈希擴展到多視圖文件中,并提出了跨視圖哈希模型(CVH),該模型通過求解廣義特征值問題來最小化對象的權重平均多視圖的 L2 范式距離。共規化哈希(CRH),其目標函數意圖是將數據投影到遠離 0 的地方,以獲得良好的泛化效果,同時,有效地保留模態間的相似性。媒介間哈希(IMH)引入媒介間一致性和媒介內一致性來發現一個共同的漢明,并利用線性回歸與復合模型來學習特定視圖的哈希函數。上述哈希方法主要用于不同視圖間的相似性搜索。例如,將一張圖片作為查詢對象,搜索引擎可以返回一些文檔,以準確描述細節。為了實現跨視圖搜索,每個視圖都需要存儲獨立的哈希碼,增加了存儲和搜索的成本。
綜合哈希方法為每個實例學習統一的哈希碼。多信息源復合哈希(CHMIS)通過優化放寬哈希碼,將不同信息源的信息結合到最終的綜合哈希碼中。多視圖頻譜哈希(MVSH)將多視圖信息分解為二進制代碼,并使用碼字乘積來避免不良嵌入。這類哈希方法一般是利用一個實例的多個信息源進行組合來提高哈希碼的搜索精度,對于跨視圖相似搜索沒有實現。它們只有在所有信息源都可用的情況下才能很好地工作,這在現實世界中需求量太大。
在本文中,我們提出了一種新型的哈希方法,基于協同矩陣分解的哈希方法(CMFH)。CMFH 假設一個實例的每個視圖都會產生相同的哈希碼,這些哈希碼并不是不同視圖中的一些哈希碼的組合或并發。圖 1 說明了上述兩類方法和 CMFH 的區別。對于每個實例,我們通過協同矩陣分解與潛因子模型從不同的視圖中形成源學習統一的代碼。為了保證學習到的哈希碼可以搜索到不同的視圖,我們還為每個視圖學習線性哈希函數,以確定未見實例的二進制代碼。我們的論文有以下貢獻:
- 我們提出了一種跨視圖場景下的統一哈希方法,不僅可以支持跨視圖搜索,而且可以通過合并多個視圖信息提高搜索精度。
- 我們的工作是首次嘗試采用協同矩陣分解(CMF)技術來學習跨視角的哈希函數。我們的實驗證明,當有多個視圖信息源時,CMF 是一種有效的哈希方法。
- 我們證明所提出的 CMFH 是一種具有近似雙連續性的相似性保存哈希方法。

圖 1. 三類方法的區別
2 基于協同矩陣分解的哈希方法
在本節中,我們將介紹我們的多模態數據哈希方法,即基于協同矩陣分解的哈希方法(CMFH)。在不失通用性的前提下,我們首先介紹雙模態情況下的 CMFH,因為它簡單易懂。
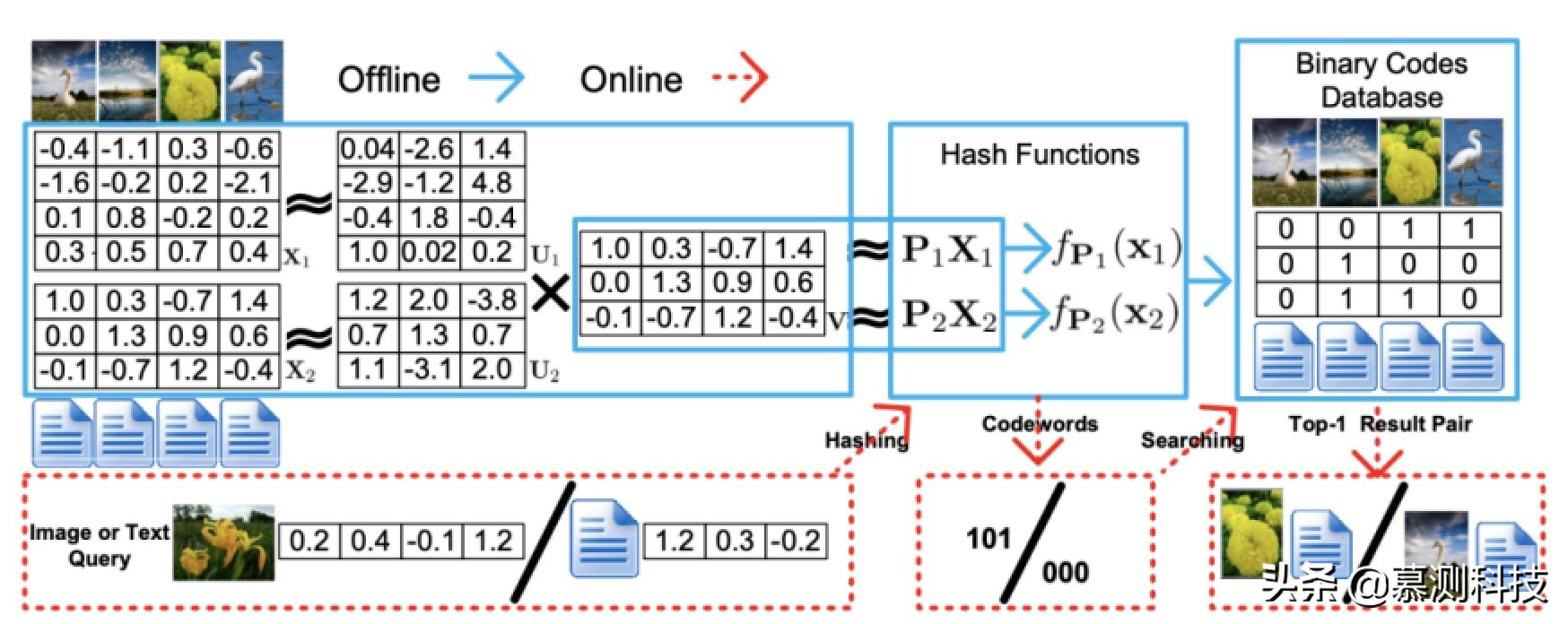
圖 2. CMFH 的框架
如圖 2 所示,所提出的 CMFH 包括兩個階段。一個是離線哈希函數學習和數據庫生成,另一個是在線編碼和搜索。在離線階段,CMFH 學習統一的哈希碼 Y = [y1 , ..., yn ]。對于樣本外的實例,CMFH 學習第 t 個視圖的特定視圖哈希函數 ft。與之前的工作類似,我們只考慮了以下形式的仿射
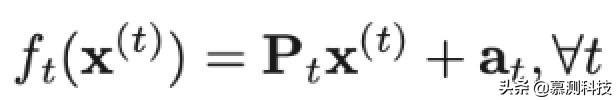
我們可以通過矩陣分解從源數據集中學習潛在的語義特征。我們假定:
1.相互關聯的數據應具有相同的潛在語義表示。
2.哈希碼可以從潛在語義表示中學習
本方法的優化問題為非凸問題,有五個矩陣變量 U1,U2,P1,P2,V,幸運的是,在固定其他四個矩陣變量的情況下,對五個矩陣變量中的任何一個都是凸的。因此,該優化問題可以反復迭代求解,直到收斂為止。該方法可總結為算法 1。

3 實驗
我們在三個不同的數據集上進行了實驗:Wiki、NUS-WIDE 和 MIRFLICKR-25000。我們將所提出的 CMFH 與幾種最先進的方法進行了比較,實驗結果表明,CMFH 的性能明顯優于基線方法。
3.1 實驗設置
WiKi。它是從維基百科中收集的 2,866 個圖像-文本對。每幅圖像由 128 維的 SIFT 直方圖表示,每篇文字由 10 維的主題向量表示。它包含 10 個語義類,每對圖像都被標記為其中之一。我們將 75%的對子作為訓練集,其余 25%作為查詢集。
NUS-WIDE。它是一個真實世界的網絡圖像數據庫,包含 81 個概念和 269,648 張帶標簽的圖像。我們對十個最大的概念和相應的 186,577 張圖片進行了講解。圖像由 500 維的 SIFT 直方圖表示,文本由最常見的 1000 個標簽的索引向量表示。每對圖像由 10 個概念中的至少一個來注釋。如果它們至少共享一個概念,則認為它們是相似的。我們使用 99%的數據作為訓練集,其余 1%作為查詢集。
MIRFLICKR-25000。它由 25000 張圖像組成,每張圖像都被一些標簽注釋為 38 個唯一的標簽。圖像由 100 維度的 SIFT 直方圖描述,主要編碼表面紋理,144 維度的 CEDD 特征主要是顏色和邊緣直接性。由于它們在紋理空間上相似,而在顏色空間上不同,我們選擇它們來模擬跨視角環境。我們將 75%的對子作為訓練集,其余 25%作為查詢集。
CMFH 與五種最先進的散列 55566 方法進行了比較。LSH , CVH , IMH , CMSSH 和 CHMIS .它們可以分為三種類型。LSH 是單視圖哈希方法,而 CVH、IMH 和 CMH 是跨視圖哈希方法,其中學習特定視圖的哈希碼,CHMIS 是跨視圖方法,學習綜合哈希碼。我們仔細調整了它們的參數,并報告了它們的最佳結果。
3.2 實驗結果
表 1. mAP 對比,View1 為圖像或 CEDD,View2 為文本或 SIFT
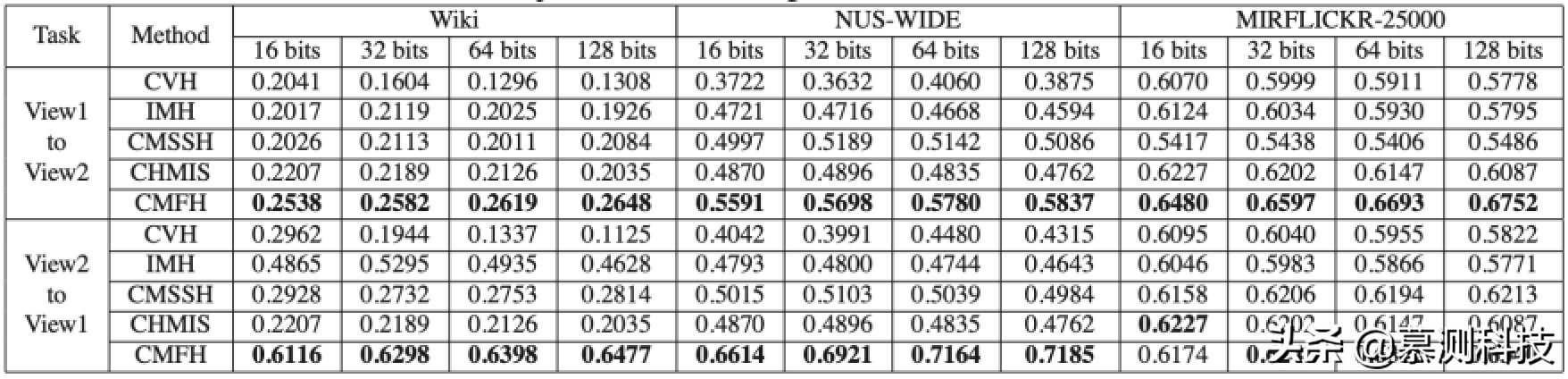
表 1 報告了 CMFH 和四種基線方法的 mAP 值。圖 4 繪制了精度-召回曲線。我們可以觀察到,CMFH 在兩個不同代碼長度的任務上都顯著優于所有基線方法,這驗證了 CMFH 的有效性。
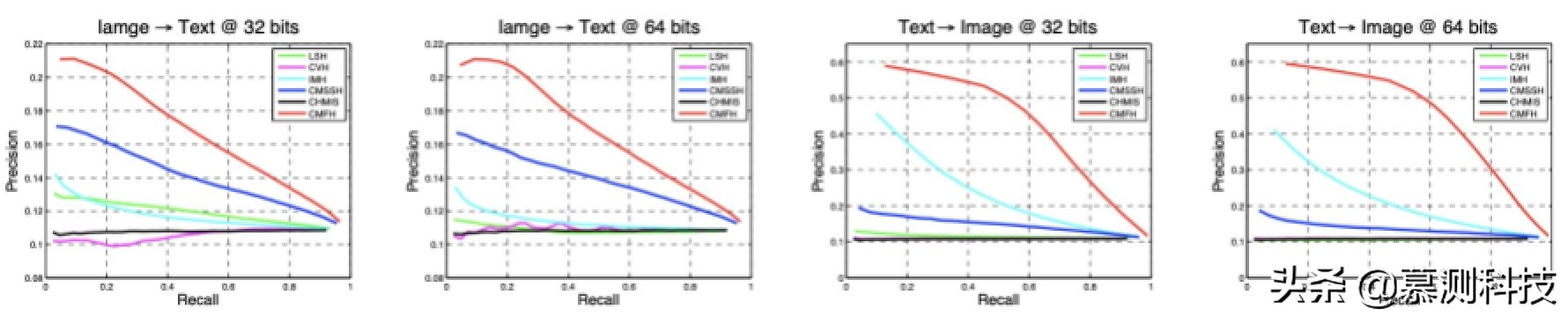
圖 4. 不同代碼長度的 PR 曲線
此外,CMFH 在代碼較長的情況下表現更好。這是合理的,因為較長的哈希碼可以編碼更多的信息,因此可以提高 mAP 表現。然而,我們可以觀察到幾種方法的 PR 曲線看起來很奇怪,例如 CVH 在 64 位時的 PR 曲線在實驗中表現得像隨機猜測。實際上,所有的基線方法都是通過特征值分解來解決的,并且對每個位子都有正交約束,所以每個位子之間沒有相關性。前幾個投影方向可能具有較高的方差,其對應的哈希位可以具有相當的判別能力,這對相似性搜索相當有用。但是,隨著碼長的增加,哈希碼將以方差很低的位為主。其實,由于方差太低,低位的比特是沒有意義的,也是模棱兩可的。所以這些不加區分的哈希位可能會導致該方法在實驗中進行隨機猜測。
表 1 報告了 CMFH 和四種基線方法的 mAP 值。如上所述,我們隨機選取 5000 個實例作為訓練集來學習哈希函數。并將學習到的哈希函數擴展到整個數據庫中。CMFH 在兩個任務上都顯著優于所有基線方法,不同的代碼長度。
此外,我們還比較了不同哈希方法在 NUS-WIDE 上進行單視圖相似度搜索的性能。我們可以觀察到,結合了一個實例的多個信息源的 CMFH 可以優于其他哈希方法。這是合理的,因為當結合多個視圖時,一個實例的更多信息可以被編碼成哈希碼。此外,這個結果也驗證了 CMFH 通過合并多個信息源來提高搜索精度的能力。
在實際應用中,由于計算資源的限制,數據庫的規模可能非常大,不可能對整個數據庫進行哈希函數的學習。而且隨著時間的推移,新的數據不斷進入數據庫,必須為新數據輸入哈希碼。本研究的目的是為了解決這些問題,在一個較小的訓練集上學習哈希函數,并將其擴展到樣本外的實例(數據庫中的其他實例或新出現的實例)。在 NUS-WIDE 上的實驗設置與現實世界的場景相當相似。實驗結果表明,CMFH 可以很容易地處理樣本外的實例,并且具有處理大規模數據庫的能力。
另外,表 1 還報告了 CMFH 和四種基線方法的跨視角相似性搜索的 mAP 值。如上結果,CMFH 在跨視角相似性搜索中可以優于所有不同代碼長度的基線方法。

上一節中描述的貪心算法的計算成本很高,因為它每一步都要調用一個決策過程。我們現在提出一種成交相對較低的技術,它依賴于數據,避免了多次調用決策過程。我們的想法是觀察大量輸入的激活特征,并學習各種輸出屬性的決策模式。在本文中,我們使用決策樹學習來提取基于層中神經元的激活狀態(激活或未激活狀態)的緊湊規則。采用決策樹是很有必要,因為決策樹能夠根據各種信息理論的衡量標準得到一個決策模式,并且是緊湊的(因此具有較高的可靠性)。所得到的模式是經過實證驗證的層屬性,可以通過對決策過程的一次調用來正式檢驗。
4 總結
多模態數據的跨視圖相似性搜索。CMFH 通過協同矩陣分解與潛因子模型從一個實例的不同模態中學習統一的哈希碼,可以對不同視圖進行搜索。我們還表明,CMFH 是一種具有近似雙連續性的相似性保存哈希方法。
我們進行實驗來驗證所提出的 CMFH 的有效性。我們表明,在所有的跨視角和大多數單視角相似性搜索實驗中,CMFH 的性能比幾種最先進的哈希方法好得多。參數分析表明,CMFH 對參數設置并不敏感,在很寬的參數值范圍內都能提供顯著的性能。此外,CMFH 能夠輕松處理樣本外的實例,并且能夠從大規模數據庫中以合理的小訓練集學習穩定的哈希函數,這使得它適用于實際場景。
5 致謝
本文由南京大學軟件學院 2019 級碩士劉佳瑋轉述





