擊這里在線咨詢客服")
前言
為了進(jìn)行機(jī)器學(xué)習(xí)工程,首先要部署一個(gè)模型,在大多數(shù)情況下作為一個(gè)預(yù)測API。為了使此API在生產(chǎn)中工作,必須首先構(gòu)建模型服務(wù)基礎(chǔ)設(shè)施。這包括負(fù)載平衡、擴(kuò)展、監(jiān)視、更新等等。
乍一看,所有這些工作似乎都很熟悉。Web開發(fā)人員和DevOps工程師多年來一直在自動化微服務(wù)基礎(chǔ)設(shè)施。當(dāng)然,我們可以重新定位他們的工具?
不幸的是,我們不能。
雖然ML的基礎(chǔ)結(jié)構(gòu)與傳統(tǒng)的DevOps類似,但它與ML的特殊性足以使標(biāo)準(zhǔn)的DevOps工具不那么理想。這就是為什么我們開發(fā)了Cortex——機(jī)器學(xué)習(xí)工程的開源平臺。
在一個(gè)非常高的層次上,Cortex被設(shè)計(jì)用來簡化在本地或云上部署模型,從而自動化所有底層基礎(chǔ)設(shè)施。該平臺的一個(gè)核心組件是預(yù)測器接口——一個(gè)可編程Python接口,開發(fā)人員可以通過該接口編寫預(yù)測api。
設(shè)計(jì)一個(gè)專門為web請求提供預(yù)測的Python接口是一個(gè)挑戰(zhàn),我們花了幾個(gè)月的時(shí)間(目前仍在改進(jìn))。在這里,我想分享一些我們已經(jīng)開發(fā)的設(shè)計(jì)原則:
1.預(yù)測器只是一個(gè)Python類
Cortex的核心是我們的預(yù)測器,它本質(zhì)上是一個(gè)預(yù)測API,包括所有的請求處理代碼和依賴關(guān)系。預(yù)測器接口為這些預(yù)測api實(shí)施了一些簡單的需求。
因?yàn)镃ortex采用微服務(wù)的方式來進(jìn)行模型服務(wù),預(yù)測器界面嚴(yán)格關(guān)注兩件事:
- 初始化模型
- 提供預(yù)測
在這種精神下,Cortex的預(yù)測界面需要兩種功能,即剩余的init__()和predict(),它們或多或少做你所期望的事情:
import torch
from transformers import pipeline
class PythonPredictor:
def __init__(self, config):
# Use GPUs, if available
device = 0 if torch.cuda.is_available() else -1
# Initialize model
self.summarizer = pipeline(task="summarization", device=device)
def predict(self, payload):
# Generate prediction
summary = self.summarizer(
payload["text"], num_beams=4, length_penalty=2.0, max_length=142, no_repeat_ngram_size=3
)
# Return prediction
return summary[0]["summary_text"]
初始化之后,您可以將一個(gè)預(yù)測器看作一個(gè)Python對象,當(dāng)用戶查詢端點(diǎn)時(shí),將調(diào)用它的單個(gè)predict()函數(shù)。
這種方法的最大好處之一是,對于任何有軟件工程經(jīng)驗(yàn)的人來說,它都是直觀的。不需要接觸數(shù)據(jù)管道或模型訓(xùn)練代碼。模型只是一個(gè)文件,而預(yù)測器只是一個(gè)導(dǎo)入模型并運(yùn)行predict()方法的對象。
然而,除了語法上的吸引力之外,這種方法還提供了一些關(guān)鍵的好處,即它如何補(bǔ)充了皮層更廣泛的方法。
2. 預(yù)測只是一個(gè)HTTP請求
為生產(chǎn)中提供預(yù)測服務(wù)而構(gòu)建接口的復(fù)雜性之一是,輸入幾乎肯定會與模型的訓(xùn)練數(shù)據(jù)不同,至少在格式上是這樣。
這在兩個(gè)層面上起作用:
- POST請求的主體不是一個(gè)NumPy數(shù)組,也不是您的模型用來處理的任何數(shù)據(jù)結(jié)構(gòu)。
- 機(jī)器學(xué)習(xí)工程就是使用模型來構(gòu)建軟件,這通常意味著使用模型來處理它們沒有受過訓(xùn)練的數(shù)據(jù),例如使用GPT-2來編寫民間音樂。
因此,預(yù)測器接口不能對預(yù)測API的輸入和輸出固執(zhí)己見。預(yù)測只是一個(gè)HTTP請求,開發(fā)人員可以隨意處理它。例如,如果他們想部署一個(gè)多模型端點(diǎn),并基于請求參數(shù)查詢不同的模型,他們可以這樣做:
import torch
from transformers import pipeline
from starlette.responses import JSONResponse
class PythonPredictor:
def __init__(self, config):
self.analyzer = pipeline(task="sentiment-analysis")
self.summarizer = pipeline(task="summarization")
def predict(self, query_params, payload):
model_name = query_params.get("model")
if model_name == "sentiment":
return self.analyzer(payload["text"])[0]
elif model_name == "summarizer":
summary = self.summarizer(payload["text"])[0]
else:
return JSONResponse({"error": f"unknown model: {model_name}"}, status_code=400)
雖然這個(gè)界面讓開發(fā)者可以自由地使用他們的API做什么,它也提供了一些自然的范圍,使皮質(zhì)在基礎(chǔ)設(shè)施方面更加固執(zhí)己見。
例如,在后臺Cortex使用FastAPI來設(shè)置請求路由。Cortex在這一層設(shè)置了許多與自動排序、監(jiān)控和其他基礎(chǔ)設(shè)施功能相關(guān)的過程,如果開發(fā)人員需要實(shí)現(xiàn)路由,這些功能可能會變得非常復(fù)雜。
但是,因?yàn)槊總€(gè)API都有一個(gè)predict()方法,所以每個(gè)API都有相同數(shù)量的路由—1。假設(shè)這允許Cortex在基礎(chǔ)設(shè)施層面做更多的事情,而不限制工程師。
3.服務(wù)模型只是一個(gè)微服務(wù)
對于在生產(chǎn)中使用機(jī)器學(xué)習(xí)的人來說,規(guī)模是一個(gè)主要的問題。型號可能會很大(GPT-2大約是6 GB),計(jì)算成本高,并且可能有很高的延遲。特別是對于實(shí)時(shí)推斷,擴(kuò)大規(guī)模來處理流量是一項(xiàng)挑戰(zhàn)——如果你的預(yù)算有限,情況更是如此。
為了解決這個(gè)問題,Cortex把預(yù)測器當(dāng)作微型服務(wù),可以水平伸縮。更具體地說,當(dāng)開發(fā)人員進(jìn)行Cortex部署時(shí),Cortex將包含API,旋轉(zhuǎn)為推理準(zhǔn)備的集群,并進(jìn)行部署。然后,它將API公開為負(fù)載平衡器背后的web服務(wù),并配置自動縮放、更新和監(jiān)視:
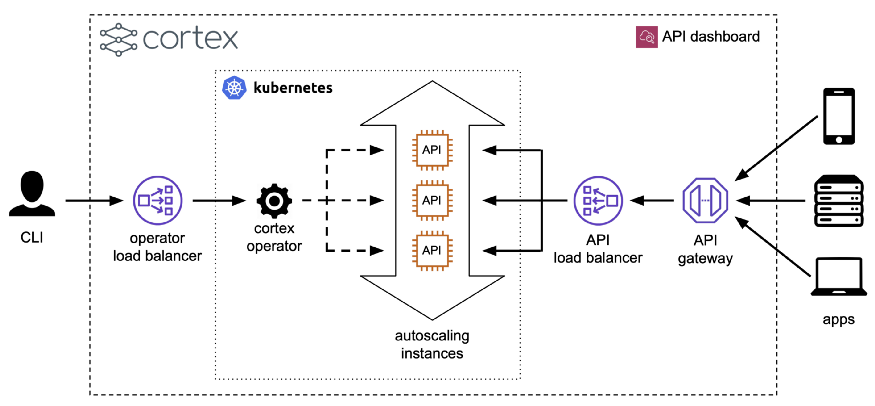
預(yù)測器接口是此過程的基礎(chǔ),盡管它“只是”一個(gè)Python接口。
預(yù)測器接口所做的是強(qiáng)制打包代碼,使其成為推理的單個(gè)原子單元。單個(gè)API所需的所有請求處理代碼都包含在一個(gè)預(yù)測器中。這使得大腦皮層能夠很容易地衡量預(yù)測因素。
通過這種方式,工程師不必做任何額外的工作——當(dāng)然,除非他們想做一些調(diào)整——準(zhǔn)備一個(gè)用于生產(chǎn)的API。一個(gè)皮層的部署是默認(rèn)的生產(chǎn)準(zhǔn)備就緒。
英文原文:
https://towardsdatascience.com/designing-a-python-interface-for-machine-learning-engineering-ae308adc4412





