
它在線上每天服務幾十萬的用戶,并且流水過億。沒有所謂的微服務、分布式,就是一個war包,然后扔到Tomcat里面去。里面的代碼很多,目前我看到的最大的一個類是28000多行代碼。是的,我沒有多打一個0,確確實實的2w8千多行。
有朋友關心線上是如何部署的,這里分享一下我的方案,大家也可以一起討論一下。
我曾經獨立負責過一個微服務,它承載了晚高峰每小時2000w+次的請求,平均到每秒是大概是5500次的接口調用,線上是用了4臺4C8G的阿里云服務器,單機單服務部署方案。
關于業務開發的一些心得,我個人的幾點看法:
- 復雜的場景簡單化,一定要越簡單越好,只有簡單了,你才hold住,bug才會少;
- 先不要去考慮性能的事情,先保證功能沒bug吧,然后再去考慮性能的事情,當然你的經驗會讓你寫的代碼性能優越,優秀的程序員自帶性能;
- 高并發的前提是高可用,沒有了可用性,談高并發都是扯淡;
- 寫好你自己的代碼,然后去壓測它,單接口壓測、鏈路壓測,找到慢的地方(怎么找?),想辦法去優化它,然后你就慢慢的成為了高手,高并發經驗就這么來的;
- 能用緩存的就用緩存,數據庫其實也很牛逼,前提是你的sql要足夠快,慢sql是性能的第一殺手!
- redis基本能hold住大部分的并發請求,當然MQ也很好用,盡量用這些中間件,別自己寫了,除非你們有基礎架構組。
上述都是扯淡,言歸正傳。
1、部署架構
開始說我的單體應用是怎么部署的,一圖勝千言:

整體情況如下:
- 一個api域名指向阿里云的SLB,SLB指向三臺ECS服務器的內網IP并指定端口,權重都100;
- 三臺Job服務器,專門去跑任務(各種埋點統計、數據報表、業務job等等);
- 6臺ECS的配置都是4C8G,連續包月,費用不高;
- 一臺16G集群版Redis,高并發就靠它了;
- 阿里云數據庫RDS一主一從,代碼里讀寫分離;
- 日志還是要好好打的,一個優秀的程序員一定會合理有效的log.info、log.error;
2、關于代碼開發、測試&部署
如果我說我自己開發、自己測試、自己部署你相信嗎?是的,這一切都得我自己來做,我還得自己CR自己的代碼,所以這很難。
我沒有高大上的方法,也從來不寫單元測試,只是寫完了自己測試一下,然后自己再過一遍自己的代碼,這需要清晰的邏輯。很多時候,思考的時間遠遠超過寫代碼的時間,以下是我的一些方法或工具:
- 我有一個代碼倉庫,使用的是云效codeup;
- 我通過jenkins去構建并發布;
- 我的發布粒度是文件級別,即只同步更改過的class文件或者其他配置文件到指定的服務器上,利用版本控制工具;
- 純人工灰度,jenkins先發布一臺服務,看日志并校驗數據驗證功能,預計5分鐘左右的時間,繼續發布剩余的機器,一臺一臺發布;
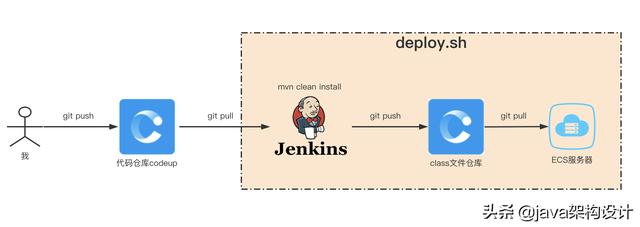
代碼提交到部署到服務器大概是這樣的一個流程:
我必須要解決一些問題:
- 線上訪問量高,如何無縫重啟服務?
- 線上日志刷太快,肉眼無法捕捉有效信息,如何確定上線功能是ok的?
- 如何降低上線風險?
- 出現問題,如何快速回滾,最小化業務損失?
- 我怎么能知道線上的代碼有問題?(佐證(報表數據)、日志監控)
同時,因為這是一個個人維護的項目,我必須使用一些小而美的技術或者工具,來避免增加運維成本,因此上云是最好的選擇。但這不一定適用于你,使用自己熟練的工具才是第一優先級。
3、解決這些問題
1、線上訪問量高,如何無縫重啟服務?
為了能夠做到無縫重啟,我需要在重啟一臺服務器的時候,先把它摘掉,以前我是手動登錄阿里云后臺去SLB實例管理控制臺把這臺機器的權重改為0,等重啟完畢并且穩定以后(load負載下降到正常值),再恢復權重的100,確定沒有問題后,再繼續其他2臺服務的上述操作。
這樣的人工操作占據了我太多的時間,我就在想,能不能我寫一個腳本,當我執行這個腳本時候,調用SLB的API先摘掉它,然后服務正常啟動后,再調用SLB的API恢復它?幸運的是阿里云提供了這樣的API,而我的重啟腳本只需要在restart之前,curl一下這個api,并在啟動之后,再調用一下恢復權重的api就好了。
這樣我就實現了無縫重啟。
2、線上日志刷太快,肉眼無法捕捉有效信息,如何確定上線功能是ok的?
我個人是喜歡打很詳細的業務日志,檢索指定日志(grep -ni 'xxx' server.log)這是我最常用的線上排查問題的方式。但是我有三臺api服務,三臺job服務,我需要有一個日志聚合的地方,方便查詢所有的日志。
很多公司采用的方案是搭建一套ELK日志收集、檢索的系統,但這不適合個人,我采用的是阿里云的日志服務。
所有的日志保存7天,7天只是我個人的選擇,節約成本并且可控而已,我并不建議你們也這么做。
阿里巴巴8月3日發布的《JAVA開發手冊嵩山版》上有說日志最少保存15天,可以看到三個周一,國家規定是保存60天。

有了實時收集的日志,我就可以查看一段時間以內接口請求的數量,error級別的日志量等各種維度的數據,通過這些數據來驗證代碼是否有問題,但這依舊不能徹底解決我的問題。
無論如何單憑日志是無法決定上線的功能是否有問題,只能證明代碼沒有運行異常。
3、降低上線風險、快速回滾
為了盡可能的降低上線的風險,我需要清楚的知道每次上線的時候明確改動的文件有哪些,它對業務的影響范圍如何。
每一次上線后,我都需要觀察如下幾個維度的數據情況:
- 3分鐘內,error級別的日志數量;
- 10分鐘內,交易數據怎么樣?
- 30分鐘,當前小時的arpu值同比前天、昨天的數據如何?
- 重點關注本次上線功能是否如期運行,所產生數據是否與期望一致。
很多時候,項目的回滾不是因為程序運行出錯了,而是因為業務數據不理想,更可氣的是,一旦回滾之后,業務數據確實又恢復上來了。
因此,我需要能夠方便的回滾到任何一個版本,且盡可能的降低上線的風險。
還記得上面那個部署的圖嗎?

具體流程:我的代碼提交到倉庫后,通過jenkins進行構建,產生最終的class文件,并通過版本控制上傳到class文件倉庫,最終增量同步文件到服務器上去,并打一個tag作為本次上線的記錄,這一切都通過腳本來操作完成。
4、結束語
我的經驗并不適合你,你得有自己的一套知識體系,并且它曾經被你實際驗證過,而且你應該不斷提升這些技能的熟練度,然后再去看別人怎么玩,最后你才會有所比較,知道好與不好,獲得真正屬于自己的心得。





