擊這里在線咨詢客服")
為了能讓索引能有更直觀的效率,我在一張表里扔進(jìn)了百萬條數(shù)據(jù)(光靠這些數(shù)據(jù),生成數(shù)據(jù)代碼寫了一個(gè)小時(shí),解決MySQL8的文件導(dǎo)入權(quán)限問題解決了兩個(gè)小時(shí),導(dǎo)入數(shù)據(jù)花費(fèi)了一個(gè)小時(shí),我太難了~(;д;)。但是,一切不以實(shí)踐數(shù)據(jù)為標(biāo)準(zhǔn)的理論都是**耍!流!氓!**o(´^`)o)。讓我們一邊講解MySQL的使用一邊看一下索引能為我們的查詢帶來的性能提升吧。
索引使用的優(yōu)勢(shì)
提高查詢效率,簡單來說就是查的快!再快!更快!外面說的什么提高表的速度、加速表連接、減少分組及排序時(shí)間、提高系統(tǒng)性能,說白了都是快,查得快!(順便我發(fā)現(xiàn)百度出來的索引使用優(yōu)勢(shì)劣勢(shì)貌似就那么一兩套,真就天下文章一大抄唄,抄我的也歡迎,煩請(qǐng)注明出處或者作者Solid_lele哈)
具體會(huì)有多快呢?
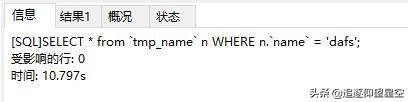
這是沒有索引的百萬級(jí)數(shù)據(jù)查找(這個(gè)算快的了,慢的四十秒,時(shí)間不是很穩(wěn)定,因?yàn)槭菑拇疟P塊中讀取數(shù)據(jù),原理參照我開頭提到的那篇文章)10.797s:
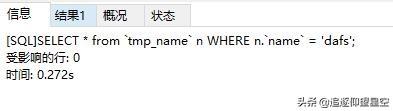
這是有索引的百萬級(jí)數(shù)據(jù)查找0.272s:
差了四十多倍,就相當(dāng)于別人一年賺四十多萬,我一年賺一萬,這差距真的是太痛苦了。
索引使用的劣勢(shì)
凡事具有兩面性,有好就會(huì)有壞,拿時(shí)間換空間或者拿空間換時(shí)間這種操作屢見不鮮,索引就是拿空間換時(shí)間,雖然并不是那么典型(因?yàn)樗诵牟⒉皇窃龃罂臻g減少時(shí)間,而是通過維護(hù)類似目錄的結(jié)構(gòu)減少IO的讀寫次數(shù),最典型的空間換時(shí)間是計(jì)數(shù)排序)。壞處自然就出現(xiàn)了:
1、維護(hù)成本高
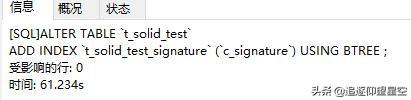
索引維護(hù)了一個(gè)類似于目錄的結(jié)構(gòu),你可以聯(lián)想新華字典的目錄,當(dāng)你創(chuàng)建目錄的時(shí)候,如果沒有程序幫忙,你自己手寫目錄的話,需要一頁一頁的去翻去看確定那個(gè)字在哪兒,然后寫進(jìn)目錄里;萬一有個(gè)字被刪了或者加了一個(gè)字還要重新調(diào)整一遍目錄。對(duì)程序也是一樣,索引的創(chuàng)建和維護(hù)是需要消耗性能的,所以會(huì)降低數(shù)據(jù)庫修改時(shí)的性能。就以創(chuàng)建索引來說,創(chuàng)建百萬級(jí)別的varchar數(shù)據(jù)BTREE索引,數(shù)據(jù)內(nèi)容長度為20個(gè)漢字,消耗的時(shí)間為61.234s:
再比較一下維護(hù)索引的代價(jià),比如無索引百萬級(jí)別數(shù)據(jù)插入一條時(shí)間為0.480s:
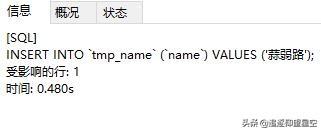
而有索引的百萬級(jí)別數(shù)據(jù)插入一條時(shí)間為1.273s:
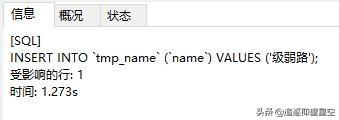
差距其實(shí)還挺大的(請(qǐng)忽略我亂打插入的三個(gè)字)。
2、所占空間大
既然提到空間換時(shí)間,那么空間的浪費(fèi)是不可避免的,我做了下面的這個(gè)測(cè)試(測(cè)試數(shù)據(jù)庫MySQL8,數(shù)據(jù)庫運(yùn)行環(huán)境windows)。
首先創(chuàng)建了一個(gè)臨時(shí)表tmp_name,其中只有一列名為c_name的字段,發(fā)現(xiàn)文件夾中存儲(chǔ)的ibd文件初始大小為112k,插入百萬條數(shù)據(jù)(100萬條數(shù)據(jù)整哦,一個(gè)不多一個(gè)不少哦)后,大小為40960k:
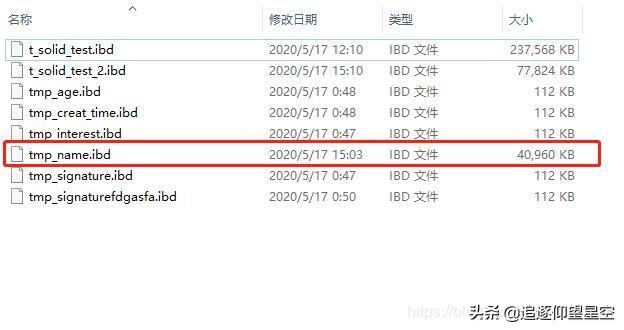
然后創(chuàng)建了一個(gè)BTREE索引,大小變?yōu)榱?3728k:
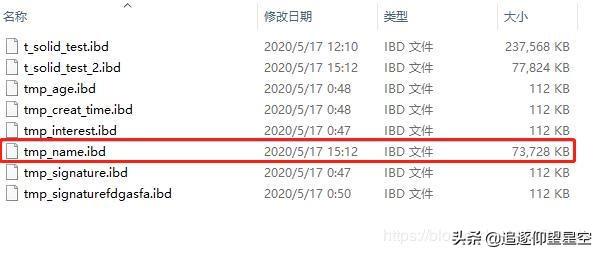
大約多用了一倍的空間。但實(shí)際中不可能每個(gè)字段都加索引,生產(chǎn)中為索引預(yù)留的空間大概占數(shù)據(jù)大小的五分之一就夠了。在這個(gè)數(shù)據(jù)為重效率至上的時(shí)代,磁盤的空間成本貌似還是比較劃算的。
其實(shí)使用索引還有個(gè)劣勢(shì),就是你需要花費(fèi)時(shí)間來看我這篇文章o(////▽////)q
索引的分類
單值索引:就是一個(gè)索引只包含單個(gè)列,一個(gè)表可以有多個(gè)單列索引;唯一索引:就是索引列的值必須唯一,但允許有空值(主鍵索引就是唯一索引,但它不能為null);復(fù)合索引:就是聯(lián)合索引,也就是一個(gè)索引包含多個(gè)列;
我看網(wǎng)上介紹索引的都說了唯一索引和復(fù)合索引,咋,單值索引就不算索引了?互相“借鑒”的時(shí)候好歹也自己思考一下好不啦。
索引的創(chuàng)建規(guī)則
索引既然有這么明顯的優(yōu)勢(shì)以及劣勢(shì),我們自然要把它的優(yōu)勢(shì)最大化,劣勢(shì)盡可能避免。所以索引最好能做到:
1、經(jīng)常作為查詢或者排序條件;
2、重復(fù)值盡可能少;
3、增刪改不會(huì)太多。
滿足上面三條規(guī)則的就可以創(chuàng)建索引了(不符合規(guī)則怎么樣這種數(shù)據(jù)我實(shí)在是不想貼出來了,就直接說吧,這篇文章到現(xiàn)在算上造數(shù)據(jù)+各種實(shí)驗(yàn)寫了十個(gè)小時(shí)了,還沒結(jié)束,又趕上LOL的無限火力,明明是周末卻只能羨慕別人在玩的我很是痛苦哇)。
所以總結(jié)一下適合創(chuàng)建的情況(就是以上面三個(gè)條件作為參考的各種情況啦):
1、主鍵:主鍵是自動(dòng)建立唯一索引的,不用咱操心;2、頻繁作為查詢條件的字段:畢竟就是為了查的快才創(chuàng)建索引的嘛;3、查詢中與其它表關(guān)聯(lián)的字段:這就是外鍵了,不僅關(guān)聯(lián)查詢用到了,重復(fù)值很少,很棒;4、如果有多個(gè)字段,盡量創(chuàng)建組合索引:當(dāng)查詢優(yōu)化器覺得分析兩個(gè)查詢索引太費(fèi)勁了,還不如用一個(gè)的時(shí)候,它就給你用一個(gè),所以只要遵循最佳左前綴原則,還是組合索引更靠譜;5、查詢中排序的字段:排序字段若通過索引去訪問將大大提高排序速度;6、查詢中統(tǒng)計(jì)或者分組字段:和上面情況一樣啦。
那什么時(shí)候不適合創(chuàng)建呢:
1、表記錄太少而且不會(huì)變得很多:夭壽啦,就這么幾百條數(shù)據(jù)建索引不如直接查一遍;
2、頻繁更新的字段不適合創(chuàng)建索引:維護(hù)索引很累的,查的沒這么多但是總改總改,系統(tǒng)就像被經(jīng)常需求變動(dòng)的程序員,不跟你打起來就不錯(cuò)了;
3、Where條件里用不到的字段不創(chuàng)建索引:不要問為什么,問就是出門左轉(zhuǎn)是電梯;
索引的CRD沒有U
創(chuàng)建Create
#該語句添加一個(gè)主鍵,這意味著索引值必須是唯一的,且不能為NULL。
ALTER TABLE [table_name] ADD PRIMARY KEY ([column_list]);
#這條語句創(chuàng)建索引的值必須是唯一的(除了NULL外,NULL可能會(huì)出現(xiàn)多次)。
ALTER TABLE [table_name] ADD UNIQUE [index_name] ([column_list]);
#添加普通索引,索引值可出現(xiàn)多次。
ALTER TABLE [table_name] ADD INDEX [index_name] ([column_list]);
#該語句指定了索引為 FULLTEXT ,用于全文索引。
ALTER TABLE [table_name] ADD FULLTEXT [index_name] ([column_list]);
查看Read
SHOW INDEX FROM [table_name];
刪除Drop
DROP INDEX [index_name] ON [table_name];
更新,不好意思沒有,想改就是刪了重加。
索引的分析(Explain)
終于走到這兒了,真刀真槍打一架吧,前面都是開胃小菜,現(xiàn)在才是正餐,但估計(jì)你們都快吃飽了,我也做累了,就很尷尬。
Explain是什么
話不多說,看官網(wǎng)API說明:
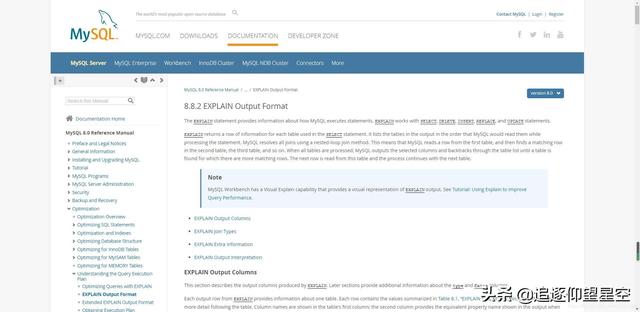
The EXPLAIN statement provides information about how MySQL executes statements. EXPLAIN works with SELECT, DELETE, INSERT, REPLACE, and UPDATE statements.
EXPLAIN returns a row of information for each table used in the SELECT statement. It lists the tables in the output in the order that MySQL would read them while processing the statement. MySQL resolves all joins using a nested-loop join method. This means that MySQL reads a row from the first table, and then finds a matching row in the second table, the third table, and so on. When all tables are processed, MySQL outputs the selected columns and backtracks through the table list until a table is found for which there are more matching rows. The next row is read from this table and the process continues with the next table.
EXPLAIN語句提供了關(guān)于MySQL怎樣執(zhí)行語句的信息。EXPLAIN可以用來分析SELECT、DELETE、INSERT、REPLACE和UPDATE語句。EXPLAIN為SELECT語句中使用的每個(gè)表返回一行信息。它按照MySQL在處理語句時(shí)讀取的順序,列出執(zhí)行輸出中的表。MySQL使用嵌套循環(huán)連接方法解析所有連接。這意味著MySQL從第一個(gè)表中讀取一行,然后在第二個(gè)表、第三個(gè)表中找到匹配的行,以此類推。當(dāng)處理完所有表后,MySQL將輸出所選的列,并通過表列表進(jìn)行回溯,直到找到一個(gè)具有更多匹配行的表為止。從該表讀取下一行,然后繼續(xù)處理下一個(gè)表。
說白了就是能讓你看表的讀取順序、用索引情況、表之間的引用、優(yōu)化器查詢的情況這些信息的執(zhí)行情況分析。(不允許說每個(gè)漢字都認(rèn)識(shí)湊到一起不知道啥意思了)
Explain的使用及分析
使用:就是Explain+你的sql語句:
EXPLAIN SELECT * FROM t_solid_test where c_name = 'Solid';
查詢出來長這個(gè)樣子:

這么多信息都代表什么?咱一個(gè)個(gè)來看。
id
select查詢的序列號(hào),包含一組數(shù)字,表示查詢中執(zhí)行select子句或操作表的順序。
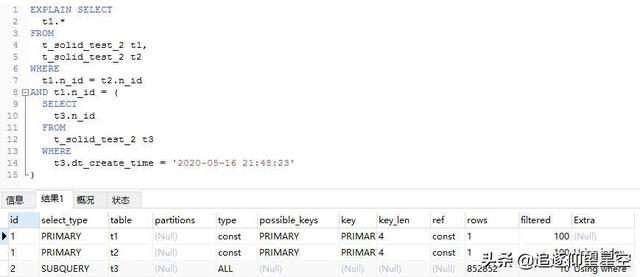
id值越大,優(yōu)先級(jí)越高,越先執(zhí)行;id如果相同,從上往下順序執(zhí)行。
select_type
查詢類型
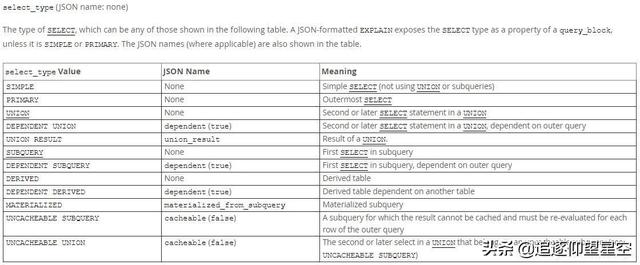
SIMPLE:簡單的 select 查詢,查詢中不包含子查詢或者UNION;
PRIMARY:查詢中若包含任何復(fù)雜的子部分,最外層查詢則被標(biāo)記為;
UNION:若第二個(gè)SELECT出現(xiàn)在UNION之后,則被標(biāo)記為UNION; 若UNION包含在FROM子句的子查詢中,外層SELECT將被標(biāo)記為:DERIVED;
DEPENDENT UNION:一個(gè)UNION中的第二個(gè)或更高版本的SELECT語句 ,取決于外部查詢;
UNION RESULT:UNION的結(jié)果。
SUBQUERY:在SELECT或WHERE列表中包含了子查詢;
DEPENDENT SUBQUERY:在子查詢中的第一個(gè)SELECT,取決于外部查詢
DERIVED:在FROM列表中包含的子查詢被標(biāo)記為DERIVED(衍生) MySQL會(huì)遞歸執(zhí)行這些子查詢, 把結(jié)果放在臨時(shí)表里;
DEPENDENT DERIVED:派生表依賴于另一個(gè)表;
MATERIALIZED:物化子查詢;
UNCACHEABLE SUBQUERY:子查詢,其結(jié)果無法緩存,必須針對(duì)外部查詢的每一行重新進(jìn)行評(píng)估;
UNCACHEABLE UNION:UNION 屬于不可緩存子查詢的中的第二個(gè)或更高版本的選擇(請(qǐng)參閱UNCACHEABLE SUBQUERY的參考資料 );
partitions
查詢分區(qū)的匹配記錄。如果未分區(qū)則為NULL;
table
顯示這一行的數(shù)據(jù)是關(guān)于哪張表的;
type
訪問類型排列, 顯示查詢使用了何種類型:
system:表只有一行記錄(等于系統(tǒng)表),這是const類型的特列,平時(shí)不會(huì)出現(xiàn),這個(gè)也可以忽略不計(jì)。
const:表示通過索引一次就找到了,const用于比較primary key或者unique索引。因?yàn)橹黄ヅ湟恍袛?shù)據(jù),所以很快 如將主鍵置于where列表中,MySQL就能將該查詢轉(zhuǎn)換為一個(gè)常量。
eq_ref:唯一性索引掃描,對(duì)于每個(gè)索引鍵,表中只有一條記錄與之匹配。常見于主鍵或唯一索引掃描。
ref:非唯一性索引掃描,返回匹配某個(gè)單獨(dú)值的所有行. 本質(zhì)上也是一種索引訪問,它返回所有匹配某個(gè)單獨(dú)值的行,然而, 它可能會(huì)找到多個(gè)符合條件的行,所以他應(yīng)該屬于查找和掃描的混合體。
fulltext:使用FULLTEXT 索引執(zhí)行聯(lián)接。
ref_or_null:這種連接類型類似于 ref,但是除了MySQL會(huì)額外搜索包含NULL值的行。
index_merge:此聯(lián)接類型指示使用索引合并優(yōu)化。在這種情況下,key輸出行中的列包含所用索引的列表,并key_len包含所用索引 的最長鍵部分的列表。有關(guān)更多信息,請(qǐng)參見 第8.2.1.3節(jié)“索引合并優(yōu)化”。
unique_subquery:此類型替換 以下形式的eq_ref某些 IN子查詢:value IN (SELECT primary_key FROM single_table WHERE some_expr),unique_subquery 只是一個(gè)索引查找函數(shù),它完全替代了子查詢以提高效率。
index_subquery:此連接類型類似于 unique_subquery。它代替IN子查詢,但適用于以下形式的子查詢中的非唯一索引:value IN (SELECT key_column FROM single_table WHERE some_expr)。
range:只檢索給定范圍的行,使用一個(gè)索引來選擇行。key 列顯示使用了哪個(gè)索引 一般就是在你的where語句中出現(xiàn)了between、<、>、in等的查詢 這種范圍掃描索引掃描比全表掃描要好,因?yàn)樗恍枰_始于索引的某一點(diǎn),而結(jié)束于另一點(diǎn),不用掃描全部索引。
index:Full Index Scan,index與ALL區(qū)別為index類型只遍歷索引樹。這通常比ALL快,因?yàn)樗饕募ǔ1葦?shù)據(jù)文件小(也就是說雖然all和Index都是讀全表,但index是從索引中讀取的,而all是從硬盤中讀的)。
all:Full Table Scan,將遍歷全表以找到匹配的行。備注:一般來說,得保證查詢至少達(dá)到range級(jí)別,最好能達(dá)到ref。
possible_keys
顯示可能應(yīng)用在這張表中的索引,一個(gè)或多個(gè)。 查詢涉及到的字段上若存在索引,則該索引將被列出,但不一定被查詢實(shí)際使用。
key
實(shí)際使用的索引。如果為NULL,則沒有使用索引。查詢中若使用了覆蓋索引,則該索引和查詢的select字段重疊。
key_len
表示索引中使用的字節(jié)數(shù),可通過該列計(jì)算查詢中使用的索引的長度。在不損失精確性的情況下,長度越短越好。key_len顯示的值為索引字段的最大可能長度,并非實(shí)際使用長度,即key_len是根據(jù)表定義計(jì)算而得,不是通過表內(nèi)檢索出的。
ref
顯示索引的哪一列被使用了,如果可能的話,是一個(gè)常數(shù)。哪些列或常量被用于查找索引列上的值。
rows
根據(jù)表統(tǒng)計(jì)信息及索引選用情況,大致估算出找到所需的記錄所需要讀取的行數(shù)。
Extra
包含不適合在其他列中顯示但十分重要的額外信息:
Using filesort:說明mysql會(huì)對(duì)數(shù)據(jù)使用一個(gè)外部的索引排序,而不是按照表內(nèi)的索引順序進(jìn)行讀取。MySQL中無法利用索引完成的排序操作稱為“文件排序”。
Using temporary:使用了臨時(shí)表保存中間結(jié)果,MySQL在對(duì)查詢結(jié)果排序時(shí)使用臨時(shí)表。常見于排序order by 和分組查詢 group by。
USING index:表示相應(yīng)的select操作中使用了覆蓋索引(Covering Index),避免訪問了表的數(shù)據(jù)行,效率不錯(cuò)! 如果同時(shí)出現(xiàn)using where,表明索引被用來執(zhí)行索引鍵值的查找; 如果沒有同時(shí)出現(xiàn)using where,表明索引用來讀取數(shù)據(jù)而非執(zhí)行查找動(dòng)作。
Using where:表明使用了where過濾。
using join buffer:使用了連接緩存。
impossible where:where子句的值總是false,不能用來獲取任何元素。
select tables optimized away:在沒有GROUPBY子句的情況下,基于索引優(yōu)化MIN/MAX操作或者對(duì)于MyISAM存儲(chǔ)引擎優(yōu)化COUNT(*)操作,不必等到執(zhí)行階段再進(jìn)行計(jì)算, 查詢執(zhí)行計(jì)劃生成的階段即完成優(yōu)化。
distinct:優(yōu)化distinct操作,在找到第一匹配的元組后即停止找同樣值的動(dòng)作
索引使用案例
最理想的情況

最佳左前綴原則
后臺(tái)創(chuàng)建的索引是name_sex_age的聯(lián)合索引,聯(lián)合索引中,從左往右匹配,如果最開始匹配不到,則索引失效。



盡量不用函數(shù)操作索引
在索引列上做任何操作(計(jì)算、函數(shù)、(自動(dòng)or手動(dòng))類型轉(zhuǎn)換),會(huì)導(dǎo)致索引失效而轉(zhuǎn)向全表掃描。

索引中范圍條件右邊的列不會(huì)被使用
下面這個(gè)聯(lián)合索引,當(dāng)聯(lián)合索引中間的值查詢條件為范圍查詢時(shí),右側(cè)的索引不會(huì)被用到。


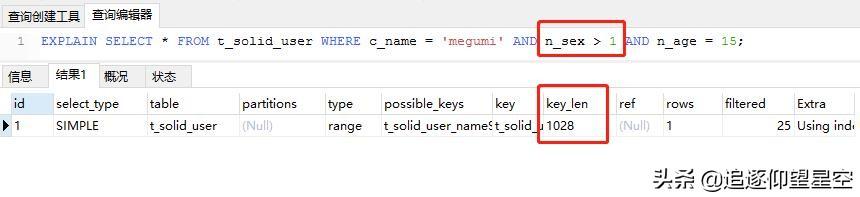
少用select *
盡量使用覆蓋索引(只訪問索引的查詢(索引列和查詢列一致)),減少select *。

索引失效的幾個(gè)情況
不等于(!= 或者<>)、is null、is not null 、or、like以通配符開頭(’%abc…’)、字符串不加單引號(hào)(類型轉(zhuǎn)換)
這就不貼圖了,沒啥可貼的,用了type就是ALL;
索引使用的總結(jié)建議
最后,給一個(gè)索引使用的總結(jié)吧:
對(duì)于單鍵索引,盡量選擇針對(duì)當(dāng)前query過濾性更好的索引。在選擇組合索引的時(shí)候,當(dāng)前Query中過濾性最好的字段在索引字段順序中,位置越靠前越好。在選擇組合索引的時(shí)候,盡量選擇可以能夠包含當(dāng)前query中的where字句中更多字段的索引。盡可能通過分析統(tǒng)計(jì)信息和調(diào)整query的寫法來達(dá)到選擇合適索引的目的。
作者:Solid-Snaker
原文鏈接:https://blog.csdn.net/jcSongle/article/details/106133005





