
BiLSTM+CRF 是命名實體識別中最為流行的模型,但是 LSTM 需要按順序處理輸入的序列,速度比較慢。而采用 CNN 可以更高效的處理輸入序列,本文介紹一種使用膨脹卷積進行命名實體識別的方法 IDCNN,通過膨脹卷積可以使模型接收更長的上下文信息。
1.膨脹卷積
膨脹卷積 (Dilated Convolution) 是指卷積核中存在空洞,下圖展示了膨脹卷積和傳統卷積的區別。之前的文章《膨脹卷積 dilated convolution》 有關于膨脹卷積的介紹,不熟悉的童鞋可以參考一下。
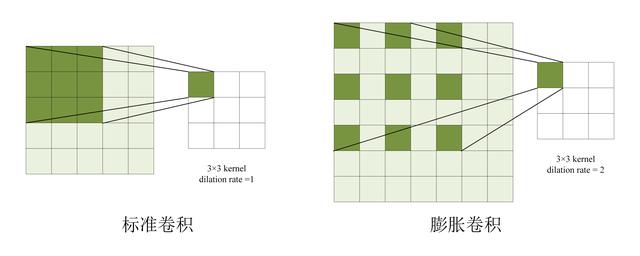
膨脹卷積和傳統卷積的區別
膨脹卷積通過在卷積核中增加空洞,可以擴大模型的感受野 (即句子中的上下文),從下圖可以看到,同樣是尺寸為 3 的卷積核,同樣是兩層卷積層,膨脹卷積的上下文大小為 7,而傳統卷積上下文大小為 5。

膨脹卷積和傳統卷積上下文大小
卷積核的膨脹系數 (即空洞的大小) 每一層是不同的,一般可以取 (1, 2, 4, 8, ...),即前一層的兩倍。
對于尺寸為 3 的傳統卷積核,第 L 層的上下文大小為 2L+1;而對于尺寸為 3 的膨脹卷積核,第 L 層上下文的大小是 2^(L+1) -1。因此膨脹卷積的上下文大小和層數是指數相關的,可以通過比較少的卷積層得到更大的上下文。
2.用膨脹卷積進行命名實體識別
論文《Fast and Accurate Entity Recognition with Iterated Dilated Convolutions》中提出了一種使用膨脹卷積的方法進行命名實體識別,IDCNN (Iterated Dilated Convolutions)。
作者認為直接堆疊膨脹卷積層,可以獲得很長距離的上下文信息,例如有 9 層膨脹卷積層,則上下文的寬度超過 1000。但是簡單的堆疊多層膨脹卷積,容易導致過擬合。
為了避免過擬合,作者先構造一個層數不多的膨脹 block,block 包含幾個膨脹卷積層,例如 4 個。然后把數據重復傳到同一個 block 中,即 block 輸出的結果又重復傳入 block 中,作者稱為 Iterated Dilated Convolutions,IDCNN。通過重復使用相同的 block,可以讓模型接收更寬的上下文信息,同時有比較好的泛化能力。
IDCNN 的膨脹卷積 block 包含多個膨脹卷積層,用 D 表示膨脹卷積層,如下面公式所示:

膨脹卷積層表示
IDCNN 網絡的第一層對輸入數據進行轉換,使用標準的卷積:

IDCNN 第一層對輸入進行轉換
后 IDCNN 會使用 Lc 個膨脹卷積層構造出 block,block 用 B() 表示,block 包含的膨脹卷積如下:
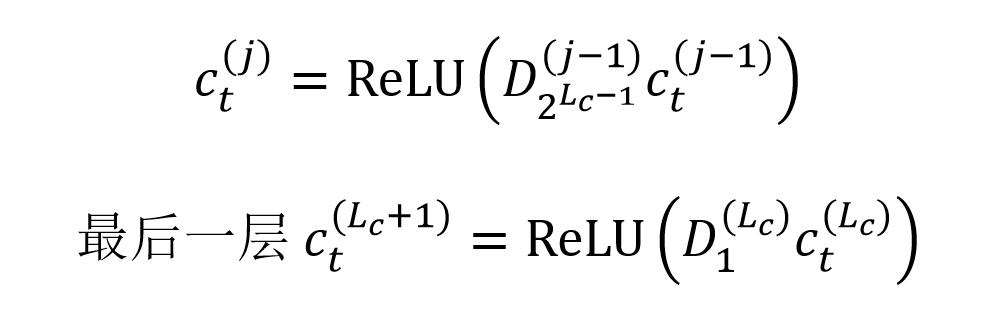
block 中包含 Lc 個膨脹卷積
IDCNN 會重復使用 Lb 次相同的 block,對數據進行處理,如下:
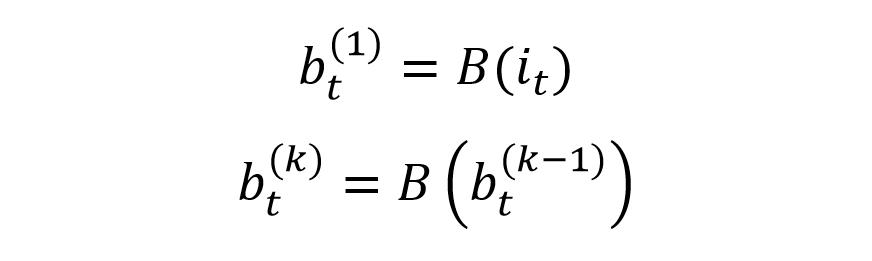
IDCNN 重復使用 Lb 次 block
最后一層的輸出再經過線性變換,可以得到序列每一個時刻 t 屬于不同類別的分數:
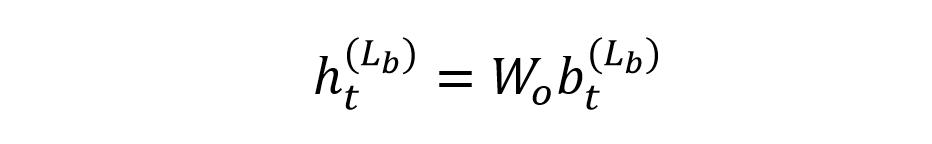
最后一層輸出線性變換
3.IDCNN 訓練
IDCNN 可以使用兩種訓練方式,第一種是利用最后一次 block 的輸出,預測每一時刻的類別,如下:

IDCNN 用最后一層 block 輸出進行預測
這種方法可以結合 CRF 進行訓練,類似 BiLSTM+CRF,因為 IDCNN 也可以輸出每一時刻屬于不同類別的概率。
第二種訓練方法是對于每一次 block 的輸出都預測序列的類標,作者認為這種方式可以起到類似 CRF 的效果,能夠把輸出結果之間的關系編碼到 IDCNN 中。例如假設執行兩次 block,則第一次 block 可以預測每一時刻對應不同類別的概率。而第二次 block 接收第一次 block 的輸出,可以預測每一時刻輸出之間的關系,類似 CRF。公式如下:
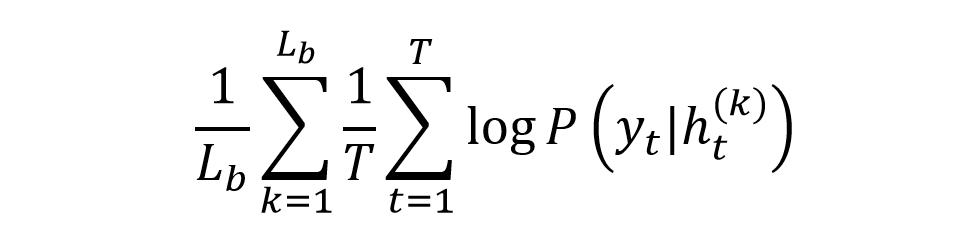
IDCNN 使用每一層 block 輸出進行預測
4.參考文獻
Fast and Accurate Entity Recognition with Iterated Dilated Convolutions





