
導讀:深度學習已經存在了幾十年,不同的結構和架構針對不同的用例而進行演變。其中一些是基于我們對大腦的想法,另一些是基于大腦的實際工作。本文將簡單介紹幾個業界目前使用的先進的架構。
作者:謝林·托馬斯(Sherin Thomas)、蘇丹舒·帕西(Sudhanshu Passi)
來源:華章科技

01 全連接網絡
全連接、密集和線性網絡是最基本但功能強大的架構。這是機器學習的直接擴展,將神經網絡與單個隱藏層結合使用。全連接層充當所有架構的最后一部分,用于獲得使用下方深度網絡所得分數的概率分布。
如其名稱所示,全連接網絡將其上一層和下一層中的所有神經元相互連接。網絡可能最終通過設置權重來關閉一些神經元,但在理想情況下,最初所有神經元都參與訓練。
02 編碼器和解碼器
編碼器和解碼器可能是深度學習另一個最基本的架構之一。所有網絡都有一個或多個編碼器–解碼器層。你可以將全連接層中的隱藏層視為來自編碼器的編碼形式,將輸出層視為解碼器,它將隱藏層解碼并作為輸出。通常,編碼器將輸入編碼到中間狀態,其中輸入為向量,然后解碼器網絡將該中間狀態解碼為我們想要的輸出形式。
編碼器–解碼器網絡的一個規范示例是序列到序列 (seq2seq)網絡(圖1.11),可用于機器翻譯。一個句子將被編碼為中間向量表示形式,其中整個句子以一些浮點數字的形式表示,解碼器根據中間向量解碼以生成目標語言的句子作為輸出。

▲圖1.11 seq2seq 網絡
自動編碼器(圖1.12)是一種特殊的編碼器–解碼器網絡,屬于無監督學習范疇。自動編碼器嘗試從未標記的數據中進行學習,將目標值設置為輸入值。
例如,如果輸入一個大小為100×100的圖像,則輸入向量的維度為10 000。因此,輸出的大小也將為 10 000,但隱藏層的大小可能為 500。簡而言之,你正在嘗試將輸入轉換為較小的隱藏狀態表示形式,從隱藏狀態重新生成相同的輸入。

▲圖1.12 自動編碼器的結構
你如果能夠訓練一個可以做到這一點的神經網絡,就會找到一個好的壓縮算法,其可以將高維輸入變為低維向量,這具有數量級收益。
如今,自動編碼器正被廣泛應用于不同的情景和行業。
03 循環神經網絡
循環神經網絡(RNN)是最常見的深度學習算法之一,它席卷了整個世界。我們現在在自然語言處理或理解方面幾乎所有最先進的性能都歸功于RNN的變體。在循環網絡中,你嘗試識別數據中的最小單元,并使數據成為一組這樣的單元。
在自然語言的示例中,最常見的方法是將一個單詞作為一個單元,并在處理句子時將句子視為一組單詞。你在整個句子上展開RNN,一次處理一個單詞(圖1.13)。RNN 具有適用于不同數據集的變體,有時我們會根據效率選擇變體。長短期記憶 (LSTM)和門控循環單元(GRU)是最常見的 RNN 單元。

▲圖1.13 循環網絡中單詞的向量表示形式
04 遞歸神經網絡
顧名思義,遞歸神經網絡是一種樹狀網絡,用于理解序列數據的分層結構。遞歸網絡被研究者(尤其是 Salesforce 的首席科學家理查德·索徹和他的團隊)廣泛用于自然語言處理。
字向量能夠有效地將一個單詞的含義映射到一個向量空間,但當涉及整個句子的含義時,卻沒有像word2vec這樣針對單詞的首選解決方案。遞歸神經網絡是此類應用最常用的算法之一。
遞歸網絡可以創建解析樹和組合向量,并映射其他分層關系(圖1.14),這反過來又幫助我們找到組合單詞和形成句子的規則。斯坦福自然語言推理小組開發了一種著名的、使用良好的算法,稱為SNLI,這是應用遞歸網絡的一個好例子。
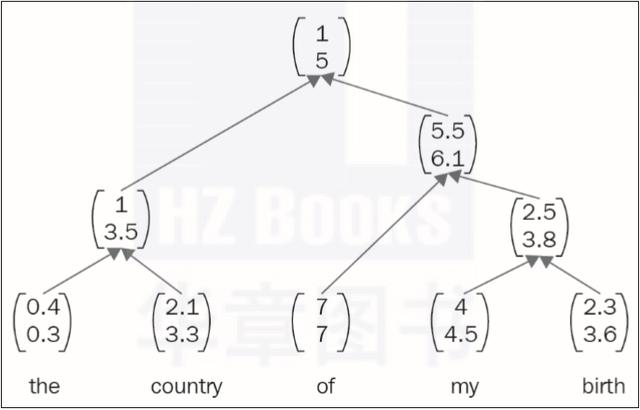
▲圖1.14 遞歸網絡中單詞的向量表示形式
05 卷積神經網絡
卷積神經網絡(CNN)(圖1.15)使我們能夠在計算機視覺中獲得超人的性能,它在2010年代早期達到了人類的精度,而且其精度仍在逐年提高。
卷積網絡是最容易理解的網絡,因為它有可視化工具來顯示每一層正在做什么。
Facebook AI研究(FAIR)負責人Yann LeCun早在20世紀90年代就發明了CNN。人們當時無法使用它,因為并沒有足夠的數據集和計算能力。CNN像滑動窗口一樣掃描輸入并生成中間表征,然后在它到達末端的全連接層之前對其進行逐層抽象。CNN也已成功應用于非圖像數據集。

▲圖1.15 典型的 CNN
Facebook的研究小組發現了一個基于卷積神經網絡的先進自然語言處理系統,其卷積網絡優于RNN,而后者被認為是任何序列數據集的首選架構。雖然一些神經科學家和人工智能研究人員不喜歡CNN(因為他們認為大腦不會像CNN那樣做),但基于CNN的網絡正在擊敗所有現有的網絡實現。
06 生成對抗網絡
生成對抗網絡(GAN)由 Ian Goodfellow 于 2014 年發明,自那時起,它顛覆了整個 AI 社群。它是最簡單、最明顯的實現之一,但其能力吸引了全世界的注意。GAN的配置如圖1.16所示。

▲圖1.16 GAN配置
在GAN中,兩個網絡相互競爭,最終達到一種平衡,即生成網絡可以生成數據,而鑒別網絡很難將其與實際圖像區分開。
一個真實的例子就是警察和造假者之間的斗爭:假設一個造假者試圖制造假幣,而警察試圖識破它。最初,造假者沒有足夠的知識來制造看起來真實的假幣。隨著時間的流逝,造假者越來越善于制造看起來更像真實貨幣的假幣。這時,警察起初未能識別假幣,但最終他們會再次成功識別。
這種生成–對抗過程最終會形成一種平衡。GAN 具有極大的優勢。
07 強化學習
通過互動進行學習是人類智力的基礎,強化學習是領導我們朝這個方向前進的方法。過去強化學習是一個完全不同的領域,它認為人類通過試錯進行學習。然而,隨著深度學習的推進,另一個領域出現了“深度強化學習”,它結合了深度學習與強化學習。
現代強化學習使用深度網絡來進行學習,而不是由人們顯式編碼這些規則。我們將研究Q學習和深度Q學習,展示結合深度學習的強化學習與不結合深度學習的強化學習之間的區別。
強化學習被認為是通向一般智能的途徑之一,其中計算機或智能體通過與現實世界、物體或實驗互動或者通過反饋來進行學習。訓練強化學習智能體和訓練狗很像,它們都是通過正、負激勵進行的。當你因為狗撿到球而獎勵它一塊餅干或者因為狗沒撿到球而對它大喊大叫時,你就是在通過積極和消極的獎勵向狗的大腦中強化知識。
我們對AI智能體也做了同樣的操作,但正獎勵將是一個正數,負獎勵將是一個負數。盡管我們不能將強化學習視為與 CNN/RNN 等類似的另一種架構,但這里將其作為使用深度神經網絡來解決實際問題的另一種方法,其配置如圖1.17所示。

▲圖1.17 強化學習配置
關于作者:謝林·托馬斯(Sherin Thomas)的職業生涯始于信息安全專家,后來他將工作重心轉移到了基于深度學習的安全系統。他曾幫助全球多家公司建立AI流程,并曾就職于位于印度班加羅爾的一家快速成長的初創公司CoWrks。
蘇丹舒·帕西(Sudhanshu Passi)是CoWrks的技術專家。在CoWrks ,他一直是機器學習的一切相關事宜的驅動者。在簡化復雜概念方面的專業知識使他的著作成為初學者和專家的理想讀物。
本文摘編自《PyTorch深度學習實戰》,經出版方授權發布。





