擊這里在線咨詢客服")
https://blog.csdn.net/weixin_43521592/article/details/106890179
5.3 Tesseract圖形驗(yàn)證碼識(shí)別
相信大家平時(shí)在登錄或者請求一些數(shù)據(jù)的時(shí)候經(jīng)常會(huì)遇到圖形驗(yàn)證碼,而我們爬蟲有時(shí)候就因?yàn)閳D形驗(yàn)證碼而手足無措,這一章通過學(xué)習(xí)Tesseract 來解決這個(gè)問題,使你的爬蟲之路更加的暢通無阻。
Tesseract是一個(gè)目前最優(yōu)秀最準(zhǔn)確的開源ORC庫,目前有谷歌贊助,可以經(jīng)過訓(xùn)練識(shí)別任何字體。
ORC 即Optical Character Recognition,光學(xué)字符識(shí)別,是指通過掃描字符,然后通過其形狀將其翻譯成電子文本的過程。
Tesseract 下載安裝:
第一步:下載Tesseract并安裝
windows系統(tǒng)下載地址:后臺(tái)回復(fù)“20200715”獲取下載鏈接
安裝過程中需要勾選一下下圖的操作,其他一直next即可

第二步:配置環(huán)境變量
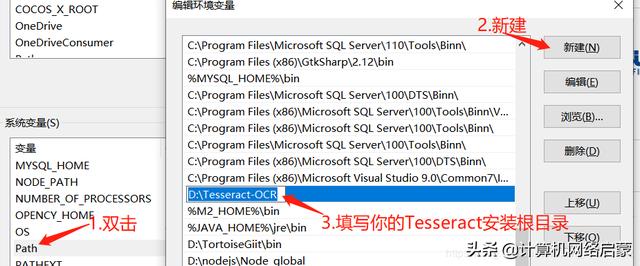
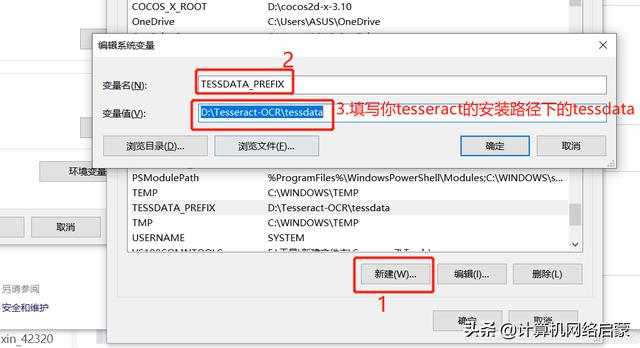
第三步:打開cmd,輸入 tesseract -v ,如果則輸入類似于下圖信息。

至此tesseract 就安裝好了。
終端操作tesseract
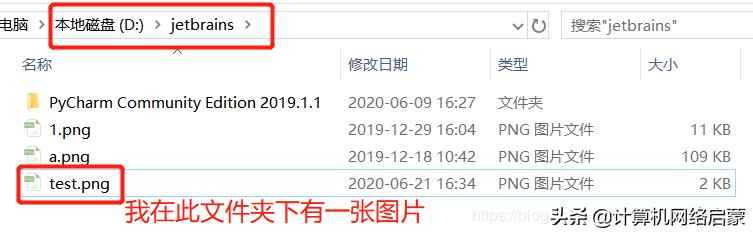

在此路徑下識(shí)別圖片:tesseract 圖片名稱 識(shí)別后文本的名稱

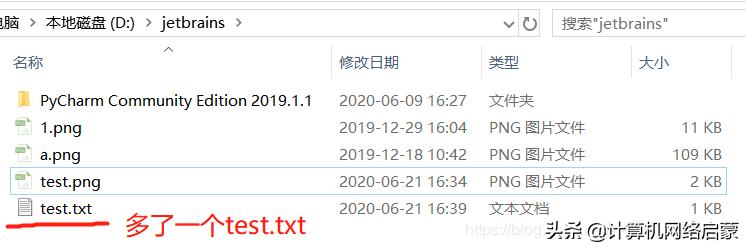

可以看出,tesseract識(shí)別這種白底黑字?jǐn)?shù)字的能力還是蠻高的。
Python中使用Tesseract
使用前需要安裝pip install pytesseract
另外,讀取圖片時(shí)需要借用一個(gè)第三方庫PIL ,可通過pip安裝pip install PIL 。
import pytesseract
from PIL import Image
# 打開圖片
image = Image.open(r'D:jetbrainstest.png')
# 將圖片轉(zhuǎn)為文字
text = pytesseract.image_to_string(image)
# 輸出文字
print(text)
自動(dòng)識(shí)別圖形驗(yàn)證碼方式
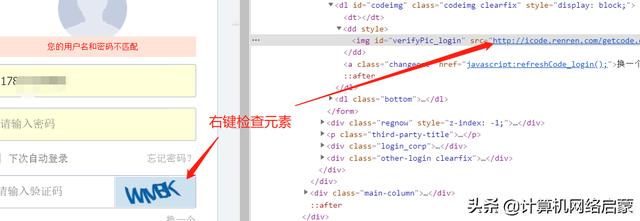
獲取到驗(yàn)證碼的url之后,你復(fù)制到瀏覽器中打開,你會(huì)發(fā)現(xiàn)每次刷新頁面圖形都會(huì)改變,那這就是圖形驗(yàn)證碼的url了,我們可以把它下載到本地,然后利用Image打開,接著用tesseract來識(shí)別。
但現(xiàn)在的反爬蟲機(jī)制越來越強(qiáng)了,圖形驗(yàn)證碼是越來越復(fù)雜,這時(shí)tesseract就顯得吃力了,而如何我們可以對其進(jìn)行訓(xùn)練的話那么它依舊會(huì)很強(qiáng)大,但是訓(xùn)練的過程比較難且復(fù)雜,所以我們可以借助專門搞這行的第三方平臺(tái)來幫助我們。
我們只需要按照第三方平臺(tái)規(guī)定的格式來發(fā)送圖片url及一些參數(shù),就可以很大幾率的識(shí)別出驗(yàn)證碼。
這次案例我們選擇阿里云上的圖形驗(yàn)證碼識(shí)別服務(wù),阿里云有給每個(gè)用戶免費(fèi)使用識(shí)別圖形的機(jī)會(huì),所以對于平時(shí)偶爾爬爬蟲的小伙伴來說是個(gè)不錯(cuò)的選擇。

下面來看代碼如何獲取:
import requests
# 圖形驗(yàn)證碼的url
yzm_url = '"http://icode.renren.com/getcode.do?t=web_login&rnd=0.48174523967288096"'
#IMAGE_TYPE 為 1代表圖像內(nèi)容為圖像文件URL鏈接 0代表圖像內(nèi)容為BASE64編碼;
bodys = {"IMAGE": yam_url,
"IMAGE_TYPE": "1"}
# 固定格式
recognize_url = 'http://codevirify.market.alicloudapi.com/icredit_ai_image/verify_code/v1'
# 購買成功后可以在訂單那里查看Appcode
headers = {
"Content-Type":"application/x-www-form-urlencoded; charset=utf-8",
"Authorization":"APPCODE 5222ba0966de4f4ebb0ac0a5b3f8064a"}
# 傳參
response = requests.post(recognize_url,data=bodys,headers=headers)
print(response.json())
結(jié)果為:
{
‘VERIFY_CODE_STATUS’: ‘艾科瑞特,讓企業(yè)業(yè)績長青’,
’ VERIFY_CODE_ENTITY’: {‘VERIFY_CODE’: ‘WFKPT’}
}
其中 VERIFY_CODE里面加粗的內(nèi)容就是我們所需要的驗(yàn)證碼的內(nèi)容。
所以,一般你要改的就是yzm_url,IMAGE_TYPE 、Authorization的APPCODE 。具體可以查看該商品的API接口:智能圖像分析-通用驗(yàn)證碼識(shí)別-艾科瑞特





