擊這里在線咨詢客服")
Scrapy基本介紹
scrapy是一種用于爬蟲(chóng)的框架,并提供了相當(dāng)成熟的模板,大大減少了程序員在編寫(xiě)爬蟲(chóng)時(shí)的勞動(dòng)需要。
Command line tool & Project structure
使用scrapy需要先創(chuàng)建scrapy project,之后再于project文件夾路徑下生成spider(爬蟲(chóng))文件,編寫(xiě)完程序后,再運(yùn)行爬蟲(chóng)(手動(dòng)指定保存文件)。以上過(guò)程由命令行執(zhí)行,具體如下:
- scrapy startproject <myproject>
- scrapy genspider <spider_name> <domain>
- scrapy crawl <spider_name> [-o filename]
后面兩個(gè)命令均要在myproject文件夾(第一個(gè)myproject)路徑下執(zhí)行。而由第一個(gè)命令創(chuàng)建的scrapy項(xiàng)目結(jié)構(gòu)如下:
myproject/
scrapy.cfg
myproject/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.py
spider_name.py
Scrapy Overview
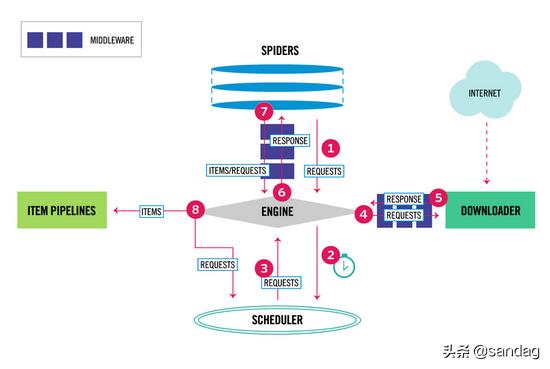
上圖是scrapy的基本結(jié)構(gòu),易見(jiàn)scrapy的程序執(zhí)行和數(shù)據(jù)流動(dòng)是由 engine 來(lái)調(diào)度控制的,關(guān)于該結(jié)構(gòu)的具體解釋見(jiàn): scrapy document overview .
Scrapy Spider詳解
基礎(chǔ)的使用scrapy一般只需要在spider_name.py中進(jìn)行編寫(xiě),該文件是我們使用scrapy genspider <spider_name>命令后自動(dòng)創(chuàng)建中,文件中還自動(dòng)import了scrapy并且還自動(dòng)創(chuàng)建了一個(gè)模版spider類(lèi)(自動(dòng)繼承自scrapy.Spider)。spider的功能簡(jiǎn)介于此: scrapy document spider 。這里介紹一些常用的scray.Spider類(lèi)的屬性及方法:
Attribute :
name :name屬性即是我們使用命令行時(shí)所指定的spider_name,這是scrapy框架中用于標(biāo)識(shí)spider所用,每個(gè)spider都必須有一個(gè)獨(dú)一無(wú)二的name。
allowed_domains :該屬性為一個(gè)以string為元素的list,每個(gè)元素string為一個(gè)domain,限定爬蟲(chóng)所能爬取的網(wǎng)址。
start_urls :該屬性同樣為一個(gè)以string為元素的list,每個(gè)元素string對(duì)應(yīng)一個(gè)完整的url,是spider開(kāi)始時(shí)需要爬取的初始網(wǎng)址。
custom_settings :該屬性的形式為一個(gè)dict,即如修改user-agent,開(kāi)啟pipeline,指定log_level之類(lèi)的,并且局限于http header。
method :
start_requests :該方法用于在scrapy開(kāi)始爬蟲(chóng)時(shí)以start_urls返回一個(gè)Request iterable或者一個(gè)generator,該方法在一次爬蟲(chóng)過(guò)程中僅被調(diào)用一次。其默認(rèn)實(shí)現(xiàn)為:Request(url, dont_filter=True) for each url in start_urls。
parse :這是spider類(lèi)中最重要的一個(gè)方法。由scrapy文檔中對(duì)spider的介紹,spider每發(fā)出一個(gè)Request,便要對(duì)該Request的Response進(jìn)行處理,處理的函數(shù)稱(chēng)為callback function,即 one Request corresponds to one Callback。而parse就是默認(rèn)的callback函數(shù),它負(fù)責(zé)對(duì)傳回的response進(jìn)行解析(xpath),提取數(shù)據(jù)(item dict-like object)并交予,并且還會(huì)根據(jù)需要發(fā)出新的Request請(qǐng)求。和start_requests一樣,它的返回值也需要是一個(gè)iterable或是一個(gè)generator。一般來(lái)說(shuō),先yield item,再根據(jù)對(duì)response的解析得到新的url與yield Request(url,callback)。這里對(duì)于response的解析和數(shù)據(jù)提取交予過(guò)程略過(guò),具體可以見(jiàn)于 b站教程 。
由以上介紹可見(jiàn)對(duì)于start_request和parse方法的返回值要求,scrapy框架的內(nèi)部代碼邏輯應(yīng)該是像for循環(huán)一樣輪詢兩者的返回值,對(duì)于parse方法還需要判斷其返回值的類(lèi)型(item/Request)來(lái)區(qū)別處理。
Scrapy Request and Response
Typically, Request objects are generated in the spiders and pass across the system until they reach the Downloader, which executes the request and returns a Response object which travels back to the spider that issued the request.
Request object
scrapy.Request(url,callback,method="GET",headers=None,body=None,cookies=None,meta=None,..,dont_filter=False)
- 其中url參數(shù)即為我們想要爬取網(wǎng)站的url
- callback為該request對(duì)應(yīng)的在返回response時(shí)的處理函數(shù)
- method是http請(qǐng)求方法,常用的有:"GET","POST"
- headers是請(qǐng)求頭,形式為dict
- body是http請(qǐng)求的請(qǐng)求數(shù)據(jù),即一般的表單數(shù)據(jù),形式為bytes字符串
- cookies形式為dict
- 這里先講dont_filter,默認(rèn)值為False,scrapy中默認(rèn)對(duì)于同一url是不重復(fù)爬取的,所以會(huì)把相同的url給filter掉,而有時(shí)我們需要爬取同一url(如爬取某個(gè)不斷更新的論壇頁(yè)面),就需要把該值設(shè)為T(mén)rue
- meta The initial values for the Request.meta attribute. If given, the dict passed in this parameter will be shallow copied.該參數(shù)也是字典形式,是為了在spider類(lèi)的多個(gè)parse函數(shù)之間傳遞信息,見(jiàn) 知乎 。 注意Response對(duì)象也有一個(gè)它對(duì)應(yīng)的Request對(duì)象 :The Request object that generated this response. This attribute is assigned in the Scrapy engine, after the response and the request have passed through all Downloader Middlewares In particular, this means that:HTTP redirections will cause the original request (to the URL before redirection) to be assigned to the redirected response (with the final URL after redirection).Response.request.url doesn’t always equal Response.urlThis attribute is only available in the spider code, and in the Spider Middlewares, but not in Downloader Middlewares (although you have the Request available there by other means) and handlers of the response_downloaded signal.But Unlike the Response.request attribute, the Response.meta attribute is propagated along redirects and retries, so you will get the original Request.meta sent from your spider.
Response obejct
這里僅介紹一些reponse對(duì)象的屬性:
- url 即該response的來(lái)源url
- status 即該response的狀態(tài)碼
- headers response的響應(yīng)頭,形式為dict
- body response的相應(yīng)數(shù)據(jù)體,形式為bytes
- request response對(duì)應(yīng)的Request對(duì)象,對(duì)于它上文已經(jīng)介紹,即Response.url可能不等于Reponse.request.url,因?yàn)閞edirection的原因
Settings
Settings can be populated using different mechanisms, each of which having a different precedence. Here is the list of them in decreasing order of precedence:
- Command line options (most precedence)
- Settings per-spider
- Project settings module(settings.py)
- Default settings per-command
- Default global settings (less precedence)
一般我們直接在settings.py文件中對(duì)其進(jìn)行修改,常見(jiàn)需要增改的有:user-agent指定,ITEM_PIPELINES解除注釋以開(kāi)啟pipeline功能,LOG_LEVEL和LOG_FILE指定,ROBOTSTXT_OBEY設(shè)為False等等。





