
一、前言
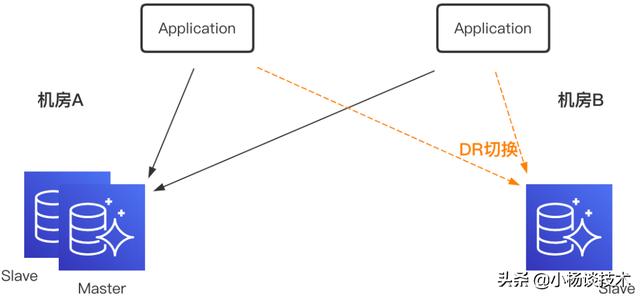
攜程內部MySQL部署采用多機房部署,機房A部署一主一從,機房B部署一從,作為DR(Disaster Recovery)切換使用。當前部署下,機房B部署的應用需要跨機房進行寫操作;當機房A出現故障時,DBA需要手動對數據庫進行DR切換。
為了做到真正的數據異地多活,實現MySQL同機房就近讀寫,機房故障時無需進行數據庫DR操作,只進行流量切換,就需要引入數據實時雙向(多向)復制組件。
二、DRC 介紹
DRC(Data Replicate Center)是攜程框架架構研發部推出的用于數據雙向或多向復制的數據庫中間件,在公司G2(高品質Great Service、全球化Globalization)戰略的背景下,服務于異地多活項目,賦予了業務全球化的部署能力。
三、DRC 架構設計
DRC采用服務端集中化設計,配合另一數據庫訪問中間件DAL(Data Access Layer)的本地讀寫功能,實現數據就近訪問。

模塊介紹
- Replicator Container
Replicator Container 實現對 Replicator 實例的管理,一個 Replicator 實例表示對一個MySQL集群的復制單元,Instance將自己偽裝為MySQL的Slave,實現Binlog的拉取和本地存儲。
- Applier Container
Applier Container實現對Applier 實例的管理,一個Applier 實例連接到一個Replicator 實例,實現對Replicator 實例本地存儲Binlog的拉取,進而解析出SQL語句并應用到目標MySQL,從而實現數據的復制。
- Cluster Manager
Cluster Manager負責集群高可用切換,包括由于MySQL主從切換導致的Replicator 實例和Applier 實例重啟,以及Replicator 實例與Applier 實例自身主從切換引起的新實例啟動通知。
- Console
Console提供UI操作、外部系統交互API以及監控告警。
四、DRC 詳細設計
4.1 接入DB規范
DRC的核心指標包括復制延遲和數據一致性。
為了實現數據復制的低延遲,Applier能夠快速應用SQL,就需要每個表至少包含主鍵或者唯一鍵,加速執行效率;同時在保證數據準確的前提下,SQL應該盡量并行復制,需要MySQL開啟從5.7.22版本引入的Writeset功能。
為了保證數據復制的準確性,在主備切換時Replicator仍能準確定位Binlog位點,需要MySQL開啟GTID;當數據復制發生沖突時,為了具備自動解決沖突的能力,需要表包含時間戳列,并精確到毫秒。
這就需要接入DRC的MySQL數據庫滿足:
1)5.7.22及以上版本;
2)Master上開啟Writeset并行復制;
3)MySQL開啟GTID;
4)每個表包含時間戳列,精確到毫秒;
5)每個表至少包含主鍵或者唯一鍵。
DRC的復制依賴GTID(Global Transaction ID),這里先簡單介紹一下GTID的概念。MySQL 5.6.5版本新增了一種基于GTID的復制方式,強化了數據庫的主備一致性,故障恢復以及容錯能力,取代傳統的基于file和position主從復制,使得在MySQL主備切換時,仍能準確定位到Binlog位點。
GTID的格式形如:source_id:transaction_id,其中source_id表示MySQL服務器的uuid,transaction_id是在事務提交的時候系統順序分配的一個序列號。
4.2 Binlog 復制
單向復制鏈路包含拉取Binlog并持久化到本地磁盤的Replicator,和請求Binlog且并行應用到目標MySQL的Applier。整個鏈路涉及的I/O操作包括網絡傳輸和磁盤讀寫。

4.2.1 低復制延遲
為了降低復制延遲,就要求復制鏈路中每一環都盡可能高效。網絡層通信模型使用異步I/O;系統層盡可能使用操作系統提供的Zero Copy和Page Cache;應用層提高數據處理并行度以及降低系統不可用時間。
監控顯示生產環境業務雙向復制延遲999線 < 1s。下面就介紹一下DRC在降低復制延遲方面所做的性能優化工作。

1)網絡層
Replicator采用GTID復制方式,實現了MySQL復制協議,偽裝成源MySQL的Slave拉取Binlog。網絡層通信組件采用攜程開源組件XPipe(
http://github.com/ctripcorp/x-pipe),實現網絡交互異步化。
2)系統層
接收Binlog時,從數據流中解析出不同類型的Event,直接保存在堆外內存。每個Event需要經過一組過濾器,進而決定是否需要落盤持久化。對于Heartbeat類型的Event需要過濾丟棄;針對某些不需要進行數據同步的庫和表,需要丟棄相應Event,減少存儲量和傳輸量;對于需要持久化的Event,直接將堆外內存中的數據寫入文件Page Cache并定時刷入磁盤,減少數據復制和IO操作,降低處理耗時,提升Replicator拉取效率。
發送Binlog時,當Applier進度落后Replicator,需要從磁盤讀取,這時只解析gtid_event事件,其他需要發送的事件直接從磁盤讀取到堆外內存進行發送,減少數據復制。
3)應用層
Applier借鑒原生MySQL基于Writeset的并行復制,內嵌了基于水位的并行算法,高效的將SQL應用到目標數據庫。
除去正常復制之外,為了降低系統的不可用時間,就需要系統在異常情況下,盡快恢復正常功能。比如斷網恢復時,為了避免一端使用老連接,就需要對連接進行空閑檢測;為了應對斷網導致數據堆積出現流量突增,就需要對流量進行控制。
4)空閑檢測
Replicator與MySQL、Applier和Replicator通過Netty進行數據傳輸,當網絡出現故障,可能一端仍然使用老連接進行通信,會導致數據復制出現中斷。
針對網絡故障,Replicator對MySQL添加了讀空閑檢測,啟動時設置MySQL空閑時間隔10s發送一次heartbeat_event,如果30s沒有收到MySQL任何事件,則認為MySQL出現問題,發起重連。
Replicator對Applier設置了寫空閑檢測,當沒有Event需要發送給Applier時,間隔10s發送一次heartbeat_event,如果發送失敗,則認為Applier出現問題,斷開連接。
Applier對Replicator設置了讀空閑檢測,如果30s沒有收到Replicator任何事件,則認為Replicator出現問題,發起重連。
5)流量控制
設計上Replicator Container使用物理機,其中會運行若干Replicator實例,Applier Container使用虛擬機,這樣會造成發送和消費的速率不匹配。尤其當Applier由于某種原因出現故障后,在Replicator端堆積大量未消費的Event,重啟后如果堆積的Event全部發送過來,可能會直接打垮Applier,這樣就需要在Replicator實例上對Applier進行限流。
Replicator發送端使用Netty提供的WRITE_BUFFER_WATER_MARK高低水位的變化來控制流控的開關,進而動態調整發送速率,整形平滑流量。
4.2.2 數據一致性
為了保證數據的一致,就需要滿足:
1)數據拉取時保證時序;
2)數據拉取不能遺漏,SQL應用時不重,或者即使重復,要保證冪等操作,保證At Least Once;
3)數據沖突時,能正確處理,保證數據最終一致。
下面就看下DRC是如何保證以上3個要求。
1)時序保證
本地磁盤保存Binlog采用原生的存儲協議,Replicator順序處理接收到每一個Event事件。存儲協議兼容MySQL原生的mysqlbinlog命令,其中根據DRC自身的需要,保存了自定義的一些輔助事件,比如DDL事件,表結構事件。消費時順序發送Binlog文件中的事件給Applier。

2)At Least Once
為了實現At Least Once,需要解決3個子問題:
1)Replicator或者Applier重啟時,如何保證請求的GTID set準確體現目前的消費偏移?
2)雙向(多向)復制如何解決循環復制?
3)Applier由于異常重復拉取時,如何保證冪等?
下面逐一介紹每個子問題的解決方案。
斷點重續
當Replicator重啟時,會從本地磁盤中恢復已經拉取過的GTID set:
1)定位重啟前使用的最后一個Binlog文件;
2)解析出previous_gtids_event;
3)遍歷該文件的所有gtid_event,與previous_gtids_event解析出的GTID set取并集。
恢復過程中,會校驗文件的正確性,對于沒有以xid_event結束的事務,Replicator會對文件進行截斷,對應的gtid事務會重新請求。
當Applier重啟時,Cluster Manager會從目標數據庫中查詢出當前已經執行過的GTID set發送給Applier,Applier帶著該參數向Replicator發送Binlog拉取請求。Replicator收到請求中的GTID set,從本地磁盤中定位出第一個需要發送的Event所在的Binlog文件,依次遍歷該文件中的每一個Event,針對gtid_event事件取出其中的gtid,判斷該gtid對應的事務是否包含在GTID set中,如果包含其中,則表示Applier已經消費過,無需發送,否則通過堆外內存直接將Event發送給Applier。
循環復制
單向復制時,經過DRC復制到對端的SQL在執行后,同樣會落到MySQL的Binlog中,這樣在雙向(多向)復制結構中,對端的Replicator Instance在拉取到該條Binlog后如果繼續復制,就會出現循環復制的問題。
針對循環復制,業內可選的解決方案是在Binlog事務開頭插入一條寫操作,標識出該條事務是DRC復制過來,而不是真實業務寫入,這樣對端Replicator發現一個事務開頭包含DRC特殊標記時,就不會繼續復制該事務。
分析MySQL自身主從復制,Slave在收到Master同步過來的Binlog時,通過set gtid_next將該事務的GTID設置為同步過來的gtid_event中的GTID,這樣就實現了主從GTID set的一致性。
如果將Replicator拉取Binlog類比為Slave的I/O線程,磁盤文件類比為Relay log,Applier類比為Slave的SQL線程,那么Applier是可以采用同樣的方式,使用set gtid_next設置經過DRC復制到對端事務的GTID,這樣源和目標數據庫的GTID set會保持一致,更重要的是可以標識出該事務是經DRC復制過來的。這也是DRC最終采用的破解循環復制的方案。
如下雙向復制結構,Replicator Instance1只會同步源MySQL集群uuidSet1中的服務器產生事務,Replicator Instance2只會同步目標MySQL集群uuidSet2中的服務器產生事務。如果業務在源MySQL集群寫入一條數據,Replicator Instance1從gtid_event中的GTID解析出uuid屬于uuidSet1,那么會持久化到磁盤并發送給Applier Instance1,Applier Instance1接收到事務中包含的所有Event后,執行set gtid_next=GTID,然后通過JDBC將SQL寫入目標MySQL,完成單向復制;Replicator Instance2接收到gtid_event后,同樣解析出GTID,但是uuid并不屬于uuidSet2,這樣該條事務就會被過濾,從而避免的循環復制。

冪等
Applier如果重復接收到相同GTID的事務,由于MySQL會記錄已經執行的GTID set,如果該GTID已經被執行,則會自動忽略,這樣即使Applier重復應用同一條事務,也不會對業務產生影響。
小結
從上面可以看到,在保證數據一致性時,GTID不論是在Replicator和Applier重啟后Binlog位點定位,標識Binlog來源避免循環復制,還是Applier重復應用時冪等實現,都起到了至關重要的作用。
3)沖突解決
設計上,首先要避免沖突的出現:
1)接入Set化的業務在流量入口處就會根據uid進行分流,同一個用戶的流量進入同一個機房;數據接入層中間件DAL同樣會采用local-2-local的路由策略。這樣同一條記錄在2個機房同時被修改的情況很少發生;
2)對于使用自增ID的業務,通過不同機房設置不同的自增ID規則,或者采用分布式全局ID生成方案,避免雙向復制后數據沖突。
如果數據確實出現了沖突,2個機房對同一條數據進行的修改,這時需要根據沖突處理策略進行處理:
1)Applier根據默認的沖突處理策略進行處理,接入DRC的表都有一個精確到毫秒自動更新的時間戳,沖突時時間戳靠后的會被采用,進而實現數據的一致;
2)沖突的SQL會被監控記錄,連同數據庫中的原始數據同時提供給用戶,進而自助決定是否需要進行覆蓋。
4.3 DDL 支持
DDL操作會引起表結構的變更,在復制鏈路中Applier需要表結構信息解析對應時刻的Binlog Event,當Applier消費速率落后Replicator的發送速率時,就需要歷史版本的表結構信息才能夠正確解析Binlog Event。這就引入了表結構設計第一個問題:歷史版本如何存儲?
為了存儲表結構,勢必首先要獲得表結構,如果從源MySQL直接抓取表結構,由于Binlog是異步發送,就導致抓取到DDL的Binlog時刻,與MySQL上表結構未必能夠一一對應,從而引起Applier解析出現問題,進而導致數據不一致。這就引入表結構設計第二個問題:表結構從何處抓取?
業界通用的解決方案是基于獨立的第3方數據庫進行表結構單獨存儲管理。數據庫本身就是存儲工具,Snapshot表和DDL表分別保存表結構快照和DDL變更記錄,這樣任意時刻的表結構等于Snapshot及其后DDL變更集合,則第一個表結構存儲問題順其自然得以解決;獨立數據庫鏡像一份源數據庫的庫表結構,每次從Binlog接收到DDL Event后,將解析出的DDL語句直接應用到鏡像數據庫,隨即抓取相應表結構即可,這樣就解決了第二個表結構從何處抓取的問題。

獨立數據庫解決方案的缺點是引入外部依賴,降低了系統的可用性,提高了運維成本。
4.3.1 表結構存儲和計算
針對DDL功能中問題一:
從數據庫中查詢Snapshot和DDL記錄的好處是時間順序容易確定,能夠簡單準確的恢復表結構。那么是否有其他存儲介質,在保存表結構快照和DDL操作的同時,能夠保證時序呢?有,保存Binlog的文件就具有這種特性,DRC采用了這種基于Binlog的表結構文件存儲方案。
針對DDL功能中問題二:
鏡像數據庫是為了實時計算出DDL變更后最新的表結構信息,在存儲不使用獨立部署的數據庫后,DRC引入嵌入式輕量數據庫,降低外部依賴和系統運維成本。
這樣整體的設計方案如下圖所示:

Binlog文件頭會保存自定義表結構快照事件,當從接收的Event事件檢測到DDL后,保存為自定義的DDL事件。這樣當Applier連接上Replicator后,總是會根據GTID set定位到需要的第一個歷史版本表結構所在的文件,從而實時恢復表結構歷史,用于后續Binlog Event的解析。
我們將數據庫最小依賴打成獨立的Jar包服務,每個Replicator實例啟動時,會一并啟動一個獨立的嵌入式數據庫,在恢復GTID set的同時,根據表結構快照事件和DDL事件重建嵌入式數據庫中表結構。
4.3.2 DDL 入口
攜程內部發布DDL是通過gh-ost進行變更,gh-ost會在影子表中執行DDL操作,等影子表中數據同步完成后,業務低峰期進行原表和影子表的切換。
針對gh-ost,需要追蹤gh-ost變更過程中內部形如_xxx_gho的表的DDL所有操作,最終執行切換時檢測出rename操作,保存對應表結構最新信息發送給Applier即可。
同時針對數據庫直接進行的DDL操作,直接檢測出DDL類型的Event即可。
4.3.3 DDL 異常處理
對于接入DRC的數據庫,當在進行DDL變更時,可能會出現兩邊數據庫變更不同步,單側進行了DDL變更,另一側未進行變更。針對新增列這種場景,Applier在保證數據一致的前提下,對新增列的值進行比較,如果Binlog中解析出的值和該列的默認值一致,則會剔除該列,繼續數據復制。這樣在另一側補上DDL變更后,兩側的數據最終仍然一致。
4.4 監控告警
DRC核心指標包括復制延遲和數據一致性。除此之外我們還提供BU、應用和IDC維度的監控:
1)流量和TPS監控告警;
2)BU、應用和IDC維度的監控告警;
3)DDL變更監控;
4)表結構一致性監控告警;
5)數據沖突監控;
6)GTID set GAP監控。
五、總結
本次分享圍繞DRC的核心指標復制延遲和數據一致性,介紹了復制過程中對性能的優化以及各種場景如何保證數據的一致性。針對DDL,分別支持gh-ost和直接DDL操作,實現在線表結構變更不影響數據復制。





