一致性算法
Paxos
Paxos 算法解決的問題是一個分布式系統如何就某個值(決議)達成一致。一個典型的場景是,在一個分布式數據庫系統中,如果各節點的初始狀態一致,每個節點執行相同的操作序列,那么他們最后能得到一個一致的狀態。為保證每個節點執行相同的命令序列,需要在每一條指令上執行一個“一致性算法”以保證每個節點看到的指令一致。zookeeper 使用的 zab 算法是該算法的一個實現。 在 Paxos 算法中,有三種角色:Proposer,Acceptor,Learners。
Paxos 三種角色:Proposer,Acceptor,Learners
Proposer:
只要 Proposer 發的提案被半數以上 Acceptor 接受,Proposer 就認為該提案里的 value 被選定了。
Acceptor:
只要 Acceptor 接受了某個提案,Acceptor 就認為該提案里的 value 被選定了。
Learner:
Acceptor 告訴 Learner 哪個 value 被選定,Learner 就認為那個 value 被選定。
Paxos 算法分為兩個階段。具體如下:
階段一(準 leader 確定 ):
(a) Proposer 選擇一個提案編號 N,然后向半數以上的 Acceptor 發送編號為 N 的 Prepare 請求。
(b) 如果一個 Acceptor 收到一個編號為 N 的 Prepare 請求,且 N 大于該 Acceptor 已經響應過的所有 Prepare 請求的編號,那么它就會將它已經接受過的編號最大的提案(如果有的話)作為響應反饋給 Proposer,同時該 Acceptor 承諾不再接受任何編號小于 N 的提案。
階段二(leader 確認):
(a) 如果 Proposer 收到半數以上 Acceptor 對其發出的編號為 N 的 Prepare 請求的響應,那么它就會發送一個針對[N,V]提案的 Accept 請求給半數以上的 Acceptor。注意:V 就是收到的響應中編號最大的提案的 value,如果響應中不包含任何提案,那么 V 就由 Proposer 自己決定。
(b) 如果 Acceptor 收到一個針對編號為 N 的提案的 Accept 請求,只要該 Acceptor 沒有對編號大于 N 的 Prepare 請求做出過響應,它就接受該提案。
Zab
ZAB( ZooKeeper Atomic Broadcast , ZooKeeper 原子消息廣播協議)協議包括兩種基本的模式:崩潰恢復和消息廣播
1. 當整個服務框架在啟動過程中,或是當 Leader 服務器出現網絡中斷崩潰退出與重啟等異常情況時,ZAB 就會進入恢復模式并選舉產生新的 Leader 服務器。
2. 當選舉產生了新的 Leader 服務器,同時集群中已經有過半的機器與該 Leader 服務器完成了狀態同步之后,ZAB 協議就會退出崩潰恢復模式,進入消息廣播模式。
3. 當有新的服務器加入到集群中去,如果此時集群中已經存在一個 Leader 服務器在負責進行消息廣播,那么新加入的服務器會自動進入數據恢復模式,找到 Leader 服務器,并與其進行數據同步,然后一起參與到消息廣播流程中去。
以上其實大致經歷了三個步驟:
1.崩潰恢復:主要就是 Leader 選舉過程
2.數據同步:Leader 服務器與其他服務器進行數據同步
3.消息廣播:Leader 服務器將數據發送給其他服務器
說明:zookeeper 章節對該協議有詳細描述。
Raft
與 Paxos 不同 Raft 強調的是易懂(Understandability),Raft 和 Paxos 一樣只要保證 n/2+1 節點正常就能夠提供服務;raft 把算法流程分為三個子問題:選舉(Leader election)、日志復制(Log replication)、安全性(Safety)三個子問題。
角色
Raft 把集群中的節點分為三種狀態:Leader、 Follower 、Candidate,理所當然每種狀態負責的任務也是不一樣的,Raft 運行時提供服務的時候只存在 Leader 與 Follower 兩種狀態;
Leader(領導者-日志管理)
負責日志的同步管理,處理來自客戶端的請求,與 Follower 保持這 heartBeat 的聯系;
Follower(追隨者-日志同步)
剛啟動時所有節點為Follower狀態,響應Leader的日志同步請求,響應Candidate的請求,把請求到 Follower 的事務轉發給 Leader;
Candidate(候選者-負責選票)
負責選舉投票,Raft 剛啟動時由一個節點從 Follower 轉為 Candidate 發起選舉,選舉出Leader 后從 Candidate 轉為 Leader 狀態;
Term(任期)
在 Raft 中使用了一個可以理解為周期(第幾屆、任期)的概念,用 Term 作為一個周期,每個 Term 都是一個連續遞增的編號,每一輪選舉都是一個 Term 周期,在一個 Term 中只能產生一個 Leader;當某節點收到的請求中 Term 比當前 Term 小時則拒絕該請求。
選舉(Election)
選舉定時器
Raft 的選舉由定時器來觸發,每個節點的選舉定時器時間都是不一樣的,開始時狀態都為Follower 某個節點定時器觸發選舉后 Term 遞增,狀態由 Follower 轉為 Candidate,向其他節點發起 RequestVote RPC 請求,這時候有三種可能的情況發生:
1:該 RequestVote 請求接收到 n/2+1(過半數)個節點的投票,從 Candidate 轉為 Leader,向其他節點發送 heartBeat 以保持 Leader 的正常運轉。
2:在此期間如果收到其他節點發送過來的 AppendEntries RPC 請求,如該節點的 Term 大則當前節點轉為 Follower,否則保持 Candidate 拒絕該請求。
3:Election timeout 發生則 Term 遞增,重新發起選舉
在一個 Term 期間每個節點只能投票一次,所以當有多個 Candidate 存在時就會出現每個Candidate 發起的選舉都存在接收到的投票數都不過半的問題,這時每個 Candidate 都將 Term遞增、重啟定時器并重新發起選舉,由于每個節點中定時器的時間都是隨機的,所以就不會多次存在有多個 Candidate 同時發起投票的問題。
在 Raft 中當接收到客戶端的日志(事務請求)后先把該日志追加到本地的 Log 中,然后通過heartbeat 把該 Entry 同步給其他 Follower,Follower 接收到日志后記錄日志然后向 Leader 發送ACK,當 Leader 收到大多數(n/2+1)Follower 的 ACK 信息后將該日志設置為已提交并追加到本地磁盤中,通知客戶端并在下個 heartbeat 中 Leader 將通知所有的 Follower 將該日志存儲在自己的本地磁盤中。
安全性(Safety)
安全性是用于保證每個節點都執行相同序列的安全機制如當某個 Follower 在當前 Leader commitLog 時變得不可用了,稍后可能該 Follower 又會倍選舉為 Leader,這時新 Leader 可能會用新的Log 覆蓋先前已 committed 的 Log,這就是導致節點執行不同序列;Safety 就是用于保證選舉出來的 Leader 一定包含先前 commited Log 的機制;
選舉安全性(Election Safety):每個 Term 只能選舉出一個 Leader
Leader 完整性(Leader Completeness):這里所說的完整性是指 Leader 日志的完整性,Raft 在選舉階段就使用 Term 的判斷用于保證完整性:當請求投票的該 Candidate 的 Term 較大或 Term 相同 Index 更大則投票,該節點將容易變成 leader。
raft 協議和 zab 協議區別
相同點
? 采用 quorum 來確定整個系統的一致性,這個 quorum 一般實現是集群中半數以上的服務器,
? zookeeper 里還提供了帶權重的 quorum 實現.
? 都由 leader 來發起寫操作.
? 都采用心跳檢測存活性
? leader election 都采用先到先得的投票方式
不同點
? zab 用的是 epoch 和 count 的組合來唯一表示一個值, 而 raft 用的是 term 和 index
? zab 的 follower 在投票給一個 leader 之前必須和 leader 的日志達成一致,而 raft 的 follower則簡單地說是誰的 term 高就投票給誰
? raft 協議的心跳是從 leader 到 follower, 而 zab 協議則相反
? raft 協議數據只有單向地從 leader 到 follower(成為 leader 的條件之一就是擁有最新的 log),而 zab 協議在 discovery 階段, 一個 prospective leader 需要將自己的 log 更新為 quorum 里面最新的 log,然后才好在 synchronization 階段將 quorum 里的其他機器的 log 都同步到一致.
NWR
N:在分布式存儲系統中,有多少份備份數據
W:代表一次成功的更新操作要求至少有 w 份數據寫入成功
R: 代表一次成功的讀數據操作要求至少有 R 份數據成功讀取
NWR值的不同組合會產生不同的一致性效果,當W+R>N 的時候,整個系統對于客戶端來講能保證強一致性。而如果 R+W<=N,則無法保證數據的強一致性。以常見的 N=3、W=2、R=2 為例:
N=3,表示,任何一個對象都必須有三個副本(Replica),W=2 表示,對數據的修改操作(Write)只需要在 3 個 Replica 中的 2 個上面完成就返回,R=2 表示,從三個對象中要讀取到 2個數據對象,才能返回。

Gossip
Gossip 算法又被稱為反熵(Anti-Entropy),熵是物理學上的一個概念,代表雜亂無章,而反熵就是在雜亂無章中尋求一致,這充分說明了 Gossip 的特點:在一個有界網絡中,每個節點都隨機地與其他節點通信,經過一番雜亂無章的通信,最終所有節點的狀態都會達成一致。每個節點可
能知道所有其他節點,也可能僅知道幾個鄰居節點,只要這些節可以通過網絡連通,最終他們的
狀態都是一致的,當然這也是疫情傳播的特點。
一致性 Hash
一致性哈希算法(Consistent Hashing Algorithm)是一種分布式算法,常用于負載均衡。
Memcached client 也選擇這種算法,解決將 key-value 均勻分配到眾多 Memcached server 上的問題。它可以取代傳統的取模操作,解決了取模操作無法應對增刪 Memcached Server 的問題(增刪 server 會導致同一個 key,在 get 操作時分配不到數據真正存儲的 server,命中率會急劇下降)。
一致性 Hash 特性
? 平衡性(Balance):平衡性是指哈希的結果能夠盡可能分布到所有的緩沖中去,這樣可以使得所有的緩沖空間都得到利用。
? 單調性(Monotonicity):單調性是指如果已經有一些內容通過哈希分派到了相應的緩沖中,又有新的緩沖加入到系統中。哈希的結果應能夠保證原有已分配的內容可以被映射到新的緩沖中去,而不會被映射到舊的緩沖集合中的其他緩沖區。容易看到,上面的簡單求余算法hash(object)%N 難以滿足單調性要求。
? 平滑性(Smoothness):平滑性是指緩存服務器的數目平滑改變和緩存對象的平滑改變是一致的。
一致性 Hash 原理
1.建構環形 hash 空間:
1. 考慮通常的 hash 算法都是將 value 映射到一個 32 為的 key 值,也即是 0~2^32-1 次方的數值空間;我們可以將這個空間想象成一個首( 0 )尾( 2^32-1 )相接的圓環。
2.把需要緩存的內容(對象)映射到 hash 空間
2. 接下來考慮 4 個對象 object1~object4 ,通過 hash 函數計算出的 hash 值 key 在環上的分布。
3.把服務器(節點)映射到 hash 空間
3. Consistent hashing 的基本思想就是將對象和 cache 都映射到同一個 hash 數值空間中,并且使用相同的 hash 算法。一般的方法可以使用 服務器(節點) 機器的 IP 地址或者機器名作為hash 輸入。
4.把對象映射到服務節點
4. 現在服務節點和對象都已經通過同一個 hash 算法映射到 hash 數值空間中了,首先確定對象hash 值在環上的位置,從此位置沿環順時針“行走”,第一臺遇到的服務器就是其應該定位到的服務器。
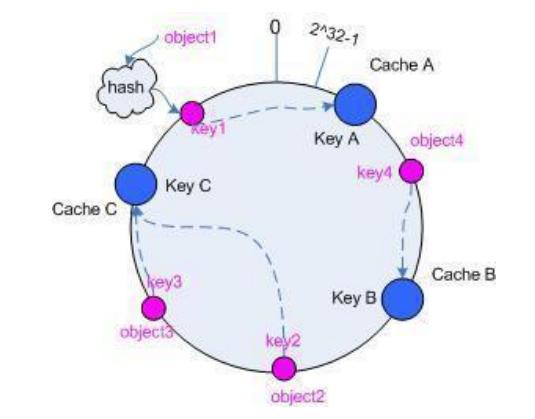
考察 cache 的變動
5. 通過 hash 然后求余的方法帶來的最大問題就在于不能滿足單調性,當 cache 有所變動時,cache 會失效。
5.1 移除 cache:考慮假設 cache B 掛掉了,根據上面講到的映射方法,這時受影響的將僅是那些沿 cache B 逆時針遍歷直到下一個 cache ( cache C )之間的對象。
5.2 添加 cache:再考慮添加一臺新的 cache D 的情況,這時受影響的將僅是那些沿 cacheD 逆時針遍歷直到下一個 cache 之間的對象,將這些對象重新映射到 cache D 上即可。
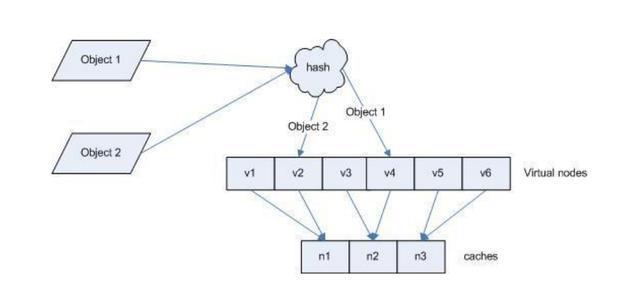
虛擬節點
hash 算法并不是保證絕對的平衡,如果 cache 較少的話,對象并不能被均勻的映射到 cache 上,為了解決這種情況, consistent hashing 引入了“虛擬節點”的概念,它可以如下定義:
虛擬節點( virtual node )是實際節點在 hash 空間的復制品( replica ),一實際個節點對應了若干個“虛擬節點”,這個對應個數也成為“復制個數”,“虛擬節點”在 hash 空間中以 hash值排列。
仍以僅部署 cache A 和 cache C 的情況為例。現在我們引入虛擬節點,并設置“復制個數”為 2 ,這就意味著一共會存在 4 個“虛擬節點”, cache A1, cache A2 代表了 cache A; cache C1,cache C2 代表了 cache C 。此時,對象到“虛擬節點”的映射關系為:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此對象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cacheC 上;平衡性有了很大提高。
引入“虛擬節點”后,映射關系就從 { 對象 -> 節點 } 轉換到了 { 對象 -> 虛擬節點 } 。查詢物體所在 cache 時的映射關系如下圖 所示。