擊這里在線咨詢客服")
作者:Aniruddha Bhandari
翻譯:王琦
校對(duì):和中華
本文約3700字,建議閱讀10分鐘。
本文介紹了Python中的生成器和迭代器。在處理大量數(shù)據(jù)時(shí),計(jì)算機(jī)內(nèi)存可能不足,我們可以通過(guò)生成器和迭代器來(lái)解決該問(wèn)題。
迭代器:一次一個(gè)!
Python 是一種美麗的編程語(yǔ)言。我喜歡它提供的靈活性和難以置信的功能。我喜歡深入研究Python的各種細(xì)微差別,并了解它如何應(yīng)對(duì)不同的情況。
在使用Python的過(guò)程中,我了解到了一些功能,這些功能的使用與其簡(jiǎn)化的復(fù)雜度不相稱。我喜歡稱它們?yōu)镻ython中“隱藏的寶石”。很多人對(duì)此并不了解,但對(duì)于分析和數(shù)據(jù)科學(xué)專家來(lái)說(shuō),它們非常有用。
Python迭代器和生成器正好屬于這一類。它們的潛力是巨大的!

如果你曾經(jīng)在處理大量數(shù)據(jù)時(shí)遇到麻煩(誰(shuí)沒(méi)有呢?!),并且計(jì)算機(jī)內(nèi)存不足,那么你會(huì)喜歡Python中的迭代器和生成器的概念。
與其將所有數(shù)據(jù)一次性都放入內(nèi)存中,不如將它按塊處理,只處理當(dāng)時(shí)所需的數(shù)據(jù),對(duì)嗎?這將大大減少我們計(jì)算機(jī)內(nèi)存的負(fù)載。這就是迭代器和生成器的作用!
因此,讓我們仔細(xì)讀讀本文,探索Python迭代器和生成器的世界吧。
我假設(shè)你熟悉Python的基礎(chǔ)知識(shí)。如果沒(méi)有,我建議你先從下面的熱門(mén)課程學(xué)起:
Python數(shù)據(jù)科學(xué):
https://courses.analyticsvidhya.com/courses/introduction-to-data-science?utm_source=blog&utm_medium=python-iterators-and-generators
這是我們要介紹的內(nèi)容:
- 什么是可迭代對(duì)象?
- 什么是Python迭代器?
- 在Python中創(chuàng)建一個(gè)迭代器
- 熟悉Python中的生成器
- 實(shí)現(xiàn)Python中的生成器表達(dá)式
- 為什么你應(yīng)該使用迭代器?
什么是可迭代對(duì)象?
“可迭代對(duì)象是能夠一次返回其一個(gè)成員的對(duì)象”。
通常使用for循環(huán)完成此操作。像列表、元組、集合、字典、字符串等等之類的對(duì)象被稱為可迭代對(duì)象。簡(jiǎn)而言之,任何你可以循環(huán)的對(duì)象都是可迭代對(duì)象。
我們可以使用for循環(huán)逐個(gè)地返回可迭代的元素。在這里,我們使用for循環(huán)遍歷列表的元素:
# iterables sample = ['data science', 'business analytics', 'machine learning'] for i in sample: print(i)
既然我們知道了什么是可迭代對(duì)象,那么實(shí)際上我們是如何遍歷這些值的?以及我們的循環(huán)如何知道何時(shí)停止?進(jìn)入到迭代器部分!
什么是Python迭代器?
迭代器是代表數(shù)據(jù)流的對(duì)象,即可迭代。它們?cè)赑ython中實(shí)現(xiàn)了迭代器協(xié)議。這是什么?
好吧,迭代器協(xié)議允許我們?cè)谝粋€(gè)可迭代對(duì)象中使用兩種方法來(lái)循環(huán)遍歷項(xiàng):__iter __()和__next __()。所有的可迭代對(duì)象和迭代器都有__iter __()方法,該方法返回一個(gè)迭代器。
迭代器跟蹤可迭代對(duì)象的當(dāng)前狀態(tài)。
但可迭代對(duì)象和迭代器不同之處在于__next __()方法只能由迭代器訪問(wèn)。這使得無(wú)論何時(shí)只要我們要求迭代器返回下一個(gè)值,迭代器就會(huì)返回下一個(gè)值。
讓我們創(chuàng)建一個(gè)簡(jiǎn)單的可迭代對(duì)象、本例中為一個(gè)列表以及使用__iter __()方法來(lái)構(gòu)造一個(gè)迭代器來(lái)了解其工作原理:
sample = ['data science', 'business analytics', 'machine learning'] # generating an iterator it = sample.__iter__() print(it) # iterables do not have __next__() method sample.__next__() 
是的,正如我所說(shuō),可迭代對(duì)象有用于創(chuàng)建迭代器的__iter __()方法,但它們沒(méi)有僅迭代器才有的__next __()方法。因此,讓我們?cè)僭囈淮危缓髧L試從列表中檢索值:
sample = ['data science', 'business analytics', 'machine learning'] # generating an iterator it = sample.__iter__() print(it.__next__()) print(it.__next__()) print(it.__next__()) 
完美!但等一下,我不是說(shuō)迭代器也具有__iter __()方法嗎?那是因?yàn)?strong>迭代器也是可迭代的,但反過(guò)來(lái)不成立。它們是自己的迭代器。讓我通過(guò)遍歷迭代器向你展示這個(gè)概念:
sample = ['data science', 'business analytics', 'machine learning'] it = sample.__iter__() itit = it.__iter__() print(type(itit)) print(itit.__next__()) print(itit.__next__()) print(itit.__next__()) 
酷!但我們可以使用iter()和next()來(lái)代替__iter__()和__next__()方法,它們提供了一種更簡(jiǎn)潔的方法:
sample = ['statistics', 'linear algebra', 'probability'] # iterator it = iter(sample) # next values print(next(it)) print(next(it)) print(next(it))
但如果我們超過(guò)了調(diào)用next()方法的限制次數(shù),該怎么辦?這會(huì)發(fā)生什么呢?
print(next(it)) 
是的,我們得到了一個(gè)錯(cuò)誤!如果我們?cè)诘竭_(dá)迭代器的末尾之后嘗試訪問(wèn)下一個(gè)值,則會(huì)引起StopIteration異常,該異常的意思是“你不能更進(jìn)一步了!”。
我們可以使用異常處理來(lái)處理此錯(cuò)誤。實(shí)際上,我們可以自己構(gòu)建一個(gè)循環(huán)來(lái)遍歷可迭代的項(xiàng):
sample = ['statistics', 'linear algebra', 'probability'] it = iter(sample) while True: # this will execute till an error is raised try: val = next(it) # when we reach end of the list, error is raised and we break out of the loop except StopIteration: break print(val) 
如果你退后一步,你會(huì)意識(shí)到,這正是for循環(huán)在底層運(yùn)行的方式。我們?cè)诖颂幨謩?dòng)循環(huán)中所做的操作,for循環(huán)會(huì)自動(dòng)執(zhí)行相同的操作。這就是為什么for循環(huán)比遍歷可迭代對(duì)象更可取,因?yàn)樗鼈儠?huì)自動(dòng)處理異常。
每當(dāng)我們迭代一個(gè)可迭代對(duì)象時(shí),for循環(huán)通過(guò)iter()知道要迭代的項(xiàng),并使用next()方法返回后續(xù)的項(xiàng)。
在Python中創(chuàng)建一個(gè)迭代器
既然我們知道了Python迭代器是如何工作的,我們可以更深入地研究并從頭開(kāi)始創(chuàng)建一個(gè)迭代器,以更好地了解其是如何湊效的。
我將創(chuàng)建一個(gè)用于打印所有偶數(shù)的簡(jiǎn)單迭代器
class Sequence(): def __init__(self): self.num = 2 def __iter__(self): return self def __next__(self): val = self.num self.num += 2 return val
讓我們分解一下這段Python代碼:
- __init __()方法是類構(gòu)造函數(shù),調(diào)用類時(shí)會(huì)首先執(zhí)行該函數(shù)。它用于分配程序執(zhí)行期間類最初所需的任何值。我在這里設(shè)置num變量的初始值為2;
- iter()和next()方法使這個(gè)類變成了迭代器;
- iter()方法返回迭代器對(duì)象并對(duì)迭代進(jìn)行初始化。由于類對(duì)象本身是迭代器,因此它返回自身;
- next()方法從迭代器中返回當(dāng)前值,并改變下一次調(diào)用的狀態(tài)。我們將num變量的值加2,因?yàn)槲覀冎淮蛴∨紨?shù)。
我們可以創(chuàng)建Sequence對(duì)象來(lái)遍歷Sequence類,在該對(duì)象上調(diào)用next()方法:
it = Sequence() print(next(it)) print(next(it)) print(next(it)) print(next(it)) print(next(it)) 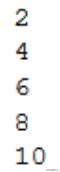
我沒(méi)有寫(xiě)sequence結(jié)束的條件,因此迭代器將永遠(yuǎn)繼續(xù)返回下一個(gè)值。但我們可以使用停止條件輕松地對(duì)其進(jìn)行更新:
sample = ['statistics', 'linear algebra', 'probability'] # iterator it = iter(sample) # next values print(next(it)) print(next(it)) print(next(it))
我剛剛加入了一條if語(yǔ)句,只要值超過(guò)10,該語(yǔ)句就會(huì)停止迭代:
it = Sequence() for i in it: print(i)
在這里,我沒(méi)有使用next()方法從迭代器返回值,而是使用了for循環(huán),該循環(huán)的工作方式與之前相同。
熟悉Python中的生成器
生成器也是迭代器,但更加優(yōu)雅。使用生成器,我們可以實(shí)現(xiàn)與迭代器相同的功能,但不必在類中編寫(xiě)iter()和next()函數(shù)。相反,我們可以使用一個(gè)簡(jiǎn)單的函數(shù)來(lái)完成與迭代器相同的任務(wù):
# fibonacci sequence using a generator def fib(): prev, curr = 0, 1 # infinite loop while prev<5: value = prev # Calculate the next number in the sequence. Using Tuple unpacking. prev, curr = curr, prev + curr # yield the value yield value
你是否注意到這個(gè)生成器函數(shù)和常規(guī)函數(shù)的不同?是的,yield關(guān)鍵字!
普通函數(shù)使用return關(guān)鍵字返回值。但是生成器函數(shù)使用yield關(guān)鍵字返回值。這就是生成器函數(shù)與常規(guī)函數(shù)不同的地方(除了這種區(qū)別,它們是完全相同的)。
yield關(guān)鍵字的工作方式類似于普通的return關(guān)鍵字,但有額外的功能:它能記住函數(shù)的狀態(tài)。因此,下次調(diào)用generator函數(shù)時(shí),它不是從頭開(kāi)始,而是從上次調(diào)用中停止的位置開(kāi)始。
讓我們看看它是如何工作的:
# generator object gen=fib() print(gen) # values print(next(gen)) print(next(gen)) print(next(gen)) print(next(gen)) print(next(gen)) 
生成器屬于“生成器”類型,它是迭代器的一種特殊類型,但仍然是迭代器,因此它們也是懶惰的工作者。除非next()方法明確要求它們這樣做,否則它們不會(huì)返回任何值。
最初創(chuàng)建fib()生成器函數(shù)的對(duì)象時(shí),它會(huì)初始化prev和curr變量。現(xiàn)在,當(dāng)在對(duì)象上調(diào)用next()方法時(shí),生成器函數(shù)會(huì)計(jì)算值并返回輸出,同時(shí)記住函數(shù)的狀態(tài)。因此,下次調(diào)用next()方法時(shí),該函數(shù)將從上次停止的地方開(kāi)始,從那里繼續(xù)。
每當(dāng)使用next()方法時(shí),該函數(shù)將繼續(xù)生成值,直到prev變得大于5,這時(shí)將引起StopIteration異常,如下所示:
print(next(gen))
實(shí)現(xiàn)Python中的生成器表達(dá)式
你不必在每次執(zhí)行生成器時(shí)都編寫(xiě)函數(shù)。相反,你可以使用生成器表達(dá)式,就像列表生成式一樣。唯一的區(qū)別是,與列表生成式不同,生成器表達(dá)式包含在圓括號(hào)內(nèi),如下所示:
squared_gen = (x*x for x in range(2,5)) print(squared_gen)
但它們?nèi)匀缓軕校虼四阈枰褂胣ext()方法。但你現(xiàn)在知道使用for循環(huán)可以更好地返回值:
for i in squared_gen: print(i) 
當(dāng)你編寫(xiě)簡(jiǎn)單的代碼時(shí),生成器表達(dá)式非常有用,因?yàn)樗鼈円鬃x、易理解。但隨著代碼變得更復(fù)雜,它們的功能會(huì)迅速變?nèi)酢T谶@種情況下,你發(fā)現(xiàn)自己會(huì)重新使用生成器函數(shù),生成器函數(shù)在編寫(xiě)更復(fù)雜的函數(shù)方面提供了更大的靈活性。
為什么你應(yīng)該使用迭代器?
一個(gè)重要的問(wèn)題:為什么要先考慮用迭代器?
我在文章開(kāi)頭提到了這一點(diǎn):之所以使用迭代器,是因?yàn)樗鼈優(yōu)槲覀児?jié)省了大量?jī)?nèi)存。這是因?yàn)榈髟谏蓵r(shí)不會(huì)計(jì)算項(xiàng),而只會(huì)在調(diào)用它們時(shí)計(jì)算。
如果我創(chuàng)建一個(gè)包含1000萬(wàn)個(gè)項(xiàng)的列表,并創(chuàng)建一個(gè)包含相同數(shù)量項(xiàng)的生成器,則它們內(nèi)存大小上的差異將令人震驚:
import sys # list comprehension mylist = [i for i in range(10000000)] print('Size of list in memory',sys.getsizeof(mylist)) # generator expression mygen = (i for i in range(10000000)) print('Size of generator in memory',sys.getsizeof(mygen)
對(duì)于相同的數(shù)量的項(xiàng),列表和生成器在內(nèi)存大小上存在巨大差異。這就是迭代器的美。
不僅如此,你可以使用迭代器逐行讀取文件中的文本,而不是一次性讀取所有內(nèi)容。這會(huì)再次為你節(jié)省大量?jī)?nèi)存,尤其是在文件很大的情況下。
在這里,讓我們使用生成器來(lái)迭代讀取文件。為此,我們可以創(chuàng)建一個(gè)簡(jiǎn)單的生成器表達(dá)式來(lái)懶惰地打開(kāi)文件,一次讀取一行:
file = "Greetings.txt" # generator expression lines = (line for line in open(file)) print(lines) # print lines print(next(lines)) print(next(lines)) print(next(lines)) 
這很棒,但對(duì)于數(shù)據(jù)科學(xué)家或分析師而言,他們最終都要在Pandas的 dataframe中處理大型數(shù)據(jù)集。當(dāng)你不得不處理龐大的數(shù)據(jù)集時(shí),也許這個(gè)數(shù)據(jù)集有幾千行數(shù)據(jù)點(diǎn)甚至更多。如果Pandas可以解決這一難題,那么數(shù)據(jù)科學(xué)家的生活將變得更加輕松。
好吧,你很幸運(yùn),因?yàn)?strong>Pandas的read_csv()(
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html)有處理該問(wèn)題的chunksize參數(shù)。它使你可以按指定大小的塊來(lái)加載數(shù)據(jù),而不是將整個(gè)數(shù)據(jù)加載到內(nèi)存中。處理完一個(gè)數(shù)據(jù)塊后,可以對(duì)dataframe對(duì)象執(zhí)行next()方法來(lái)加載下一個(gè)數(shù)據(jù)塊。就這么簡(jiǎn)單!
我將讀取Black Friday數(shù)據(jù)集(
https://datahack.analyticsvidhya.com/contest/black-friday/?utm_source=blog&utm_medium=
python-iterators-and-generators),該數(shù)據(jù)集包含550,068行數(shù)據(jù),讀取時(shí)設(shè)置每塊的大小為10,這樣做只是為了演示該函數(shù)的用法:
import pandas as pd # pandas dataframe df = pd.read_csv('./Black Friday.csv', chunksize=10) # print first chunk of data next(df)
# print second chunk of data next(df) 
很有用,不是嗎?
結(jié)語(yǔ)
我確信你現(xiàn)在已經(jīng)習(xí)慣于使用迭代器,而且一定在考慮把所有函數(shù)轉(zhuǎn)換為生成器!你開(kāi)始喜歡Python編程的強(qiáng)大之處。
你以前使用過(guò)Python迭代器和生成器嗎?或者你要與社區(qū)分享其他“隱藏的寶石”?大家可以在下方評(píng)論!
原文標(biāo)題:
What are Python Iterators and Generators? Programming Concepts Every Data Science Professional Should Know
原文鏈接:
https://www.analyticsvidhya.com/blog/2020/05/python-iterators-and-generators/
編輯:黃繼彥
校對(duì):譚佳瑤





