
緩存是互聯網高并發系統里常用的組件,由于多增加了一層,如果沒有正確的使用效果可能適得其反,諸如“緩存是刪除還是更新?”,“先操作數據庫還是先操作緩存?”都是些老生常談的話題,今天我們就來聊一聊緩存與數據庫的雙寫一致性的解決方案。
Cache Aside Pattern
在一開始先科普下最經典的緩存+數據庫讀寫的模式,就是 Cache Aside Pattern。
- 讀的時候,先讀緩存,緩存沒有的話,就讀數據庫,然后取出數據后放入緩存,同時返回響應。
- 更新的時候,先更新數據庫,然后再刪除緩存。

為什么是刪除緩存,而不是更新緩存?
更新緩存在并發下會帶來種種問題,直接刪除緩存比較簡單粗暴,穩妥。而且還有懶加載的思想,等用到的時候在去數據庫讀出來放進去,不用到你每次去更新他干嘛,浪費時間資源,而且還有更新失敗、產生臟數據的一些風險, 達成這一點共識以后,我們來開始今天的討論。
先更新數據庫,再刪除緩存
1、更新數據庫成功,刪除緩存成功,沒毛病。
2、更新數據庫失敗,程序捕獲異常,不會走到下一步,不會出現數據不一致情況。
3、更新數據庫成功,刪除緩存失敗。數據庫是新數據,緩存是舊數據,發生了不一致的情況。這里我們來看下怎么解決
- 重試的機制,如果刪除緩存失敗,我們捕獲這個異常,把需要刪除的key發送到消息隊列, 然后自己創建一個消費者消費,嘗試再次刪除這個 key。
- 異步更新緩存,更新數據庫時會往 binlog 寫入日志,所以我們可以通過一個服務來監聽 binlog 的變化(比如阿里的 canal),然后在客戶端完成刪除 key 的操作。如果刪除失敗的話,再發送到消息隊列。
總之,我們要達到最終一致性!
先刪除緩存,再更新數據庫
1、刪除緩存成功,更新數據庫成功,沒毛病。
2、刪除緩存失敗,程序捕獲異常,不會走到下一步,不會出現數據不一致情況。
3、刪除緩存成功,更新數據庫失敗,此時數據庫中是舊數據,緩存中是空的,那么數據不會不一致。因為讀的時候緩存沒有,則讀數據庫中舊數據,然后更新到緩存中。
雖然沒有發生數據不一致的情況,看上去好像一切都很完美,但是以上是在單線程的情況下,如果在并發的情況下可能會出現以下場景
1)線程 A 需要更新數據,首先刪除了 redis 緩存
2)線程 B 查詢數據,發現緩存不存在,到數據庫查詢舊值,寫入 Redis,返回
3)線程 A 更新了數據庫
復制代碼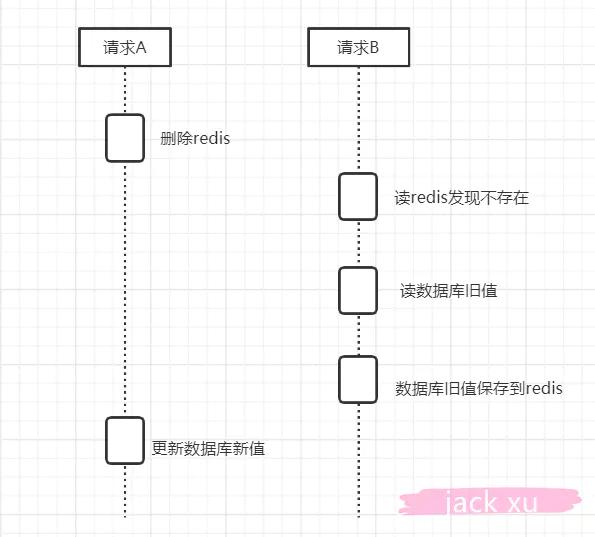
這個時候,Redis是舊的值,數據庫是新的值,還是發生了數據不一致的情況。
延時雙刪
針對上面這種情況,我們有一種延時雙刪的方法
1)刪除緩存
2)更新數據庫
3)休眠 500ms(這個時間,依據讀取數據的耗時而定)
4)再次刪除緩存
復制代碼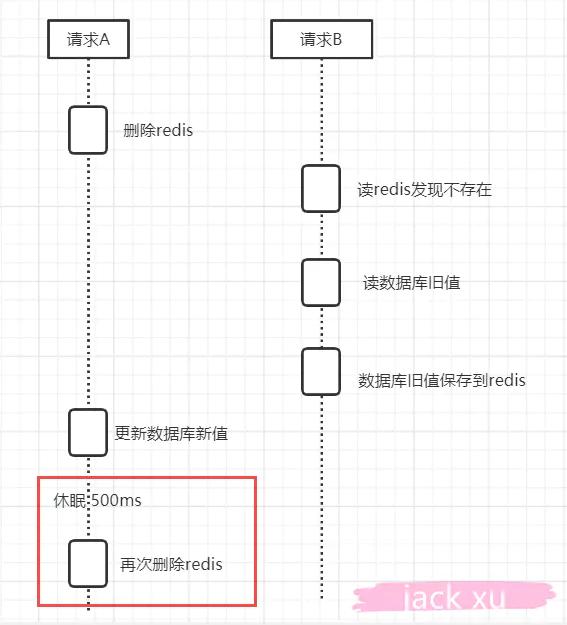
你把舊值存在Redis以后,過一段時間我在刪除一次,這時把舊值給刪掉了,這樣就能保證Redis和數據庫是同步的了,這么做在一定程度上可以緩解這個問題,但也不是十分完美,比如第一次緩存刪除成功了,第二次緩存刪除失敗,又該怎么辦?
內存隊列
除了延時雙刪這個方法,還有個方案就是內存隊列,他的思想是串行化,我們在JVM中維護一個內存隊列。當更新數據的時候,我們不直接操作數據庫和緩存,而是把數據的Id放到內存隊列;當讀數據的時候發現數據不在緩存中,我們不去數據庫查放到緩存中,而是把數據的Id放到內存隊列。
后臺會有一個線程消費內存隊列里面的數據,然后一條一條的執行。這樣的話,一個更新數據的操作,先刪除緩存,然后再去更新數據庫,但是還沒完成更新。此時如果一個讀請求過來,讀到了空的緩存,那么先將緩存更新的請求發送到隊列中,此時會在隊列中積壓,然后同步等待緩存更新完成。
這里有一個優化點,一個隊列中,其實多個更新緩存請求串在一起是沒意義的,因此可以做過濾,如果發現隊列中已經有一個更新緩存的請求了,那么就不用再放個更新請求操作進去了,直接等待前面的更新操作請求完成即可。
等內存隊列中將更新數據的操作完成之后,才會去執行下一個操作,也就是讀數據的操作,此時會從數據庫中讀取最新的值,然后寫入緩存中。 如果請求還在等待時間范圍內,不斷輪詢發現可以取到值了,那么就直接返回;如果請求等待的時間超過一定時長,那么這一次直接從數據庫中讀取。
總結
上面說的幾種方案,都是比較常見的,也比較簡單,沒有十全十美的,最后的內存隊列也會影響性能以及增加系統的復雜度。今天討論的Redis和數據庫的數據更新是不可能通過事務達到統一的,什么叫做事務,就是一損俱損一榮俱榮,要么都成功要么都失敗,這是不能保證的。
我們只能根據相應的場景和所需要付出的代價來采取一些措施,降低數據不一致的問題出現的概率,在數據一致性和性能之間取得一個權衡,具體場景具體使用。
作者:jack_xu
鏈接:https://juejin.im/post/5edafcb051882543023c0cd0





