
什么是長連接?
長連接還是短連接
相比于短連接,長連接更節省資源。如果每發送一條消息就要創建鏈路、發起握手認證、關閉鏈路釋放資源,會損耗大量的系統資源。長連接只在首次創建時或者鏈路斷連重連才創建鏈路,鏈路創建成果之后服務提供者和消費者會通過業務消息和心跳維系鏈路,實現多消息復用同一個鏈路節省資源。
HTTP1.1規定了默認保持長連接(HTTP persistent connection ,也有翻譯為持久連接),數據傳輸完成了保持TCP連接不斷開(不發RST包、不四次握手),等待在同域名下繼續用這個通道傳輸數據;相反的就是短連接。
HTTP首部的Connection: Keep-alive是HTTP1.0瀏覽器和服務器的實驗性擴展,當前的HTTP1.1 RFC2616文檔沒有對它做說明,因為它所需要的功能已經默認開啟,無須帶著它,但是實踐中可以發現,瀏覽器的報文請求都會帶上它。如果HTTP1.1版本的HTTP請求報文不希望使用長連接,則要在HTTP請求報文首部加上Connection: close。《HTTP權威指南》提到,有部分古老的HTTP1.0 代理不理解Keep-alive,而導致長連接失效:客戶端-->代理-->服務端,客戶端帶有Keep-alive,而代理不認識,于是將報文原封不動轉給了服務端,服務端響應了Keep-alive,也被代理轉發給了客戶端,于是保持了“客戶端-->代理”連接和“代理-->服務端”連接不關閉,但是,當客戶端第發送第二次請求時,代理會認為當前連接不會有請求了,于是忽略了它,長連接失效。書上也介紹了解決方案:當發現HTTP版本為1.0時,就忽略Keep-alive,客戶端就知道當前不該使用長連接。其實,在實際使用中不需要考慮這么多,很多時候代理是我們自己控制的,如Nginx代理,代理服務器有長連接處理邏輯,服務端無需做patch處理,常見的是客戶端跟Nginx代理服務器使用HTTP1.1協議&長連接,而Nginx代理服務器跟后端服務器使用HTTP1.0協議&短連接。
在實際使用中,HTTP頭部有了Keep-Alive這個值并不代表一定會使用長連接,客戶端和服務器端都可以無視這個值,也就是不按標準來,譬如我自己寫的HTTP客戶端多線程去下載文件,就可以不遵循這個標準,并發的或者連續的多次GET請求,都分開在多個TCP通道中,每一條TCP通道,只有一次GET,GET完之后,立即有TCP關閉的四次握手,這樣寫代碼更簡單,這時候雖然HTTP頭有Connection: Keep-alive,但不能說是長連接。正常情況下客戶端瀏覽器、web服務端都有實現這個標準,因為它們的文件又小又多,保持長連接減少重新開TCP連接的開銷很有價值。
以前使用libcurl做的上傳/下載,就是短連接,抓包可以看到:1、每一條TCP通道只有一個POST;2、在數據傳輸完畢可以看到四次握手包。只要不調用curl_easy_cleanup,curl的handle就可能一直有效,可復用。這里說可能,因為連接是雙方的,如果服務器那邊關掉了,那么我客戶端這邊保留著也不能實現長連接。
如果是使用windows的WinHTTP庫,則在POST/GET數據的時候,雖然我關閉了句柄,但這時候TCP連接并不會立即關閉,而是等一小會兒,這時候是WinHTTP庫底層支持了跟Keep-alive所需要的功能:即便沒有Keep-alive,WinHTTP庫也可能會加上這種TCP通道復用的功能,而其它的網絡庫像libcurl則不會這么做。
1、概述
提高網絡性能優化,很重要的一點就是降低延遲和提升響應速度。
通常我們在瀏覽器中發起請求的時候header部分往往是這樣的
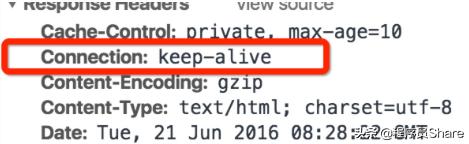
keep-alive 就是瀏覽器和服務端之間保持長連接,這個連接是可以復用的。在HTTP1.1中是默認開啟的。
2、連接的復用為什么會提高性能呢?
通常我們在發起http請求的時候首先要完成tcp的三次握手,然后傳輸數據,最后再釋放連接。三次握手的過程可以參考這里 TCP三次握手詳解及釋放連接過程
一次響應的過程

在高并發的請求連接情況下或者同個客戶端多次頻繁的請求操作,無限制的創建會導致性能低下。
如果使用keep-alive

在timeout空閑時間內,連接不會關閉,相同重復的request將復用原先的connection,減少握手的次數,大幅提高效率。
并非keep-alive的timeout設置時間越長,就越能提升性能。長久不關閉會造成過多的僵尸連接和泄露連接出現。
那么okttp在客戶端是如果類似于客戶端做到的keep-alive的機制。
長連接的過期時間
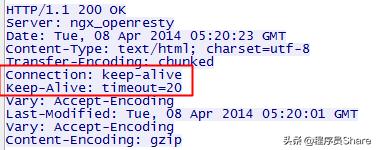
上圖中的Keep-Alive: timeout=20,表示這個TCP通道可以保持20秒。另外還可能有max=XXX,表示這個長連接最多接收XXX次請求就斷開。對于客戶端來說,如果服務器沒有告訴客戶端超時時間也沒關系,服務端可能主動發起四次握手斷開TCP連接,客戶端能夠知道該TCP連接已經無效;另外TCP還有心跳包來檢測當前連接是否還活著,方法很多,避免浪費資源。
長連接的數據傳送完成識別
使用長連接之后,客戶端、服務端怎么知道本次傳輸結束呢?兩部分:1是判斷傳輸數據是否達到了Content-Length指示的大小;2動態生成的文件沒有Content-Length,它是分塊傳輸(chunked),這時候就要根據chunked編碼來判斷,chunked編碼的數據在最后有一個空chunked塊,表明本次傳輸數據結束。更細節的介紹可以看這篇文章。
并發連接數的數量限制
在web開發中需要關注瀏覽器并發連接的數量,RFC文檔說,客戶端與服務器最多就連上兩通道,但服務器、個人客戶端要不要這么做就隨人意了,有些服務器就限制同時只能有1個TCP連接,導致客戶端的多線程下載(客戶端跟服務器連上多條TCP通道同時拉取數據)發揮不了威力,有些服務器則沒有限制。瀏覽器客戶端就比較規矩,限制了同域名下能啟動若干個并發的TCP連接去下載資源。并發數量的限制也跟長連接有關聯,打開一個網頁,很多個資源的下載可能就只被放到了少數的幾條TCP連接里,這就是TCP通道復用(長連接)。如果并發連接數少,意味著網頁上所有資源下載完需要更長的時間(用戶感覺頁面打開卡了);并發數多了,服務器可能會產生更高的資源消耗峰值。瀏覽器只對同域名下的并發連接做了限制,也就意味著,web開發者可以把資源放到不同域名下,同時也把這些資源放到不同的機器上,這樣就完美解決了。
容易混淆的概念——TCP的keep alive和HTTP的Keep-alive
TCP的keep alive是檢查當前TCP連接是否活著;HTTP的Keep-alive是要讓一個TCP連接活久點。它們是不同層次的概念。
TCP keep alive的表現:
當一個連接“一段時間”沒有數據通訊時,一方會發出一個心跳包(Keep Alive包),如果對方有回包則表明當前連接有效,繼續監控。
這個“一段時間”可以設置。具體做法google吧。
HTTP 流水線技術
使用了HTTP長連接(HTTP persistent connection )之后的好處,包括可以使用HTTP 流水線技術(HTTP pipelining,也有翻譯為管道化連接),它是指,在一個TCP連接內,多個HTTP請求可以并行,下一個HTTP請求在上一個HTTP請求的應答完成之前就發起。從wiki上了解到這個技術目前并沒有廣泛使用,使用這個技術必須要求客戶端和服務器端都能支持,目前有部分瀏覽器完全支持,而服務端的支持僅需要:按HTTP請求順序正確返回Response(也就是請求&響應采用FIFO模式),wiki里也特地指出,只要服務器能夠正確處理使用HTTP pipelinning的客戶端請求,那么服務器就算是支持了HTTP pipelining。
由于要求服務端返回響應數據的順序必須跟客戶端請求時的順序一致,這樣也就是要求FIFO,這容易導致Head-of-line blocking:第一個請求的響應發送影響到了后邊的請求,因為這個原因導致HTTP流水線技術對性能的提升并不明顯(wiki提到,這個問題會在HTTP2.0中解決)。另外,使用這個技術的還必須是冪等的HTTP方法,因為客戶端無法得知當前已經處理到什么地步,重試后可能發生不可預測的結果。POST方法不是冪等的:同樣的報文,第一次POST跟第二次POST在服務端的表現可能會不一樣。
在HTTP長連接的wiki中提到了HTTP1.1的流水線技術對RFC規定一個用戶最多兩個連接的指導意義:流水線技術實現好了,那么多連接并不能提升性能。我也覺得如此,并發已經在單個連接中實現了,多連接就沒啥必要,除非瓶頸在于單個連接上的資源限制迫使不得不多開連接搶資源。





